

在详细了解去噪扩散概率模型(DDPM)的工作原理之前,我们先来了解一下生成式人工智能的一些发展情况,这也是DDPM的基础研究之一。

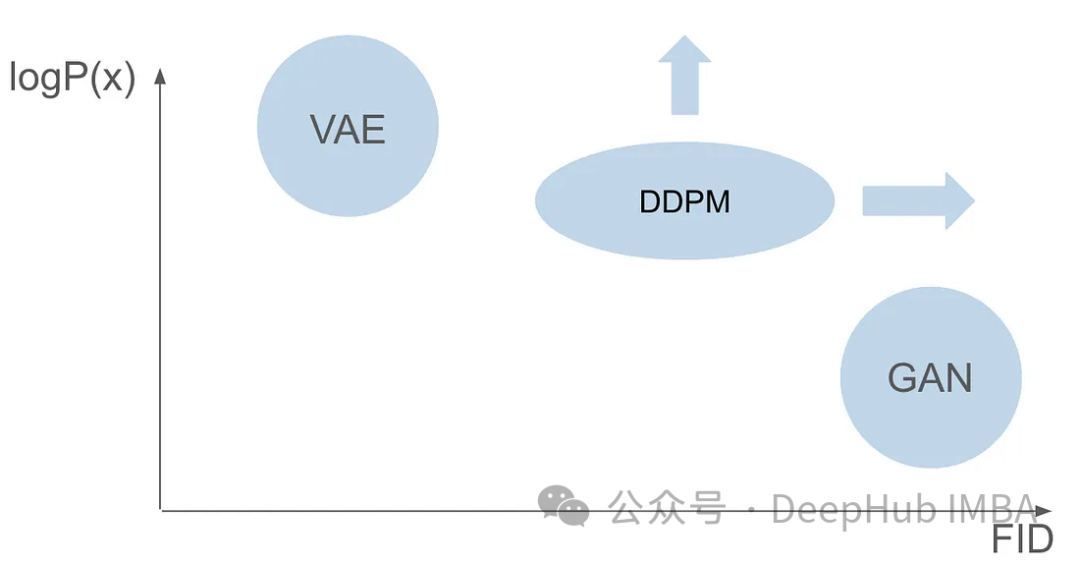
VAE使用编码器、概率潜在空间和解码器。在训练过程中,编码器预测每个图像的均值和方差,并从高斯分布中对这些值进行采样。采样的结果传递到解码器中,解码器将输入图像转换为与输出图像相似的形式。KL散度用于计算损失。VAE的一个显著优势是其能够生成多样化的图像。在采样阶段,可以直接从高斯分布中采样,并通过解码器生成新的图像。
在变分自编码器(VAEs)的短短一年之后,一个开创性的生成家族模型出现了——生成对抗网络(GANs),标志着一类新的生成模型的开始,其特征是两个神经网络的协作:一个生成器和一个鉴别器,涉及对抗性训练过程。生成器的目标是从随机噪声中生成真实的数据,例如图像,而鉴别器则努力区分真实数据和生成数据。在整个训练阶段,生成器和鉴别器通过竞争性学习过程不断完善自己的能力。生成器生成越来越有说服力的数据,从而比鉴别器更聪明,而鉴别器又提高了辨别真实样本和生成样本的能力。这种对抗性的相互作用在生成器生成高质量、逼真的数据时达到顶峰。在采样阶段,经过GAN训练后,生成器通过输入随机噪声产生新的样本。它将这些噪声转换为通常反映真实示例的数据。
虽然GANs和VAEs在图像生成方面各有优势,但它们都存在一些问题。GANs可以生成与训练集中图像非常相似的逼真图像,但其生成结果缺乏多样性。而VAEs则可以创建各种各样的图像,但容易生成模糊的图像。 然而,目前还没有成功将这两种功能结合起来,即创造出既高度逼真又多样化的图像。这个挑战对于研究人员来说是一个重大障碍,需要解决。因此,未来的研究方向之一是探索如何将GANs和VAEs的优势相结合,以实现高度逼真且多样化的图像生成。这将为图像生成领域带来重大突破,并在各个领域中得到广泛应用。
在GAN论文发表六年后,VAE论文发表七年后,出现了一个开创性的模型,即去噪扩散概率模型(DDPM)。DDPM将两个领域的优势融合,能够创造出多样化和逼真的图像。
本文将详细探讨DDPM的复杂性,包括训练过程、正向和逆向过程,以及采样方法。我们将使用PyTorch从零开始构建并训练DDPM,全程引导读者完成。
假设您已熟悉深度学习基础知识,具备扎实的深度计算机视觉基础。我们不再详细介绍这些基本概念,而是致力于生成令人相信真实性的图像。
去噪扩散概率模型(DDPM)是生成模型领域的一种前沿方法。相较于传统模型依赖显式似然函数的方式,DDPM通过迭代的去噪扩散过程来运行。这一过程包括逐渐向图像中添加噪声并试图去除该噪声。其基本理论是基于以下思路:通过一系列扩散步骤将一个简单的分布(如高斯分布)转换为复杂且具有表现力的图像数据分布。换言之,通过将样本从原始图像分布转移到高斯分布,我们可以建立一个模型来逆转这一过程。这使得我们能够从全高斯分布开始,生成出具有图像分布特征的新图像,从而实现有效的图像生成。
DDPM的训练包括两个基本步骤:产生噪声图像这是固定和不可学习的正向过程,以及随后的逆向过程。逆向过程的主要目标是使用专门的机器学习模型对图像进行去噪。
正向过程是一个固定且不可学习的步骤,但是它需要一些预定义的设置。在深入研究这些设置之前,让我们先了解一下它是如何工作的。
这个过程的核心概念是从一个清晰的图像开始。在用“T”表示的特定步长上,少量噪声按照高斯分布逐渐引入。

從圖像中可以看出,雜訊是在每一步遞增的,我們深入研究這種雜訊的數學表示。
雜訊是從高斯分佈中取樣的。為了在每一步引入少量的噪聲,我們使用馬可夫鏈。要產生目前時間戳記的圖像,我們只需要上次時間戳記的圖像。馬可夫鏈的概念在這裡是關鍵的,並對隨後的數學細節至關重要。
馬可夫鍊是一個隨機過程,其中過渡到任何特定狀態的機率只取決於當前狀態和經過的時間,而不是先前的事件序列。這項特性簡化了雜訊添加過程的建模,使其更易於數學分析。
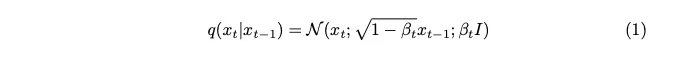
用beta表示的變異數參數被有意地設定為一個非常小的值,目的是在每個步驟中只引入最少量的噪音。
步長參數「T」決定了產生全雜訊影像所需的步長。在本文中,該參數被設定為1000,這可能顯得很大。我們真的需要為資料集中的每個原始影像創建1000個雜訊影像嗎?馬可夫鏈方面被證明有助於解決這個問題。由於我們只需要上一步的圖像來預測下一步,並且每一步添加的雜訊保持不變,因此我們可以透過產生特定時間戳的雜訊影像來簡化計算。採用對的再參數化技巧使我們能夠進一步簡化方程式。
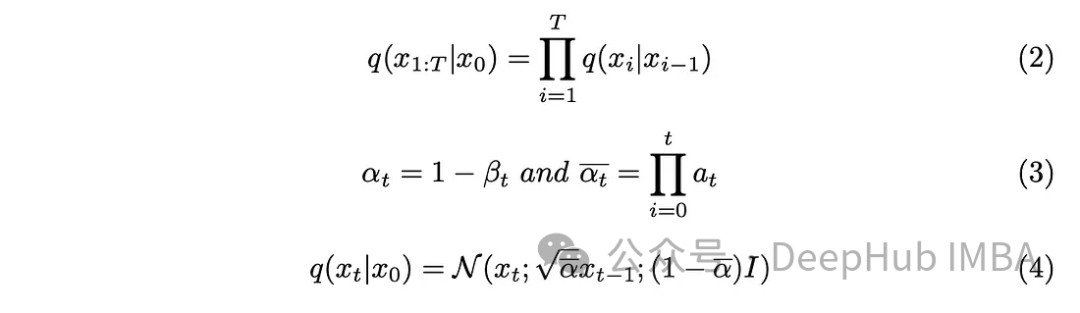
將式(3)中引入的新參數納入式(2)中,對式(2)進行了發展,得到了結果。
我們已經為影像引入了雜訊下一步就是執行逆操作了。除非我們知道初始條件,即t = 0時的未去噪影像,否則無法從數學上實現對影像進行逆向處理去噪。我們的目標是直接從雜訊中採樣以創建新影像,這裡缺乏關於結果的資訊。所以我需要設計一種在不知道結果的情況下逐步去雜訊影像的方法。所以就出現了一個使用深度學習模型來近似這個複雜的數學函數的解。
有了一點數學背景,模型將近似於方程式(5)。一個值得注意的細節是,我們將堅持DDPM原始論文並保持固定的方差,儘管也有可能使模型學習它。
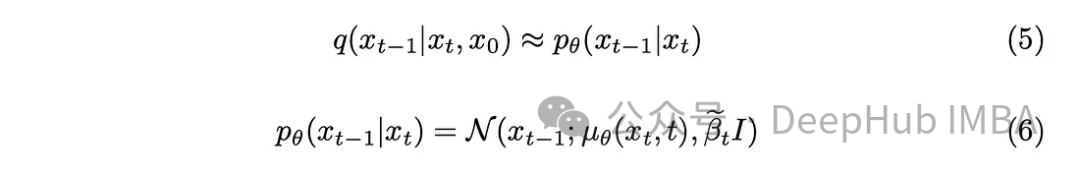
此模型的任務是預測當前時間戳與前一個時間戳記之間所新增的雜訊的平均值。這樣做可以有效去除噪音,達到預期的效果。但是如果我們的目標是讓模型預測從「原始影像」到最後一個時間戳添加的雜訊呢?
除非我們知道沒有雜訊的初始影像,否則在數學上執行逆向過程是具有挑戰性的,讓我們從定義後變異數開始。

模型的任務是預測從初始影像加入時間戳記t的影像的雜訊。正向過程使我們能夠執行這個操作,從一個清晰的圖像開始,並在時間戳t處進展到一個有雜訊的影像。
我們假設用於進行預測的模型體系結構將會是一個U-Net。訓練階段的目標是:對於資料集中的每個影像,在[0,T]範圍內隨機選擇一個時間戳,並計算正向擴散過程。這產生了一個清晰的,有點雜訊的影像,以及實際使用的雜訊。然後利用我們對逆向過程的理解,使用該模型來預測添加到圖像中的雜訊。有了真實的和預測的噪音,我們似乎已經進入了一個有監督的機器學習問題。
最主要的問題來了,我們應該用哪個損失函數來訓練我們的模型呢?由於處理的是機率潛在空間,Kullback-Leibler (KL)散度是一個合適的選擇。
KL散度衡量兩個機率分佈之間的差異,在我們的例子中,是模型預測的分佈和期望分佈。在損失函數中加入KL散度不僅可以指導模型產生準確的預測,還可以確保潛在空間表示符合期望的機率結構。
KL散度可以近似為L2損失函數,所以可以得到以下損失函數:
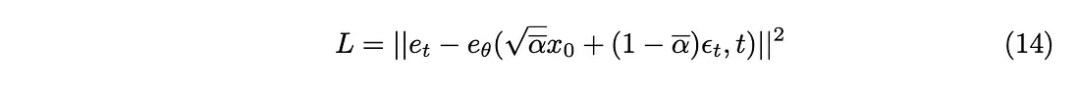
##最終我們得到了論文中提出的訓練演算法。

逆向流程已經解釋完成了,以下就是如何使用了。從時刻T的一個完全隨機的圖像開始,並使用逆向過程T次,最終到達時刻0。這構成了本文中概述的第二個演算法

##我們有很多不同的參數beta,beta_tildes,alpha, alpha_hat 等等。目前都不知道如何選擇這些參數。但此時已知的唯一參數是T,它被設定為1000。
對於所有列出的參數,它們的選擇取決於beta。從某種意義上說,Beta決定了我們要在每一步中添加的噪音量。因此,為了確保演算法的成功,仔細選擇beta是至關重要的。其他的參數因為太多,請參考論文。
在原始論文的實驗階段探索了各種抽樣方法。最初的線性取樣方法影像要麼接收到的雜訊不足,要麼變得過於嘈雜。為了解決這個問題,採用了另一種更常用的方法,即餘弦取樣。餘弦取樣提供了更平滑和更一致的雜訊添加。
我們將利用U-Net架構進行雜訊預測,之所以選擇U-Net,是因為U-Net是影像處理、擷取空間和特徵地圖以及提供與輸入相同的輸出大小的理想架構。
考慮到任務的複雜性和對每一步使用相同模型的要求(其中模型需要能夠以相同的權重去噪完全有噪聲的影像和稍微有雜訊的影像),調整模型是不可或缺的。這包括合併更複雜的區塊,並透過正弦嵌入步驟引入對所用時間戳的感知。這些增強的目的是使模型成為去噪任務的專家。在繼續建立完整的模型之前,我們將介紹每個區塊。
為了滿足提高模型複雜度的需要,卷積塊起著至關重要的作用。這裡不能只依賴u-net論文中的基本區塊,我們將結合ConvNext。
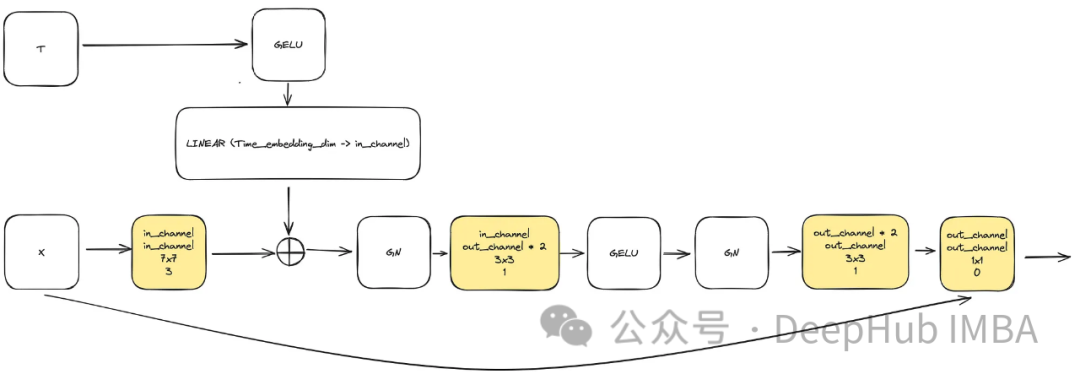
輸入由代表圖像的「x」和大小為「time_embedding_dim」的嵌入的時間戳記可視化「t」組成。由於區塊的複雜性以及與輸入和最後一層的殘差連接,在整個過程中,區塊在學習空間和特徵映射方面起著關鍵作用。
class ConvNextBlock(nn.Module):def __init__(self,in_channels,out_channels,mult=2,time_embedding_dim=None,norm=True,group=8,):super().__init__()self.mlp = (nn.Sequential(nn.GELU(), nn.Linear(time_embedding_dim, in_channels))if time_embedding_dimelse None) self.in_conv = nn.Conv2d(in_channels, in_channels, 7, padding=3, groups=in_channels) self.block = nn.Sequential(nn.GroupNorm(1, in_channels) if norm else nn.Identity(),nn.Conv2d(in_channels, out_channels * mult, 3, padding=1),nn.GELU(),nn.GroupNorm(1, out_channels * mult),nn.Conv2d(out_channels * mult, out_channels, 3, padding=1),) self.residual_conv = (nn.Conv2d(in_channels, out_channels, 1)if in_channels != out_channelselse nn.Identity()) def forward(self, x, time_embedding=None):h = self.in_conv(x)if self.mlp is not None and time_embedding is not None:assert self.mlp is not None, "MLP is None"h = h + rearrange(self.mlp(time_embedding), "b c -> b c 1 1")h = self.block(h)return h + self.residual_conv(x)
模型中的關鍵區塊之一是正弦時間戳嵌入區塊,它使給定時間戳的編碼能夠保留關於模型解碼所需的當前時間的信息,因為該模型將用於所有不同的時間戳記。
這是一個非常經典的是實現,並且應用在各個地方,我們就直接貼程式碼了
class SinusoidalPosEmb(nn.Module):def __init__(self, dim, theta=10000):super().__init__()self.dim = dimself.theta = theta def forward(self, x):device = x.devicehalf_dim = self.dim // 2emb = math.log(self.theta) / (half_dim - 1)emb = torch.exp(torch.arange(half_dim, device=device) * -emb)emb = x[:, None] * emb[None, :]emb = torch.cat((emb.sin(), emb.cos()), dim=-1)return emb
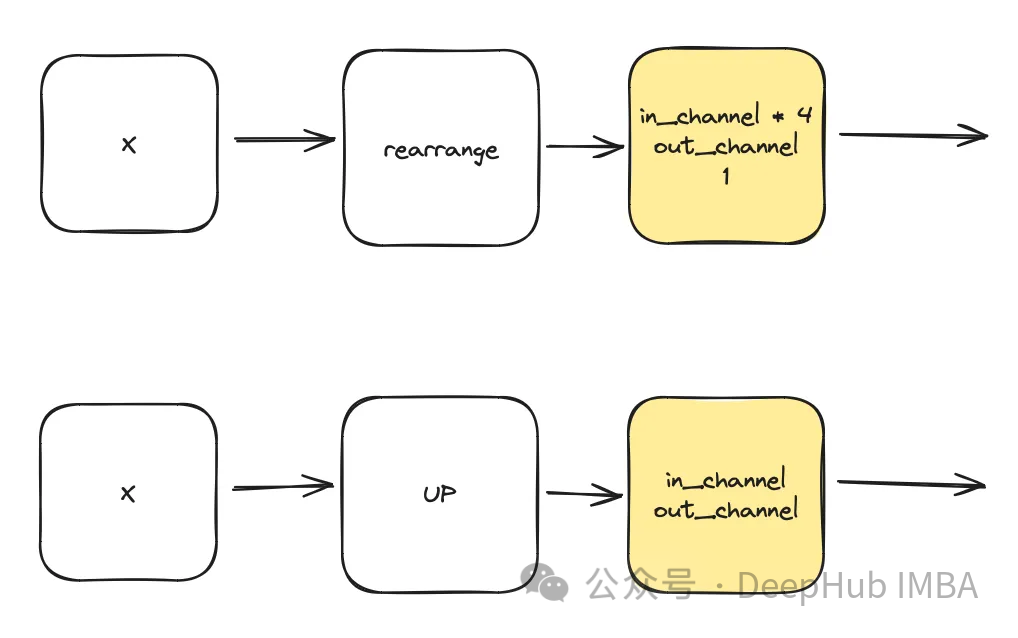
class DownSample(nn.Module):def __init__(self, dim, dim_out=None):super().__init__()self.net = nn.Sequential(Rearrange("b c (h p1) (w p2) -> b (c p1 p2) h w", p1=2, p2=2),nn.Conv2d(dim * 4, default(dim_out, dim), 1),) def forward(self, x):return self.net(x) class Upsample(nn.Module):def __init__(self, dim, dim_out=None):super().__init__()self.net = nn.Sequential(nn.Upsample(scale_factor=2, mode="nearest"),nn.Conv2d(dim, dim_out or dim, kernel_size=3, padding=1),) def forward(self, x):return self.net(x)這個模組利用它來基於給定的時間戳t建立時間表示。這個多層感知器(MLP)的輸出也將作為所有修改過的ConvNext區塊的輸入「t」。

這裡,「dim」是模型的超參數,表示第一個區塊所需的通道數。它作為後續區塊中通道數量的基本計算。
sinu_pos_emb = SinusoidalPosEmb(dim, theta=10000) time_dim = dim * 4 time_mlp = nn.Sequential(sinu_pos_emb,nn.Linear(dim, time_dim),nn.GELU(),nn.Linear(time_dim, time_dim),)
這是unet中使用的可選元件。注意力有助於增強剩餘連結在學習中的作用。它透過殘差連接計算的注意機制和中低潛空間計算的特徵映射,更關注從Unet左側獲得的重要空間資訊。它來自ACC-UNet論文。
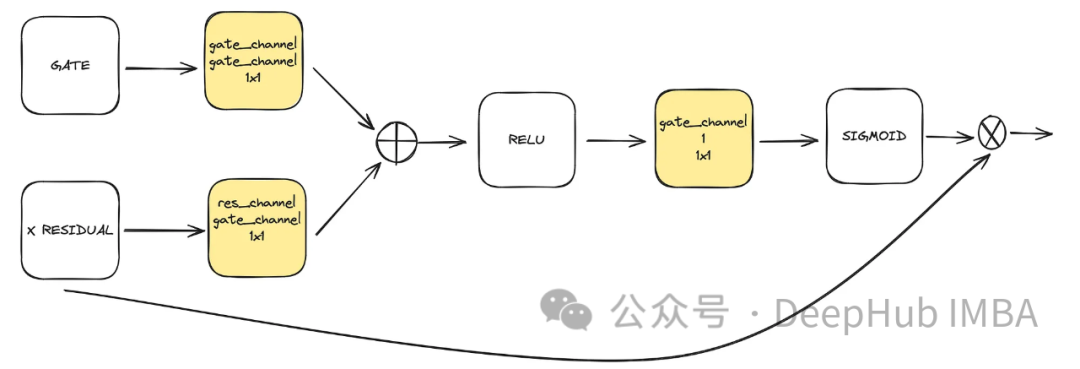
gate 表示下塊的上取樣輸出,而x殘差表示在應用注意的層級上的殘差連接。
class BlockAttention(nn.Module):def __init__(self, gate_in_channel, residual_in_channel, scale_factor):super().__init__()self.gate_conv = nn.Conv2d(gate_in_channel, gate_in_channel, kernel_size=1, stride=1)self.residual_conv = nn.Conv2d(residual_in_channel, gate_in_channel, kernel_size=1, stride=1)self.in_conv = nn.Conv2d(gate_in_channel, 1, kernel_size=1, stride=1)self.relu = nn.ReLU()self.sigmoid = nn.Sigmoid() def forward(self, x: torch.Tensor, g: torch.Tensor) -> torch.Tensor:in_attention = self.relu(self.gate_conv(g) + self.residual_conv(x))in_attention = self.in_conv(in_attention)in_attention = self.sigmoid(in_attention)return in_attention * x
将前面讨论的所有块(不包括注意力块)整合到一个Unet中。每个块都包含两个残差连接,而不是一个。这个修改是为了解决潜在的过度拟合问题。
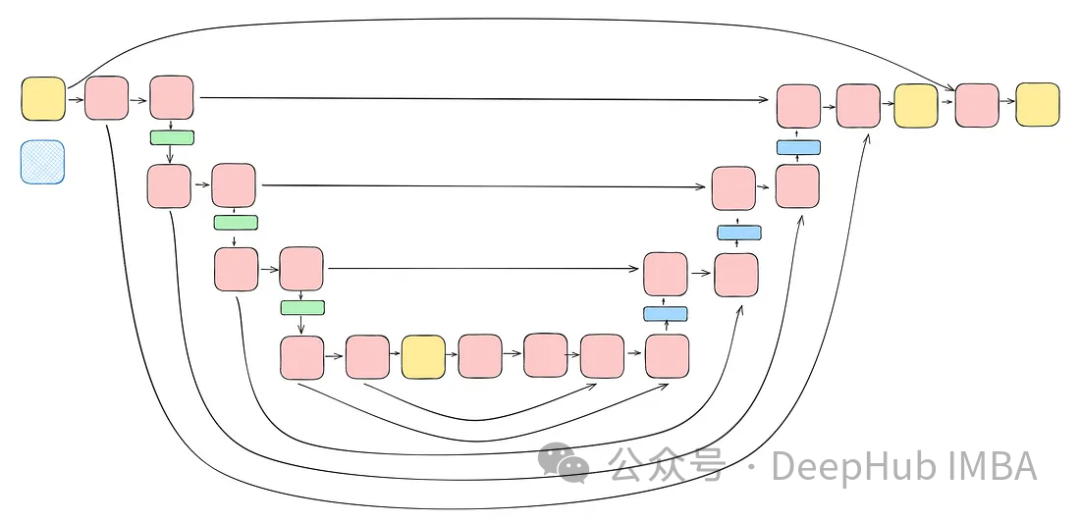
class TwoResUNet(nn.Module):def __init__(self,dim,init_dim=None,out_dim=None,dim_mults=(1, 2, 4, 8),channels=3,sinusoidal_pos_emb_theta=10000,convnext_block_groups=8,):super().__init__()self.channels = channelsinput_channels = channelsself.init_dim = default(init_dim, dim)self.init_conv = nn.Conv2d(input_channels, self.init_dim, 7, padding=3) dims = [self.init_dim, *map(lambda m: dim * m, dim_mults)]in_out = list(zip(dims[:-1], dims[1:])) sinu_pos_emb = SinusoidalPosEmb(dim, theta=sinusoidal_pos_emb_theta) time_dim = dim * 4 self.time_mlp = nn.Sequential(sinu_pos_emb,nn.Linear(dim, time_dim),nn.GELU(),nn.Linear(time_dim, time_dim),) self.downs = nn.ModuleList([])self.ups = nn.ModuleList([])num_resolutions = len(in_out) for ind, (dim_in, dim_out) in enumerate(in_out):is_last = ind >= (num_resolutions - 1) self.downs.append(nn.ModuleList([ConvNextBlock(in_channels=dim_in,out_channels=dim_in,time_embedding_dim=time_dim,group=convnext_block_groups,),ConvNextBlock(in_channels=dim_in,out_channels=dim_in,time_embedding_dim=time_dim,group=convnext_block_groups,),DownSample(dim_in, dim_out)if not is_lastelse nn.Conv2d(dim_in, dim_out, 3, padding=1),])) mid_dim = dims[-1]self.mid_block1 = ConvNextBlock(mid_dim, mid_dim, time_embedding_dim=time_dim)self.mid_block2 = ConvNextBlock(mid_dim, mid_dim, time_embedding_dim=time_dim) for ind, (dim_in, dim_out) in enumerate(reversed(in_out)):is_last = ind == (len(in_out) - 1)is_first = ind == 0 self.ups.append(nn.ModuleList([ConvNextBlock(in_channels=dim_out + dim_in,out_channels=dim_out,time_embedding_dim=time_dim,group=convnext_block_groups,),ConvNextBlock(in_channels=dim_out + dim_in,out_channels=dim_out,time_embedding_dim=time_dim,group=convnext_block_groups,),Upsample(dim_out, dim_in)if not is_lastelse nn.Conv2d(dim_out, dim_in, 3, padding=1)])) default_out_dim = channelsself.out_dim = default(out_dim, default_out_dim) self.final_res_block = ConvNextBlock(dim * 2, dim, time_embedding_dim=time_dim)self.final_conv = nn.Conv2d(dim, self.out_dim, 1) def forward(self, x, time):b, _, h, w = x.shapex = self.init_conv(x)r = x.clone() t = self.time_mlp(time) unet_stack = []for down1, down2, downsample in self.downs:x = down1(x, t)unet_stack.append(x)x = down2(x, t)unet_stack.append(x)x = downsample(x) x = self.mid_block1(x, t)x = self.mid_block2(x, t) for up1, up2, upsample in self.ups:x = torch.cat((x, unet_stack.pop()), dim=1)x = up1(x, t)x = torch.cat((x, unet_stack.pop()), dim=1)x = up2(x, t)x = upsample(x) x = torch.cat((x, r), dim=1)x = self.final_res_block(x, t) return self.final_conv(x)
最后我们介绍一下扩散是如何实现的。由于我们已经介绍了用于正向、逆向和采样过程的所有数学理论,所里这里将重点介绍代码。
class DiffusionModel(nn.Module):SCHEDULER_MAPPING = {"linear": linear_beta_schedule,"cosine": cosine_beta_schedule,"sigmoid": sigmoid_beta_schedule,} def __init__(self,model: nn.Module,image_size: int,*,beta_scheduler: str = "linear",timesteps: int = 1000,schedule_fn_kwargs: dict | None = None,auto_normalize: bool = True,) -> None:super().__init__()self.model = model self.channels = self.model.channelsself.image_size = image_size self.beta_scheduler_fn = self.SCHEDULER_MAPPING.get(beta_scheduler)if self.beta_scheduler_fn is None:raise ValueError(f"unknown beta schedule {beta_scheduler}") if schedule_fn_kwargs is None:schedule_fn_kwargs = {} betas = self.beta_scheduler_fn(timesteps, **schedule_fn_kwargs)alphas = 1.0 - betasalphas_cumprod = torch.cumprod(alphas, dim=0)alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)posterior_variance = (betas * (1.0 - alphas_cumprod_prev) / (1.0 - alphas_cumprod)) register_buffer = lambda name, val: self.register_buffer(name, val.to(torch.float32)) register_buffer("betas", betas)register_buffer("alphas_cumprod", alphas_cumprod)register_buffer("alphas_cumprod_prev", alphas_cumprod_prev)register_buffer("sqrt_recip_alphas", torch.sqrt(1.0 / alphas))register_buffer("sqrt_alphas_cumprod", torch.sqrt(alphas_cumprod))register_buffer("sqrt_one_minus_alphas_cumprod", torch.sqrt(1.0 - alphas_cumprod))register_buffer("posterior_variance", posterior_variance) timesteps, *_ = betas.shapeself.num_timesteps = int(timesteps) self.sampling_timesteps = timesteps self.normalize = normalize_to_neg_one_to_one if auto_normalize else identityself.unnormalize = unnormalize_to_zero_to_one if auto_normalize else identity @torch.inference_mode()def p_sample(self, x: torch.Tensor, timestamp: int) -> torch.Tensor:b, *_, device = *x.shape, x.devicebatched_timestamps = torch.full((b,), timestamp, device=device, dtype=torch.long) preds = self.model(x, batched_timestamps) betas_t = extract(self.betas, batched_timestamps, x.shape)sqrt_recip_alphas_t = extract(self.sqrt_recip_alphas, batched_timestamps, x.shape)sqrt_one_minus_alphas_cumprod_t = extract(self.sqrt_one_minus_alphas_cumprod, batched_timestamps, x.shape) predicted_mean = sqrt_recip_alphas_t * (x - betas_t * preds / sqrt_one_minus_alphas_cumprod_t) if timestamp == 0:return predicted_meanelse:posterior_variance = extract(self.posterior_variance, batched_timestamps, x.shape)noise = torch.randn_like(x)return predicted_mean + torch.sqrt(posterior_variance) * noise @torch.inference_mode()def p_sample_loop(self, shape: tuple, return_all_timesteps: bool = False) -> torch.Tensor:batch, device = shape[0], "mps" img = torch.randn(shape, device=device)# This cause me a RunTimeError on MPS device due to MPS back out of memory# No ideas how to resolve it at this point # imgs = [img] for t in tqdm(reversed(range(0, self.num_timesteps)), total=self.num_timesteps):img = self.p_sample(img, t)# imgs.append(img) ret = img # if not return_all_timesteps else torch.stack(imgs, dim=1) ret = self.unnormalize(ret)return ret def sample(self, batch_size: int = 16, return_all_timesteps: bool = False) -> torch.Tensor:shape = (batch_size, self.channels, self.image_size, self.image_size)return self.p_sample_loop(shape, return_all_timesteps=return_all_timesteps) def q_sample(self, x_start: torch.Tensor, t: int, noise: torch.Tensor = None) -> torch.Tensor:if noise is None:noise = torch.randn_like(x_start) sqrt_alphas_cumprod_t = extract(self.sqrt_alphas_cumprod, t, x_start.shape)sqrt_one_minus_alphas_cumprod_t = extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise def p_loss(self,x_start: torch.Tensor,t: int,noise: torch.Tensor = None,loss_type: str = "l2",) -> torch.Tensor:if noise is None:noise = torch.randn_like(x_start)x_noised = self.q_sample(x_start, t, noise=noise)predicted_noise = self.model(x_noised, t) if loss_type == "l2":loss = F.mse_loss(noise, predicted_noise)elif loss_type == "l1":loss = F.l1_loss(noise, predicted_noise)else:raise ValueError(f"unknown loss type {loss_type}")return loss def forward(self, x: torch.Tensor) -> torch.Tensor:b, c, h, w, device, img_size = *x.shape, x.device, self.image_sizeassert h == w == img_size, f"image size must be {img_size}" timestamp = torch.randint(0, self.num_timesteps, (1,)).long().to(device)x = self.normalize(x)return self.p_loss(x, timestamp)扩散过程是训练部分的模型。它打开了一个采样接口,允许我们使用已经训练好的模型生成样本。
对于训练部分,我们设置了37,000步的训练,每步16个批次。由于GPU内存分配限制,图像大小被限制为128x128。使用指数移动平均(EMA)模型权重每1000步生成样本以平滑采样,并保存模型版本。
在最初的1000步训练中,模型开始捕捉一些特征,但仍然错过了某些区域。在10000步左右,这个模型开始产生有希望的结果,进步变得更加明显。在3万步的最后,结果的质量显著提高,但仍然存在黑色图像。这只是因为模型没有足够的样本种类,真实图像的数据分布并没有完全映射到高斯分布。

有了最终的模型权重,我们可以生成一些图片。尽管由于128x128的尺寸限制,图像质量受到限制,但该模型的表现还是不错的。

注:本文使用的数据集是森林地形的卫星图片,具体获取方式请参考源代码中的ETL部分。
我们已经完整的介绍了有关扩散模型的必要知识,并且使用Pytorch进行了完整的实现,本文的代码:
https://github.com/Camaltra/this-is-not-real-aerial-imagery/
以上是用PyTorch實現雜訊去除擴散模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















