

對於自動駕駛中的許多任務來說,從自上而下、地圖或鳥瞰 (BEV) 幾個角度去看會更容易完成。由於許多自動駕駛主題被限制在地平面,所以俯視圖是一種更實用的低維度表徵,對於導航也更加理想,能夠捕捉相關障礙和危險。對於像自主駕駛這樣的場景,語義分割的 BEV 地圖必須作為瞬時估計生成,以處理自由移動的物件和只訪問一次的場景。
要從影像推斷 BEV 地圖,就需要確定影像元素與它們在環境中的位置之間的對應關係。 先前的一些研究以稠密深度圖和圖像分割地圖指導這種轉換過程,還有研究延展了隱式解析深度和語義的方法。一些研究則利用了相機的幾何先驗,但並沒有明確地學習影像元素和 BEV 平面之間的相互作用。
在近期一篇論文中,來自薩里大學的研究者引入了注意力機制,將自動駕駛的2D 影像轉換為鳥瞰圖,使得模型的識別準確率提升了15%。這項研究在不久前落幕的 ICRA 2022 會議上獲得了傑出論文獎。

論文連結:https://arxiv.org/pdf/2110.00966.pdf

#與以往的方法不同,這項研究將BEV 的轉換視為一個「Image-to-World」的轉換問題,其目標是學習影像中的垂直掃描線(vertical scan lines)和BEV 中的極射線(polar ray)之間的對齊。因此,這種射影幾何對網路來說是隱式的。
在對齊模型上,研究者採用了 Transformer 這種基於注意力的序列預測結構。利用其註意力機制,研究者明確地建模了影像中垂直掃描線與其極性 BEV 投影之間的成對交互作用。 Transformer 非常適合影像到 BEV 的轉換問題,因為它們可以推理出物件、深度和場景照明之間的相互依賴關係,以實現全局一致的表徵。
研究者將基於Transformer 的對齊模型嵌入到端對端學習公式中,該公式以單眼影像及其固有矩陣為輸入,然後預測靜態和動態類別的語意BEV 映射。
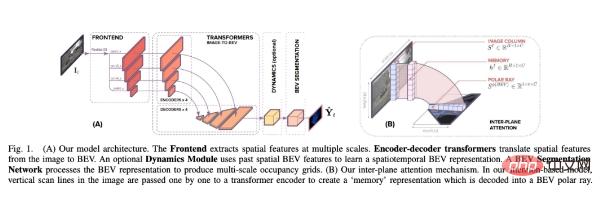
本文建構了一個體系結構,有助於從對齊模型周圍的單眼影像預測語意 BEV 映射。如下圖1 所示,它包含三個主要組成部分:一個標準的CNN 骨幹,用於提取圖像平面上的空間特徵;編碼器- 解碼器Transformer 將圖像平面上的特徵轉換為BEV;最後一個分割網絡將BEV 特徵解碼為語意地圖。

#具體而言,本研究的主要貢獻在於:
#在實驗中,研究者做了幾項評估:將影像到BEV 的轉換作為nuScenes 資料集上的轉換問題評估其效用;在單調注意力中消融回溯方向,評估長序列水平上下文的效用和極位置資訊(polar positional information)的影響。最後,將該方法與 nuScenes 、Argoverse 和 Lyft 資料集的 SOTA 方法進行比較。
消融實驗
#如下表2 的第一部分所示,研究者比較了軟注意力(looking both ways)、圖像底部回溯(looking down) 的單調注意力、圖像頂部回溯(looking up) 的單調注意力。 結果表明,從圖像中的一個點向下看比向上看要好。
沿著局部的紋理線索-這與人類在城市環境中試圖確定物體距離的方法是一致的,我們會利用物體與地平面相交的位置。結果還表明,兩個方向的觀察都進一步提高了精確度,使深度推理更具辨識力。

長序列水平上下文的效用。 此處的圖像 - BEV 轉換是作為一組 1D 序列 - 序列轉換進行的,因此一個問題是,當整個圖像轉換成 BEV 時會發生什麼。考慮到生成注意力地圖所需的二次計算時間和記憶力,這種方法的成本高得令人望而卻步。然而,可以透過在影像平面特徵上應用水平軸向注意力,取得近似使用整個影像的上下文效益。借助透過影像行的軸向注意力,垂直掃描線中的像素現在具備了長距離的水平上下文,之後像以前一樣,透過在 1D 序列之間轉換來提供長距離的垂直上下文。
如表 2 中間部分所示,合併長序列水平上下文並不會使模型受益,甚至略有不利影響。這說明了兩點:首先,每個轉換後的射線並不需要輸入圖像整個寬度的信息,或者更確切地說,比起已經通過前端卷積聚合的上下文,長序列上下文並沒有提供任何額外的好處。這表明,使用整個圖像執行轉換,不會讓模型精度提高以至超過baseline 約束公式;此外,引入水平軸向注意力導致的性能下降意味著使用注意力訓練圖像寬度的序列的困難,可以看出,使用整個影像作為輸入序列的話,會更難訓練。
Polar-agnostic vs polar-adaptive Transformers:表2 最後一部分比較了Po-Ag 與Po -Ad 的變體。一個 Po-Ag 模型沒有極化位置訊息,影像平面的 Po-Ad 包括添加到 Transformer 編碼器中的 polar encodings,而對於 BEV 平面,這些訊息會加入解碼器。在任何一個平面上添加 polar encodings 都比在不可知模型上添加更有益處,其中動態類別的增加最多。將它加到兩個平面會進一步強化這一點,但對靜態類別的影響最大。
和 SOTA 方法的比較
#研究者將本文方法與一些 SOTA 方法進行了比較。 如下表 1 所示,空間模型的表現優於目前壓縮的 SOTA 方法 STA-S ,平均相對改善 15% 。在較小的動態類別上,改善更加顯著,公車、卡車、拖車和障礙物的偵測準確度都增加了相對 35-45% 。

下圖 2 中得到的定性結果也支持了這個結論,本文模型顯示出更大的結構相似性和更好的形狀感。這種差異可以部分歸因於用於壓縮的全連接層(FCL) : 當檢測小而遙遠的物體時,影像的大部分是冗餘的上下文。

此外,行人等物體往往會部分被車輛擋住。在這種情況下,全連接層將傾向於忽略行人,而是保持車輛的語義。在這裡,注意力方法展示了它的優勢,因為每個徑向深度都可以獨立地註意到圖像ーー如此,更深的深度可以使行人的身體可見,而此前的深度只可以注意到車輛。
下表 3 中 Argoverse 資料集上的結果展示了類似的模式,其中本文方法對比 PON [8]提高了 30% 。

如下表 4 所示,本文方法在 nuScenes 和 Lyft 的表現優於 LSS [9]和 FIERY [20]。在 Lyft 上進行真正的對比是不可能的,因為它沒有規範的 train/val 分割,而且無法獲得 LSS 所使用的分割。

更多研究細節,可參考原文。
以上是ICRA 2022傑出論文:把自動駕駛2D影像轉成鳥瞰圖,模型辨識準確率立增15%的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































