遮罩建模(MIM, MAE)已被證明是非常有效的自監督訓練方法。然而,如圖 1 所示,MIM 對於更大的模型效果相對較好。當模型很小的時候(例如 ViT-T 5M 參數,這樣的模型對於現實世界非常重要),MIM 甚至可能在某種程度上降低模型的效果。例如用 MAE 訓練的 ViT-L 比一般監督訓練的模型在 ImageNet 上的分類效果提升 3.3%,但用 MAE 訓練的 ViT-T 比一般監督訓練的模型在 ImageNet 上的分類效果降低了 0.6%。
在這篇工作中我們提出了TinyMIM,其在保持ViT 結構不變並且不修改結構引入其他歸納偏壓(inductive bias)的基礎上、用蒸餾的方法遷移大模型上的知識到小模型。

-
論文網址:https://arxiv.org/pdf/2301.01296.pdf
-
程式碼位址:https://github.com/OliverRensu/TinyMIM
#我們系統性的研究了蒸餾目標、資料增強、正則化、輔助損失函數等對於蒸餾的影響。在嚴格的只用 ImageNet-1K 作為訓練資料的情況下(包括 Teacher model 也只用 ImageNet-1K 訓練)和 ViT-B 作為模型,我們的方法實現了當前最好的效能。如圖所示:
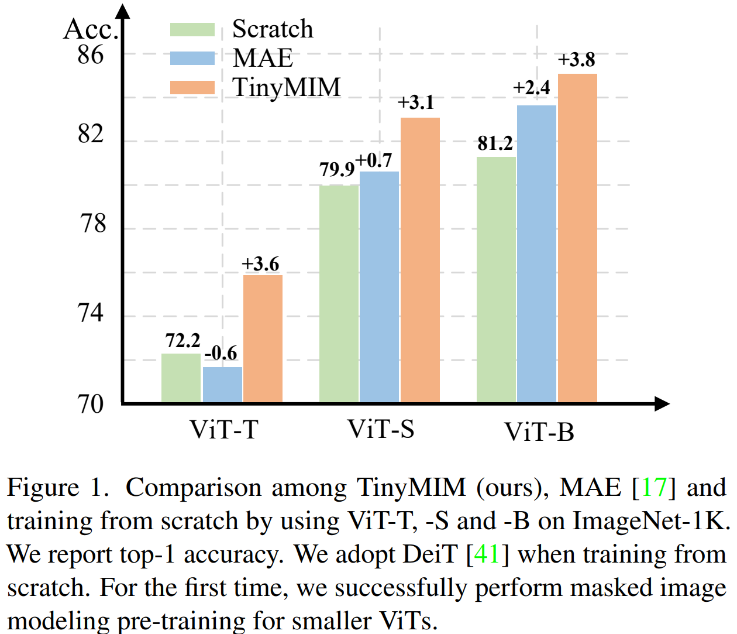
把我們的方法(TinyMIM)和基於掩碼重建的方法MAE,以及監督式學習的方法從頭開始訓練的DeiT 進行比較。 MAE 在模型比較大的時候有顯著的效能提升,但在模型比較小的時候提升幅度有限甚至會傷害模型的最終效果。我們的方法 TinyMIM 在不同模型的大小上都有大幅提升。
#1. 蒸餾的目標(Distillation targets):1)蒸餾token 之間的關係比單獨蒸餾class token 或特徵圖(feature map)更有效;2)以中間層作為蒸餾的目標更有效。
2. 資料增強和模型正規化(Data and network regularization):1)用帶有遮罩的圖片效果較差;2)學生模型需要一點 drop path,但是 teacher 模型不需要。
3. 輔助損失函數(auxiliary losses):MIM 作為輔助損失函數沒有意義。
4. 宏觀蒸餾策略(Macro distillation strategy):我們發現序列化的蒸餾(ViT-B -> ViT-S -> ViT-T)效果最好。
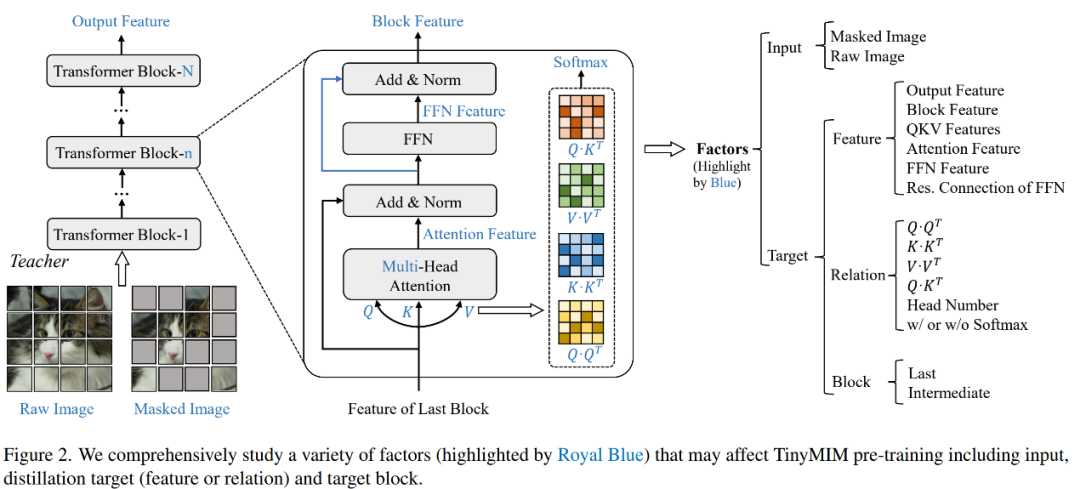
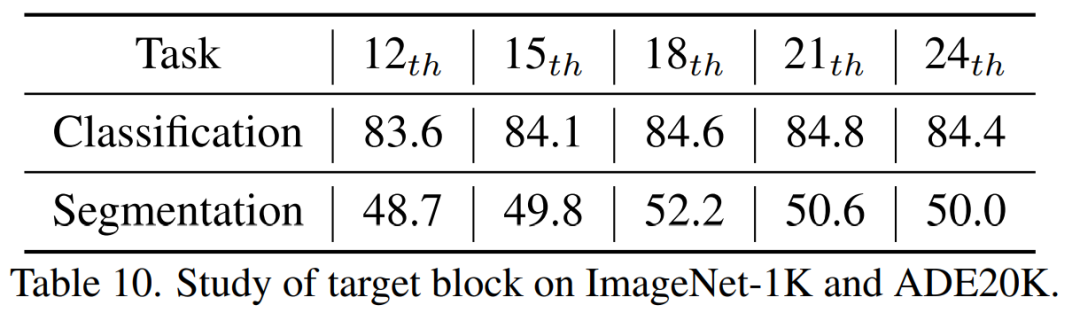
我們系統性的研究了蒸餾的目標,輸入的圖片,蒸餾目標模組。
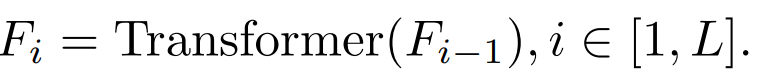
當i=L 時,指的是Transformer 輸出層的特徵。當 i
b. 注意力(Attention)特徵與前饋層(FFN)層特徵
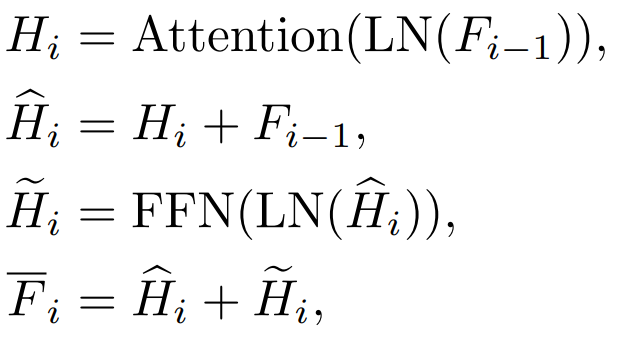
Transformer 每一個block 有Attention 層和FFN 層,蒸餾不同的層會帶來不同的影響。
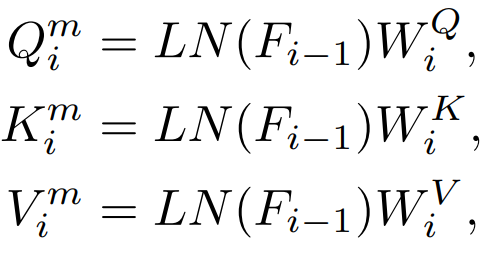
在Attention 層內會有Q,K,V 特徵,這些特徵用於計算注意力機制,我們也研究了直接蒸餾這些特徵。

Q,K,V 用來計算注意力圖,這些特徵之間的關係也可以作為知識蒸餾的目標。
傳統的知識蒸餾是直接輸入完整的圖片。我們的方法為了探索蒸餾遮罩建模模型,所以我們也探索了帶有遮罩的圖片是否適合作為知識蒸餾時候的輸入。
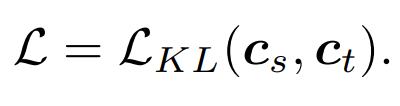
最簡單的方法就是類似DeiT 直接蒸餾MAE 預訓練模型的class token:
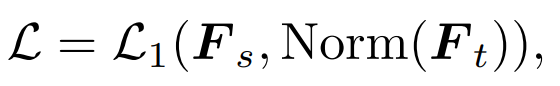
其中
指學生模型的class token,而
指老師模型的class token。
2)特徵蒸餾:我們直接參考了feature distillation [1] 作為對比
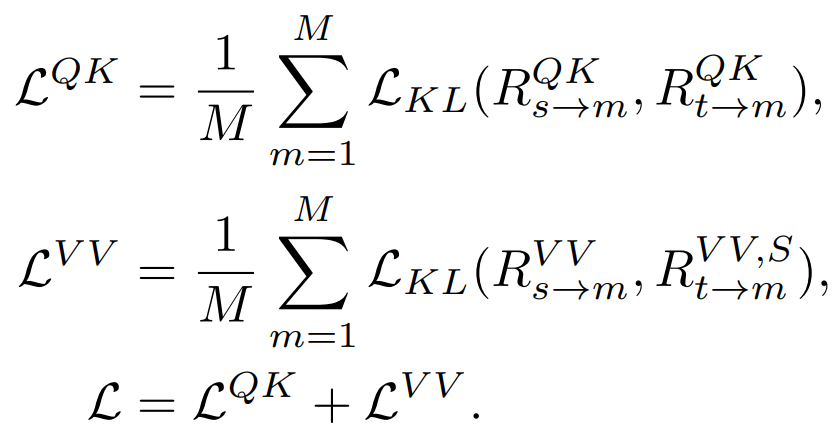
三、實驗
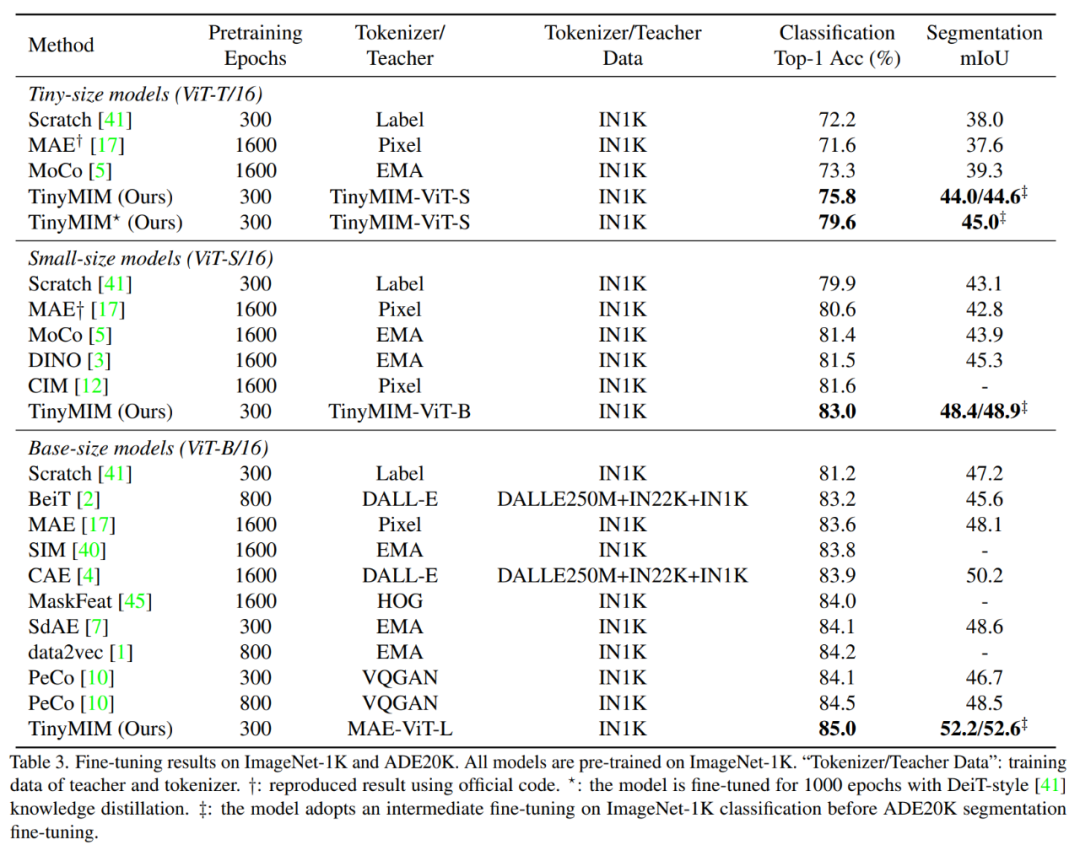
###3.1 主要實驗結果##################我們的方法在ImageNet-1K 上預先訓練,而且教師模型也是在ImageNet-1K 預先訓練。然後我們將我們預先訓練的模型在下游任務(分類、語義分割)上進行了微調。模型表現如圖:#####################
我们的方法显著超过之前基于 MAE 的方法,尤其是小模型。具体来讲,对于超小的模型 ViT-T,我们的方法实现了 75.8% 的分类准确性,相比 MAE 基线模型实现了 4.2 的提升。对于小模型 ViT-S,我们实现了 83.0% 的分类准确性,比之前最好的方法提升了 1.4。对于 Base 尺寸的模型,我们的方法分别超过 MAE 基线模型和以前最好的模型 CAE 4.1 和 2.0。
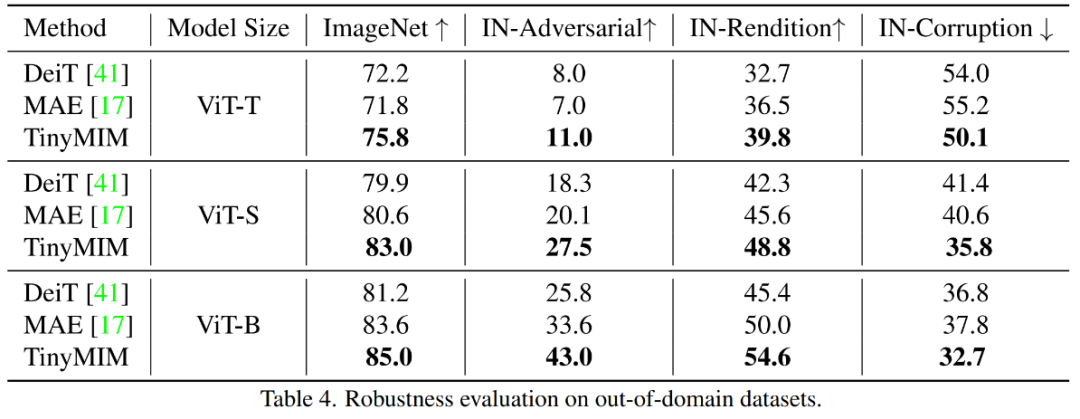
TinyMIM-B 对比 MAE-B,在 ImageNet-A 和 ImageNet-R 分别提升了 6.4 和 4.6。
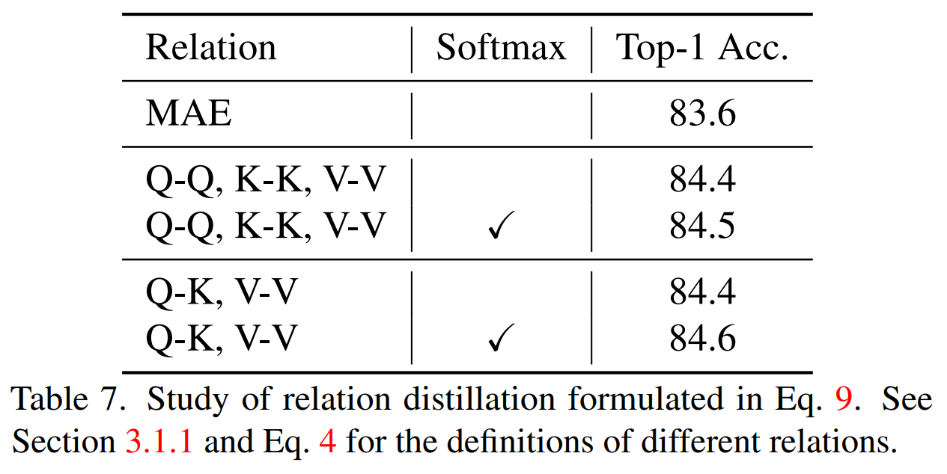
同时蒸馏 QK,VV 关系而且在计算关系的时候有 Softmax 实现了最好的效果。
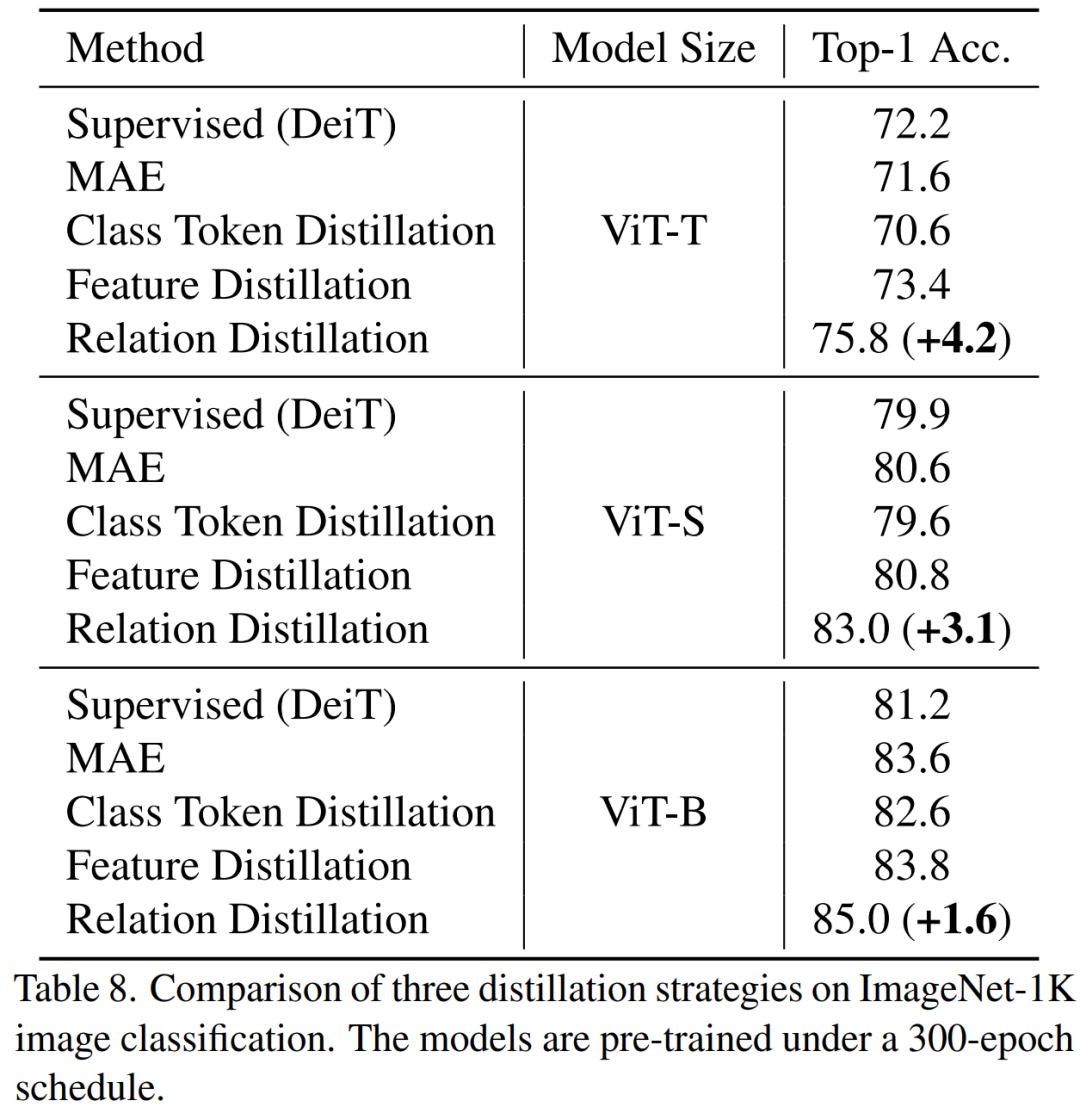
TinyMIM 这种蒸馏关系的方法实现了比 MAE 基线模型,class token 蒸馏,特征图蒸馏都更好的效果,在各种尺寸的模型上都是如此。
在本文中,我们提出了 TinyMIM,它是第一个成功地使小模型受益于掩码重建建模(MIM)预训练的模型。我们没有采用掩码重建作为任务,而是通过以知识蒸馏的方式训练小模型模拟大模型的关系来预训练小模型。TinyMIM 的成功可以归功于对可能影响 TinyMIM 预训练的各种因素的全面研究,包括蒸馏目标、蒸馏输入和中间层。通过大量的实验,我们得出结论,关系蒸馏优于特征蒸馏和类标记蒸馏等。凭借其简单性和强大的性能,我们希望我们的方法能够为未来的研究提供坚实的基础。
[1] Wei, Y., Hu, H., Xie, Z., Zhang, Z., Cao, Y., Bao, J., ... & Guo, B. (2022). Contrastive learning rivals masked image modeling in fine-tuning via feature distillation. arXiv preprint arXiv:2205.14141.
以上是微軟亞洲研究院推出TinyMIM:透過知識蒸餾提升小型ViT的效能的詳細內容。更多資訊請關注PHP中文網其他相關文章!




































