

知識抽取通常指從非結構化文字中挖掘結構化訊息,例如含有豐富語意資訊的標籤和短語。這在業界被廣泛應用於內容理解和商品理解等場景,透過從用戶生成的文本資訊中提取有價值的標籤,將其應用於內容或商品上
#知識抽取通常伴隨著對所抽取標籤或短語的分類,通常被建模為命名實體識別任務,通用的命名實體識別任務是識別命名實體成分並將成分劃分到地名、人名、機構名等類型上;領域相關的標籤詞抽取將標籤詞識別並劃分到領域自訂的類別上,如係列(空軍一號、音速9)、品牌(Nike、李寧)、類型(鞋、服裝、數碼)、風格(ins 風、復古風、北歐風)等。
為了方便描述,下文將富含資訊的標籤或短語統一稱為標籤詞
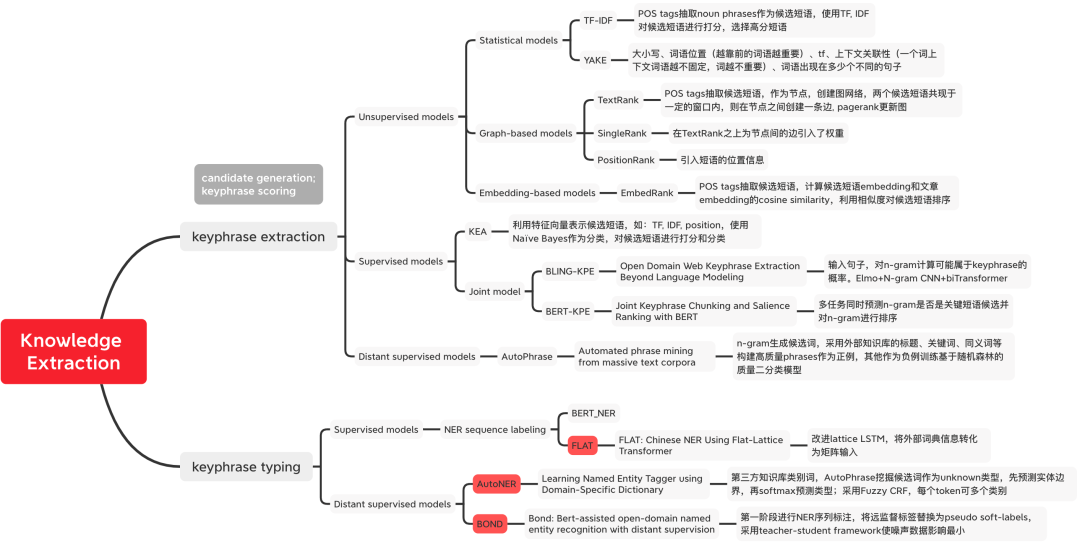 圖1 知識抽取方法分類
圖1 知識抽取方法分類
重寫後的內容:計算方法:tfidf(t, d, D) = tf(t, d) * idf(t, D),其中tf(t, d) = log (1 freq(t, d)),freq(t,d)表示候選詞t 在目前文件d 中出現的次數,idf(t,D) = log(N/count(d∈D:t∈D) )表示候選詞t 出現在多少文件中,用來表示一個詞語的稀有度,假如一個詞語只在一篇文檔中出現,說明這個詞語比較稀有,信息量更豐富
特定業務場景下可以藉助外部工具對候選詞先進行一輪篩選,如採用詞性標識篩選名詞。
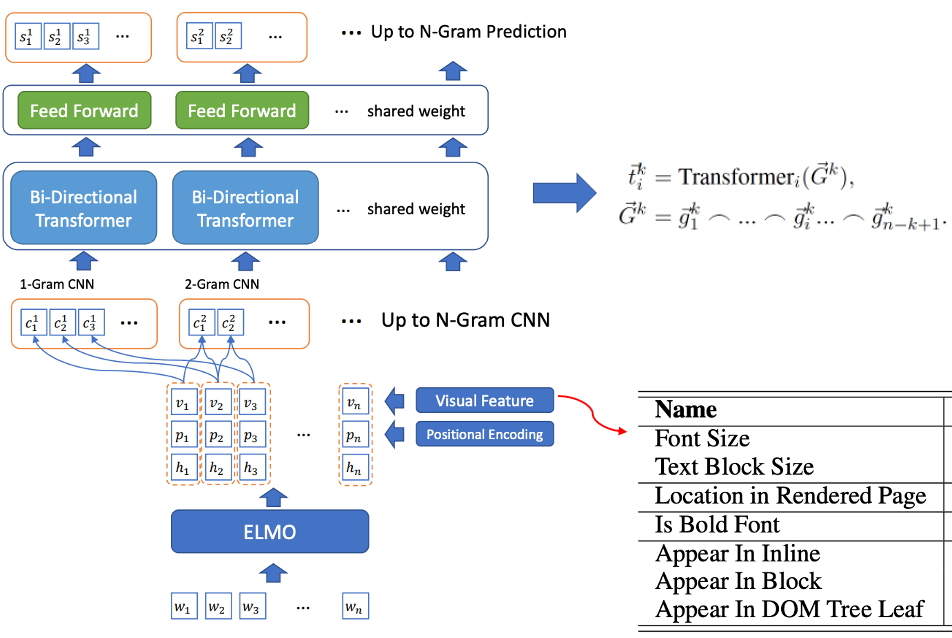 圖2 BLING-KPE 模型結構
圖2 BLING-KPE 模型結構
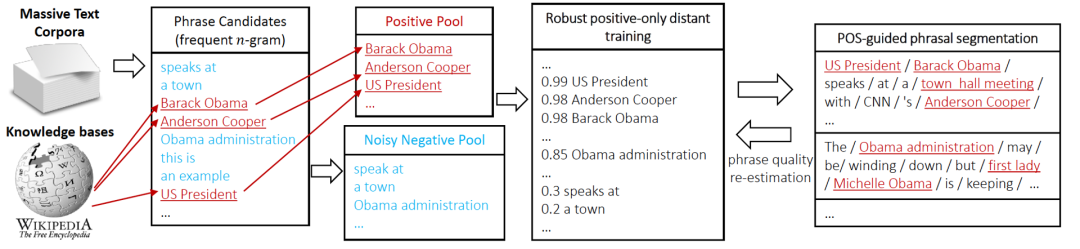 圖3 AutoPhrase 標籤挖掘流程
圖3 AutoPhrase 標籤挖掘流程
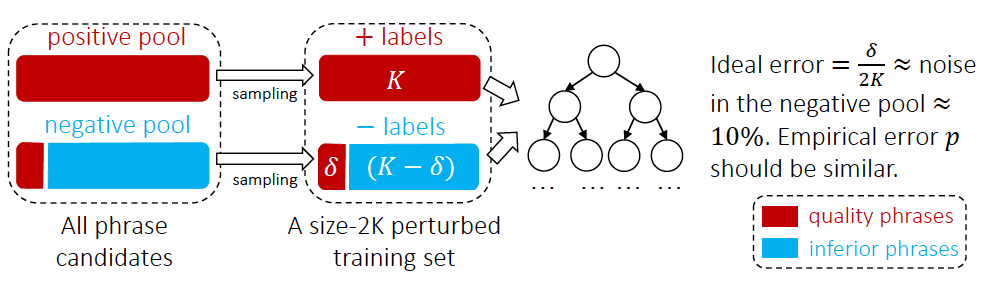 圖4 AutoPhrase標籤詞分類方法
圖4 AutoPhrase標籤詞分類方法
Lattice LSTM[8] 是針對中文NER 任務引入詞彙訊息的開頭之作,Lattice 是一個有向無環圖,詞彙的開始和結束字符決定了格子位置,透過詞彙訊息(字典)配對一個句子時,可以得到一個類似Lattice 的結構,如圖5(a) 所示。 Lattice LSTM 結構則融合了詞彙訊息到原生的LSTM 中,如5(b) 所示,對於當前的字符,融合以該字符結束的所有外部詞典信息,如“店”融合了“人和藥店”和「藥局」的資訊。對於每一個字符,Lattice LSTM 採取注意力機制去融合個數可變的詞單元。雖然Lattice-LSTM 有效提升了NER 任務的性能,但RNN 結構無法捕捉長距離依賴,同時引入詞彙資訊是有損的,同時動態的Lattice 結構也不能充分進行GPU 並行,Flat[9] 模型有效改善了這兩個問題。如圖5(c),Flat 模型透過Transformer 結構來捕捉長距離依賴,並設計了一種位置編碼Position Encoding 來融合Lattice 結構,將字符匹配到的詞彙拼接到句子後,對於每一個字符和詞彙都建造兩個Head Position Encoding 和Tail Position Encoding,將Lattice 結構展平,從一個有向無環圖展平為一個平面的Flat-Lattice Transformer 結構。
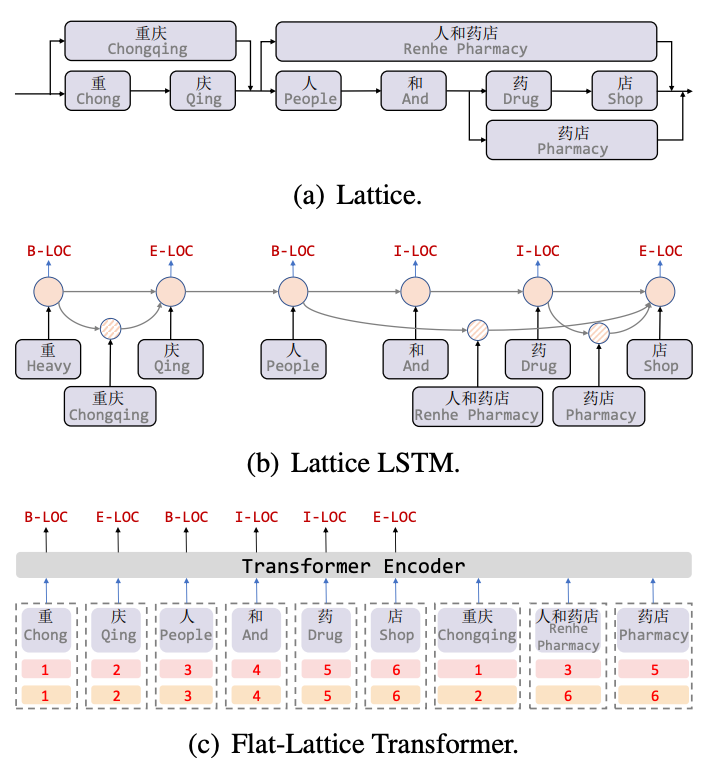 圖5 引入詞彙資訊的NER 模型
圖5 引入詞彙資訊的NER 模型
為了解決遠監督中的噪音問題,我們採用了Tie或Break的實體邊界識別方案來取代BIOE的標註方式。其中,Tie表示當前詞和上一個詞屬於同一個實體,而Break表示當前詞和上一個詞不再同一個實體中
在實體分類階段,使用模糊CRF(Fuzzy CRF)來應對一個實體具有多種類型的情況
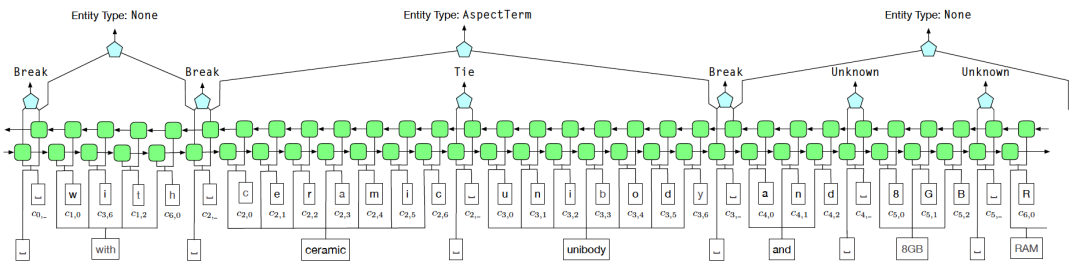 圖6 AutoNER 模型結構圖
圖6 AutoNER 模型結構圖
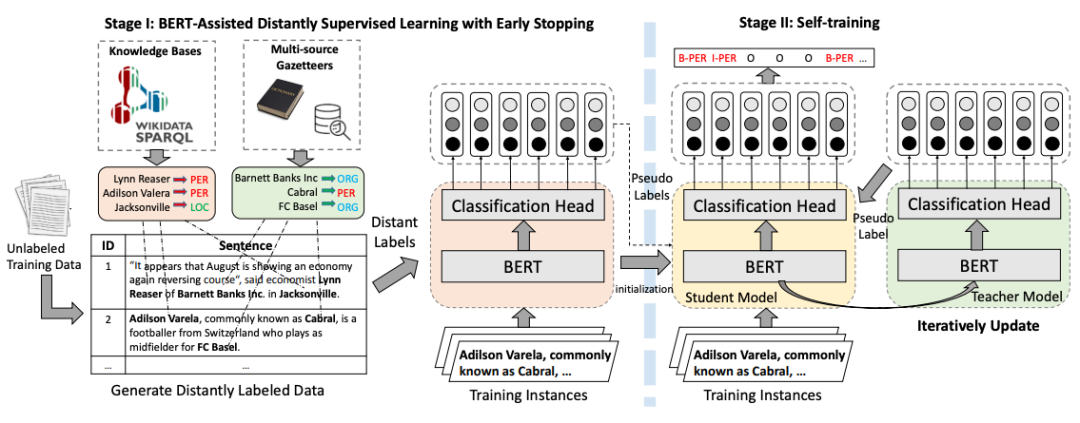 圖片
圖片
需要重新書寫的內容是:圖7 BOND訓練流程圖
【1】Campos R, Mangaravite V, Pasquali A, et al. Yake! collection-independent automatic keyword extractor[ C]//Advances in Information Retrieval: 40th European Conference on IR Research, ECIR 2018, Grenoble, France, March 26-29, 2018, Proceedings 40. Springer International Publishing, 2018: 806-810. /LIAAD/yake
【2】Mihalcea R, Tarau P. Textrank: Bringing order into text[C]//Proceedings of the 2004 conference on empirical methods in natural language processing. 2004: 404-411.
3 】Bennani-Smires K, Musat C, Hossmann A, et al. Simple unsupervised keyphrase extraction using sentence embeddings[J]. arXiv preprint arXiv:1801.04470, 2018. arXiv preprint arXiv:1801.04470, 2018.KKey#BERT#://gKKey:2018. .com/MaartenGr/KeyBERT
【5】Witten I H, Paynter G W, Frank E, et al. KEA: Practical automatic keyphrase extraction[C]//Proceedings of the fourth ACM conference on Digital libraries. 1999: 254-255.
翻譯內容:【6】熊L,胡C,熊C,等。超越語言模型的開放領域Web關鍵字擷取[J]。 arXiv預印本arXiv:1911.02671,2019年
【7】Sun, S., Xiong, C., Liu, Z., Liu, Z., & Bao, J. (2020). Joint Keyphrase Chunking and Salience Ranking with BERT. arXiv preprint arXiv:2004.13639.
需要重寫的內容是:【8】張Y,楊J。使用格子LSTM的中文命名實體辨識[C]。 ACL 2018
【9】Li X, Yan H, Qiu X, et al. FLAT: Chinese NER using flat-lattice transformer[C]. ACL 2020.
#【10】Shang J , Liu J, Jiang M, et al. Automated phrase mining from massive text corpora[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 30(10): 1825-1837.
【11】 Shang J, Liu L, Ren X, et al. Learning named entity tagger using domain-specific dictionary[C]. EMNLP, 2018.
【12】Liang C, Yu Y, Jiang H, et al. Bond : Bert-assisted open-domain named entity recognition with distant supervision[C]//Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2020: 1054-1064.#13#;搜尋中NER技術的探索與實踐,https://zhuanlan.zhihu.com/p/163256192
以上是我們一起聊聊知識抽取,你學會了嗎?的詳細內容。更多資訊請關注PHP中文網其他相關文章!

































