

蘋果的一項最新研究,大幅提高了擴散模型在高解析度影像上表現。
利用這個方法,同樣解析度的影像,訓練步數減少了超過七成。
在1024×1024的解析度下,圖片畫質直接拉滿,細節都清晰可見。

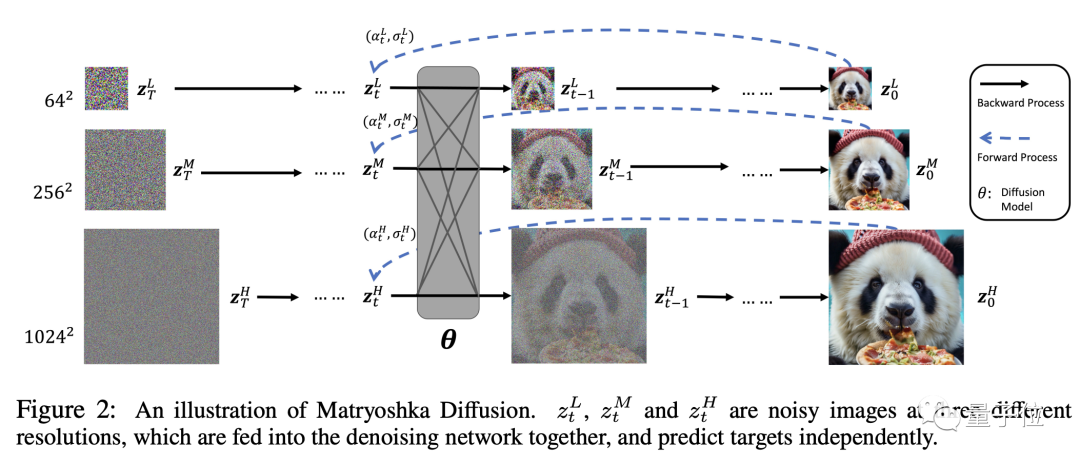
蘋果把這項成果命名為MDM,DM就是擴散模型(Diffusion Model)的縮寫,而第一個M則代表了套娃(Matryoshka)。
就像真的套娃一樣,MDM在高解析度過程中嵌套了低解析度過程,而且是多層嵌套。
高低解析度擴散過程同時進行,大幅降低了傳統擴散模型在高解析度過程中的資源消耗。

對於256×256解析度的影像,在批次大小(batch size)為1024的環境下,傳統擴散模型需要訓練150萬步,而MDM僅需39萬,減少了超七成。
另外,MDM採用了端到端訓練,不依賴特定資料集和預訓練模型,在提速的同時依然保證了生成質量,而且使用靈活。

不僅可以畫出高解析度的影像,還能合成16×256²的影片。

有網友評論到,蘋果終於把文字連接到圖像中了。
那麼,MDM的「套娃」技術,具體是怎麼做的呢?
在開始訓練之前,需要將資料進行預處理,高解析度的影像會用一定演算法重新取樣,得到不同分辨率的版本。
然後就是利用這些不同分辨率的資料進行聯合UNet建模,小UNet處理低分辨率,並嵌套進處理高分辨率的大UNet。
透過跨解析度的連接,不同大小的UNet之間可以共用特徵和參數。

MDM的訓練則是一個循序漸進的過程。
雖然建模是聯合進行的,但訓練過程並不會一開始就針對高解析度進行,而是從低解析度開始逐步擴大。
這樣做可以避免龐大的運算量,還可以讓低解析度UNet的預訓練可以加速高解析度訓練過程。
訓練過程中會逐步將更高解析度的訓練資料加入整體過程中,讓模型適應漸進增長的分辨率,平滑過渡到最終的高解析度過程。
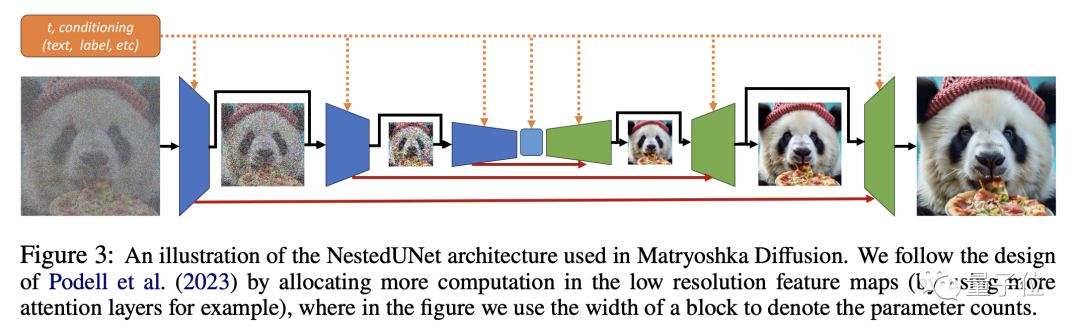
不過從整體來看,在高解析度過程逐步加入之後,MDM的訓練依舊是端到端的聯合過程。
在不同解析度的聯合訓練當中,多個解析度上的損失函數一起參與參數更新,避免了多階段訓練帶來的誤差累積。
每個解析度都有對應的資料項目的重建損失,不同解析度的損失被加權合併,其中為保證產生質量,低解析度損失權重較大。
在推理階段,MDM採用的同樣是並行與漸進結合的策略。
此外,MDM利還採用了預先訓練的圖像分類模型(CFG)來引導生成樣本向更合理的方向優化,並為低分辨率的樣本添加噪聲,使其更貼近高分辨率樣本的分佈。
那麼,MDM的效果究竟如何呢?
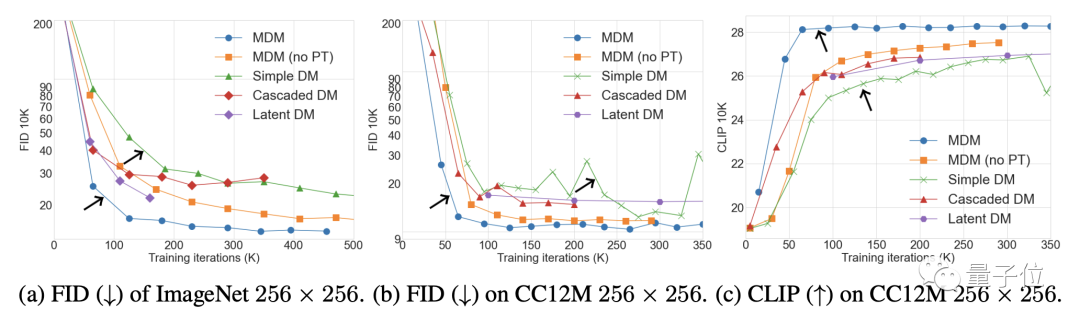
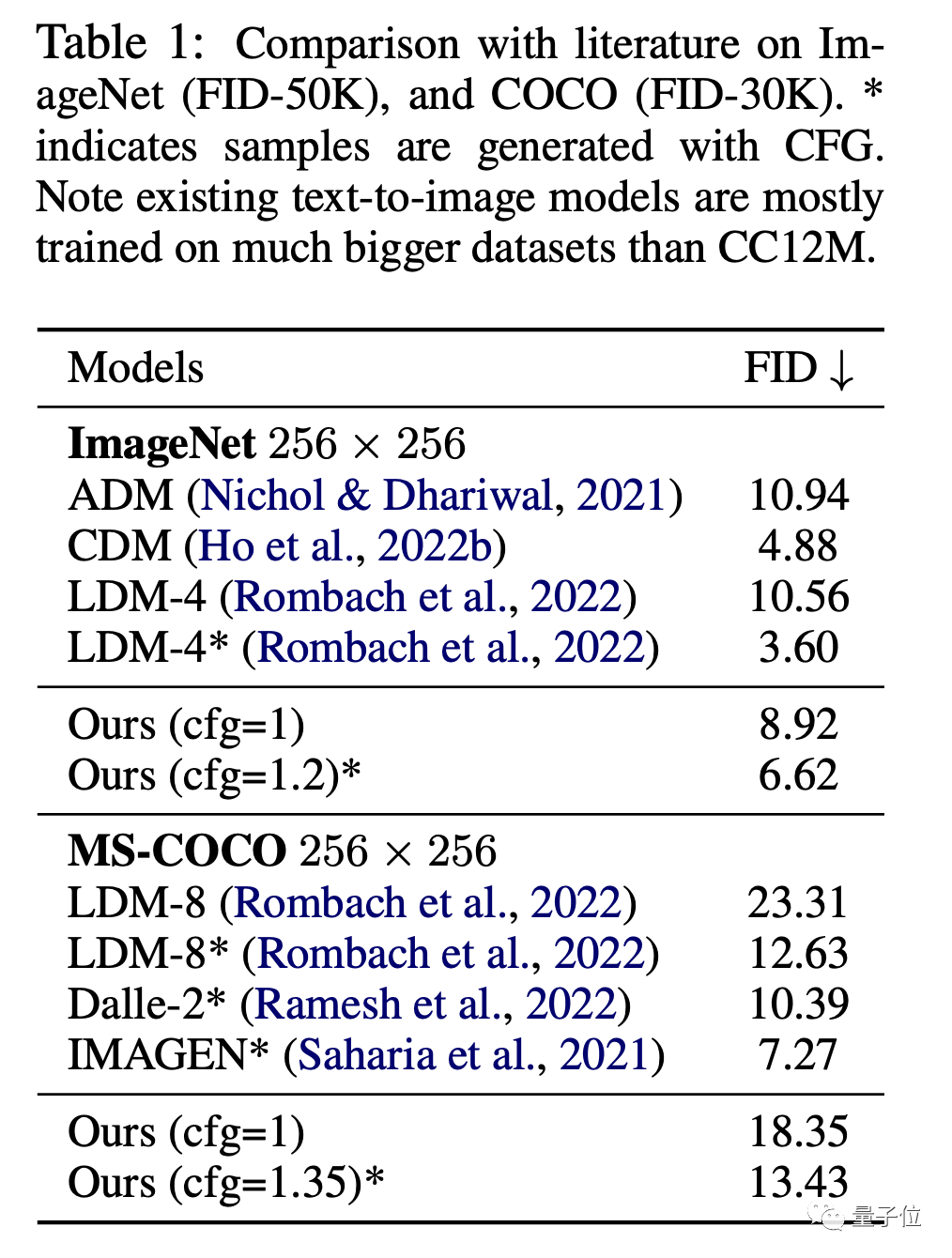
影像方面,在ImageNet和CC12M資料集上,MDM的FID(數值越低效果越好)和CLIP表現都顯著優於一般擴散模型。
其中FID用來評價圖像本身的質量,CLIP則說明了圖像和文字指令之間的匹配程度。
和DALL E、IMAGEN等SOTA模型相比,MDM的表現也很接近,但MDM的訓練參數遠少於這些模型。
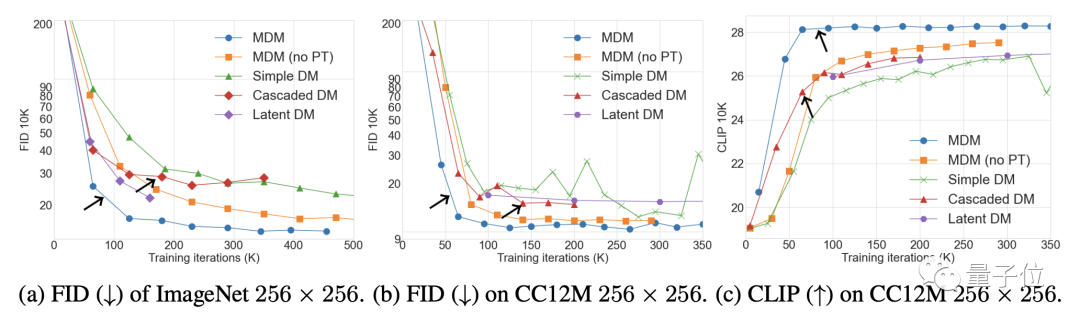
不僅是優於一般擴散模型,MDM的表現也超過了其他級聯擴散模型。
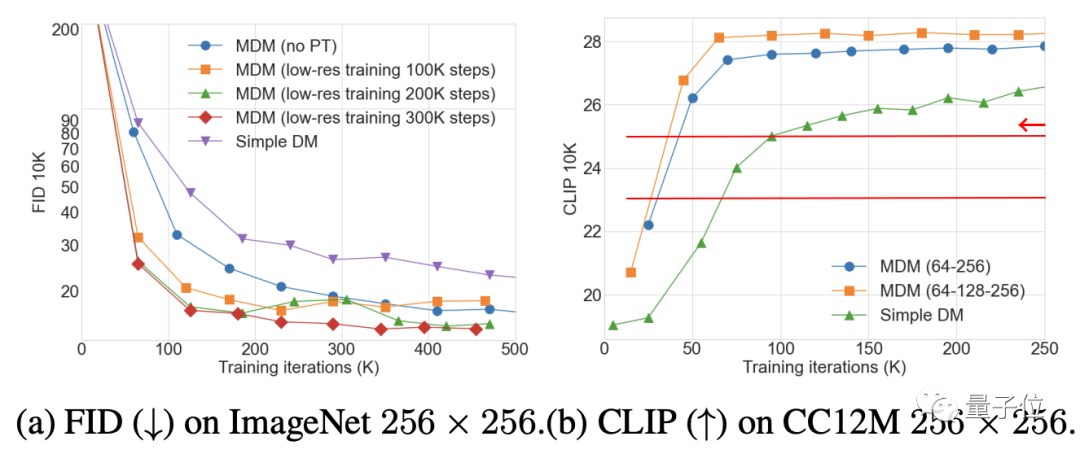
消融實驗結果表明,低解析度訓練的步數越多,MDM效果增強就越明顯;另一方面,嵌套層級越多,取得相同的CLIP得分所需的訓練步數就越少。
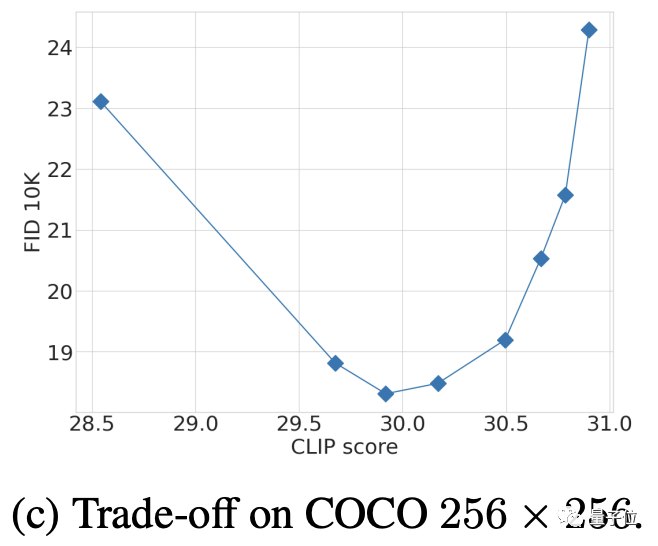
而關於CFG參數的選擇,則是多次測試後再FID和CLIP之間權衡的結果(CLIP得分高相對於CFG強度增加)。
以上是蘋果「套娃」式擴散模型,訓練步數減少七成!的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















