

在使用Python本爬蟲採集資料時,一個很重要的操作就是如何從請求到的網頁中提取資料,而正確定位想要的資料又是第一步操作。
本文將比較幾種Python 爬蟲中比較常用的定位網頁元素的方式供大家學習
“」
傳統 BeautifulSoup操作基於 BeautifulSoup的CSS 選擇器(與PyQuery類似)XPath正規表示式
參考網頁是當網圖書暢銷總榜:
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1
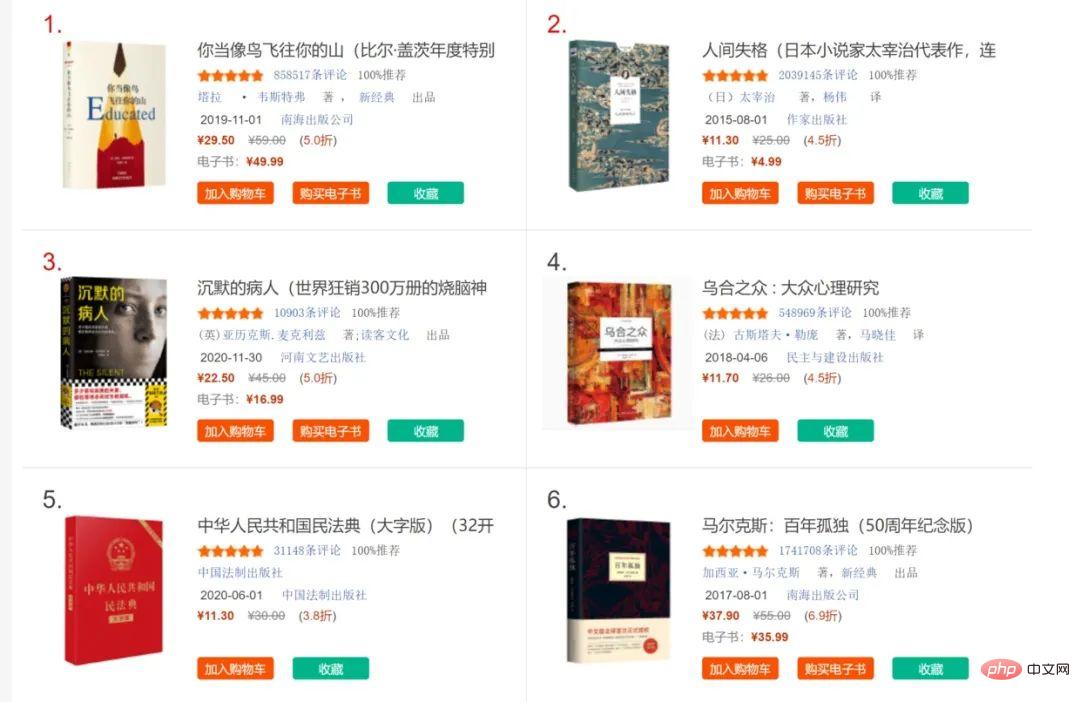
我們以取得第一頁 20 本書的書名為範例。先確定網站沒有設定反爬措施,是否能直接回傳待解析的內容:
import requests url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text print(response)
#仔細檢查後發現需要的資料都在回傳內容中,說明不需要特別考慮反爬舉措
審查網頁元素後可以發現,書目資訊都包含在li中,從屬於class為bang_list clearfix bang_list_mode的ul中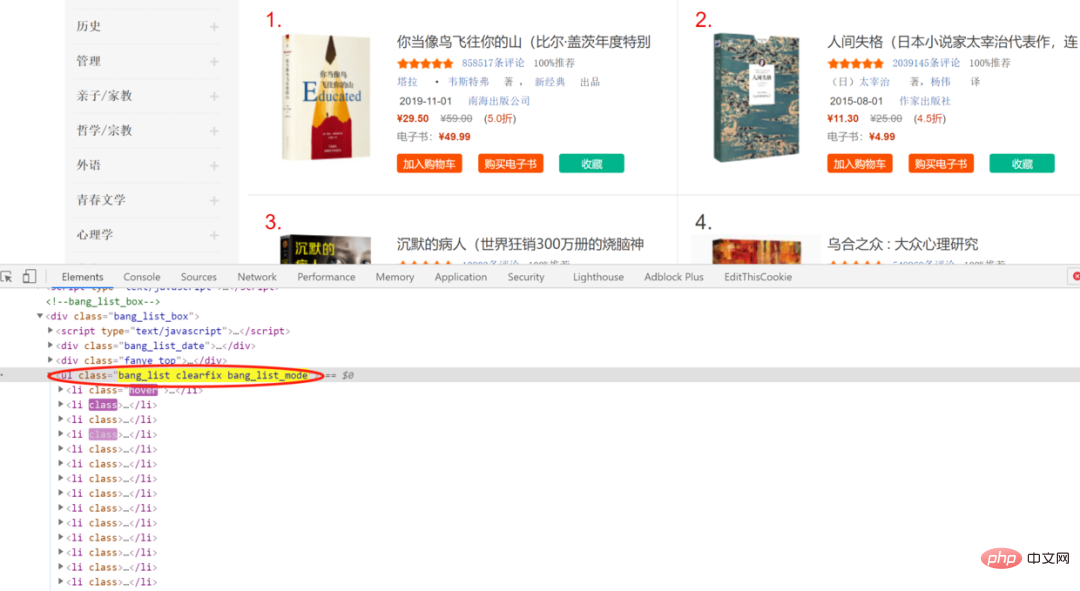
進一步檢視也可以發現書名在的對應位置,這是多種解析方法的重要基礎
經典的BeautifulSoup 方法借助from bs4 import BeautifulSoup,然後透過soup = BeautifulSoup(html, "Soup(html, "Soup# lxml")將文字轉換為特定規範的結構,利用find
import requests from bs4 import BeautifulSoup url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def bs_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.find('ul', class_='bang_list clearfix bang_list_mode').find_all('li') # 锁定ul后获取20个li for li in li_list: title = li.find('div', class_='name').find('a')['title'] # 逐个解析获取书名 print(title) if __name__ == '__main__': bs_for_parse(response)

这种方法实际上就是 PyQuery 中 CSS 选择器在其他模块的迁移使用,用法是类似的。关于 CSS 选择器详细语法可以参考:http://www.w3school.com.cn/cssref/css_selectors.asp由于是基于 BeautifulSoup 所以导入的模块以及文本结构转换都是一致的:
import requests from bs4 import BeautifulSoup url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def css_for_parse(response): soup = BeautifulSoup(response, "lxml") print(soup) if __name__ == '__main__': css_for_parse(response)
然后就是通过soup.select辅以特定的 CSS 语法获取特定内容,基础依旧是对元素的认真审查分析:
import requests from bs4 import BeautifulSoup from lxml import html url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def css_for_parse(response): soup = BeautifulSoup(response, "lxml") li_list = soup.select('ul.bang_list.clearfix.bang_list_mode > li') for li in li_list: title = li.select('div.name > a')[0]['title'] print(title) if __name__ == '__main__': css_for_parse(response)
XPath 即为 XML 路径语言,它是一种用来确定 XML 文档中某部分位置的计算机语言,如果使用 Chrome 浏览器建议安装XPath Helper插件,会大大提高写 XPath 的效率。
之前的爬虫文章基本都是基于 XPath,大家相对比较熟悉因此代码直接给出:
import requests from lxml import html url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text def xpath_for_parse(response): selector = html.fromstring(response) books = selector.xpath("//ul[@class='bang_list clearfix bang_list_mode']/li") for book in books: title = book.xpath('div[@class="name"]/a/@title')[0] print(title) if __name__ == '__main__': xpath_for_parse(response)
如果对 HTML 语言不熟悉,那么之前的几种解析方法都会比较吃力。这里也提供一种万能解析大法:正则表达式,只需要关注文本本身有什么特殊构造文法,即可用特定规则获取相应内容。依赖的模块是re
首先重新观察直接返回的内容中,需要的文字前后有什么特殊:
import requests import re url = 'http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-24hours-0-0-1-1' response = requests.get(url).text print(response)

 观察几个数目相信就有答案了:
观察几个数目相信就有答案了:
相關標籤:
來源:Python当打之年
本網站聲明
本文內容由網友自願投稿,版權歸原作者所有。本站不承擔相應的法律責任。如發現涉嫌抄襲或侵權的內容,請聯絡admin@php.cn
作者最新文章
2023-08-15 15:07:54
2023-08-15 15:03:09
2023-08-15 15:01:56
2023-08-15 14:56:46
2023-08-15 14:55:25
2023-08-15 14:53:11
2023-08-15 14:48:06
2023-08-15 14:42:31
2023-08-15 14:41:13
2023-08-15 14:39:02
最新問題
如何在 google chrome 中從 HTML 執行 python 腳本?
我正在建立一個chrome擴充程序,我想透過點擊擴充功能(基本上是HTML)中的按鈕來運行我的PC中的python腳本。 python腳本使用seleniumweb-driver從...
來自於 2023-11-02 23:34:24
0
1
400
為什麼有些mysql連接在刪除+插入後選擇mysql資料庫的舊資料?
我的python/wsgiWeb應用程式中的會話出現問題。 2個wsgi守護程式中的每個執行緒都有一個不同的、持久的mysqldb連線。有時,在刪除舊會話並建立新會話後,某些連線仍...
來自於 2023-10-30 12:37:20
0
2
229
Python中使用變數執行SQL語句
我有以下Python程式碼:cursor.execute("INSERTINTOtableVALUESvar1,var2,var3,")其中var1是整數,va...
來自於 2023-10-12 15:06:00
0
2
258
理解Python中的三元運算子 [重複]
我目前正在從JavaScript過渡到Python,我想知道Python是否有類似JavaScript的三元運算子。在JavaScript中,我會這樣寫一個三元操作:leta=10...
來自於 2023-09-21 18:46:04
0
1
377


































