

所以,如果我們使用UUID 字串作為主鍵,那麼就會導致每次資料插入的時候,都需要在B Tree 中尋找到適合它自己的位置,找到之後就有可能要挪動後面的節點(就像在數組中插入一條記錄),挪動後面的節點,就有可能涉及到頁分裂,插入效率就會降低。
另一方面,在非聚集索引中,葉子結點保存的是主鍵值,主鍵如果是一個很長的UUID 字串,就會佔據較大的儲存空間(相對int 而言),那麼同一個葉子結點能夠保存的主鍵值數量就會減少,進而可能會導致樹變高,樹變高,意味著查詢的時候IO 次數增加,查詢效率降低。
基於上面的分析,我們在 MySQL 中盡量不使用 UUID 作為主鍵,不用 UUID,可能會有小夥伴想到,那我使用主鍵自增行不行?
主鍵自增很明顯可以解決使用 UUID 作為主鍵所遇到的兩個問題。主鍵自增,每次只需要往樹的末尾添加就行了,基本上不會涉及到頁分裂問題;主鍵自增意味著主鍵是數字,佔用的存儲空間相對來說就比較小,對非聚簇索引的影響也會小一些。
那麼主鍵自增就是最佳方案嗎?主鍵自增有沒有一些需要注意的問題?
以下內容,有一個共同的大前提,就是我們的表設定了主鍵自增。
#一般來說,主鍵自增是沒有什麼問題的。但是,如果在高並發環境下,就會有問題了。
首先最容易想到的就是在高並發插入的時候產生的尾部熱點問題,並發插入時,大家都需要去查詢這個值然後計算出自己的主鍵值,那麼主鍵的上界就會成為熱點數據,並發插入時這裡會產生鎖定競爭。
為了解決這個問題,我們就需要選擇適合自己的 innodb_autoinc_lock_mode。
首先,我們在向資料表中插入資料的時候,一般來說有三種不同的形式,分別如下:
insert into user(name) values('javaboy') 或replace into user(name) values('javaboy') ,這種沒有巢狀子查詢並且能夠確定具體插入多少行的插入叫做simple insert,不過需要注意的是INSERT ... ON DUPLICATE KEY UPDATE 不算是 simple insert。
load data 或insert into user select ... from ....,這種都是批次插入,叫做bulk insert,這種批次插入有一個特點就是插入多少資料在一開始是未知的。
insert into user(id,name) values(null,'javaboy'),(null,'江南一點雨'),這種也是批量插入,但是跟第二種又不太一樣,這種裡邊包含了一些自動生成的值(本案例中的主鍵自增),並且能夠確定一共插入多少行,這種稱為mixed insert,對於前面第一點提到的INSERT ... ON DUPLICATE KEY UPDATE 也算是一種mixed insert。
將資料插入分為這三類,主要是因為在主鍵自增的時候,鎖的處理方案不同,我們繼續往下看。
我們可以透過控制 innodb_autoinc_lock_mode 變數的值,來控制在主鍵自增的時候,MySQL 鎖定的處理思路。
innodb_autoinc_lock_mode 變數一共有三個不同的取值:
0: 這個表示traditional,在這個模式下,我們上面提到的三種不同的插入SQL,對於自增鎖的處理方案是一致的,都是在插入SQL 語句開始的時候,取得到一個表級的AUTO-INC 鎖,然後當插入SQL 執行完畢之後,再釋放掉這把鎖,這樣做的好處是可以確保在批次插入的時候,自增主鍵是連續的。
1: 這個表示consecutive,在這個模式下,對simple insert(能夠確定具體插入行數的,對應上面1、3 兩種情況)做了一些優化,由於simple insert 插入多少行這個很好計算,於是可以一次性生成幾個連續的值用在對應的插入SQL 語句上,這樣就可以提前釋放掉AUTO- INC 鎖,可以減少鎖等待,提高並發插入效率。
2: 這個表示interleaved,這種情況下不存在AUTO-INC 鎖,來一個處理一個,批量插入的時候,就有可能出現主鍵雖然自增,但是不連續的問題。
從上面的介紹中小夥伴們可以看到,實際上第三種,也就是innodb_autoinc_lock_mode 取值為2 的情況下,並發效率是最強的,那麼我們是不是就應該設定innodb_autoinc_lock_mode=2 呢?
這得看情況。
松哥之前寫過一篇文章和小夥伴們介紹MySQL binlog 日誌檔案的三種格式:
row:binlog 中記錄的是具體的值而不是原始的SQL,舉一個簡單例子,假設表中有一個欄位是UUID,使用者執行的SQL 是insert into user(username,uuid) values('javaboy',uuid()),那麼最終記錄到binlog 中的SQL 是insert into user(username,uuid) values('javaboy',‘0212cfa0-de06-11ed-a026-0242ac110004’)。
statement:binlog 中記錄的就是原始的SQL 了,以row 中的為例,最終binlog 中記錄的就是insert into user(username,uuid) values( 'javaboy',uuid())。
mixed:在這個模式下,MySQL 會根據特定的 SQL 語句來決定日誌的形式,也就是在 statement 和 row 之間選擇一個。
對於這三種不同的模式,很明顯,在主從複製的時候,statement 模式可能會導致主從資料不一致,所以現在MySQL 預設的binlog 格式都是row 。
回到我們的問題:
如果binlog 格式是row,那麼我們就可以設定innodb_autoinc_lock_mode 的值為2,這樣就能盡最大程度保證資料並發插入的能力,同時不會發生主從資料不一致的問題。
如果binlog 格式是statement,那麼我們最好設定innodb_autoinc_lock_mode 的值為1,這樣對於simple insert 的並發插入能力進行了提高,批量插入還是先取得AUTO-INC 鎖,等插入成功之後再釋放,這樣也能避免主從資料不一致,確保資料複製的安全性。
以上兩點主要針對InnoDB 儲存引擎,如果是MyISAM 儲存引擎,都是先取得AUTO-INC 鎖,插入完成再釋放,相當於innodb_autoinc_lock_mode 變數的取值對MyISAM 不生效。
接下來我們來透過一個簡單的 SQL 來和小夥伴們示範一下 innodb_autoinc_lock_mode 不同取值對應不同結果的情況。
我們可以使用以下SQL 查詢來查看目前innodb_autoinc_lock_mode 的設定:

可以看到,我使用的8.0.32 這個版本目前預設值是2。
我先把它改成0,修改方式就是在/etc/my.cnf 檔案中加入一行innodb_autoinc_lock_mode=0:
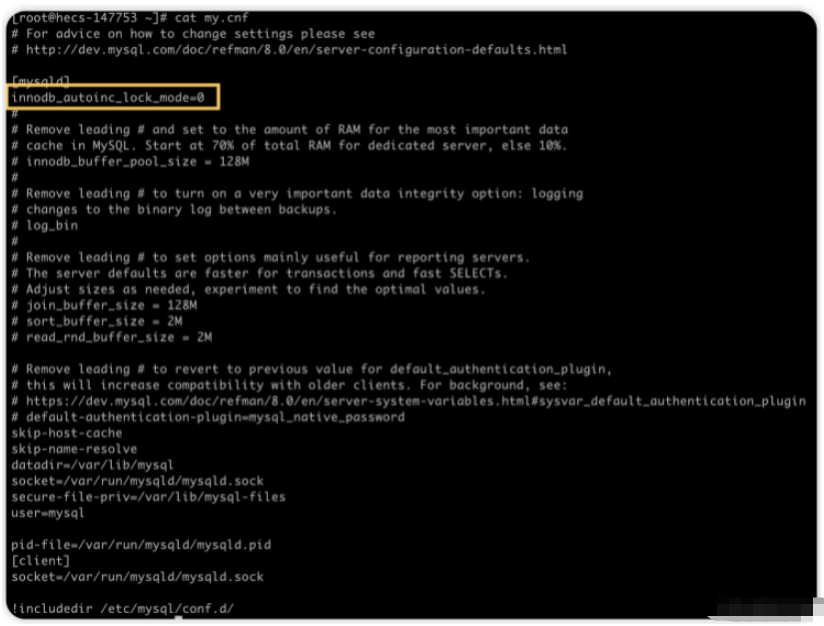
改完之後再重啟查看,如下:

#可以看到,現在就已經改過來了。
現在假設我有如下表:
CREATE TABLE `user` ( `id` int unsigned NOT NULL AUTO_INCREMENT, `username` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=100 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
這個自增是從100 開始計的,現在假設我有如下插入SQL:
insert into user(id,username) values(1,'javaboy'),(null,'江南一点雨'),(3,'www.javaboy.org'),(null,'lisi');
插入完成之後,我們來看查詢結果:

依照我們前文的介紹,這個情況應該是可以解釋的通的,我這裡不再贅述。
接下來,我把 innodb_autoinc_lock_mode 取值改為 1,如下:

還是上面相同的 SQL,我們再執行一次。執行完成之後結果也和上文相同。
但是! ! ! **當上面的 SQL 執行完畢之後,如果我們還想再插入數據,並且新插入的 ID 不指定值,則我們發現自動生成的 ID 值為 104。 **這就是因為我們設定了innodb_autoinc_lock_mode=1,此時,執行simple insert 插入的時候,系統一看我要插入4 筆記錄,就直接給我提前拿了4 個ID 出來,分別是100、101、102 以及103,結果這個SQL 其實只用了兩個ID,剩下兩個沒用,但下次插入還是從104 開始了。
以上是MySQL主鍵自增會遇到的坑怎麼解決的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















