

現在,AI已經可以即時解讀大腦訊號了!
這不是聳人聽聞,而是Meta的新研究,能夠憑腦訊號猜出你在0.5秒內看的圖,並用AI即時還原出來。
在此之前,AI雖然已經能從大腦訊號中比較準確地還原影像,但還有個bug-不夠快。
為此,Meta研發了一個新解碼模型,讓AI光是影像檢索的速度就提升了7倍,幾乎「瞬間」能讀出人在看什麼,並猜出個大概。
像是個站立的男人,AI幾次還原後,竟然真的解讀出了一個「站立的人」出來:
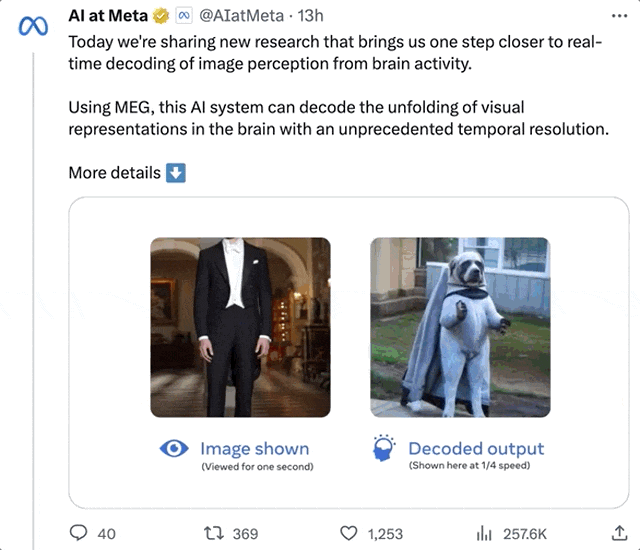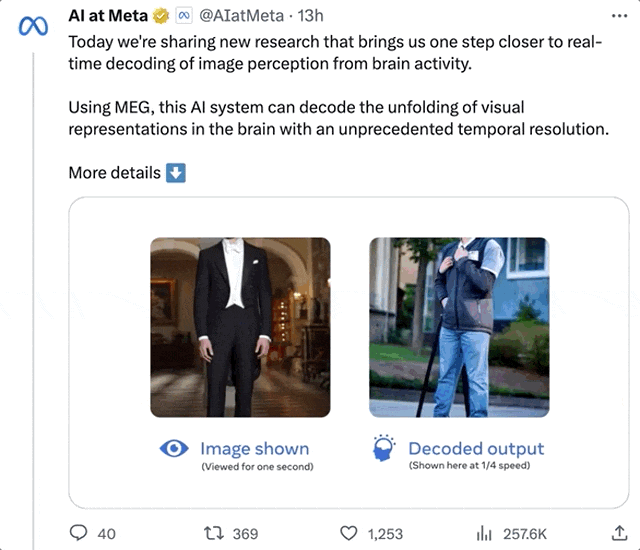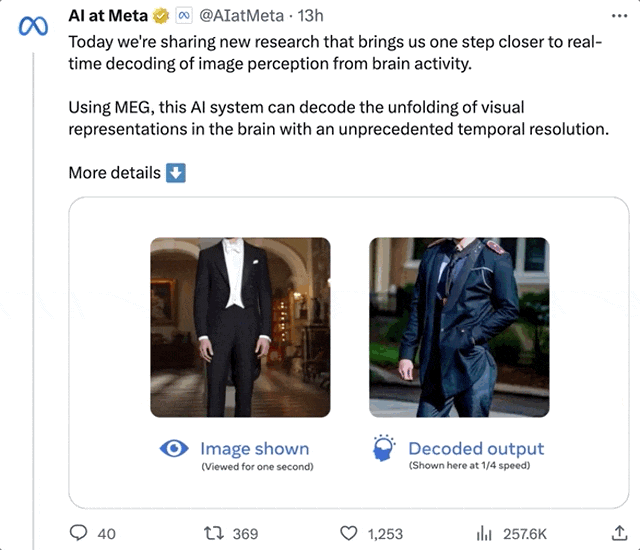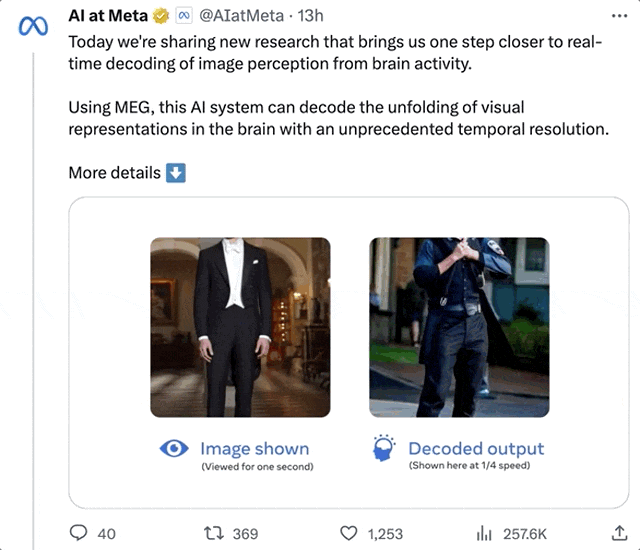
LeCun轉發表示,從MEG腦訊號重建視覺等輸入的研究,確實很棒。
 圖片
圖片
那麼,Meta究竟是怎麼讓AI「快速讀腦」的呢?
目前,AI讀取大腦訊號並還原影像的方法,主要有兩種。
其中一種是fMRI(功能性磁振造影),可以產生流向大腦特定部位的血流影像;另一種是MEG(腦磁圖),可以測量腦內神經電流發出的極其微弱的生物磁場訊號。
然而,fMRI神經成像的速度往往非常慢,平均2秒才出一張圖(≈0.5 Hz),相較之下MEG甚至能在每秒內記錄上千次大腦活動影像( ≈5000 Hz)。
所以比起fMRI,為什麼不用MEG數據來試試還原出「人類看到的圖像」呢?
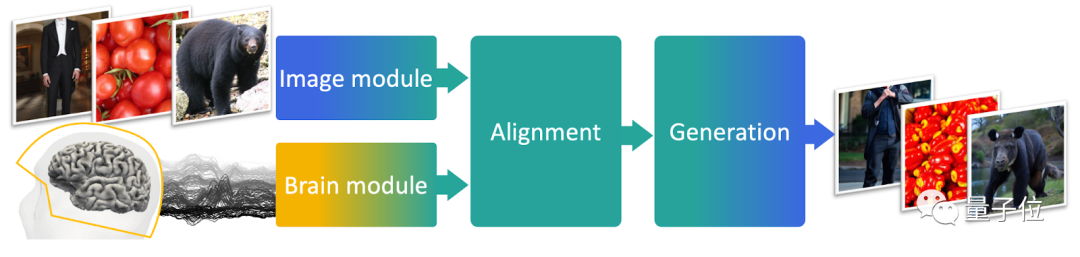
基於這個思路,作者們設計了一個MEG解碼模型,由三個部分組成。
第一部分預訓練模型,負責從圖像中獲得embeddings;
第二部分是一個端到端訓練模型,負責將MEG資料與圖像embeddings對齊;
第三部分是一個預訓練影像產生器,負責還原出最終的影像。
 圖片
圖片
訓練上,研究人員用了一個名叫THINGS-MEG的資料集,包含了4個年輕人(2男2女,平均23.25歲)觀看影像時所記錄的MEG資料。
這些年輕人總共觀看了22448張圖像(1854種類型),每張圖像顯示時間為0.5秒,間隔時間為0.8~1.2秒,其中有200張圖片被反覆觀看。
除此之外,還有3659張圖像沒有展示給參與者,但也被用於圖像檢索中。
所以,這樣訓練出來的AI,效果究竟如何?
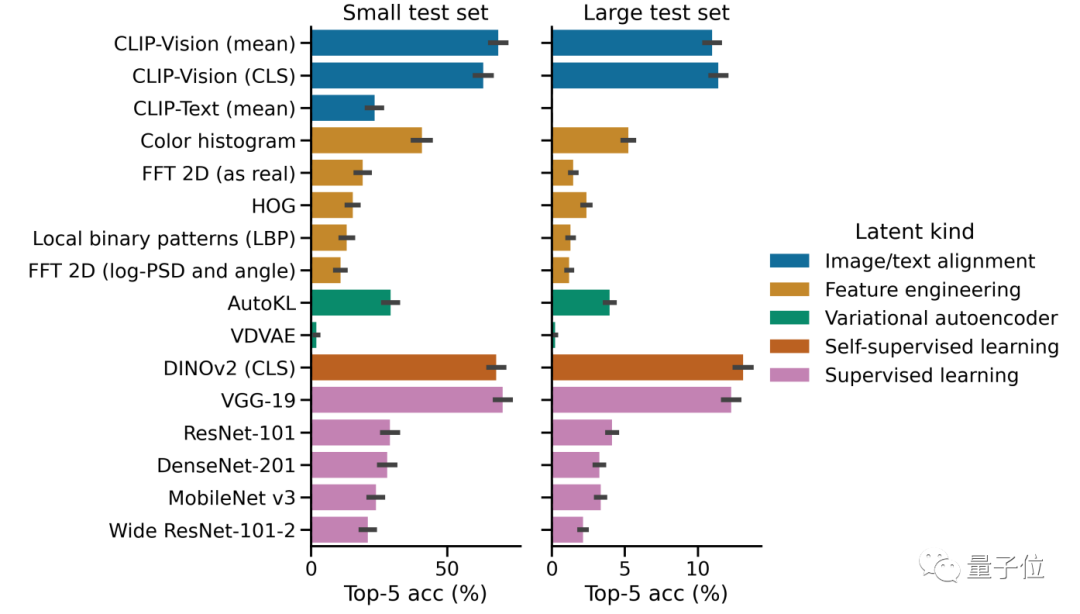
整體來看,這項研究設計的MEG解碼模型,比線性解碼器的影像檢索速度提升了7倍。
其中,比較CLIP等模型,又以Meta研發的視覺Transformer架構DINOv2在擷取影像特徵方面表現較好,更能將MEG資料和影像embeddings對齊。
 圖片
圖片
作者將整體產生的圖像分成了三大類,匹配度最高的、中等的和匹配度最差的:
 圖片
圖片
不過,從生成範例來看,這個AI還原出來的圖片效果,確實不算太好。
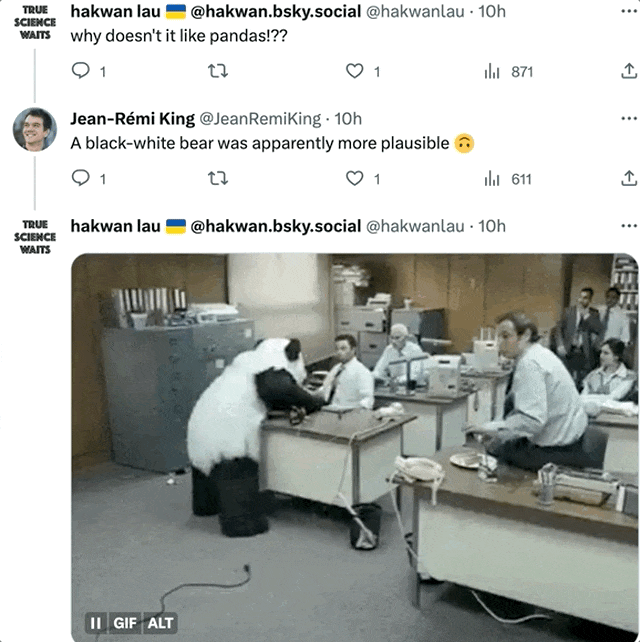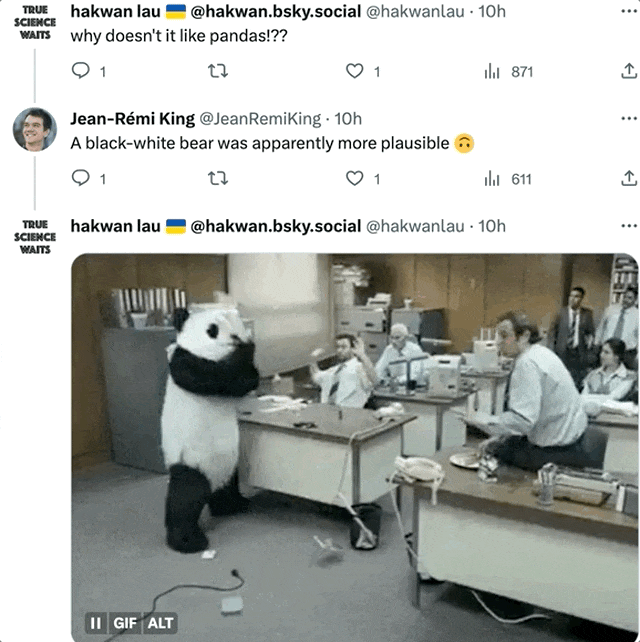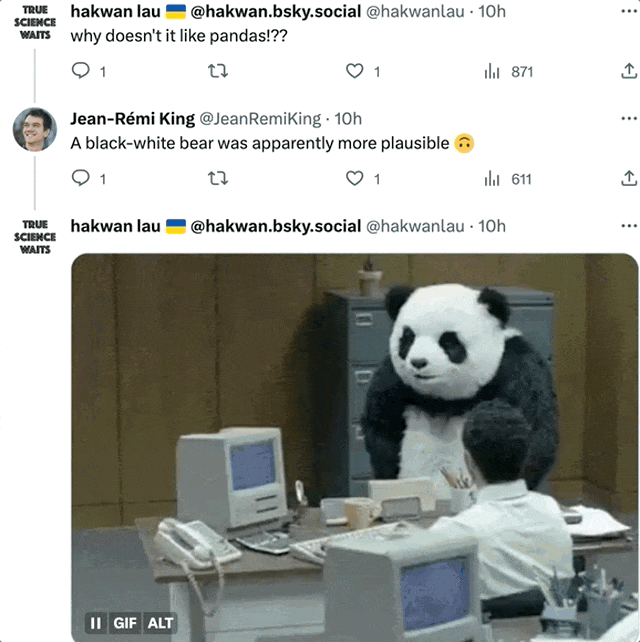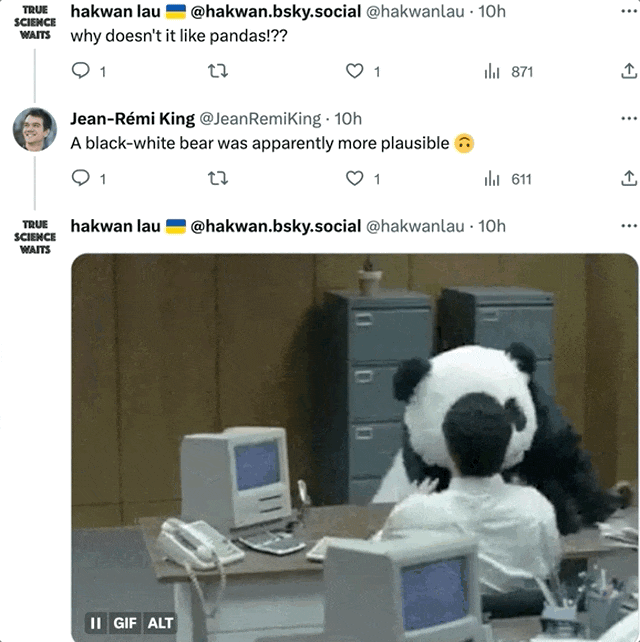
即使是還原度最高的圖像,仍然受到了一些網友的質疑:為什麼熊貓看起來完全不像熊貓?
 圖片
圖片
作者表示:至少像黑白熊。 (熊貓震怒!)
 圖片
圖片
當然,研究人員也承認,MEG數據復原出來的圖像效果,確實目前還不太行,主要優勢還是在速度上。
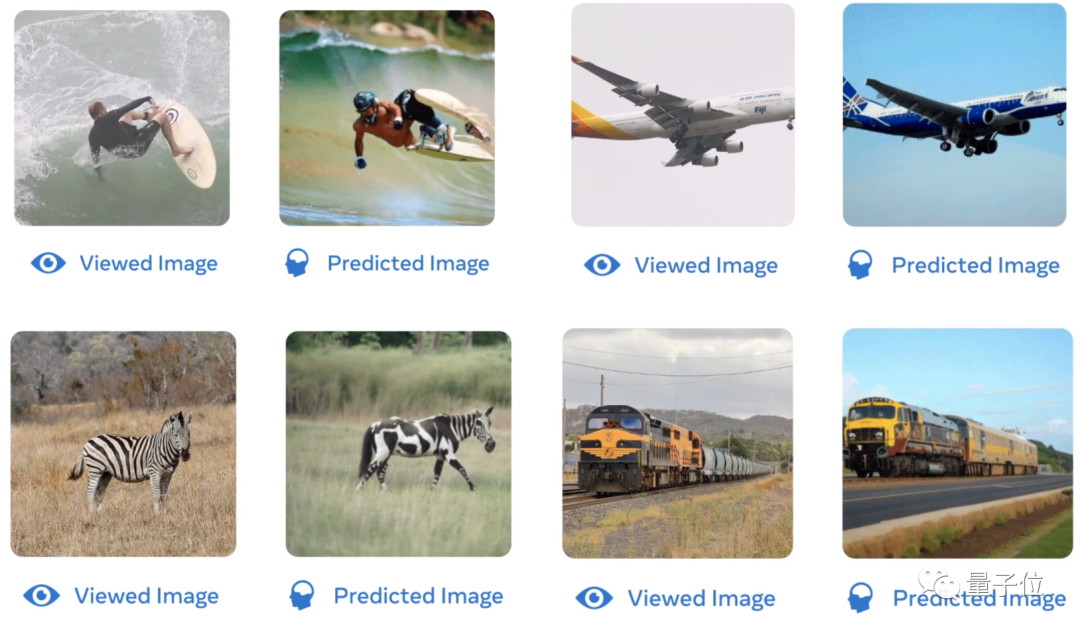
例如先前來自明尼蘇達大學等機構的一項名為7T fMRI的研究,就能以較高的復原度從fMRI資料中還原出人眼看到的影像。
 圖片
圖片
無論是人類的衝浪動作、飛機的形狀、斑馬的顏色、火車的背景,基於fMRI資料訓練的AI都能更好地將圖像還原出來:
 圖片
圖片
對此,作者們也給了解釋,認為這是因為AI基於MEG還原出來的視覺特徵偏高級。
但相較之下,7T fMRI可以擷取並還原出影像中較低階的視覺特徵,這樣產生的影像整體還原度更高。
你覺得這類研究可以用在哪些地方?
論文網址:
//m.sbmmt.com/link/f40723ed94042ea9ea36bfb5ad4157b2
以上是AI即時解讀大腦訊號,7倍速還原影像關鍵視覺特徵,LeCun轉發的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















