

在CTR預估中,主流都採用特徵embedding MLP的方式,其中特徵非常關鍵。然而對於相同的特徵,在不同的樣本中,表徵是相同的,這種方式輸入到下游模型,會限制模型的表達能力。
為了解決這個問題,CTR預估領域提出了一系列相關工作,稱為特徵增強模組。特徵增強模組根據不同的樣本,對embedding層的輸出結果進行一次矯正,以適應不同樣本的特徵表示,提升模型的表達能力。
最近,復旦大學和微軟亞洲研究院合作發布了一篇關於特徵增強工作的綜述,對比了不同特徵增強模組的實現方法及其效果。現在,讓我們來介紹幾個特徵增強模組的實作方法,以及本文所進行的相關對比實驗
 論文標題:A Comprehensive Summarization and Evaluation of Feature Refinement Modules for CTR Prediction
論文標題:A Comprehensive Summarization and Evaluation of Feature Refinement Modules for CTR Prediction
下載網址:https://arxiv.org/pdf/2311.04625v1.pdf
特徵增強模組,旨在提升CTR預估模型中Embedding層的表達能力,實現相同特徵在不同樣本下的表徵差異化。特徵增強模組可以用下面這個統一公式表達,輸入原始的Embedding,經過一個函數後,產生這個樣本個性化的Embedding。
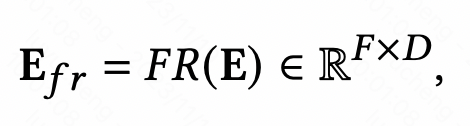 圖片
圖片
這類方法的大致思路為,在得到初始的每個特徵的embedding後,使用樣本本身的表徵,對特徵embedding做一個變換,得到目前樣本的個人化embedding。以下為大家介紹一些經典的特徵增強模組建模方法。
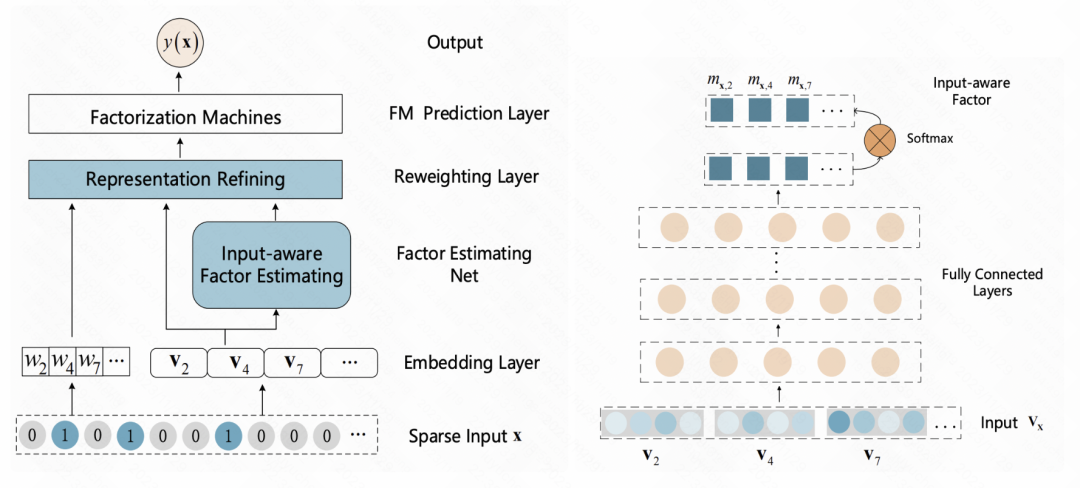
An Input-aware Factorization Machine for Sparse Prediction(IJCAI 2019)這篇文章在embedding層之後增加了一個reweight層,將樣本初始embedding輸入到一個MLP中得到一個表徵樣本的向量,使用softmax進行歸一化。 Softmax後的每個元素對應一個特徵,代表這個特徵的重要程度,使用這個softmax結果和每個對應特徵的初始embedding相乘,實現樣本粒度的特徵embedding加權。
 圖片
圖片
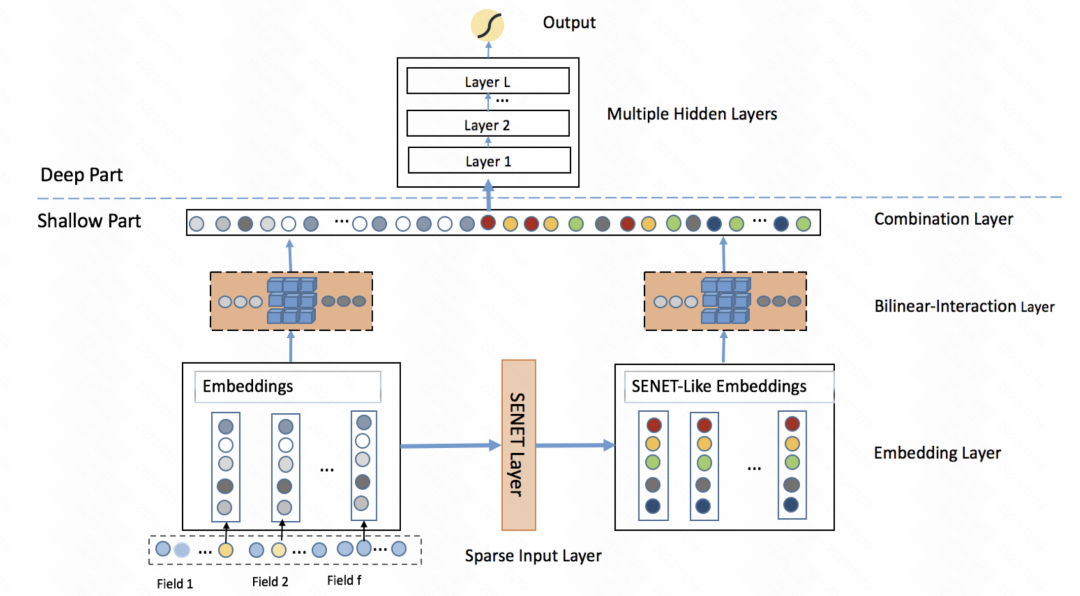
FiBiNET: 結合特徵重要性和二階特徵互動的點擊率預測模型(RecSys 2019)也採用了類似的想法。該模型為每個樣本學習了一個特徵的個人化權重。整個過程分為擠壓(squeeze)、提取(extraction)和重新加權(reweight)三個步驟。在擠壓階段,透過池化方法將每個特徵的嵌入向量得到一個統計標量。在提取階段,將這些標量輸入到多層感知機(MLP)中,得到每個特徵的權重。最後,將這些權重與每個特徵的嵌入向量相乘,得到加權後的嵌入結果,相當於在樣本層級上進行特徵重要性的篩選
 圖片
圖片
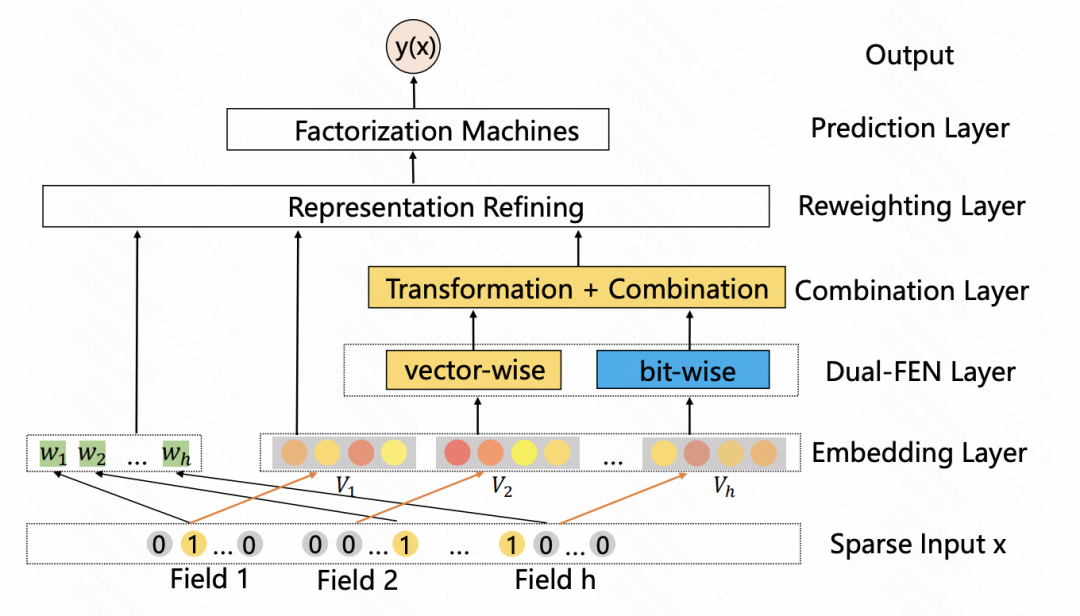
#A Dual Input-aware Factorization Machine for CTR Prediction(IJCAI 2020)和上一篇文章類似,也是利用self-attention對特徵進行一層增強。整體分為vector-wise和bit-wise兩個模組。 Vector-wise將每個特徵的embedding當成序列中的一個元素,輸入到Transformer中得到融合後的特徵表示;bit-wise部分使用多層MLP對原始特徵進行對應。兩部分的輸入結果相加後,得到每個特徵元素的權重,乘到對應的原始特徵的每一位上,得到增強後的特徵。
 圖片
圖片
GateNet:增強門控深度網路用於點擊率預測(2020)利用每個特徵的初始嵌入向量透過一個MLP和sigmoid函數產生其獨立的特徵權重分數,同時使用MLP將所有特徵映射為按位的權重分數,將兩者結合起來對輸入特徵進行加權。除了特徵層外,在MLP的隱藏層中,也利用類似的方法對每個隱藏層的輸入進行加權
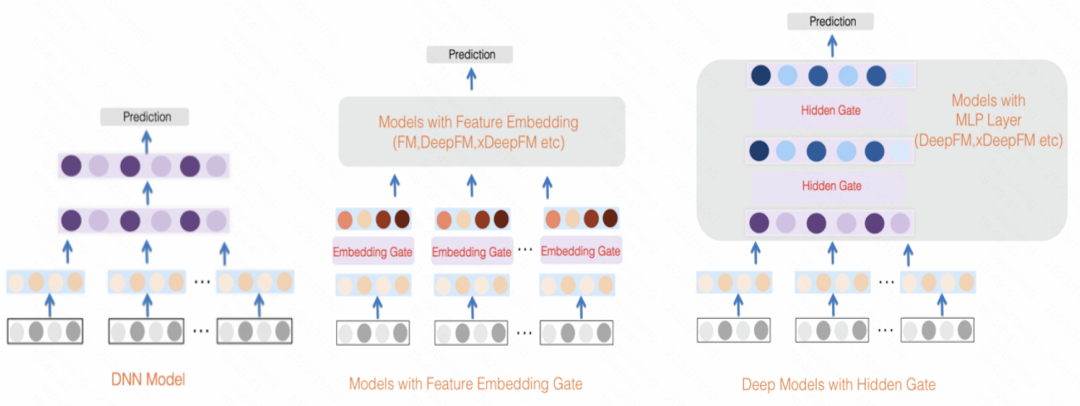 圖片
圖片
Interpretable Click-Through Rate Prediction through Hierarchical Attention(WSDM 2020)也是利用self-attention實現特徵的轉換,但是增加了高階特徵的生成。這裡面使用層次self-attention,每一層的self-attention以上一層sefl-attention的輸出作為輸入,每一層增加了一階高階特徵組合,實現層次多層特徵提取。具體來說,每一層進行self-attention後,將生成的新特徵矩陣經過softmax得到每個特徵的權重,根據權重對原始特徵加權新的特徵,再和原始特徵進行一次點積,實現增加一階的特徵交叉。
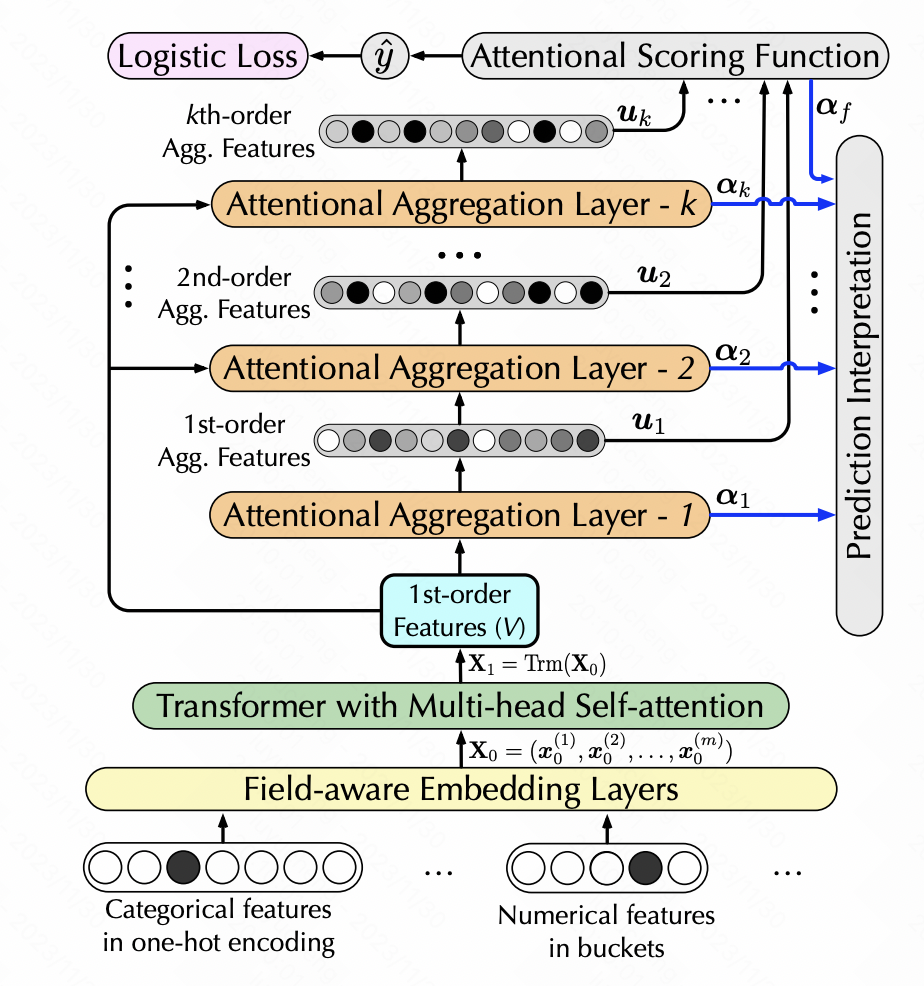 圖片
圖片
ContextNet: A Click-Through Rate Prediction Framework Using Contextual information to Refine Feature Embedding(2021)也是類似的做法,使用一個MLP將所有特徵映射成一個每個特徵embedding尺寸的維度,對原始特徵做一個縮放,文中針對每個特徵使用了個性化的MLP參數。透過這種方式,利用樣本中的其他特徵作為上下位增強每個特徵。
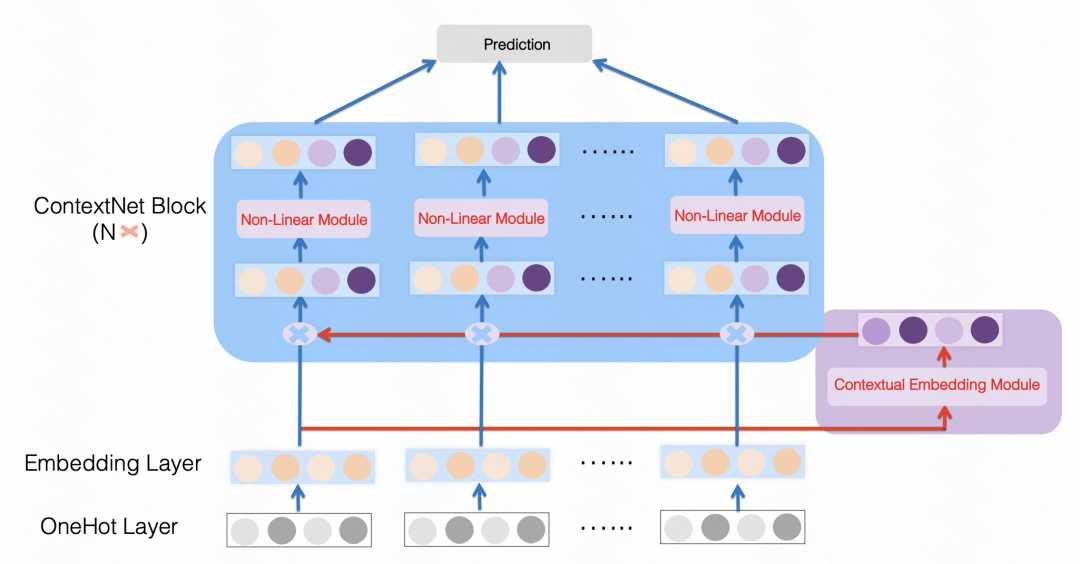 圖片
圖片
Enhancing CTR Prediction with Context-Aware Feature Representation Learning(SIGIR 2022)採用了self-attention進行特徵增強,對於一組輸入特徵,每個特徵對於其他特徵的影響程度是不同的,透過self-attention,對每個特徵的embedding進行一次self-attention,實現樣本內特徵間的資訊交互作用。除了特徵間的交互,文中也利用MLP進行bit層級的訊息交互。上述生成的新embedding,會透過一個gate網絡,和原始的embedding進行融合,得到最終refine後的特徵表示。
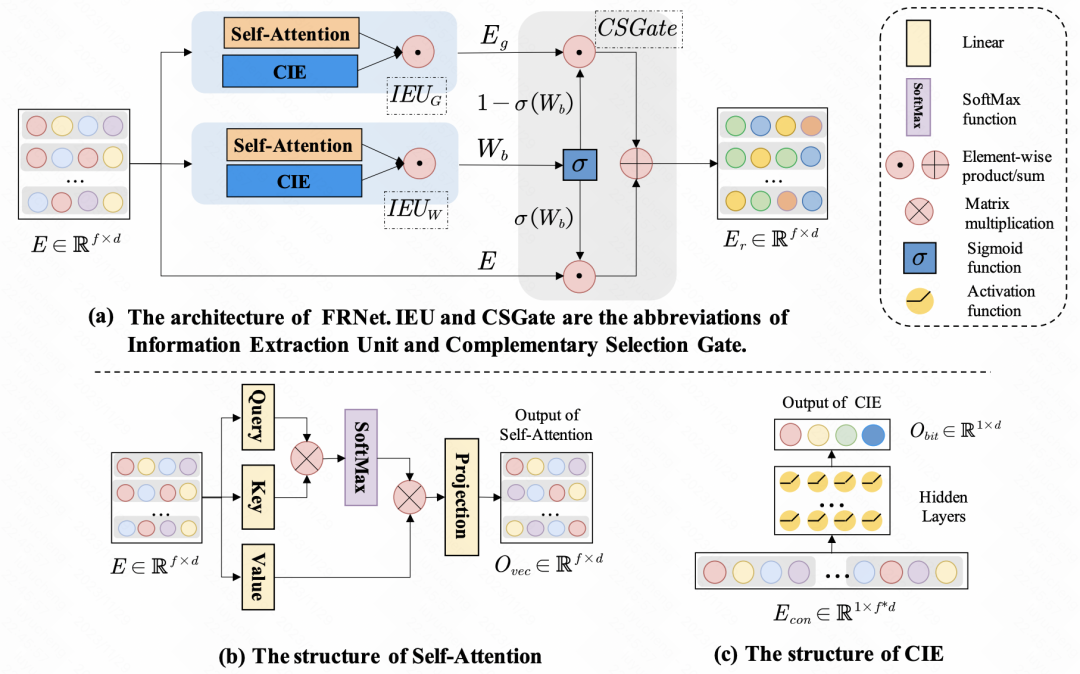 圖片
圖片
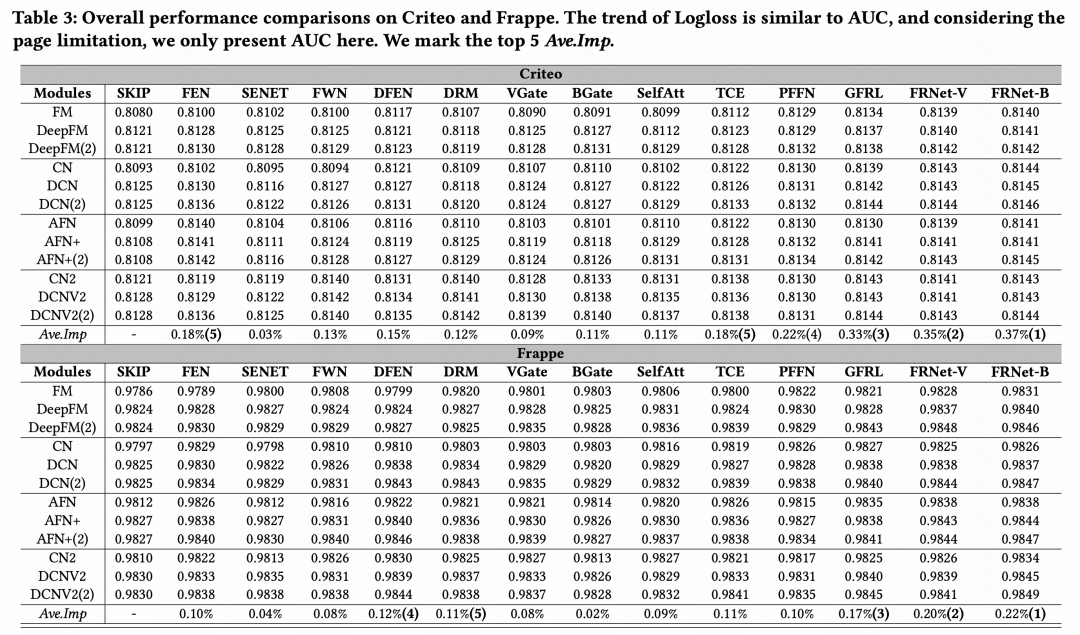
#進行了各類別特徵增強方法的效果對比後,得出整體結論:在在眾多特徵增強模組中,GFRL、FRNet-V、FRNetB表現最優,且效果優於其他特徵增強方法
 ##圖片 #
##圖片 #
以上是一文總結特徵增強&個人化在CTR預估中的經典方法與效果對比的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















