

「任何認為自動回歸式LLM 已經接近人類水平的AI,或者僅僅需要擴大規模就能達到人類水平的人,都必須讀一讀這個。AR-LLM 的推理和規劃能力非常有限,要解決這個問題,並不是把它們變大、用更多資料進行訓練就能解決的。」
一直以來,圖靈獎得主Yann LeCun 就是LLM 的「質疑者」,而自回歸模型是GPT 系列LLM 模型所依賴的學習範式。他不只一次公開表達對自回歸和LLM 的批評,並產出了不少金句,例如:
「從現在起5 年內,沒有哪個頭腦正常的人會使用自迴歸模型。」
「自迴歸產生模型弱爆了!(Auto-Regressive Generative Models suck!)」

「LLM 對世界的理解非常膚淺。」
讓LeCun 近日再次發出疾呼的,是兩篇新發布的論文:
「LLM 真的能像文獻中所說的那樣自我批判(並迭代改進)其解決方案嗎?我們小組的兩篇新論文在推理(https://arxiv. org/abs/2310.12397) 和規劃(https://arxiv.org/abs/2310.08118) 任務中對這些說法進行了調查(並提出了質疑)。」
看起來,這兩篇關於調查GPT-4 的驗證和自我批判能力的論文的主題引起了很多人的共鳴。
論文作者表示,他們同樣認為 LLM 是了不起的「創意生成器」(無論是語言形式還是程式碼形式),只是它們無法保證自己的規劃 / 推理能力。因此,它們最好在 LLM-Modulo 環境中使用(環路中要么有一個可靠的推理者,要么有一個人類專家)。自我批判需要驗證,而驗證是推理的一種形式(因此對所有關於 LLM 自我批判能力的說法都感到驚訝)。
同時,質疑的聲音也是存在的:「卷積網路的推理能力更加有限,但這並沒有阻止AlphaZero 的工作出現。這一切都是關於推理過程和建立的(RL) 回饋循環。我認為模型能力可以進行極其深入的推理(例如研究級數學)。」
對此,LeCun 的想法是:「AlphaZero「確實」執行規劃。這是透過蒙特卡羅樹搜尋完成的,使用卷積網路提出好的動作,並使用另一個卷積網路來評估位置。探索這棵樹所花費的時間可能是無限的,這就是推理和規劃。 」
在未來的一段時間內,自回歸 LLM 是否具備推理和規劃能力的話題或許都不會有定論。

論文1:GPT-4 Doesn't Know It's Wrong: An Analysis of Iterative Prompting for Reasoning Problems
#第一篇論文引發了研究者對最先進的LLM 具有自我批判能力的質疑,包括GPT-4 在內。
###論文網址:https://arxiv.org/pdf/2310.12397.pdf############接下來我們看看論文簡介。 ############人們對大型語言模型(LLM)的推理能力一直存在相當大的分歧,最初,研究者樂觀的認為LLM 的推理能力隨著模型規模的擴大會自動出現,然而,隨著更多失敗案例的出現,人們的期望不再那麼強烈。之後,研究者普遍認為 LLM 具有自我批判( self-critique )的能力,並以迭代的方式改進 LLM 的解決方案,這一觀點被廣泛傳播。 ############然而事實真的是這樣嗎? ######
來自亞利桑那州立大學的研究者在新的研究中檢驗了 LLM 的推理能力。具體而言,他們重點研究了迭代提示(iterative prompting)在圖著色問題(是最著名的 NP - 完全問題之一)中的有效性。
該研究表明(i)LLM 不擅長解決圖著色實例(ii)LLM 不擅長驗證解決方案,因此在迭代模式下無效。從而,本文的結果引發了人們對最先進的 LLM 自我批判能力的質疑。
論文給出了一些實驗結果,例如,在直接模式下,LLM 在解決圖著色實例方面非常糟糕,此外,研究還發現 LLM 並不擅長驗證解決方案。然而更糟的是,系統無法辨識正確的顏色,最終得到錯誤的顏色。
如下圖是對圖著色問題的評估,在該設定下,GPT-4 可以以獨立和自我批判的模式猜測顏色。在自我批判迴路之外還有一個外在聲音驗證器。
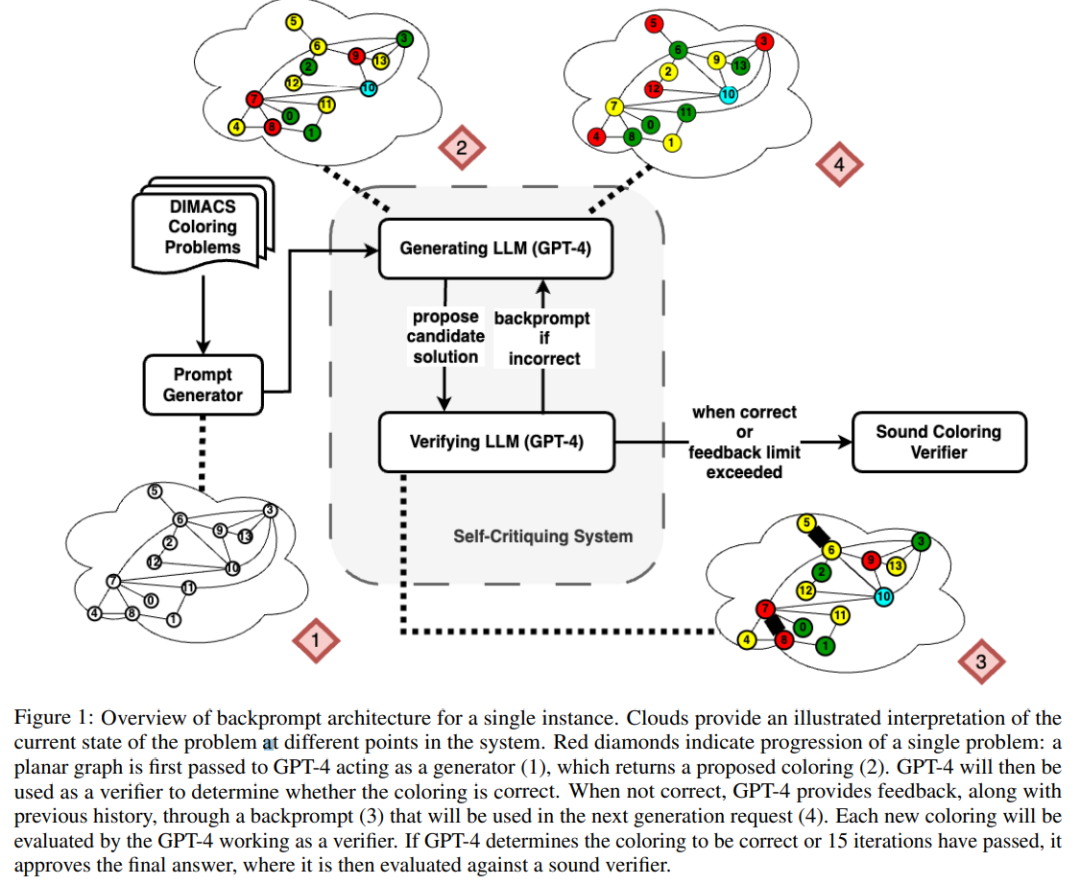
結果顯示GPT4 在猜測顏色方面的準確率低於20%,更令人驚訝的是,自我批判模式(下圖第二欄)的準確率最低。本文也研究了相關問題:如果外部聲音驗證器對 GPT-4 猜測的顏色提供可證明正確的批判,GPT-4 是否會改善其解決方案。在這種情況下,反向提示確實可以提高效能。
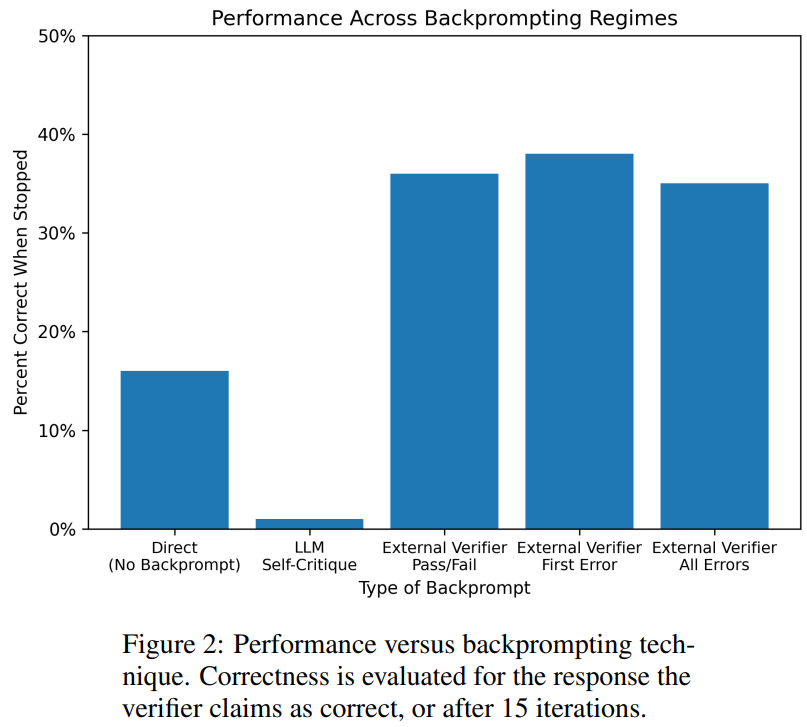
即使GPT-4 偶然猜出了一個有效的顏色,它的自我批判可能會讓它產生幻覺,認為不存在違規行為。
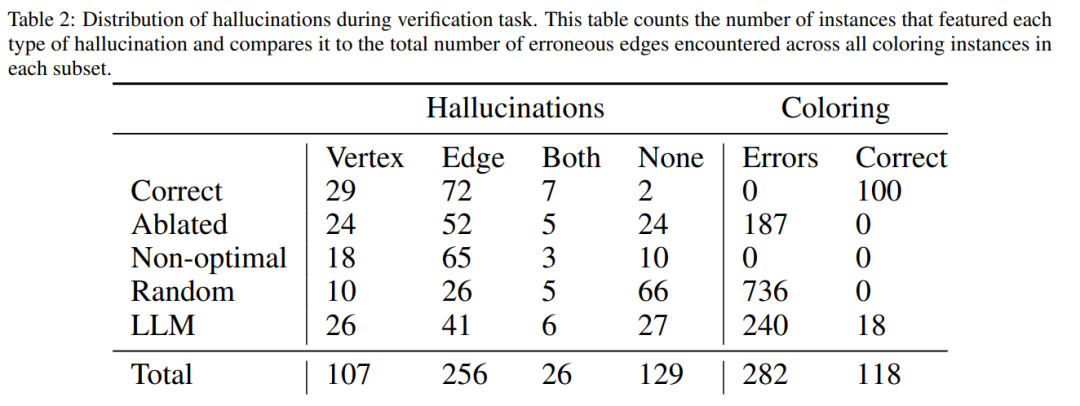
最後,作者給出總結,對於圖著色問題:
論文2:Can Large Language Models Really Improve by Self-critiquing Their Own Plans?
#在論文《Can Large Language Models Really Improve by Self-critiquing Their Own Plans?》中,研究團隊探討了LLM 在規劃(planning)的情境下自我驗證/ 批判的能力。
這篇論文對 LLM 批判自身輸出結果的能力進行了系統研究,特別是在經典規劃問題的背景下。雖然最近的研究對 LLM 的自我批判潛力持樂觀態度,尤其是在迭代環境中,但這項研究提出了不同的觀點。

論文網址:https://arxiv.org/abs/2310.08118
令人意外的是,研究結果表明,自我批判會降低規劃產生的效能,特別是與具有外部驗證器和LLM 驗證器的系統相比。 LLM 會產生大量錯誤訊息,從而損害系統的可靠性。
研究者在經典 AI 規劃領域 Blocksworld 上進行的實證評估突出表明,在規劃問題中,LLM 的自我批判功能並不有效。驗證器可能會產生大量錯誤,這對整個系統的可靠性不利,尤其是在規劃的正確性至關重要的領域。
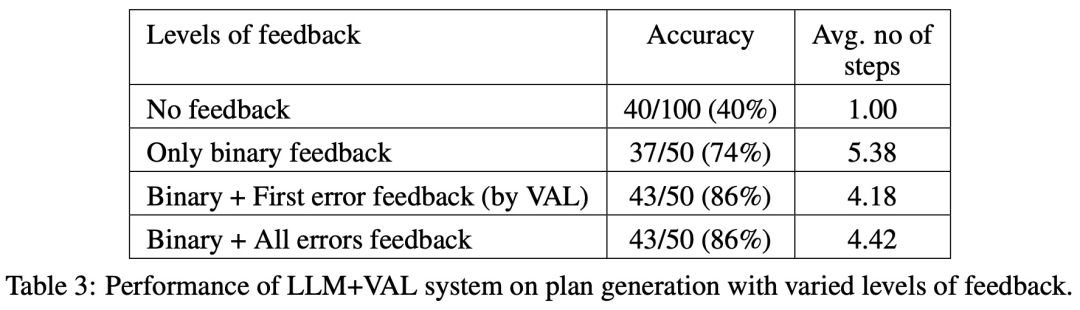
有趣的是,回饋的性質(二進位或詳細回饋)對規劃產生效能沒有明顯影響,這表明核心問題在於 LLM 的二進位驗證能力,而不是回饋的粒度。
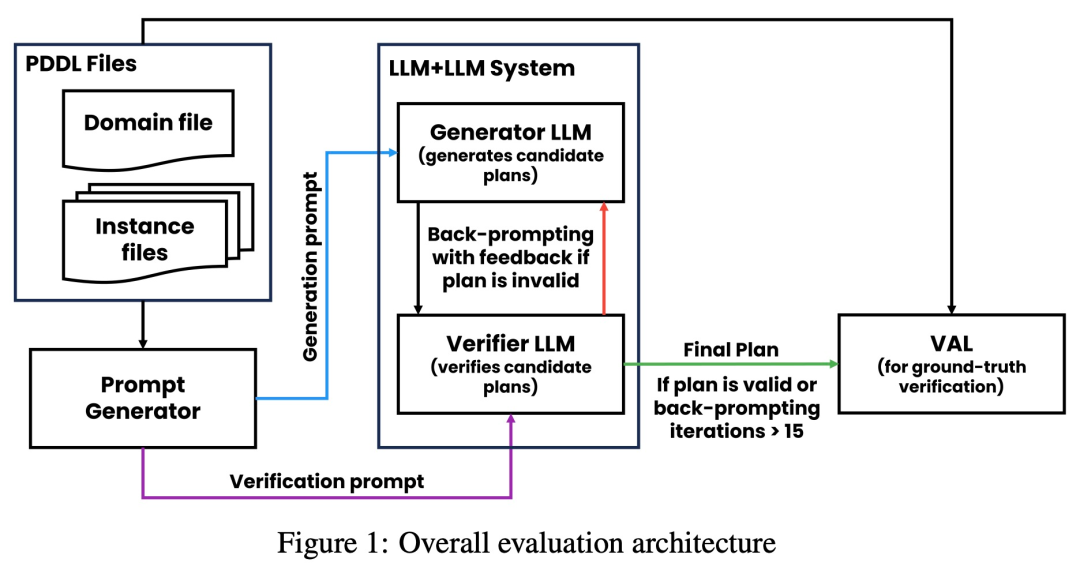
如下圖所示,研究的評估架構包括 2 個 LLM—— 生成器 LLM 驗證器 LLM。對於給定的實例,生成器 LLM 負責產生候選規劃,而驗證器 LLM 決定其正確性。如果發現規劃不正確,驗證器會提供回饋,給出其錯誤的原因。然後,該回饋被傳輸到生成器 LLM 中,並 prompt 生成器 LLM 產生新的候選規劃。研究所有實驗均採用 GPT-4 作為預設 LLM。
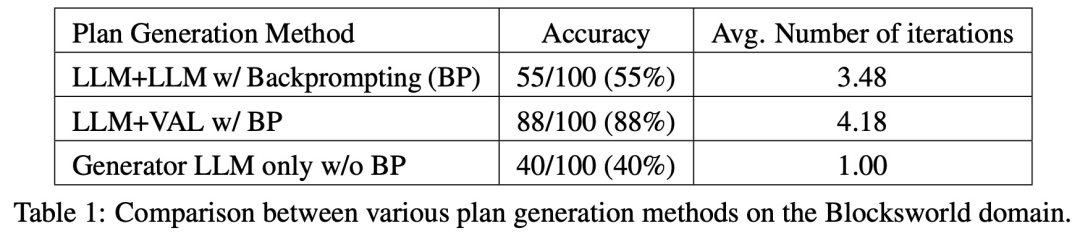
該研究在 Blocksworld 上對幾種規劃生成方法進行了實驗和比較。具體來說,該研究產生了 100 個隨機實例,用於對各種方法進行評估。為了對最終 LLM 規劃的正確性進行真實評估,研究採用了外部驗證器 VAL。
如表 1 所示,LLM LLM backprompt 方法在準確度方面略優於非 backprompt 方法。
在 100 個實例中,驗證器準確地識別了 61 個(61%)。
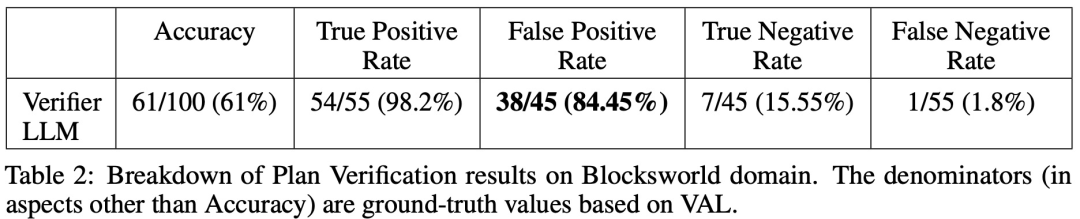
下表顯示了 LLM 在接受不同程度回饋(包含沒有回饋)時的表現。
以上是LeCun又雙詠唱衰自回歸LLM:GPT-4的推理能力非常有限,有兩篇論文為證的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















