

1月24日,上海岩芯数智人工智能科技有限公司对外推出了一个非Attention机制的通用自然语言大模型——Yan模型。岩芯数智发布会上称,Yan模型使用了全新自研的“Yan架构”代替Transformer架构,相较于Transformer,Yan架构的记忆能力提升3倍、速度提升7倍的同时,实现推理吞吐量的5倍提升。 岩芯数智CEO刘凡平认为,以大规模著称的Transformer,在实际应用中的高算力和高成本,让不少中小型企业望而却步。其内部架构的复杂性,让决策过程难以解释;长序列处理困难和无法控制的幻觉问题也限制了大模型在某些关键领域和特殊场景的广泛应用。随着云计算和边缘计算的普及,行业对于高效能、低能耗AI大模型的需求正不断增长。
岩芯数智CEO刘凡平认为,以大规模著称的Transformer,在实际应用中的高算力和高成本,让不少中小型企业望而却步。其内部架构的复杂性,让决策过程难以解释;长序列处理困难和无法控制的幻觉问题也限制了大模型在某些关键领域和特殊场景的广泛应用。随着云计算和边缘计算的普及,行业对于高效能、低能耗AI大模型的需求正不断增长。
“在全球范围内,一直以来都有不少优秀的研究者试图从根本上解决对 Transformer架构的过度依赖,寻求更优的办法替代 Transformer。就连Transformer 的论文作者之一Llion Jones也在探索‘Transformer 之后的可能’,试图用一种基于进化原理的自然启发智能方法,从不同角度创造对AI框架的再定义。”
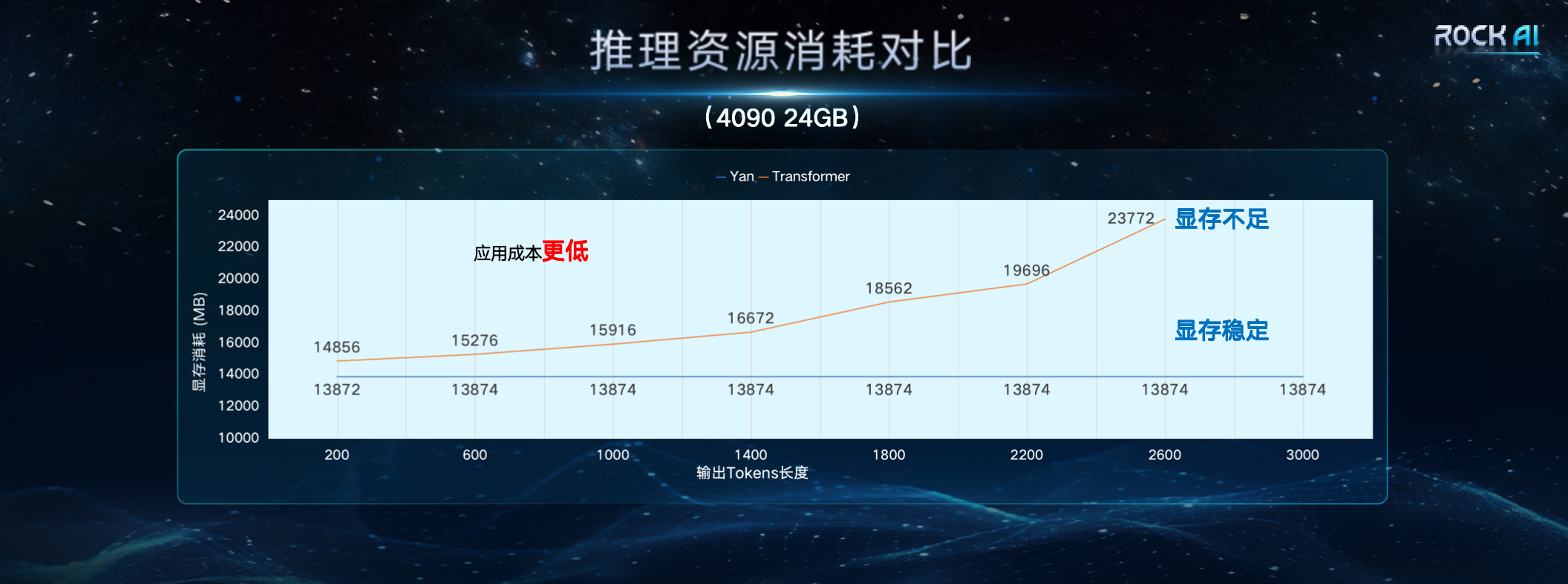
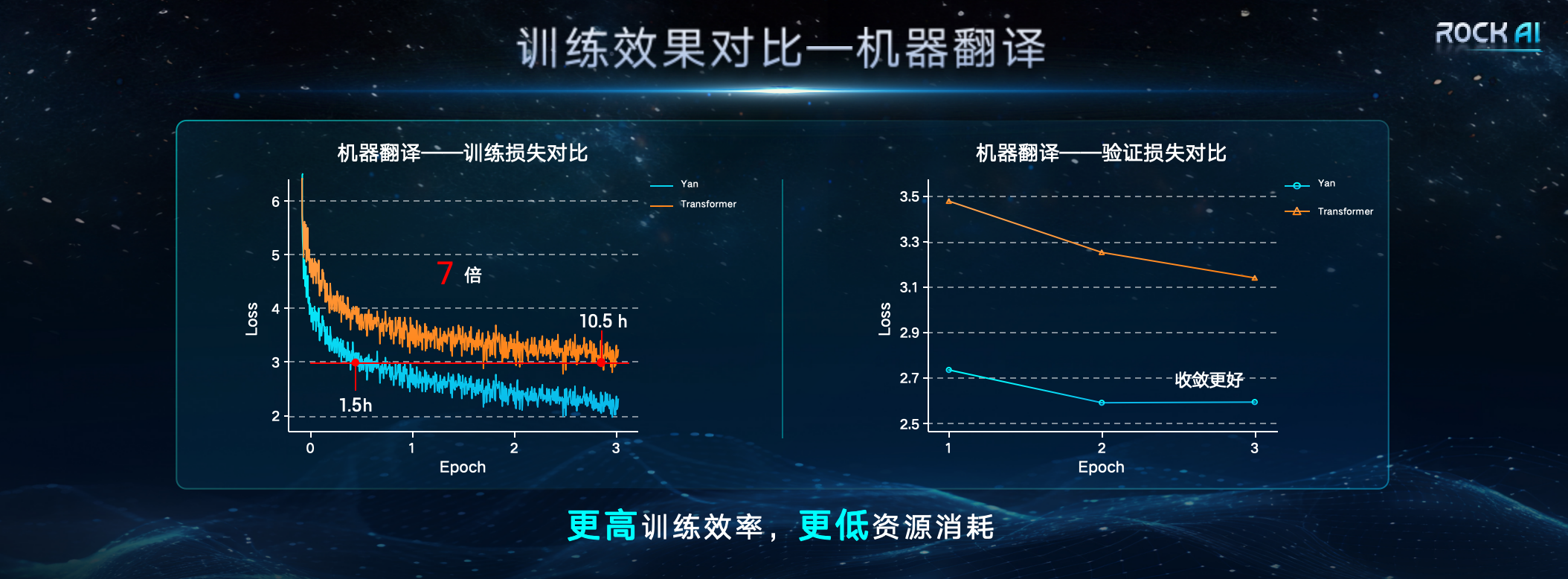
在发布会上,岩芯数智称,在同等资源条件下,Yan架构的模型,训练效率和推理吞吐量分别是Transformer架构的7倍及5倍,并使记忆能力得到3倍提升。Yan架构的设计,使得Yan模型在推理时的空间复杂度为常量,因此针对Transformer面临的长序列难题,Yan模型同样表现优异。对比数据表明,在单张4090 24G显卡上,当模型输出token的长度超出2600时,Transformer的模型会出现显存不足,而Yan模型的显存使用始终稳定在14G左右,理论上能够实现无限长度的推理。
以上是岩芯數智發布支援離線端側部署的大型非Attention機制模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















