

影片場景圖產生(VidSGG)旨在識別視覺場景中的物件並推斷它們之間的視覺關係。
該任務不僅需要全面了解分散在整個場景中的每個對象,還需要深入研究它們在時序上的運動和互動。
最近,來自中山大學的研究人員在人工智慧頂尖期刊IEEE T-IP上發表了一篇論文,進行了相關任務的探索並發現:每對物體組合及其它們之間的關係在每個影像內具有空間共現相關性,並且在不同影像之間具有時間一致性/轉換相關性。

論文連結:https://arxiv.org/abs/2309.13237
基於這些先驗知識,研究人員提出了一種基於時空知識嵌入的Transformer(STKET)將先驗時空知識納入多頭交叉注意機制中,從而學習更多有代表性的視覺關係表示。
具體來說,首先以統計方式學習空間共現和時間轉換相關性;然後,設計了時空知識嵌入層對視覺表示與知識之間的交互進行充分探索,分別產生空間和時間知識嵌入的視覺關係表示;最後,作者聚合這些特徵,以預測最終的語義標籤及其視覺關係。
大量實驗表明,文中提出的框架大幅優於當前競爭演算法。目前,該論文已經被接收。
隨著場景理解領域的快速發展,許多研究者開始嘗試利用各種框架來解決場景圖生成( Scene Graph Generation, SGG)任務,並已取得了不俗的進展。
但是,這些方法往往只考慮單張圖像的情況,忽略了時序中存在的大量的上下文信息,導致現有大部分場景圖生成演算法在無法準確地識別所給定的影片中所包含的動態視覺關係。
因此,許多研究者致力於開發視訊場景圖生成(Video Scene Graph Generation, VidSGG)演算法來解決這個問題。
目前的工作主要關注從空間和時間角度聚合物件層級視覺訊息,以學習對應的視覺關係表示。
然而,由於各類物體與交互動作的視覺外表方差大以及視頻收集所導致的視覺關係顯著的長尾分佈,單純的僅用視覺信息容易導致模型預測錯誤的視覺關係。
針對上述問題,研究者做了以下兩方面的工作:
首先,提出挖掘訓練樣本中包含的先驗時空知識用以促進視訊場景圖生成領域。其中,先驗時空知識包括:
1)空間共現相關性:某些物件類別之間的關係傾向於特定的交互作用。
2)時間一致性/轉換相關性:給定對的關係在連續影片剪輯中往往是一致的,或者很有可能轉換到另一個特定關係。
其次,提出了一個新穎的基於時空知識嵌入的Transformer(Spatial-Temporal Knowledge-Embedded Transformer, STKET)框架。
此框架將先驗時空知識納入多頭交叉注意機制中,從而學習更多代表性的視覺關係表示。根據在測試基準上得到的比較結果可以發現,研究人員所提出的STKET框架優於先前最先進的方法。

圖1:由於視覺外觀多變與視覺關係的長尾分佈,導致影片場景圖產生充滿挑戰
在推論視覺關係時,人類不僅利用視覺線索,也利用累積的先驗知識[1, 2]。受此啟發,研究人員提出直接從訓練集中提取先驗時空知識,以促進視訊場景圖生成任務。
其中,空間共現相關性具體表現為當給定物體組合後其視覺關係分佈將高度傾斜(例如,“人”與“杯子”之間的視覺關係的分佈明顯不同於“狗」與「玩具」之間的分佈)和時間轉移相關性具體表現為當給定前一時刻的視覺關係後各個視覺關係的轉換機率將大幅變化(例如,當已知前一時刻的視覺關係為「吃」時,下一時刻視覺關係轉移為「書寫」的機率大幅下降)。
如圖2所示,可以直觀地感受到給定物體組合或先前的視覺關係後,預測空間可以被大幅的縮減。
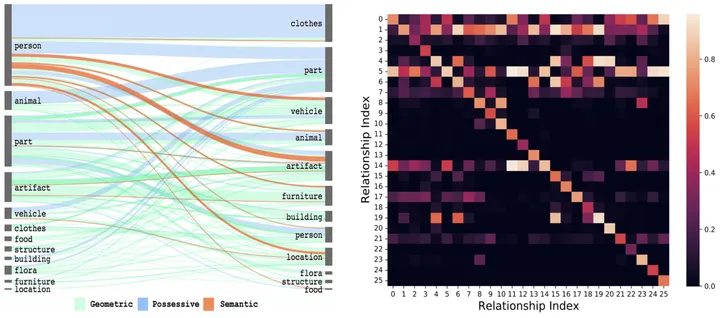
圖2:視覺關係的空間共現機率[3]與時間轉移機率
具體而言,對於第i類物體與第j類物體的組合,以及其上一時刻為第x類關係的情況,首先透過統計的方式獲得其對應的空間共現機率矩陣E^{i,j }和時間轉移機率矩陣Ex^{i,j}。
接著,將其輸入到全連接層中得到對應的特徵表示,並利用對應的目標函數確保模型所學到的知識表示包含對應的先驗時空知識。
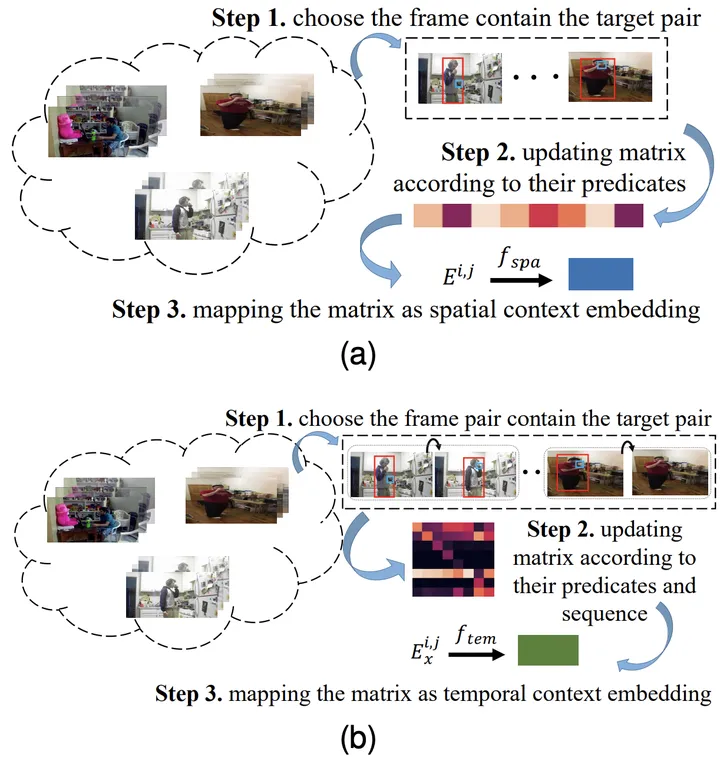
圖3:學習空間(a)與時間(b)知識表示的過程
##知識嵌入註意力層空間知識通常包含實體之間的位置、距離和關係的資訊。另一方面,時間知識涉及動作之間的順序、持續時間和間隔。
鑑於它們獨特的屬性,單獨處理它們可以允許專門的建模更準確地捕捉固有模式。
因此,研究者設計了時空知識嵌入層,徹底探索視覺表示與時空知識之間的互動。
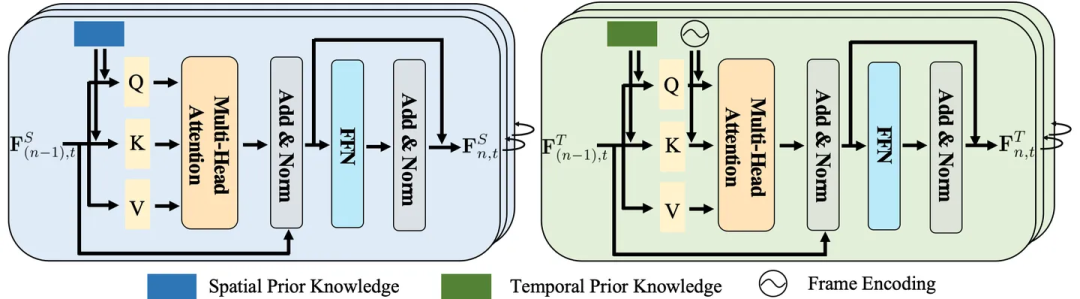
圖4:空間(左邊)與時間(右邊)知識嵌入層
時空聚合模組如前所述,空間知識嵌入層探索每個影像內的空間共現相關性,時間知識嵌入層探索不同影像之間的時間轉移相關性,以此充分探索了視覺表示和時空知識之間的互動。
儘管如此,這兩層忽略了長時序的上下文訊息,而這對於識別大部分動態變化的視覺關係具有幫助。
為此,研究人員進一步設計了時空聚合(STA)模組來聚合每個物件對的這些表示,以預測最終的語義標籤及其關係。它將不同幀中相同主客體對的空間和時間嵌入關係表示作為輸入。
具體來說,研究人員將相同物件對的這些表示連接起來以產生上下文表示。
然後,為了在不同幀中找到相同的主客體對,採用預測的物件標籤和IoU(即並集交集)來匹配幀中檢測到的相同主客體對。
最後,考慮到影格中的關係在不同批次中有不同的表示,選擇滑動視窗中最早出現的表示。
實驗結果為了全面評估所提出的框架的效能,研究人員除了比較現有的影片場景圖生成方法(STTran , TPI, APT)外,也選取了先進的影像場景圖產生方法(KERN, VCTREE, ReIDN, GPS-Net)進行比較。
其中,為確保對比的公平,影像場景圖產生方法透過對每個畫面影像進行識別,從而達到對所給定影片產生對應場景圖的目標。
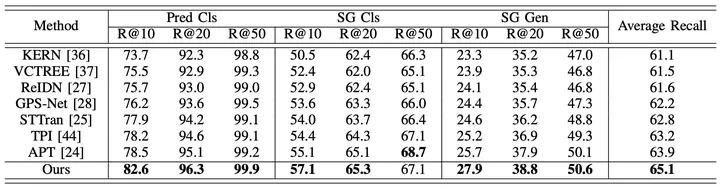
圖5:在Action Genome資料集上以Recall為評價指標的實驗結果

圖6:在Action Genome資料集上以mean Recall為評估指標的實驗結果
#以上是中山大學的全新時空知識嵌入框架推動了視訊場景圖生成任務的最新進展,發表於 TIP '24的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















