

IT之家 7 月 11 日消息,王小川旗下百川智能今日發表 Baichuan-13B 大模型,號稱「130 億參數開源可商用」。
▲ 圖表來源 Baichuang-13B GitHub 頁面
根據官方介紹,Baichuan-13B 是由百川智能繼Baichuan-7B 之後開發的包含130 億參數的開源可商用的大規模語言模型,在中英文Benchmark 上均取得同尺寸模型中最好的效果。本次發布包含有預訓練 (Baichuan-13B-Base) 和對齊 (Baichuan-13B-Chat) 兩個版本。
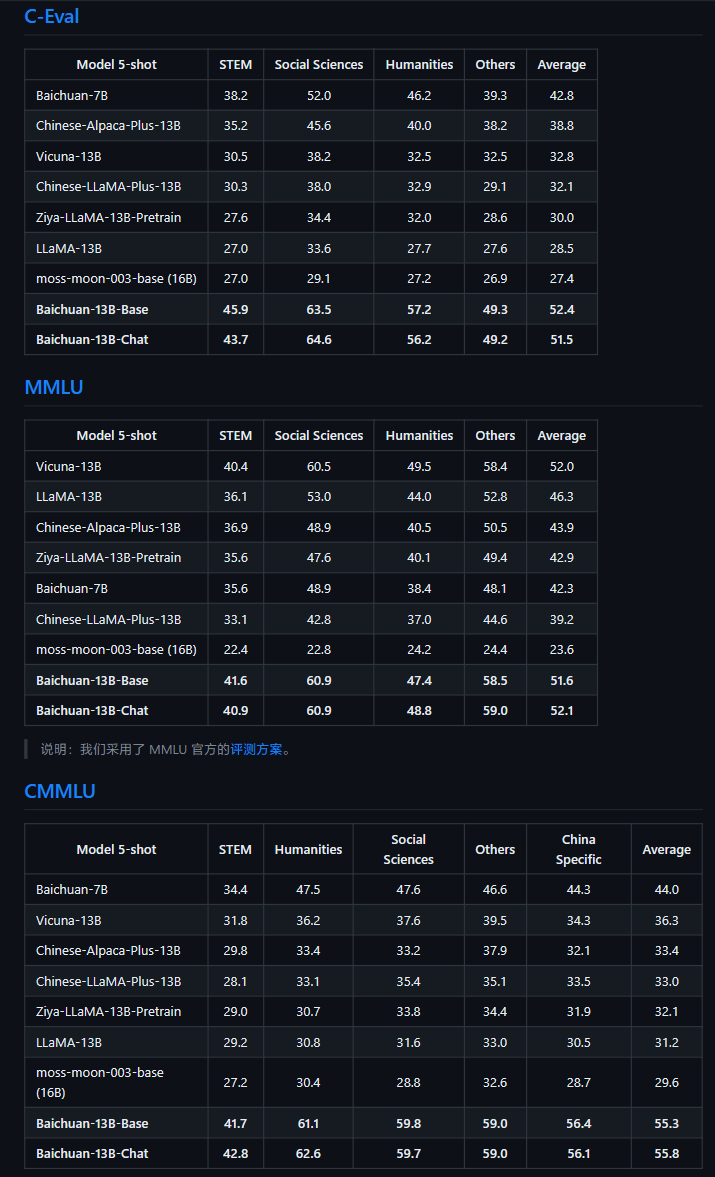
▲ 圖表來源 Baichuang-13B GitHub 頁面
官方宣稱,Baichuan-13B 有以下幾個特點:
- 更大尺寸、更多數據:Baichuan-13B 在Baichuan-7B 的基礎上進一步擴大參數量到130 億,並且在高品質的語料上訓練了1.4 萬億tokens,超過LLaMA-13B40%,是目前開源13B 尺寸下訓練資料量最多的模型。支援中英雙語,使用 ALiBi 位置編碼,上下文視窗長度為 4096。
- 同時開源預訓練和對齊模型:預訓練模型是適用開發者的‘ 基座 ’,而廣大普通用戶對有對話功能的對齊模型具有更強的需求。因此專案中同時具有對齊模型(Baichuan-13B-Chat),具有很強的對話能力,開箱即用,幾行程式碼即可簡單部署。
- 更有效率的推理:為了支援更廣大用戶的使用,專案中同時開源了int8 和int4 的量化版本,相對非量化版本在幾乎沒有效果損失的情況下大大降低了部署的機器資源門檻,可以部署在如英偉達RTX3090 這樣的消費級顯示卡上。
- 開源免費可商用:Baichuan-13B 不僅對學術研究完全開放,開發者也僅需郵件申請並獲得官方商用許可後,即可以免費商用。
目前模型已經在 HuggingFace、GitHub、Model Scope 公佈,有興趣的 IT之家小夥伴們可以前往了解。
以上是百川智慧發布Baichuan-13B AI模型,號稱'130億參數開源可商用”的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















