

眾所周知,對 GPT-3.5 進行微調是非常昂貴的。本文透過實驗來驗證手動微調模型是否可以接近 GPT-3.5 的效能,而成本只是 GPT-3.5 的一小部分。有趣的是,本文確實做到了。
在SQL 任務和functional representation 任務上的結果對比,本文發現:
本實驗的結論之一是微調GPT-3.5 適用於初始驗證工作,但在那之後,像Llama 2 這樣的模型可能是最佳選擇,簡單總結一下:
接下來我們來看看,本文是如何實現的。
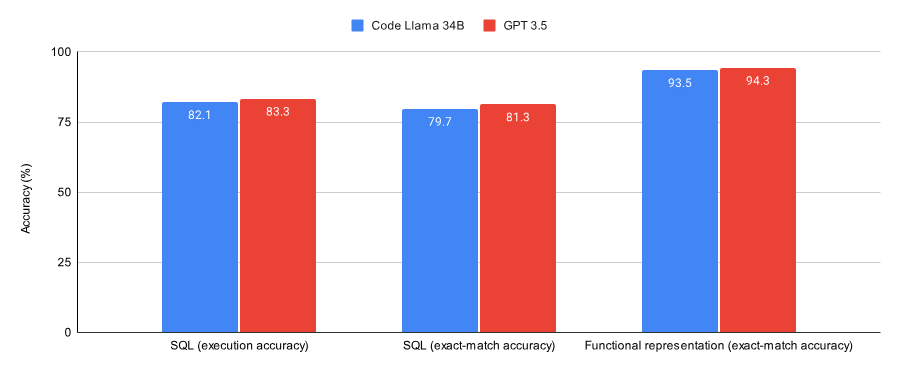
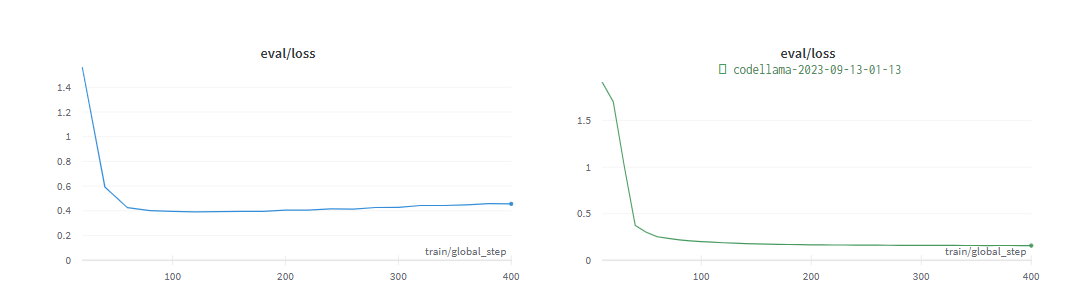
下圖為 Code Llama 34B 和 GPT-3.5 在 SQL 任務和 functional representation 任務上訓練至收斂的效能。結果表明,GPT-3.5 在這兩個任務上都取得了更好的準確率。
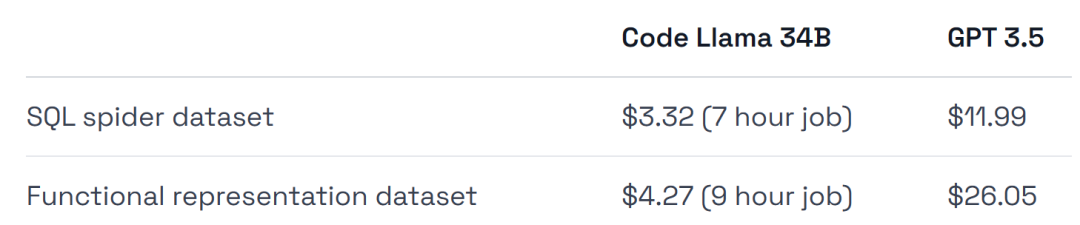
在硬體使用上,實驗使用的是 A40 GPU,每小時約 0.475 美元。
此外,實驗選取了兩個非常適合進行微調的資料集,Spider 資料集的子集以及Viggo functional representation 資料集。
為了與 GPT-3.5 模型進行公平的比較,實驗對 Llama 進行了最少超參數微調。
本文實驗的兩個關鍵選擇是使用 Code Llama 34B 和 Lora 微調,而不是全參數微調。
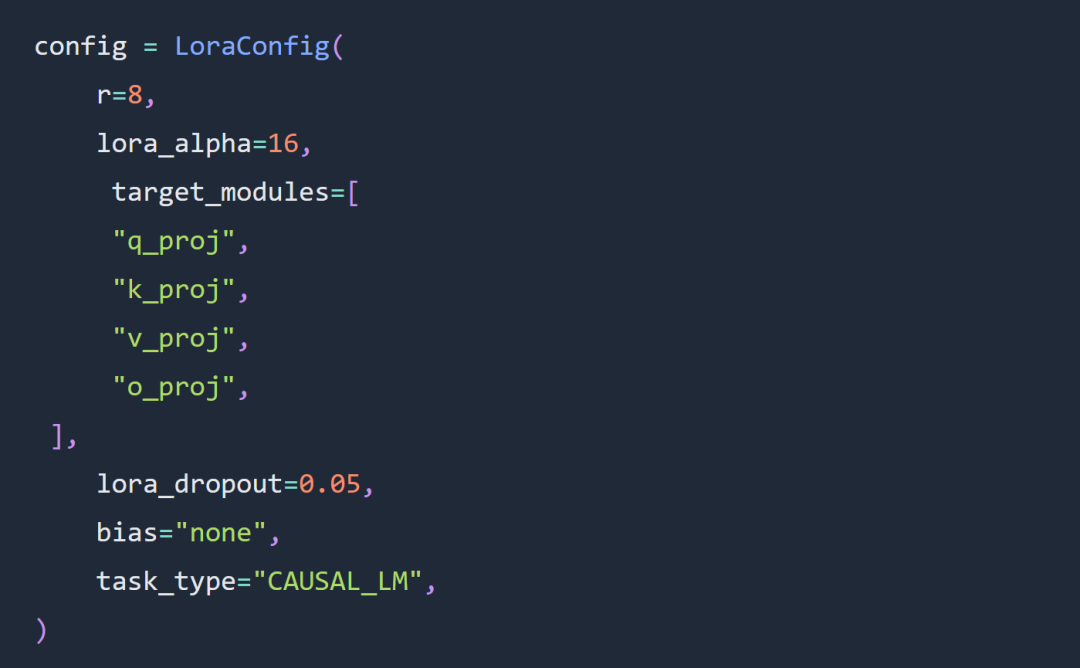
實驗在很大程度上遵循了有關Lora 超參數微調的規則,Lora 適配器配置如下:
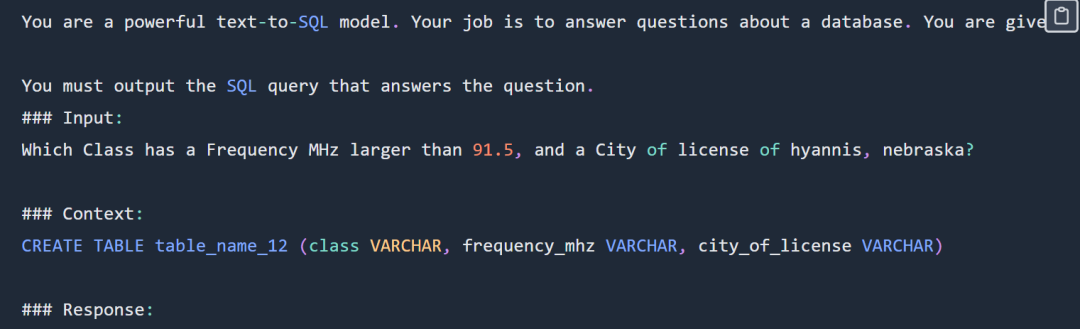
SQL 提示範例如下:
#SQL 提示部分展示,完整提示請查看原始部落格
實驗沒有使用完整的Spider 資料集,具體形式如下
department : Department_ID [ INT ] primary_key Name [ TEXT ] Creation [ TEXT ] Ranking [ INT ] Budget_in_Billions [ INT ] Num_Employees [ INT ] head : head_ID [ INT ] primary_key name [ TEXT ] born_state [ TEXT ] age [ INT ] management : department_ID [ INT ] primary_key management.department_ID = department.Department_ID head_ID [ INT ] management.head_ID = head.head_ID temporary_acting [ TEXT ]
實驗選擇使用sql-create-context 資料集和Spider 資料集的交集。為模型提供的上下文是一個SQL 建立命令,如下所示:
CREATE TABLE table_name_12 (class VARCHAR, frequency_mhz VARCHAR, city_of_license VARCHAR)
#SQL 任務的程式碼和資料位址:https://github.com/samlhuillier/spider-sql- finetune
functional representation 提示的範例如下:
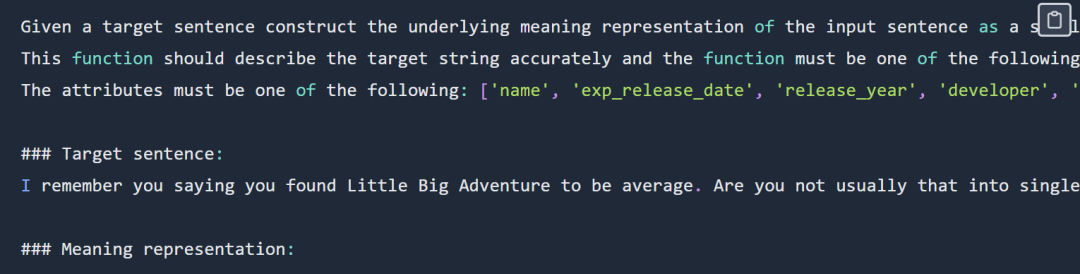
##functional representation 提示部分展示,完整提示請查看原始部落格
輸出如下:
verify_attribute(name[Little Big Adventure], rating[average], has_multiplayer[no], platforms[PlayStation])
#了解更多內容,請查看原始部落格。
以上是選擇GPT-3.5、還是微調Llama 2等開源模型?綜合比較後答案有了的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















