

ChatGPT 等對話 AI 的出現讓人們習慣了這樣一件事情:輸入一段文字、程式碼或一張圖片,對話機器人就能給出你想要的答案。但在這種簡單的互動方式背後,AI 模型要進行非常複雜的資料處理與運算,tokenization 就是比較常見的一種。
在自然語言處理領域,tokenization 指的是將文字輸入分割成更小的單元,稱為「token」。這些 token 可以是詞、子詞或字符,這取決於特定的分詞策略和任務需求。例如,如果對句子「我喜歡吃蘋果」執行 tokenization 操作,我們將得到一串 token 序列:["我", "喜歡", "吃", "蘋果"]。有人將 tokenization 翻譯成「分詞」,但也有人認為這種翻譯會引起誤導,畢竟分割後的 token 未必是我們日常所理解的「詞」。
圖來源:https://towardsdatascience.com/dynamic-word-tokenization-with-regex -tokenizer-801ae839d1cd
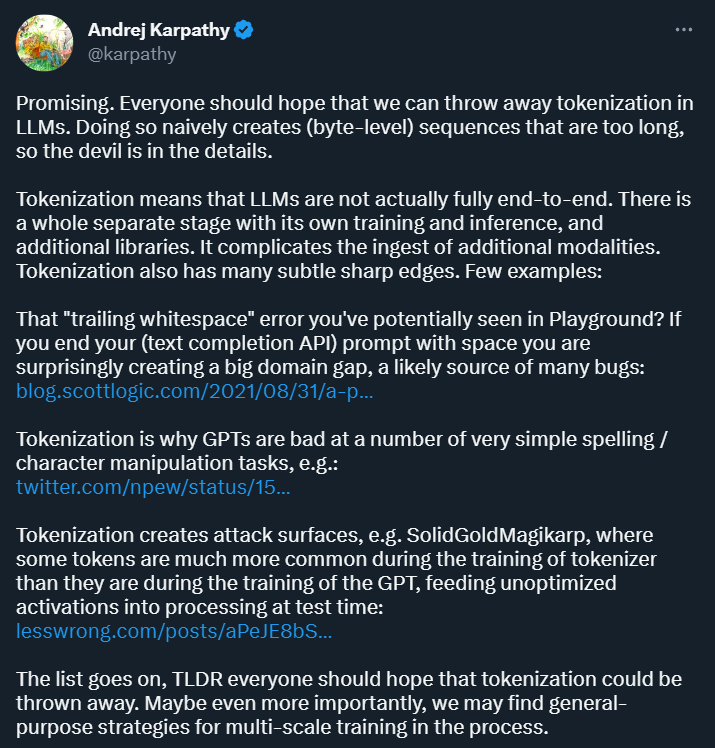
Tokenization 的目的是將輸入資料轉換成電腦可以處理的形式,並為後續的模型訓練和分析提供一種結構化的表示方式。這種方式為深度學習研究帶來了便利,但同時也帶來了許多麻煩。前段時間剛加入 OpenAI 的 Andrej Karpathy 指出了其中幾種。
首先,Karpathy 認為,Tokenization 引入了複雜性:透過使用 tokenization,語言模型並不是完全的端對端模型。它需要一個獨立的階段進行 tokenization,該階段有自己的訓練和推理過程,並需要額外的庫。這增加了引入其他模態資料的複雜性。
此外,tokenization 在某些場景下也會讓模型變得容易出錯,例如在使用文字補全API 時,如果你的prompt 以空格結尾,你得到的結果可能大不相同。

圖片來源:https://blog.scottlogic.com/2021/08/31/a -primer-on-the-openai-api-1.html
再例如,因為tokenization 的存在,強大的ChatGPT 竟然不會將單字反過來寫(以下測試結果來自GPT 3.5)。
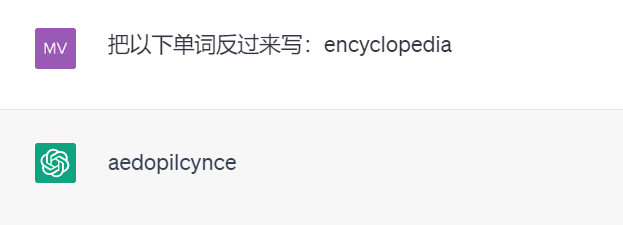
這樣的範例可能還有很多。 Karpathy 認為,要解決這些問題,我們首先要拋棄 tokenization。
Meta AI 發表的一篇新論文探討了這個問題。具體來說,他們提出了一種名為「 MEGABYTE」的多尺度解碼器架構,可以對超過一百萬位元組的序列進行端對端可微建模。

論文連結:https://arxiv.org/pdf/2305.07185.pdf
#重要的是,論文展現出了拋棄tokenization 的可行性,被Karpathy 評價為「很有前途(Promising)」。
以下是論文的詳細資訊。
在機器學習的文章中講過,機器學習之所以看上去可以解決很多複雜的問題,是因為它把這些問題都轉化為了數學問題。
而NLP 也是相同的思路,文字都是一些「非結構化資料」,我們需要先將這些資料轉化為「結構化數據」,結構化資料就可以轉化為數學問題了,分詞就是轉化的第一步。
由於自註意力機制和大型前饋網路的成本都比較高,大型 transformer 解碼器 (LLM) 通常只使用數千個上下文 token。這嚴重限制了可以套用 LLM 的任務集。
基於此,來自 Meta AI 的研究者提出了一種對長位元組序列進行建模的新方法 ——MEGABYTE。此方法將位元組序列分割成固定大小的 patch,和 token 類似。
MEGABYTE 模型由三個部分組成:
至關重要的是,該研究發現對許多任務來說,大多數位元組都相對容易預測(例如,完成給定前幾個字元的單字),這意味著沒有必要對每個位元組都使用大型神經網絡,而是可以使用小得多的模型進行intra-patch 建模。
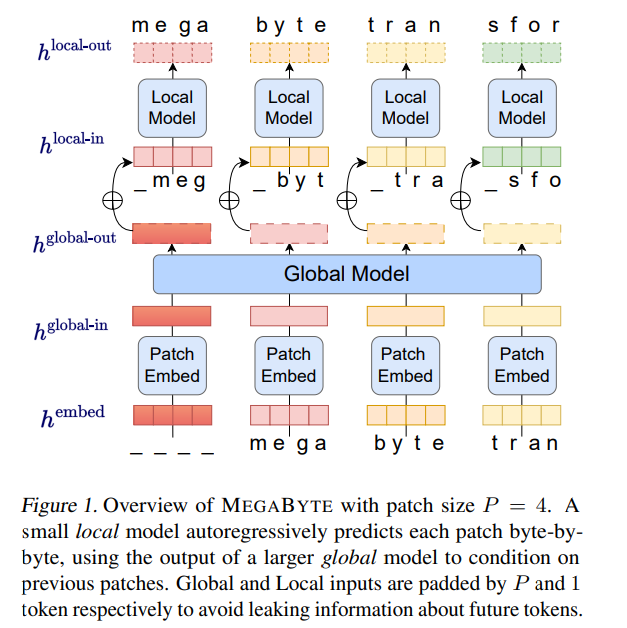
MEGABYTE 架構對長序列建模的Transformer 進行了三項主要改進:
sub-quadratic 自註意力。大多數關於長序列模型的工作都集中在減少自註意力的二次成本。透過將長序列分解為兩個較短的序列和最佳 patch 大小,MEGABYTE 將自註意力機制的成本降低到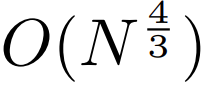 ,即使是長序列也能易於處理。
,即使是長序列也能易於處理。
per-patch 前饋層。在 GPT-3 等超大模型中,超過 98% 的 FLOPS 用於計算 position-wise 前饋層。 MEGABYTE 透過給 per-patch(而不是 per-position)使用大型前饋層,在相同的成本下實現了更大、更具表現力的模型。在 patch 大小為 P 的情況下,基線 transformer 將使用具有 m 個參數的相同前饋層 P 次,而 MEGABYTE 僅需以相同的成本使用具有 mP 個參數的層一次。
3.平行解碼#。 transformer 必須在生成期間串行執行所有計算,因為每個時間步的輸入是前一個時間步的輸出。透過並行產生 patch 的表徵,MEGABYTE 在生成過程中實現了更大的並行性。例如,具有 1.5B 參數的 MEGABYTE 模型產生序列的速度比標準的 350M 參數 transformer 快 40%,同時在使用相同的計算進行訓練時也改善了困惑度(perplexity)。
總的來說,MEGABYTE 讓我們能夠以相同的運算預算訓練更大、效能更好的模型,將能夠處理非常長的序列,並提高部署期間的生成速度。
MEGABYTE 也與現有的自回歸模型形成鮮明對比,後者通常使用某種形式的tokenization,其中位元組序列被映射成更大的離散token(Sennrich et al., 2015; Ramesh et al., 2021; Hsu et al., 2021) 。 tokenization 讓預處理、多模態建模和遷移到新領域變得複雜,同時隱藏了模型中有用的結構。這意味著大多數 SOTA 模型並不是真正的端到端模型。最廣泛使用的 tokenization 方法需要使用特定於語言的啟發式方法(Radford et al., 2019)或遺失資訊(Ramesh et al., 2021)。因此,用高效和高效能的位元組模型取代 tokenization 將具有許多優勢。
該研究對 MEGABYTE 和一些強大的基準模型進行了實驗。實驗結果表明,MEGABYTE 在長上下文語言建模上的性能可與子詞模型媲美,並在 ImageNet 上實現了 SOTA 的密度估計困惑度,並允許從原始音訊檔案進行音訊建模。這些實驗結果證明了大規模無 tokenization 自迴歸序列建模的可行性。

patch 嵌入器
大小為P 的patch 嵌入器能夠將位元組序列
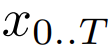
對應成一個長度為
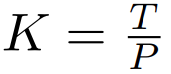
、維度為
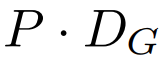
#的 patch 嵌入序列。
首先,每個位元組都嵌入了一個查找表
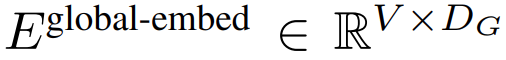
,形成一個大小為D_G 的嵌入,並加入了位置嵌入。
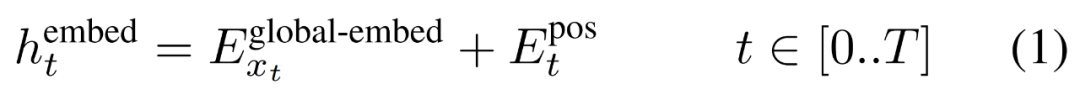
#然後,位元組嵌入重塑成維度為
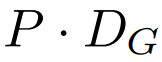
#的K 個patch 嵌入的序列。為了允許自回歸建模,該patch 序列被填充以從可訓練的patch 大小的填充嵌入(
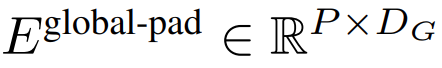
),然後從輸入中移除最後一個patch。此序列是全域模型的輸入,表示為
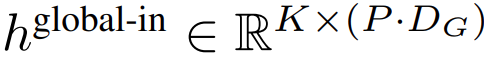
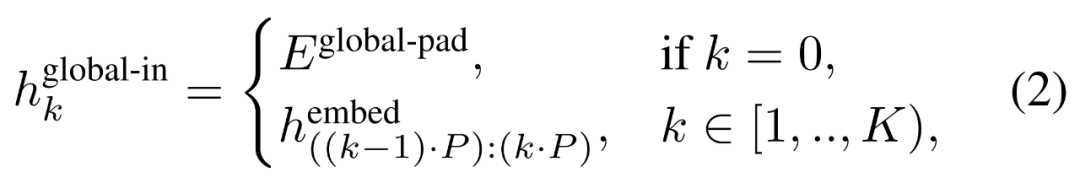
全域模組#########
全域模組是一個 decoder-only 架構的 P・D_G 維 transformer 模型,它在 k 個 patch 序列上進行操作。全域模組結合自註意力機制和因果掩碼來捕捉 patch 之間的依賴性。全域模組輸入k 個patch 序列的表示
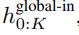
,並透過對先前patch 執行自註意力來輸出更新的表示
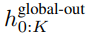
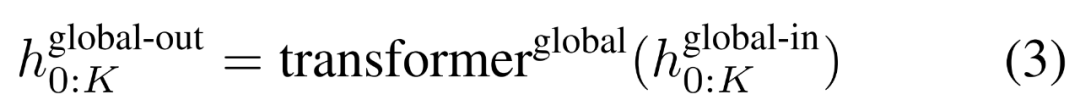
#最終全域模組的輸出
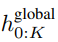
#包含P・D_G 維的K 個patch 表示。對於其中的每一個,研究者將它們重塑維長度為 P、維度為 D_G 的序列,其中位置 p 使用維度 p・D_G to (p 1)・D_G。然後將每個位置對應到具有矩陣
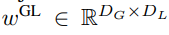
的局部模組維度,其中 D_L 為局部模組維度。接著將這些與大小為 D_L 的位元組嵌入結合,用於下一個
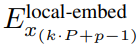
的 token。
局部位元組嵌入透過可訓練的局部填滿嵌入(E^local-pad ∈ R^DL)偏移1,從而允許在path 中進行自回歸建模。最後得到張量
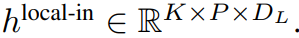
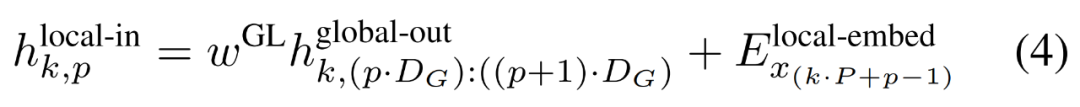
局部模組
局部模組是一個較小的、decoder-only 架構的D_L 維transformer 模型,它在包含P 個元素的單一patch k 上運行,每個元素又是一個全域模組輸出和序列中前一個位元組的嵌入的總和。 K 個局部模組副本在每個patch 上獨立運行,並在訓練時並行運行,從而計算表示
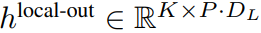

#最後,研究者可以計算每個位置的詞彙機率分佈。第 k 個 patch 的第 p 個元素對應於完整序列的元素 t,其中 t = k・P p。
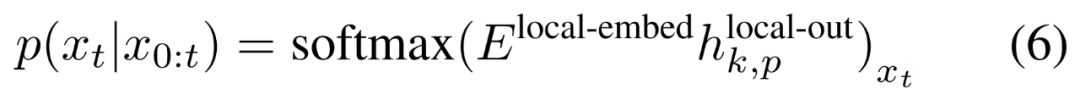
#訓練效率
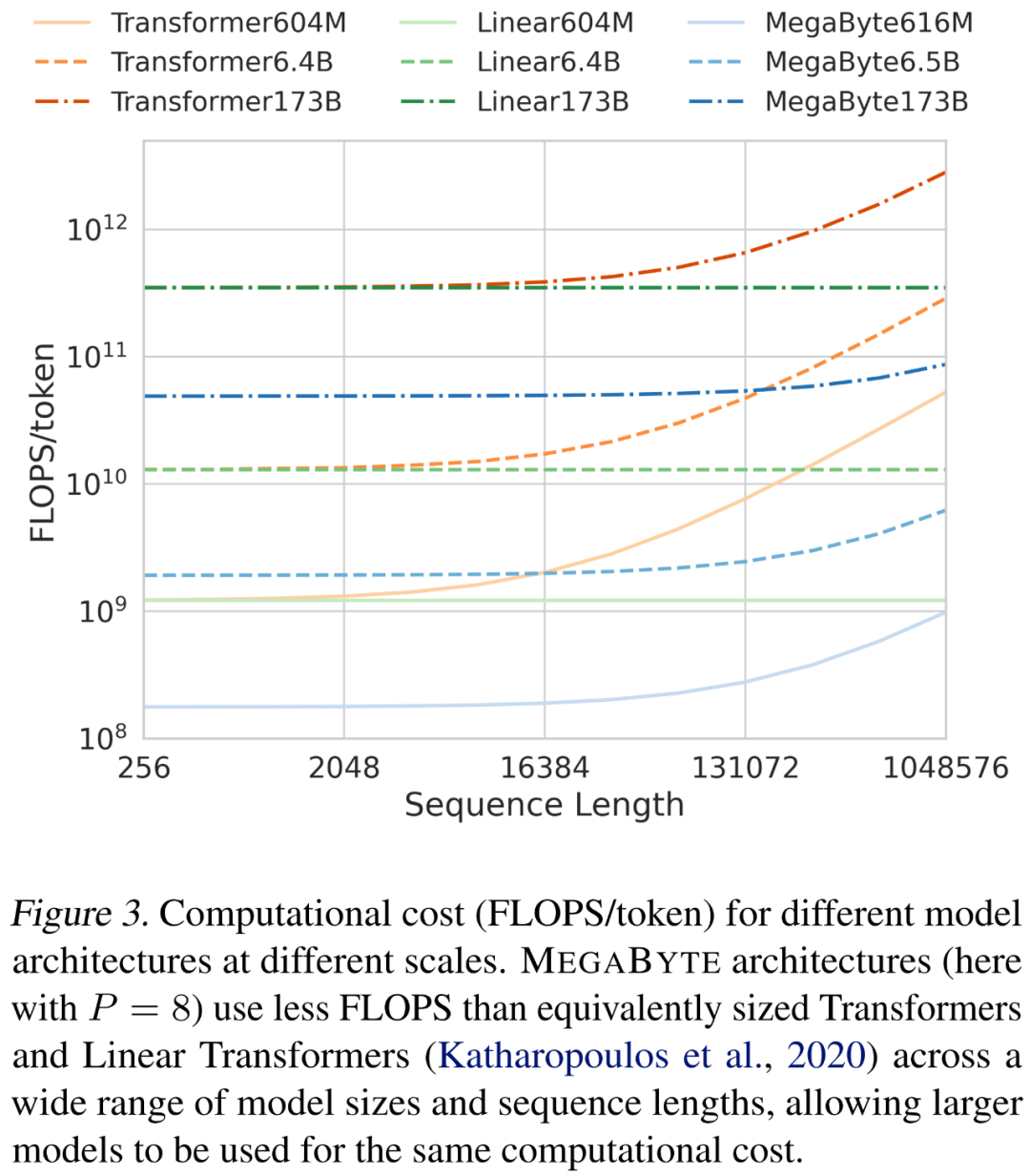
在縮放序列長度和模型大小時,研究者分析了不同架構的成本。如下圖 3 所示,MEGABYTE 架構在各種模型大小和序列長度上使用的 FLOPS 少於同等大小的 transformer 和線性 transformer,允許相同的運算成本下使用更大的模型。
考慮這樣一個MEGABYTE 模型,它在全域模型中有L_global 層,在局部模組中有L_local 層,patch 大小為P,並與具有L_local L_global 層的transformer 架構進行比較。用 MEGABYTE 產生每個 patch 需要一個 O (L_global P・L_local) 串列操作序列。當 L_global ≥ L_local(全域模組的層多於局部模組)時,MEGABYTE 可以將推理成本降低近 P 倍。
實驗結果
語言建模
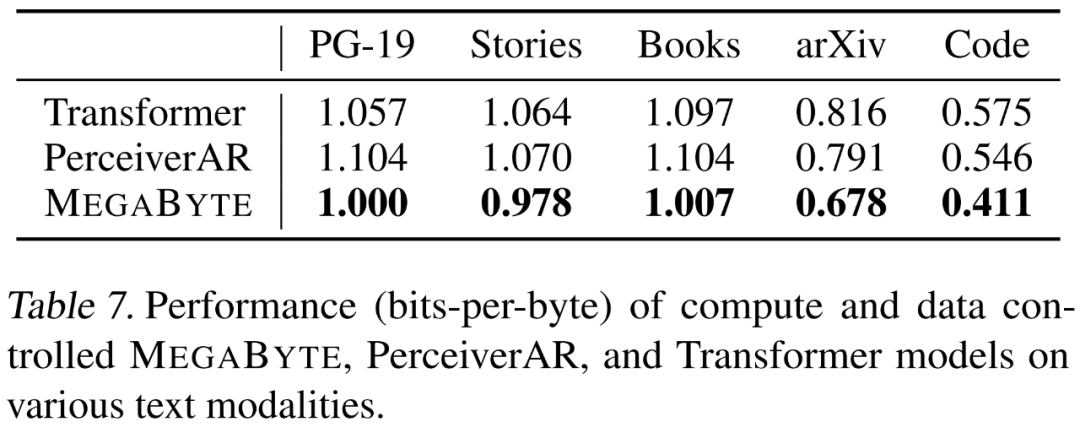
#研究者在強調長程依賴的5 個在不同資料集上分別評估了MEGABYTE 的語言建模功能,它們是Project Gutenberg (PG-19)、Books、Stories、arXiv 和Code。結果如下表 7 所示,MEGABYTE 在所有資料集上的表現始終優於基準 transformer 和 PerceiverAR 。
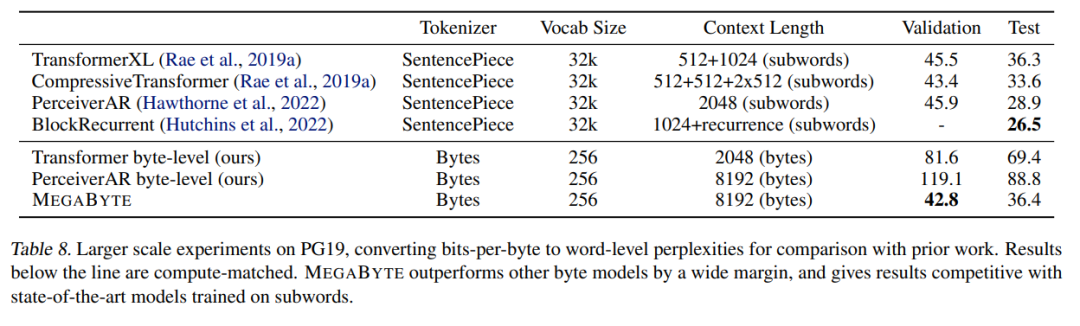
研究者也擴展了PG-19 上的訓練數據,結果如下表8 所示,MEGABYTE 顯著優於其他位元組模型,並可與子詞(subword)上訓練的SOTA 模型相媲美。
圖片建模
研究者在ImageNet 64x64 資料集上訓練了一個大型MEGABYTE 模型,其中全域和局部模組的參數分別為2.7B 和350M,並有1.4T token。他們估計,訓練模型所用時間少於「Hawthorne et al., 2022」論文中復現最佳 PerceiverAR 模型所需 GPU 小時數的一半。如上表 8 所示,MEGABYTE 與 PerceiverAR 的 SOTA 效能相當的同時,僅用了後者一半的運算量。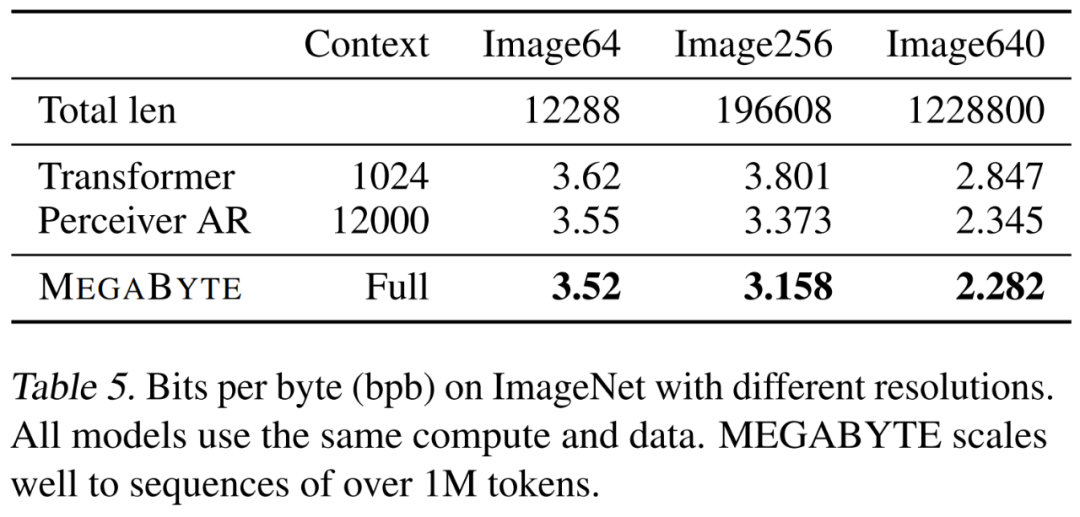
研究者比較了三種 transformer 變體,即 vanilla、PerceiverAR 和 MEGABYTE,以測試在越來越大影像解析度上長序列的可擴展性。結果如下表 5 所示,在此運算控制設定下,MEGABYTE 在所有解析度上均優於基準模型。
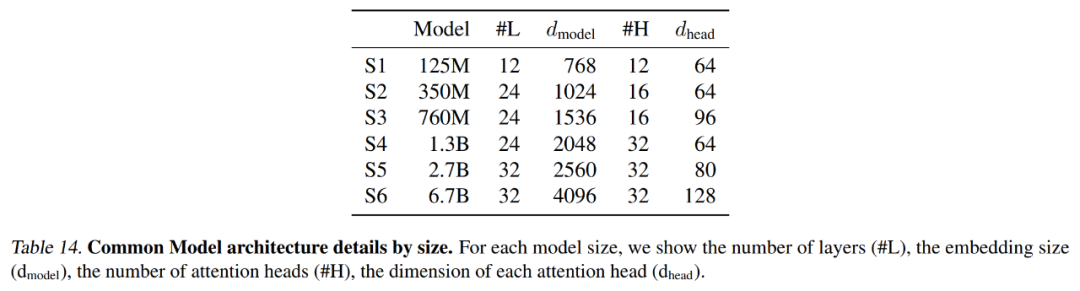
下表 14 總結了每個基準模型使用的精確設置,包括上下文長度和 latent 數量。
音訊建模
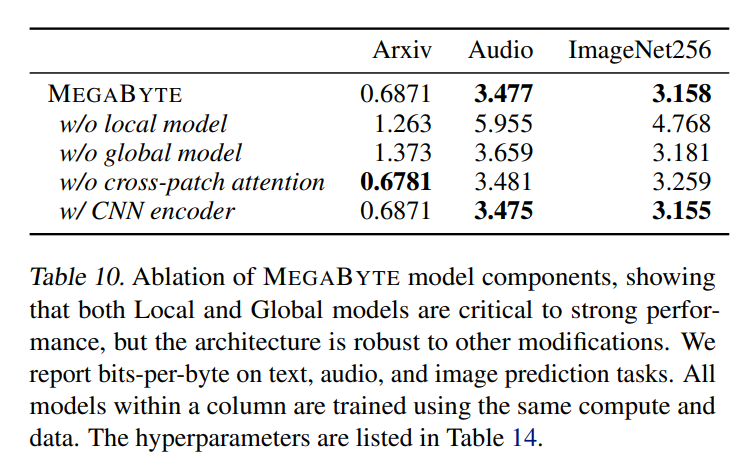
###############更多技術細節與實驗結果請參考原文。 ######
以上是一定要「分詞」嗎? Andrej Karpathy:是時候拋棄這個歷史包袱了的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































