

OpenAI GPT-4V 和 Google Gemini 都展現了非常強的多模態理解能力,推動了多模態大模型(MLLM)快速發展,MLLM 成為了現在業界最熱的研究方向。
MLLM 在多種視覺-語言開放任務中取得了出色的指令跟隨能力。儘管過去多模態學習的研究顯示不同模態之間能夠相互協同和促進,但是現有的MLLM 的研究主要關注提升多模態任務的能力,如何平衡模態協作的收益與模態幹擾的影響仍然是亟待解決的重要問題。

請點擊以下連結查看論文:https://arxiv.org/pdf/2311.04257.pdf
#請查看以下程式碼位址:https://github.com/X-PLUG/mPLUG-Owl/tree/main/mPLUG-Owl2
ModelScope 體驗位址:https: //modelscope.cn/studios/damo/mPLUG-Owl2/summary
HuggingFace 體驗位址連結:https://huggingface.co/spaces/MAGAer13/mPLUG-Owl2
針對這個問題,阿里巴巴的多模態大模型mPLUG-Owl迎來了一次大升級。透過模態協同的方式,它同時提升了純文字和多模態的性能,超過了LLaVA1.5、MiniGPT4、Qwen-VL等模型,在多種任務中取得了最佳性能。具體來說,mPLUG-Owl2利用共享的功能模組促進了不同模態之間的協作,並引入了模態自適應模組來保留各個模態的特徵。透過簡潔而有效的設計,mPLUG-Owl2在包括純文字和多模態任務在內的多個領域取得了最佳效能。模態協作現象的研究也為未來多模態大模型的發展提供了啟示
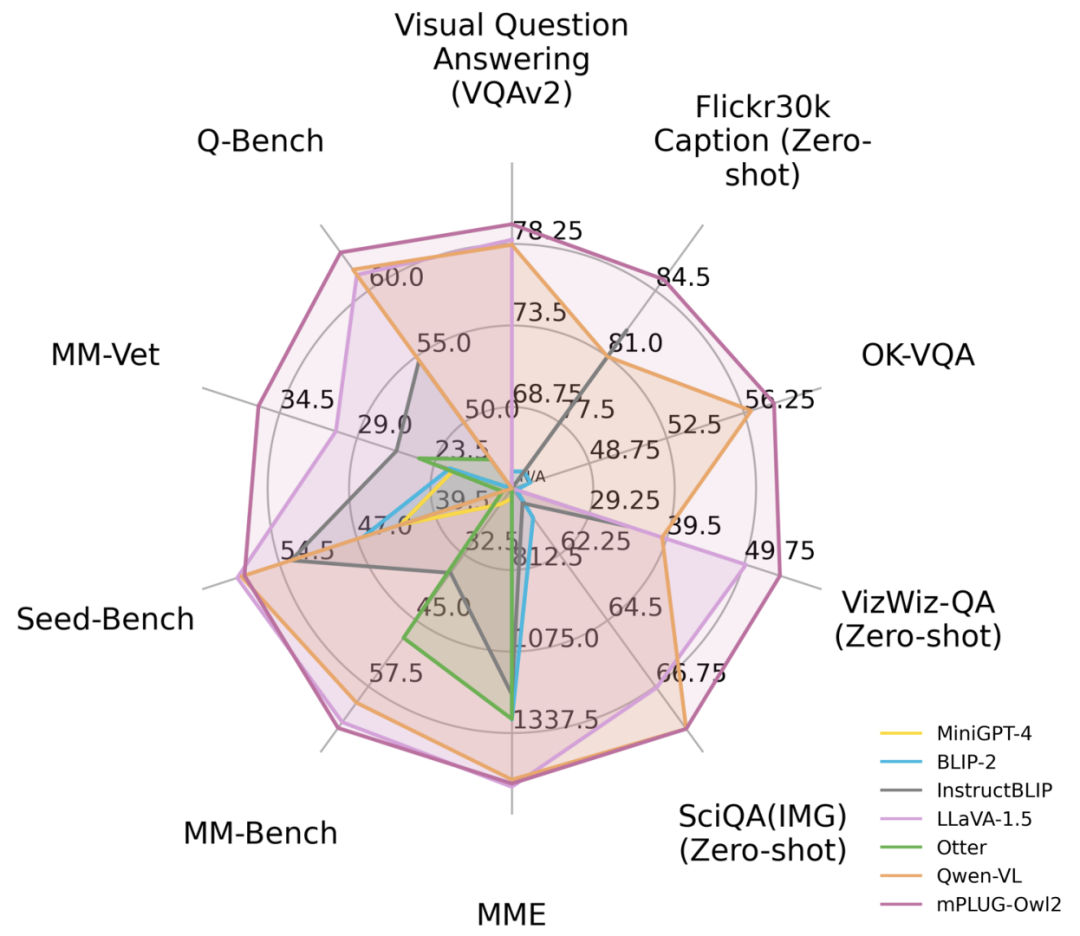
圖1 與現有MLLM 模型效能對比
方法介紹 為了達到不改變原始意思的目的,需要將內容重新寫成中文
mPLUG-Owl2 模型主要包含三個部分:
Visual Encoder:以ViT-L/14 作為視覺編碼器,將輸入的解析度為H x W 的影像,轉換為H/14 x W/14 的視覺tokens 序列,輸入到Visual Abstractor 中。
視覺擷取器:透過學習一組可用的查詢,提取高層次的語意特徵,同時減少輸入語言模型的視覺序列長度
語言模型:使用了LLaMA-2-7B 作為文字解碼器,並設計如圖3 所示的模態自適應模組。
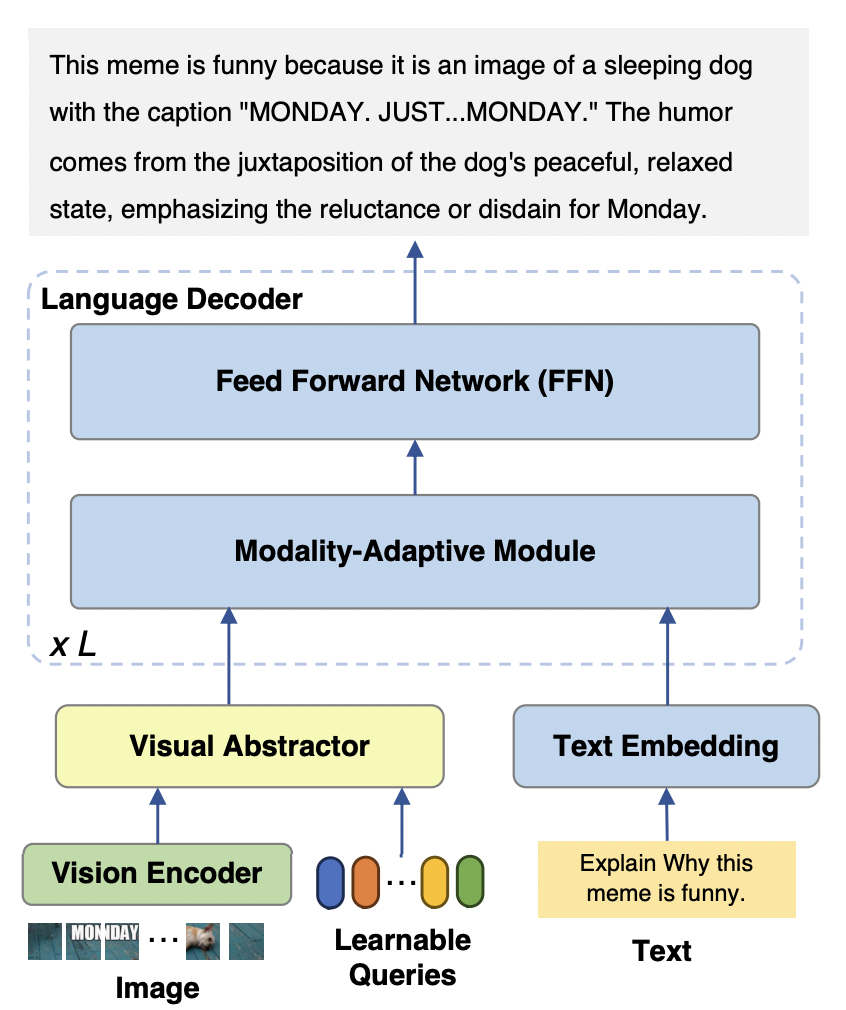
圖2 mPLUG-Owl2 模型結構
為了對齊視覺和語言模態,現有的工作通常是將視覺特徵映射到文本的語義空間中,然而這樣的做法忽視了視覺和文本信息各自的特性,可能由於語義粒度的不匹配影響模型的性能。為了解決這個問題,本文提出模態自適應模組(Modality-adaptive Module, MAM),將視覺和文字特徵映射到共享的語義空間,同時解耦視覺- 語言表徵以保留模態各自的獨特屬性。
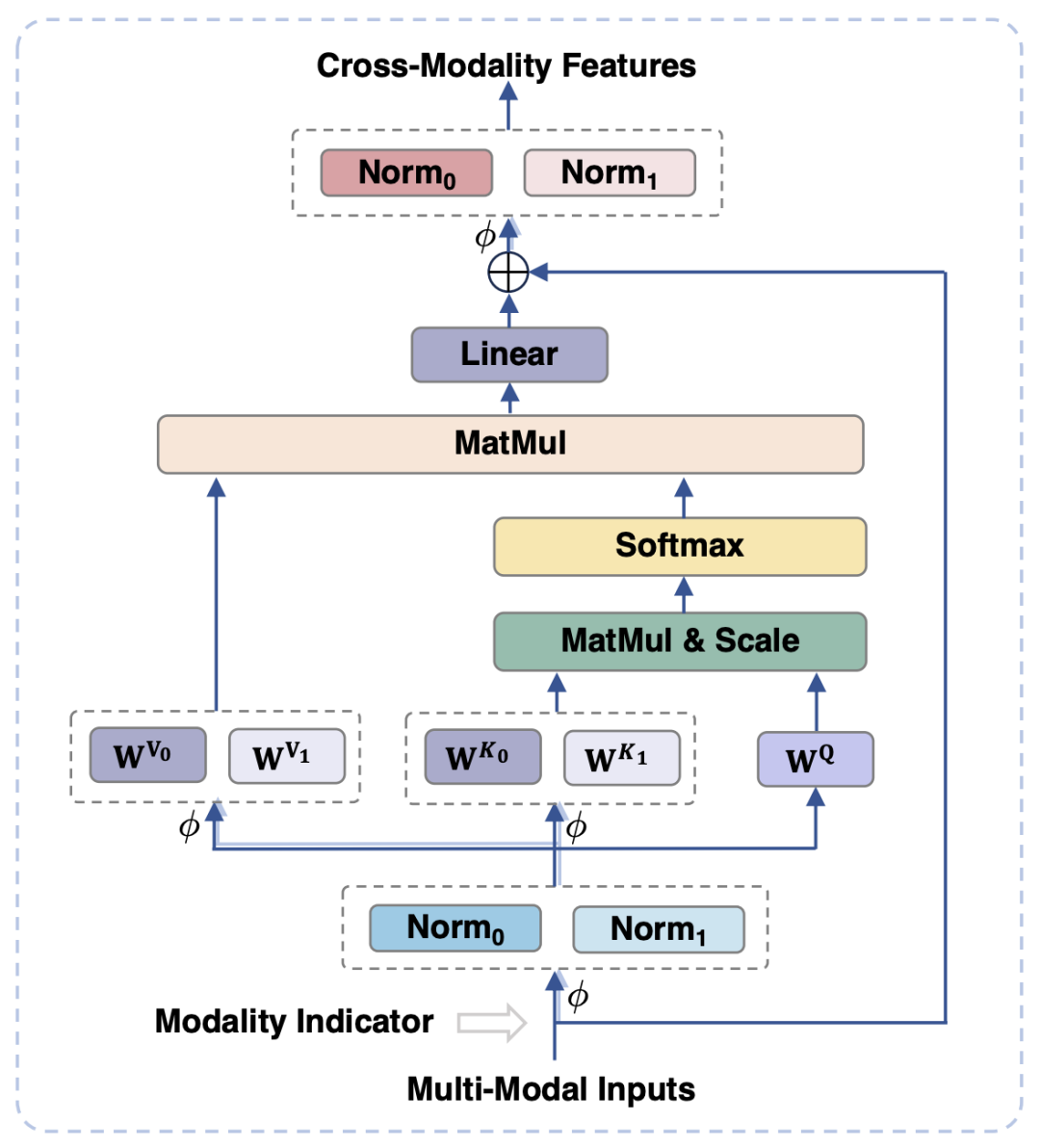
圖3 展示了模態自適應模組的示意圖
在圖3中顯示的是,與傳統的Transformer相比,模態自適應模組的主要設計在於:
#在模組的輸入、輸出階段,分別對視覺和語言模態進行LayerNorm 操作,以適應兩種模態各自的特徵分佈。
在自註意力操作中,對視覺和語言模態採用分離的key 和value 投影矩陣,但採用共享的query 投影矩陣,透過這樣解耦key 和value 投影矩陣,能夠在語意粒度不匹配的情況下,避免兩種模態之間的干擾。
透過共享相同的FFN,兩個模態可以促進彼此之間的協作
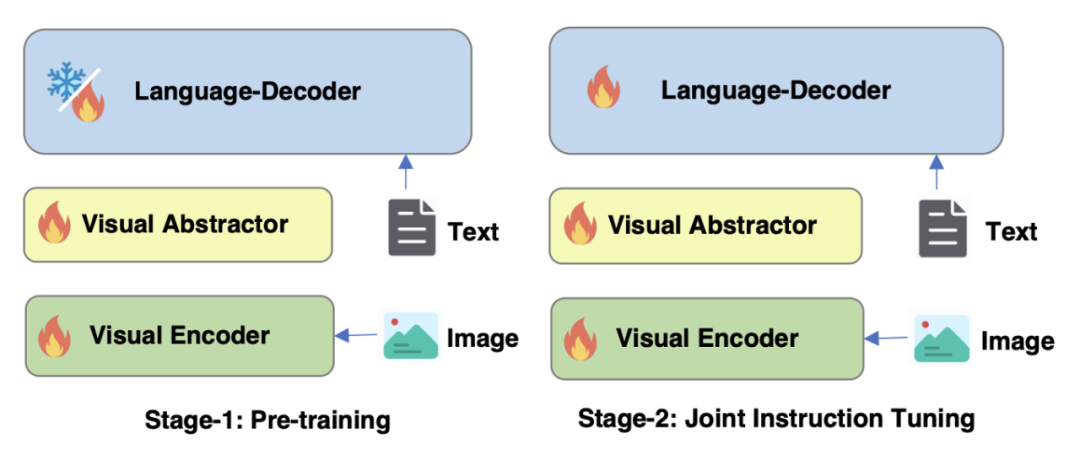
#對於圖4 mPLUG-Owl2的訓練策略進行最佳化
#如圖 4 所示,mPLUG-Owl2 的訓練包含預訓練和指令微調兩個階段。預訓練階段主要是為了實現視覺編碼器和語言模型的對齊,在這個階段,Visual Encoder、Visual Abstractor 都是可訓練的,語言模型中則只對Modality Adaptive Module 新增的視覺相關的模型權重進行更新。在指令微調階段,結合文字和多模態指令資料(如圖 5 所示)對模型的全部參數進行微調,以提升模型的指令跟隨能力。
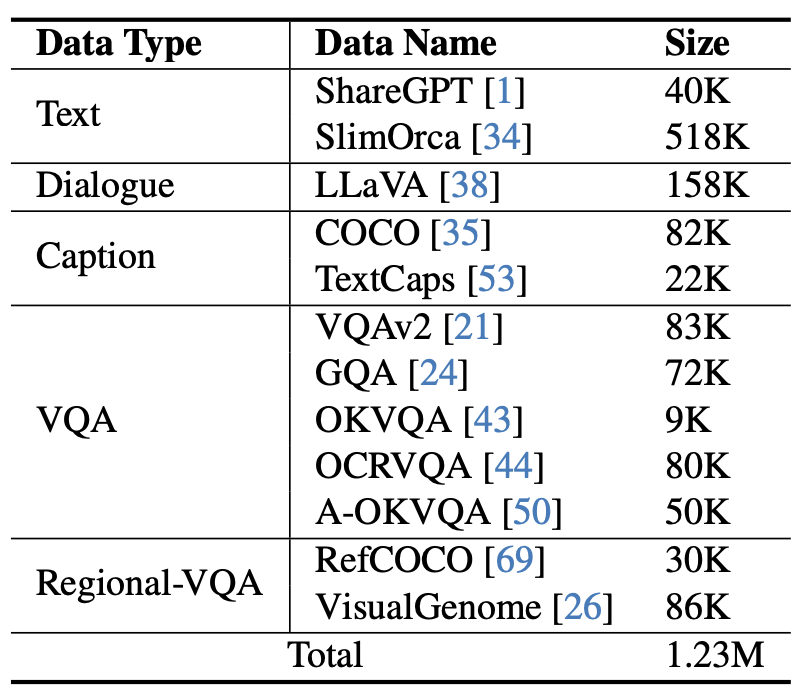
圖5 mPLUG-Owl2 使用的指令微調資料
實驗及結果
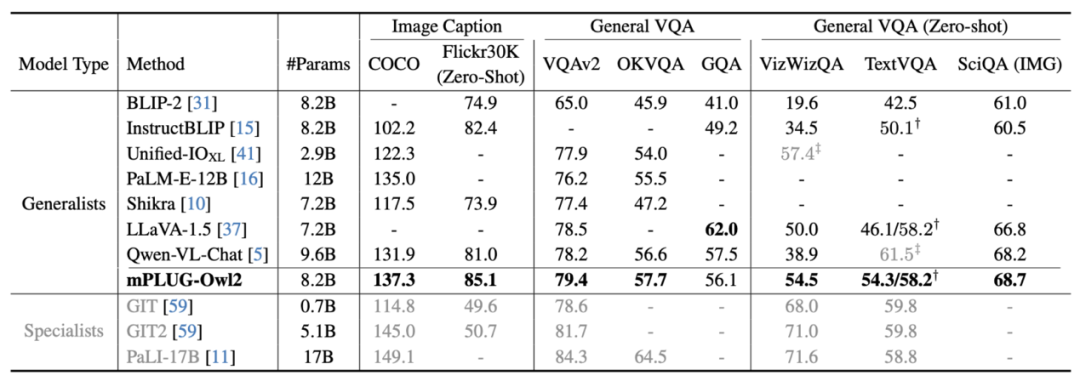
#圖6 圖片描述與VQA 任務效能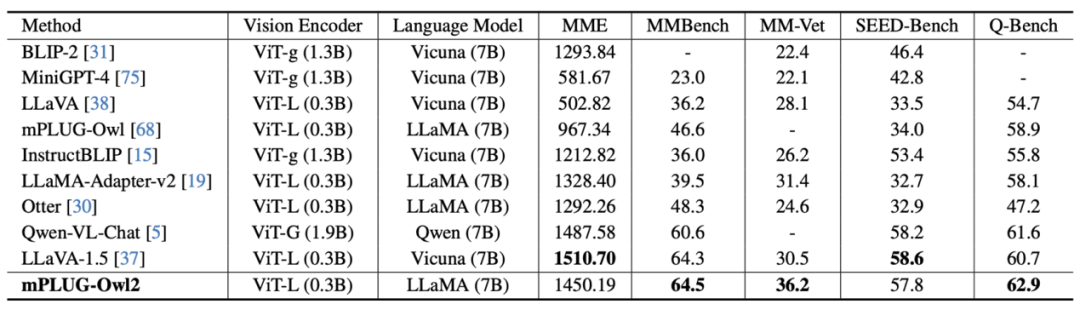
圖7 MLLM 基準測試表現
如圖6、圖7 所示,無論是傳統的影像描述、VQA 等視覺- 語言任務,或是MMBench、Q-Bench 等在面向多模態大模型的基準資料集上,mPLUG-Owl2 都取得了優於現有工作的效能。
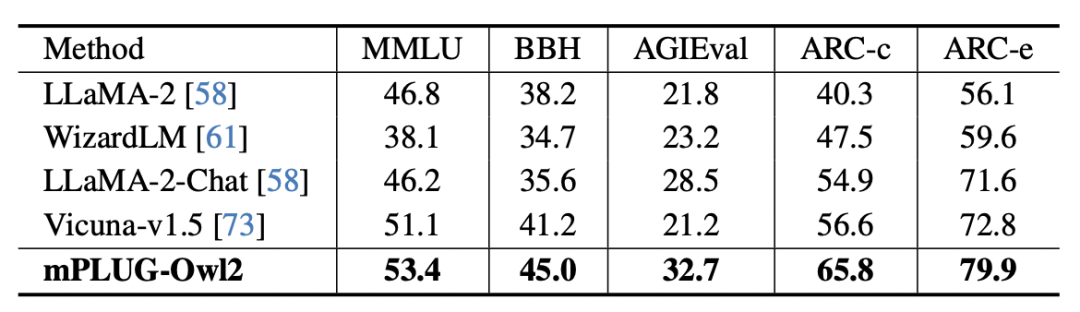
圖8 純文字基準測試效能
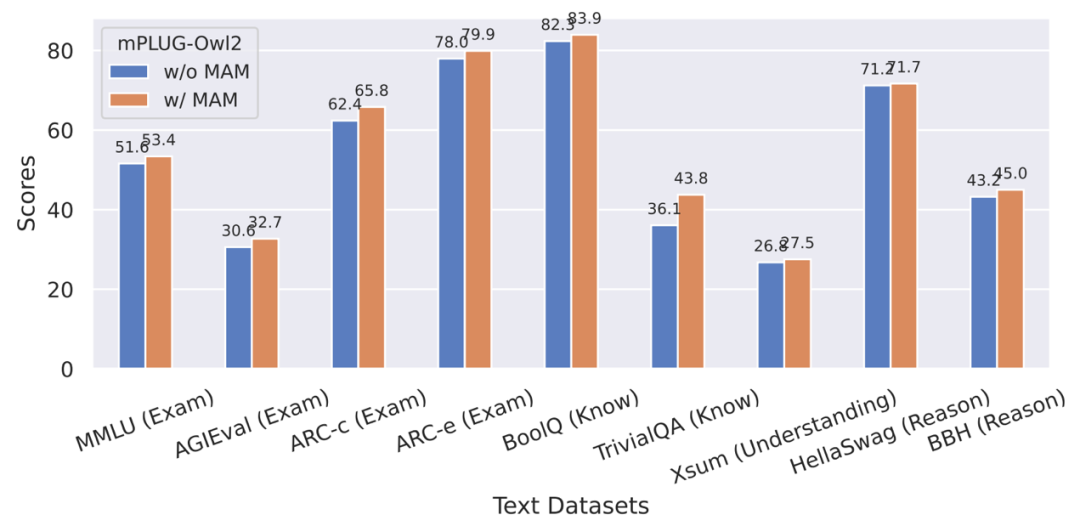
圖9 模態自適應模組對純文字任務表現的影響
#此外,為了評估模態協同對純文字任務的影響,作者也測試了mPLUG -Owl2 在自然語言理解和生成方面的表現。如圖 8 所示,與其他指令微調的 LLM 相比,mPLUG-Owl2 取得了更好的效能。圖 9 所展示的純文字任務上的表現可以看出,由於模態自適應模組促進了模態協作,模型的測驗和知識能力都得到了顯著提升。作者分析,這是由於多模態協作使得模型能夠利用視覺資訊來理解語言難以描述的概念,並透過圖像中豐富的資訊來增強模型的推理能力,並間接強化文本的推理能力。


mPLUG-Owl2 展現了出色的多模態理解能力,成功地緩解了多模態幻覺。這種多模態技術已經被應用於通義星塵、通義智文等核心通義產品,並且已經在 ModelScope、HuggingFace 開放 Demo 中得到了驗證
以上是阿里mPLUG-Owl新升級,魚與熊掌兼得,模態協同實現MLLM新SOTA的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















