

多年來,Transformer、Large-kernel CNN和MLP這三個視覺主幹網路在廣泛的電腦視覺任務中取得了巨大的成功,這主要歸功於它們在全局範圍內高效地融合信息的能力
Transformer、CNN和MLP是當前三種主流的神經網絡,它們分別採用不同的方式來實現全域範圍的Token融合。在Transformer網路中,自註意力機制利用查詢-鍵對的相關性作為Token融合的權重。 CNN透過擴大卷積核的尺寸來實現與Transformer相似的性能。而MLP則透過全連接在所有令牌之間實現另一個強大的範式。儘管這些方法都是有效的,但它們的運算複雜度較高(O(N^2)),難以在儲存和運算能力有限的裝置上部署,從而限制了許多模型的應用範圍
為了解決計算昂貴的問題,研究人員開發了一種名為自適應傅裡葉濾波器(Adaptive Fourier Filter,AFF)的高效全域Token融合演算法。此演算法利用傅立葉變換將Token集合轉換到頻域,並在頻域學習到一個能夠自適應內容的濾波掩膜,以對轉換到頻域空間中的Token集合進行自適應濾波操作
Adaptive Frequency Filters: Efficient Global Token Mixers

#點擊此連結可存取原文:https://arxiv .org/abs/2307.14008
根據頻域卷積定理,AFF Token Mixer 的數學等價操作是在原始域中進行的捲積操作,相當於在傅立葉域中進行的Hadamard乘積操作。這意味著AFF Token Mixer 可以透過在原始域中使用動態卷積核,其空間解析度與Token集合大小相同,來實現內容自適應的全域Token融合(如下圖右子圖所示)
眾所周知,動態卷積的運算成本很高,尤其是在使用大空間解析度的動態卷積核時,對於高效能/ 輕量級網路設計來說,這種成本似乎是難以接受的。然而,本文提出的AFF Token Mixer 卻能夠以低功耗的等效實現方式同時滿足上述要求,將複雜性從O (N^2) 降低到O (N log N),從而顯著提高了計算效率
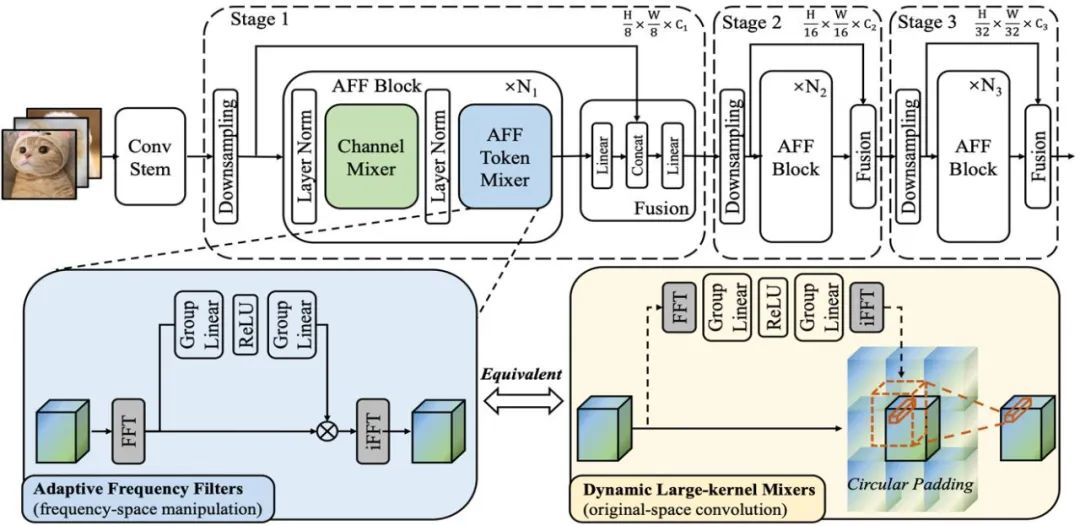
示意圖1:展示了AFF 模組和AFFNet 網路的結構
透過將AFF Token Mixer 作為主要神經網路操作算子,研究人員成功建構了一個稱為AFFNet 的輕量級神經網路。豐富的實驗結果表明,AFF Token Mixer 在廣泛的視覺任務中取得了卓越的準確性和效率平衡,包括視覺語義識別和密集預測任務
研究人員評估了AFF Token Mixer和AFFNet在視覺語義識別、分割、檢測等多個任務上的性能,並與目前研究領域中最先進的輕量級視覺主幹網路進行了比較。實驗結果顯示,該模型設計在廣泛的視覺任務中表現出色,證實了AFF Token Mixer作為新一代輕量級高效的Token融合算子的潛力
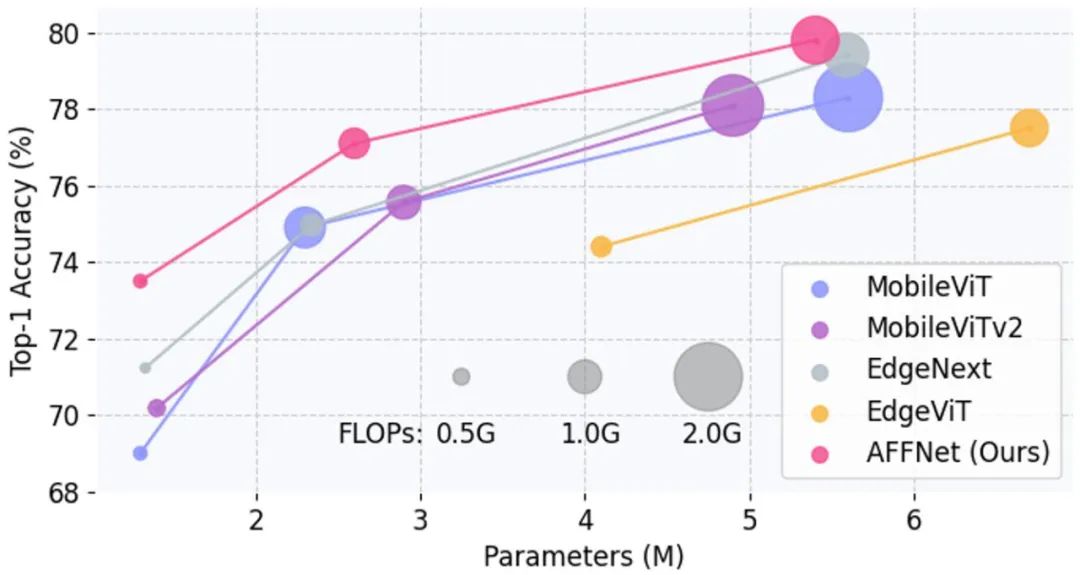
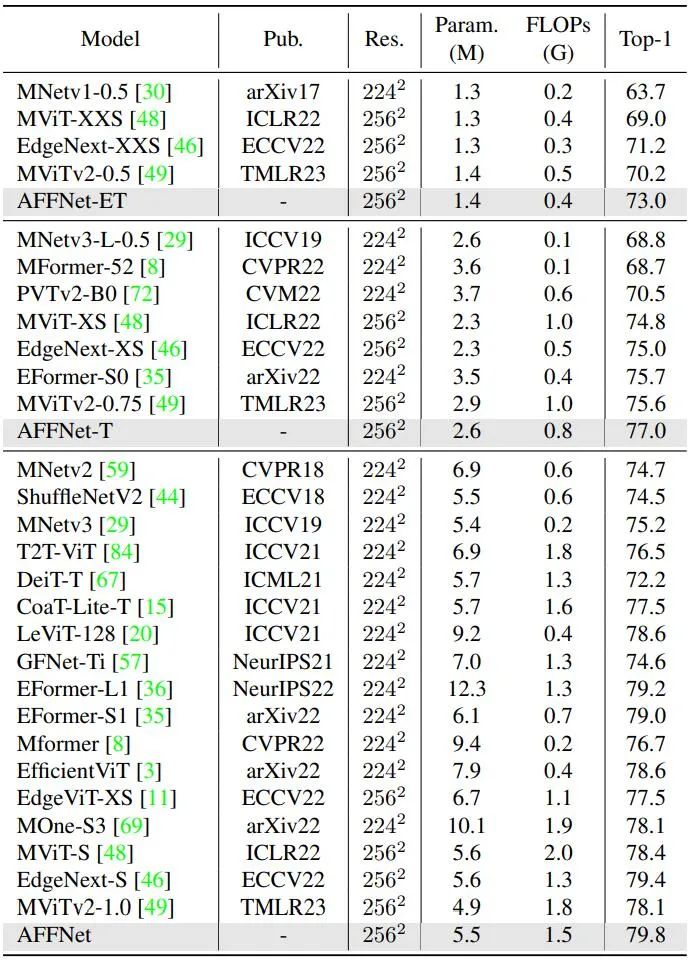
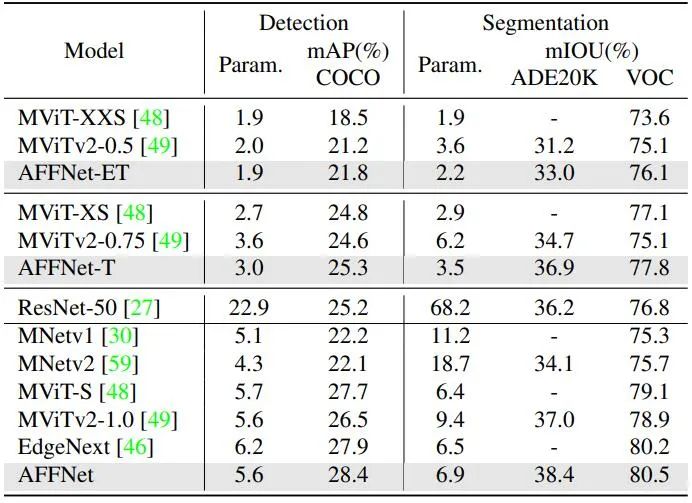
這項研究證明了隱空間中的頻域變換在全域自適應Token 融合中起到了重要作用,是一種高效且低功耗的等效實現方式。它為神經網路中的Token 融合算子設計提供了新的研究思路,並為在邊緣設備上部署神經網路模型提供了新的發展空間,尤其是在儲存和運算能力有限的情況下5. 結論
以上是輕量級視覺網路新主幹:高效率的傅立葉算符Token混合器的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















