

只要微調一下,大模型支援上下文大小就能從1.6萬tokens延長至100萬? !
還是在只有70億參數的LLaMA 2上。
要知道,即使是目前最火的Claude 2和GPT-4,支援上下文長度也不過10萬和3.2萬,超出這個範圍大模型就會開始胡言亂語、記不住東西。
現在,一項來自復旦大學和上海人工智慧實驗室的新研究,不僅找到了讓一系列大模型提升上下文視窗長度的方法,還發掘出了其中的規律。

依照這個規律,只要調整1個超參數,就能確保輸出效果的同時,穩定提升大模型外推效能。
外推性,指大模型輸入長度超過預訓練文字長度時,輸出表現變化情況。如果外推能力不好,輸入長度一旦超過預訓練文字長度,大模型就會「胡言亂語」。
所以,它究竟能提升哪些大模型的外推能力,又是如何做到的呢?
這種提升大模型外推能力的方法,和Transformer架構中名叫位置編碼的模組有關。
事實上,單純的注意力機制(Attention)模組無法區分不同位置的token,例如「我吃蘋果」和「蘋果吃我」在它眼裡沒有差異。
因此需要加入位置編碼,來讓它理解詞序訊息,從而真正讀懂一句話的意思。
目前的Transformer位置編碼方法,有絕對位置編碼(將位置資訊融入輸入)、相對位置編碼(將位置資訊寫入attention分數計算)和旋轉位置編碼幾種。其中,最火熱的要屬旋轉位置編碼,也就是RoPE了。
RoPE透過絕對位置編碼的形式,實現了相對位置編碼的效果,但與相對位置編碼相比,又能更好地提升大模型的外推潛力。
如何進一步激發採用RoPE位置編碼的大模型的外推能力,也成為了最近不少研究的新方向。
這些研究,又主要分為限制注意力和調整旋轉角兩大流派。
限制注意力的代表性研究包括ALiBi、xPos、BCA等。最近MIT提出的StreamingLLM,可以讓大模型實現無限的輸入長度(但不增加上下文視窗長度),就屬於這一方向的研究類型。
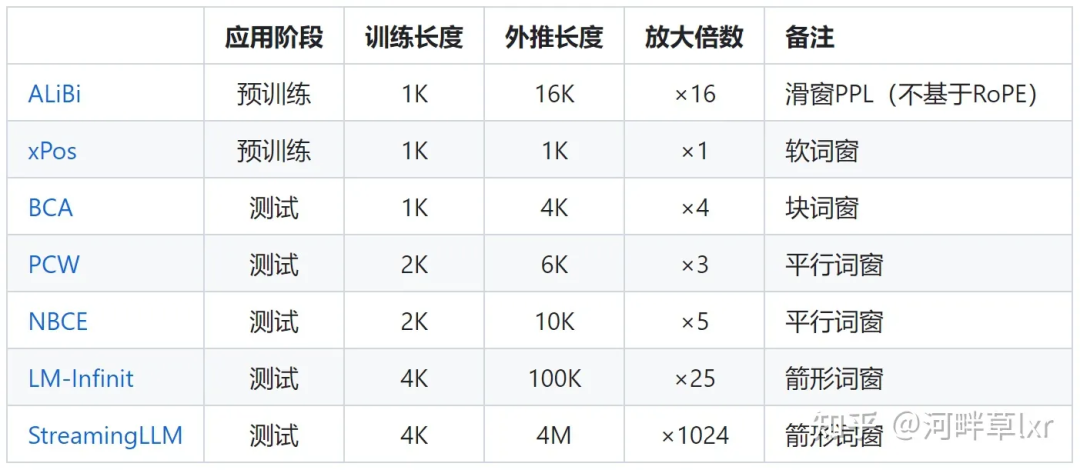
△圖源作者
調整旋轉角的工作則更多,典型代表如線性內插、Giraffe、Code LLaMA、LLaMA2 Long等都屬於這一類型的研究。
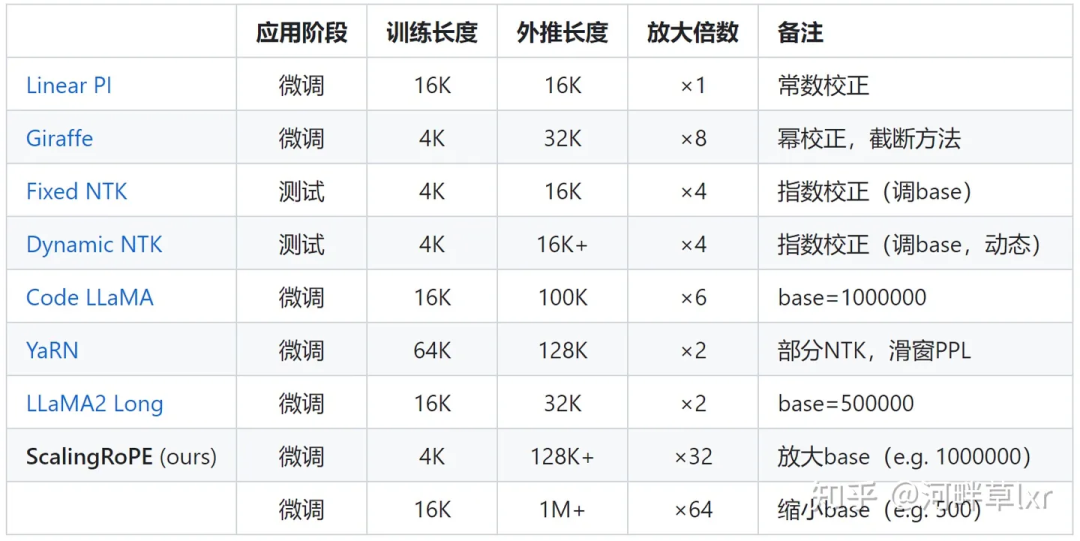
△圖源作者
以Meta最近爆火的LLaMA2 Long研究為例,它就提出了一個名叫RoPE ABF的方法,透過修改一個超參數,成功將大模型的上下文長度延長到3.2萬tokens。
這個超參數,正是Code LLaMA和LLaMA2 Long等研究找出的「開關」——
旋轉角底數(base )。
只需要微調它,就可以確保提升大模型的外推表現。
但無論是Code LLaMA或LLaMA2 Long,都只是在特定的base和續訓長度上進行微調,使得其外推能力增強。
是否能找到一種規律,確保所有用了RoPE位置編碼的大模型,都能穩定提升外推表現?
來自復旦大學和上海AI研究院的研究人員,針對這個問題進行了實驗。
他們先是分析了影響RoPE外推能力的幾個參數,提出了一個名為臨界維度(Critical Dimension)的概念,隨後基於這個概念,總結出了一套RoPE外推的縮放法則(Scaling Laws of RoPE-based Extrapolation)。
只需要應用這個規律,就能確保任意基於RoPE位置編碼大模型都能改善外推能力。
先來看看臨界維度是什麼。
從定義來看,它和預訓練文字長度Ttrain、自註意力頭維度數d等參數都有關係,具體計算方法如下:

其中,10000即超參數、旋轉角底數base的「初始值」。
作者發現,無論放大或縮小base,最終都能讓基於RoPE的大模型的外推能力增強,相較之下當旋轉角底數為10000時,大模型外推能力是最差的。
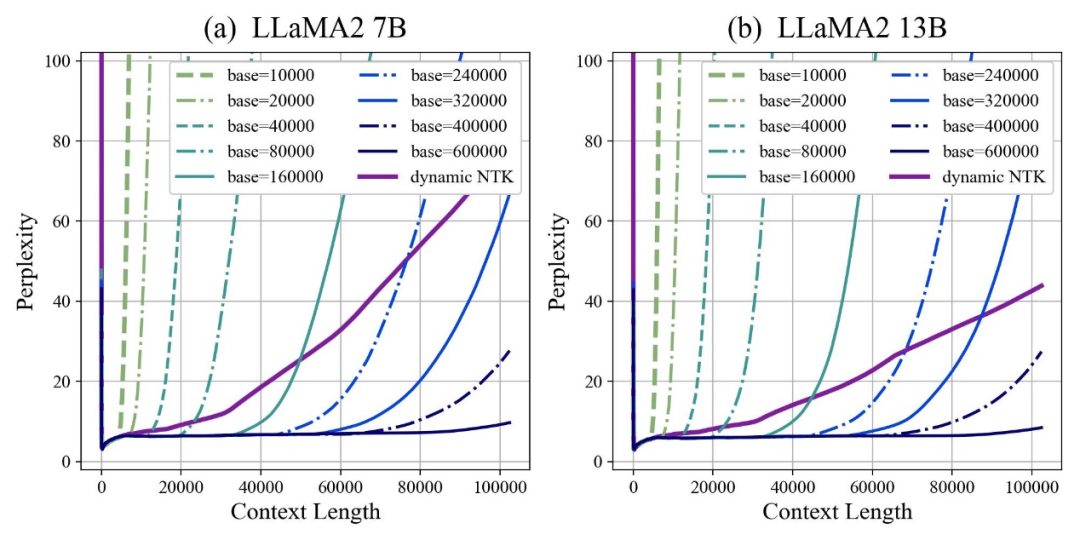
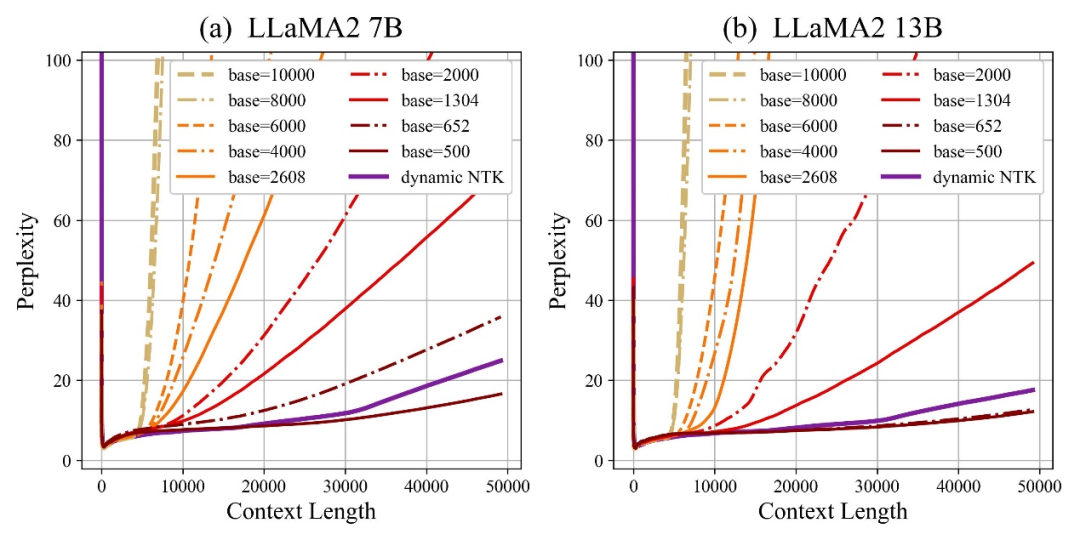
對此論文認為,旋轉角底數更小,能讓更多的維度感知到位置信息,旋轉角底數更大,則能表示出更長的位置資訊。
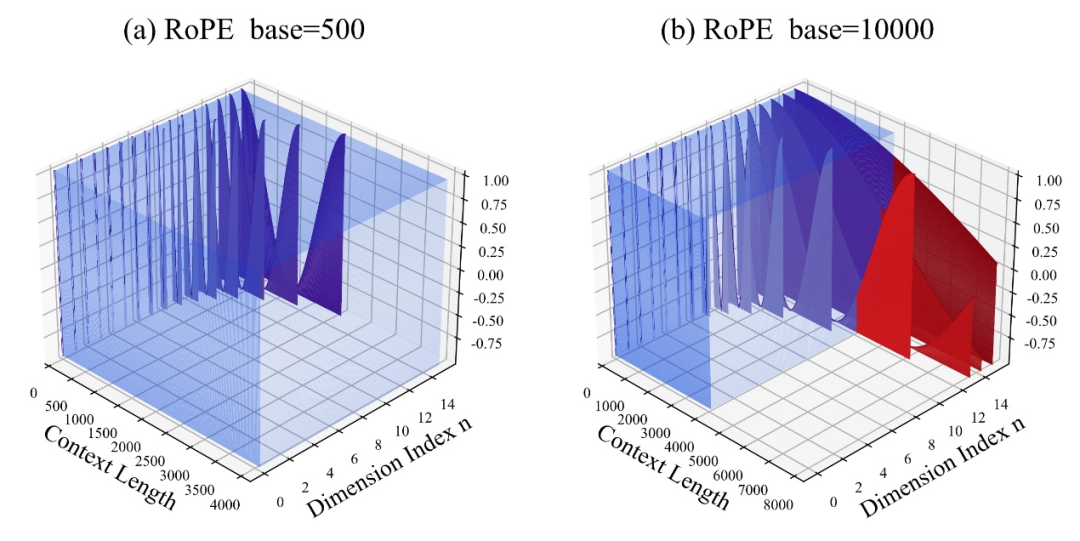
既然如此,在面對不同長度的續訓語料時,究竟縮小和放大多少旋轉角底數,才能確保大模型外推能力得到最大程度上的提升?
論文給出了一個擴展RoPE外推的縮放法則,與臨界維度、大模型的續訓文本長度和預訓練文本長度等參數有關:

基於這個規律,可以根據不同預訓練和續訓文本長度,來直接計算出大模型的外推表現,換言之就是預測大模型的支持的上下文長度。
反之利用這法則,也能快速推導出如何最好地調整旋轉角底數,從而提升大模型外推表現。
作者針對這一系列任務進行了測試,發現實驗上目前輸入10萬、50萬甚至100萬tokens長度,都可以保證,無需額外注意力限制即可實現外推。
同時,包括Code LLaMA和LLaMA2 Long在內的大模型外推能力增強工作都證明了這項規律是確實合理有效的。
這樣一來,只需要根據這個規律“調個參”,就能輕鬆擴展基於RoPE的大模型上下文窗口長度、增強外推能力了。
論文一作柳瀟然表示,目前這項研究還在透過改進續訓語料,提升下游任務效果,等完成之後就會將程式碼和模型開源,可以期待一下~
論文網址:
https://arxiv.org/abs/2310.05209
##Github倉庫:
https://github.com/OpenLMLab/scaling-rope
#論文解析部落格:
##https:// zhuanlan.zhihu.com/p/660073229以上是LLaMA2上下文長度飆升至100萬tokens,只需調整1個超參數的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















