


透過上面爬取股票個股資金流的例子,大家應該已經能夠學會自己寫爬取程式碼。現在鞏固一下,做個相似的小練習題。要動手自己寫Python程序,爬取網路板塊的資金流。爬取網址為http://data.eastmoney.com/bkzj/hy.html,顯示介面如圖1所示。
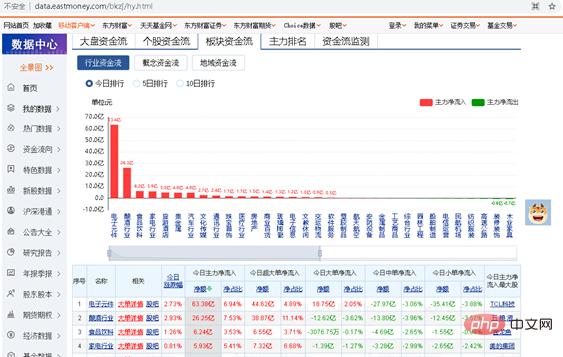
圖1 板塊資金流網址介面
##直接按F12鍵,開啟開發工具找出「JS#」所對應的網頁,如圖2所示。
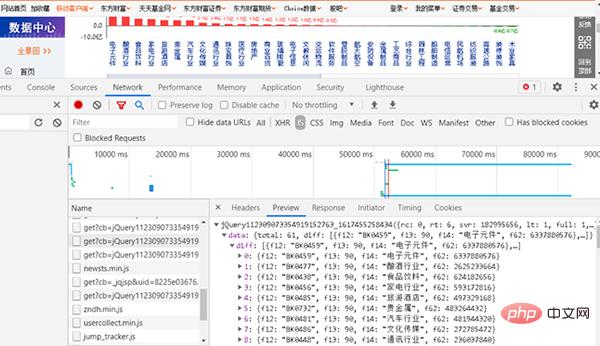
圖2 找出JS所對應的網頁
#然後把網址輸入瀏覽器中,網址比較長。
http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_1617455258434&pn=1&pz=500&po=1617455258434&pn=1&pz=500&po=1&np=200,000,4000,0000,000m&fm. t:2&ut=b2884a393a59ad64002292a3e90d46a5&_=1617455258435
此時,會得到網站的回饋,如圖3所示。

圖3 從網站取得板塊及資金流
該網址對應的內容即是我們想要爬取的內容。
編寫爬蟲程式碼,詳見以下程式碼:
# coding=utf-8 import requests url=" http://push2.eastmoney.com/api/qt/clist/get?cb=jQuery112309073354919152763_ 1617455258436&fid=f62&po=1&pz=50&pn=1&np=1&fltt=2&invt=2&ut=b2884a393a59ad64002292a3 e90d46a5&fs=m%3A90+t%3A2&fields=f12%2Cf14%2Cf2%2Cf3%2Cf62%2Cf184%2Cf66%2Cf69%2Cf72%2 Cf75%2Cf78%2Cf81%2Cf84%2Cf87%2Cf204%2Cf205%2Cf124" r = requests.get(url)
r.status_code顯示200,表示回應狀態正常。 r.text也有數據,說明爬取資金流數據是成功的,如圖4所示。
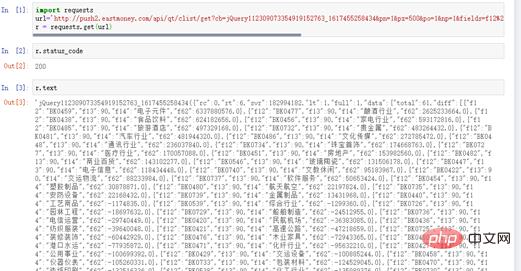
圖4 response回應狀態
(1)分析r.text資料。其內部是標準的JSON格式,只是前面多了一些前綴。將jQ前綴去掉,使用split()函數就能完成這個操作。詳見如下程式碼:
r_text=r.text.split("{}".format("jQuery112309073354919152763_1617455258436"))[1]
r_text運行結果如圖5所示。

.詳見如下程式碼:
r_text_qu=r_text.rstrip(';')
r_text_json=json.loads(r_text_qu[1:-1])['data']['diff']
dfcf_code={"f12":"code","f2":"价格","f3":"涨幅","f14":"name","f62":"主净入√","f66":"超净入","f69":"超占比", "f72":"大净入","f75":"大占比","f78":"中净入","f81":"中占比","f84":"小净入","f87":"小占比","f124":"不知道","f184":"主占比√"}
result_=pd.DataFrame(r_text_json).rename(columns=dfcf_code)
result_["主净入√"]=round(result_["主净入√"]/100000000,2)#一亿,保留2位
result_=result_[result_["主净入√"]>0]
result_["超净入"]=round(result_["超净入"]/100000000,2)#一亿,保留2位
result_["大净入"]=round(result_["大净入"]/100000000,2)#一亿,保留2位
result_["中净入"]=round(result_["中净入"]/100000000,2)#一亿,保留2位
result_["小净入"]=round(result_["小净入"]/100000000,2)#一亿,保留2位
result_運作結果如圖6所示。
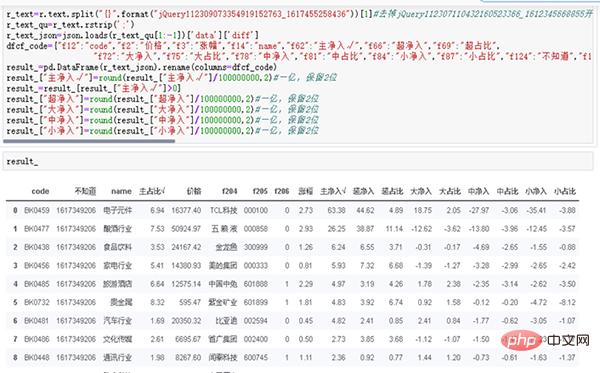 之後符號中排入時的資金中整理出排結果# 使用to_csv()函數保存到本地,如圖7所示。
之後符號中排入時的資金中整理出排結果# 使用to_csv()函數保存到本地,如圖7所示。
透過以上兩種資金爬取的例子,想必大家已經了解了爬蟲的部分使用方法。其核心想法是:
(2)取得網址並加以分析;
(3)使用爬蟲進行數據取得並保存資料。
圖6 資料保存#總結 JSON格式的資料是許多網站所使用的標準化資料格式之一,是一種輕量級的資料交換格式,十分易於閱讀編寫,可以有效提升網路傳輸效率。首先爬取到的是str格式的字串,透過資料加工與處理,將其變成標準的JSON格式,繼而變成Pandas格式。
JSON格式的資料是許多網站所使用的標準化資料格式之一,是一種輕量級的資料交換格式,十分易於閱讀編寫,可以有效提升網路傳輸效率。首先爬取到的是str格式的字串,透過資料加工與處理,將其變成標準的JSON格式,繼而變成Pandas格式。
透過案例分析與實戰,我們要學會自己編寫程式碼爬取金融資料並具備轉換為JSON標準格式的能力。完成每日資料爬取工作與資料保存工作,為日後資料進行歷史測試與歷史分析提供有效的資料支援。
當然,有能力的讀者可以將結果儲存到MySQL、MongoDB等資料庫中,甚至雲端資料庫Mongo Atlas中,這裡作者不作重點講解。我們將重點完全放在量化學習與策略的研究上。使用txt格式儲存數據,完全可以解決前期資料儲存問題,資料也是完整有效的。
以上是寫一個爬取板塊資金流的Python程序的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































