


19世紀是印象主義藝術運動盛行的時期,該運動在繪畫、雕塑、版畫等藝術領域都有影響力。印象主義的特徵是使用短小、斷斷續續的筆觸,幾乎不追求形式的精準,這後來演變為印象派藝術風格。簡言之,印象派藝術家的筆觸沒有經過修飾,呈現出明顯的特點,不追求形式的精確度,甚至有些模糊。印象派藝術家將光與色的科學概念引入繪畫中,革新了傳統的色彩觀念。
在D3GA中,作者有一個與眾不同的目標,他希望透過反其道而行的方式創造出逼真如照片般的表現效果。為了實現這一目標,作者在D3GA中創造性地運用了高斯潑濺(Gaussian Splatting)技術,將其作為一種現代化的“段筆觸”,用來構建虛擬角色的結構和外觀,並實現實時穩定的效果。

《日出·印象》是著名的印象派畫家莫內的代表作品。

為了創造可生成動畫新內容的逼真人類形象,虛擬形象的建構工作目前需要大量的多視角數據。這是因為單目方法的準確性有限。此外,現有的技術還需要進行複雜的預處理,包括準確的3D配準。然而,要取得這些配準資料需要迭代,並且很難整合到端到端的流程中。 另外,還有一些不需要準確配準的方法,它們是基於神經輻射場(NeRFs)。然而,這些方法通常在即時渲染方面速度較慢,或者在服裝動畫方面有困難。
Kerbl等人提出了一種名為3D Gaussian Splatting(3DGS)的渲染方法,它在經典的Surface Splatting渲染方法的基礎上進行了改進。與基於神經輻射場的最先進方法相比,3DGS能夠以更快的幀率呈現更高品質的影像,而且無需進行高度準確的3D初始化。
然而,3DGS最初是為靜態場景設計的。目前已經有人提出了基於時間條件的高斯噴灑(Gaussian Splatting)方法,可以用來渲染動態場景。這種方法只能回放先前觀察到的內容,因此不適用於表達新的或以前未見過的運動。
在驅動型的神經輻射場的基礎上,作者對3D 的人類的外觀及變形進行建模,將其放置在一個規範化的空間中,但使用3D 高斯而不是輻射場。除性能更好以外,Gaussian Splatting 還不需要使用相機射線採樣啟發式方法。
剩下的問題是定義觸發這些 cage 變形的訊號。目前在驅動型的虛擬角色中的最新技術需要密集的輸入訊號,如 RGB-D 影像甚至是多鏡頭,但這些方法可能不適用於傳輸頻寬比較低的情況。在本研究中,作者採用基於人體姿勢的更緊湊輸入,包括以四元數形式的骨骼關節角度和 3D 面部關鍵點。
透過在九個高品質的多視圖序列上訓練個體特定的模型,涵蓋各種身體形狀、動作和服裝(不僅限於貼身服裝),以後我們就可以通過任何主體的新姿勢對人物進行驅動了。
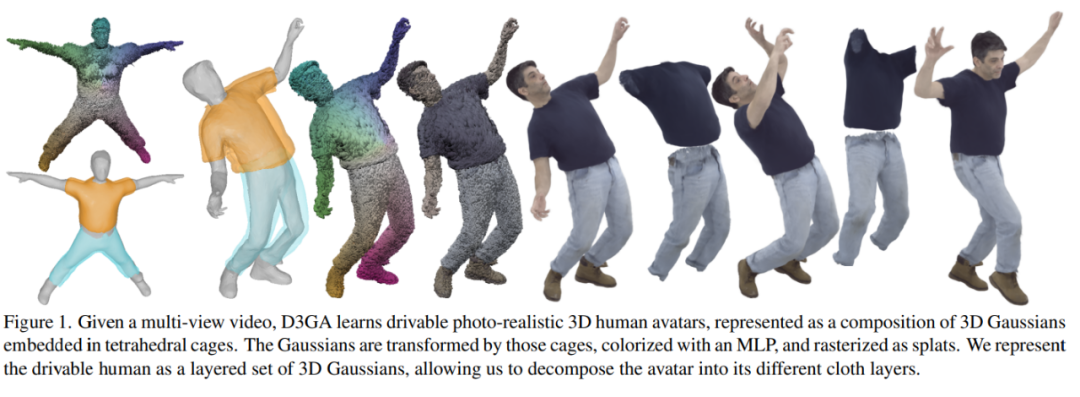


#目前用於動態體積化虛擬角色的方法要么將點從變形空間映射到規範空間,要么僅依賴正向映射。基於反向映射的方法往往在規範空間中累積誤差,因為它們需要一個容易出錯的反向傳遞,並且在建模視角相關效果時存在問題。
因此,作者決定採用僅正向映射的方法。 D3GA 是基於 3DGS 的基礎上透過神經表示和 cage 進行擴展,分別對虛擬角色的每個動態部分的顏色和幾何形狀進行建模。
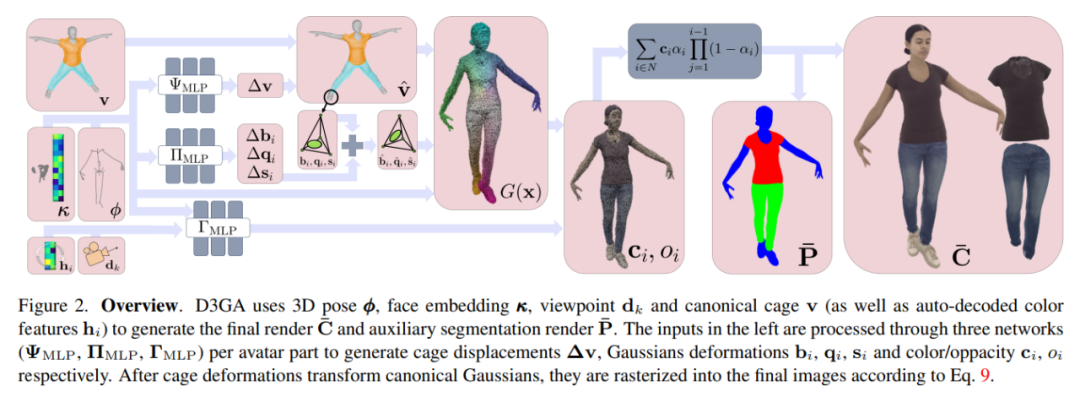
D3GA 使用3D 姿勢ϕ、臉部嵌入κ、視點dk 和規範cage v(以及自動解碼的顏色特徵hi)來產生最終的渲染C¯ 和輔助分割渲染P¯。左側的輸入透過每個虛擬角色部分的三個網路(ΨMLP、ΠMLP、ΓMLP)進行處理,以產生 cage 位移∆v、高斯變形 bi、qi、si 以及顏色 / 透明度 ci、oi。
在 cage 變形將規範高斯變形後,透過方程式 9,它們被光柵化成最終的影像。
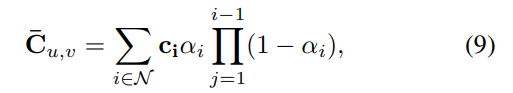
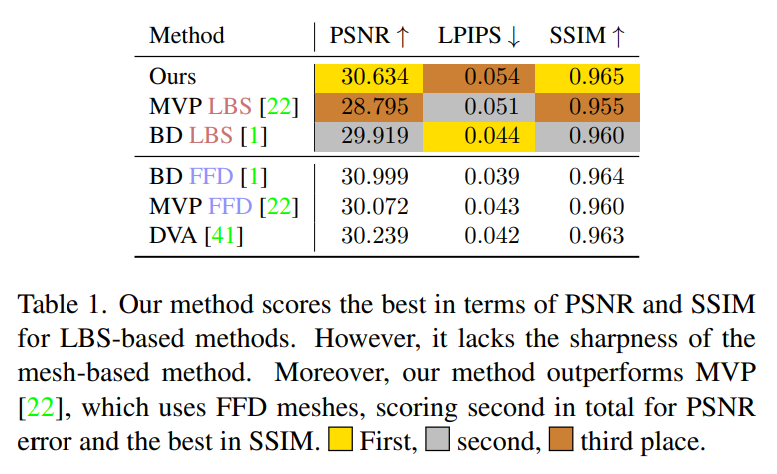
#D3GA 在SSIM、PSNR 和知覺度量LPIPS等指標上進行評估。表1 顯示,D3GA 在只使用LBS 的方法中(即不需要為每個幀掃描3D 數據)其在PSNR 和SSIM 上的表現是最佳的,並在這些指標中勝過所有FFD 方法,僅次於於BD FFD,儘管其訓練訊號較差且沒有測試影像(DVA 是使用所有200 台攝影機進行測試的)。
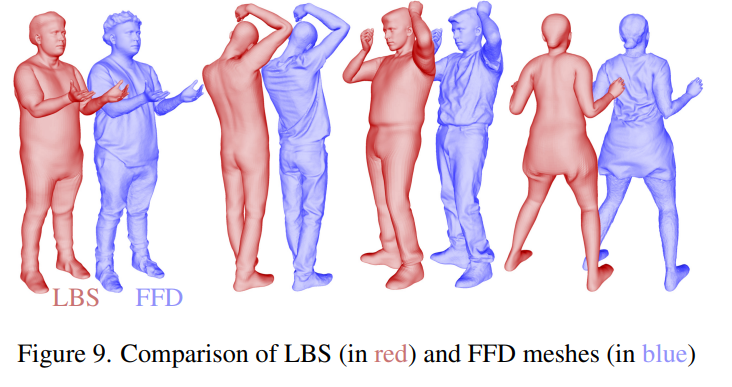
定性比較顯示,與其它最先進方法相比,D3GA 能更好地建模服裝,特別是像裙子或運動褲這樣的寬鬆服裝(圖4)。 FFD 代表自由形變網格,其包含比 LBS 網格更豐富的訓練訊號 (圖 9)。

#與其基於體積方法相比,作者的方法可以將虛擬角色的服裝分離出來,並且服裝也是可驅動的。圖 5 顯示了每個單獨的服裝層,可以僅透過骨骼關節角度控制,而不需要特定的服裝配準模組。

以上是AI研究也能藉鏡印象派?這些栩栩如生的人竟然是3D模型的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















