

嘉賓:譚中意
整理:千山
吳恩達曾在多個場合表達過AI已經從以模型為中心的研究範式向以數據為中心的研究範式轉變,數據是AI落地最大的挑戰。如何確保資料的高品質供給是關鍵問題,而要解決好這個問題,需要利用MLOps的實踐、工具等,幫助AI多快好省的落地。
日前,在51CTO主辦的 AISummit 全球人工智慧技術大會上,開放原子基金會TOC副主席譚中意帶來了主題演講《從Model-Centric到Data-Centric-MLOps幫助AI多快好省的落地》,和與會者重點分享了MLOps的定義、MLOps能解決什麼問題、常見的MLOps項目,以及如何評估一個AI團隊MLOps的能力和水平。
現在將演講內容整理如下,希望對諸君有所啟發。
目前,AI界有個趨勢是-「從Model-Centric到Data-Centric」。具體是什麼意義?首先來看一些來自科學界和工業界的分析。
吳恩達曾分享演講《MLOps:From Model-centric to Data-centric》,在矽谷引起了極大反響。在演講中,他認為「AI= Code Data」(此處Code包含模型和演算法),透過提升Data而非Code來提升AI system。
具體來說,採用Model-Centric的方法,即保持資料不變,不斷的調整模型演算法,例如使用更多網路層,更多超參數調整等;而採用Data-Centric的方法,即維持模型不變,提升資料質量,例如改進資料標籤,提高資料標註品質等。
對於同一個AI問題,改進程式碼還是改進數據,效果完全不同。
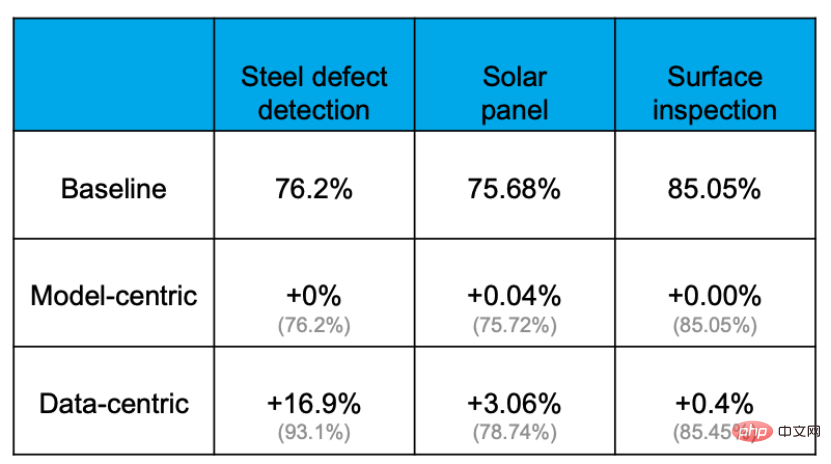
實證顯示,透過Data-centricapproach能夠有效提升準確率,而透過改善模型、更換模型能提升準確率的程度極為有限。例如,在下列鋼板缺陷偵測任務當中,baseline準確率為76.2%,各種換模型調參數的操作之後,對準確率幾乎沒有提升。但對資料集的優化卻將準確率提升了16.9%。其它專案的經驗也證明了這一點。
之所以會這樣,是因為資料比想像中更重要。大家都知道「Data is Food for AI」。在一個真實的AI應用中,大概有80%的時間是處理跟數據相關的內容,其餘20%則用來調整演算法。這個過程就像烹飪,八成時間用來準備食材,對各種食材進行處理和調整,而真正的烹調可能只有大廚下鍋的幾分鐘。可以說,決定一道菜是否美味的關鍵,在於食材和食材的處理。
在吳恩達看來,MLOps(即「Machine learning Engineering for Production」)最重要的任務就是在機器學習生命週期的各個階段,包括資料準備、模型訓練、模型上線,以及模型的監控和重新訓練等等各個階段,始終保持高品質的資料供給。
以上是AI科學家對MLOps的認知。接著來看AI工程師和業內分析師的一些觀點。
先從業內分析師看來,目前AI專案的失敗率是驚人的高。 2019年5月Dimensional Research研究發現,78%的AI專案最終沒有上線;2019年6月,VentureBeat的報告發現,87%的AI專案沒有部署到生成環境。換句話說,雖然AI科學家、AI工程師做了很多工作,但最終沒有產生業務的價值。
為什麼會產生這個結果? 2015年在NIPS上發布的論文《Hidden Technical Debt in Machine Learning Systems》中提到,在一個真實上線的AI系統裡面,包含了資料收集、驗證、資源管理、特徵抽取、流程管理、監控等諸多內容。但真正跟機器學習相關的程式碼,只佔整個AI系統的5%,95%都是跟工程相關的內容,跟數據相關的內容。因此,數據是最重要的,也是最容易出錯的。
數據對一個真實的AI系統的挑戰主要在於以下幾點:
以上列舉的都是機器學習裡面資料相關的一些挑戰。此外,在現實生活中,即時數據會帶來更大的挑戰。
那麼,對於一個企業來說,AI落地如何才能做到規模化?以大企業為例,它可能會有超過1000多個應用場景,同時有1500多個模型在線上跑,這麼多模型如何支撐?在技術上怎麼能做到AI「多、快、好、省」的落地?
多:需要圍繞關鍵業務的流程落地多個場景,對大企業來說可能是1000甚至上萬的量級。
快:每個場景落地時間要短,迭代速度要快。例如推薦場景中,常常需要做到每天1次全量訓練,每15分鐘甚至每5分鐘做到1次增量訓練。
好:每個場景的落地效果都要達到預期,至少比沒有落地前強。
省:每個場景的落地成本比較節省,符合預期。
要真正做到“多、快、好、省”,我們需要MLOps。

在傳統的軟體開發領域,遇到上線慢、品質不穩定等類似問題,我們用DevOps來解決。 DevOps大幅提升了軟體開發和上線的效率,促進了現代軟體的快速迭代和發展。而在面臨AI系統的問題時,我們可以從DevOps領域的成熟經驗中學習去發展MLOps。所以如圖所示,「Machine learning development Modern software development」就變成了MLOps。
對於MLOps是什麼,目前業界並沒有標準定義。
上述說法都比較繞口,我個人對此的理解相對簡單:MLOps是「Code Model Data」的持續整合、持續部署、持續訓練和持續監控。
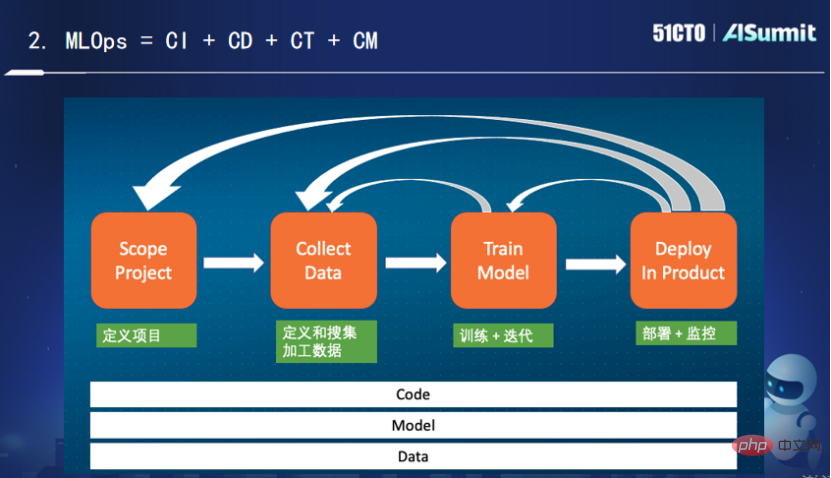
上圖展示的是一個典型的機器學習的生命場景。定義專案階段之後就開始定義和收集加工數據,就要觀察對解決當前問題有幫助的數據究竟是哪些?要怎麼加工,怎麼做特徵工程,怎麼轉換儲存。
收集完資料之後就開始進行模型的訓練與迭代,需要不斷調整演算法,然後不斷訓練,最後得到一個符合預期的結果。如果對這個結果不滿意,就需要返回上層,此時需要獲取更多的數據,對數據進行更多的轉換,之後再進行訓練,循環往復,直到得出比較滿意的模型算法出來,然後再開始部署到線上。
在部署和監控環節,如果模型效果不一致,這時候要觀察訓練和部署出了什麼問題。在部署了一段時間後,可能會面臨模型衰退的問題,此時就需要重新訓練。甚至有時候在部署過程中發現資料有問題,此時就需要回到資料處理這一層。更有甚者,部署效果遠未達到專案預期,也可能需要返回初始原點。
可以看到,整個過程是一個循環迭代的過程。而對於工程實務來說,我們需要不斷地持續整合、持續部署、持續訓練、持續監控。其中持續訓練和持續監控是MLOps所特有的。持續訓練的作用在於,即使程式碼模型沒有任何改變,也需要針對其資料改變進行持續訓練。而持續監控的作用在於,不斷監控資料和模型之間的匹配是否發生問題。這裡的監控指的不僅是監控線上系統,更要監控系統跟機器學習相關的一些指標,如召回率、準確率等。綜合來說,我認為MLOps其實就是程式碼、模型、資料的持續集成,持續部署,持續訓練和持續監控。
當然,MLOps不僅只是流程和Pipeline,它還包括更大更多的內容。例如:
(1) 儲存平台: 特徵和模型的儲存和讀取
(2) 運算平台:串流、批次用於特徵處理
(3) 訊息佇列:用於接收即時資料
(4) 調度工具:各種資源(運算/儲存)的調度
(5) Feature Store:註冊、發現、共享各種特徵
(6) Model Store:模型的特徵
(7) Evaluation Store:模型的監控/ AB測試
Feature Store、Model store和Evaluation store都是機器學習領域中新興的應用和平台,因為有時候線上會同時跑多個模型,要實現快速迭代,需要很好的基礎設施來保留這些信息,從而讓迭代更高效,這些新應用、新平台就應運而生。
下面簡單介紹一下Feature Store,即特徵平台。作為機器學習領域特有的平台,Feature Store具有許多特性。
第一,需要同時滿足模型訓練和預測的要求。特徵資料儲存引擎在不同的場景有著完全不同的應用需求。模型訓練時需要擴展性佳、儲存空間大;即時預測則需要滿足高效能、低延遲的要求。
第二,必須解決特徵處理在訓練時候和預測階段不一致的問題。在模型訓練時,AI科學家一般會使用Python腳本,然後用Spark或SparkSQL來完成特徵的處理。這種訓練對延遲不敏感,在應付線上業務時效率較低,因此工程師會用性能較高的語言把特徵處理的過程翻譯一下。但翻譯過程異常繁瑣,工程師要重複跟科學家去校對邏輯是否符合預期。只要稍微不符合預期,就會帶來線上和線下不一致的問題。
第三,需要解決特徵處理中的重複使用問題,避免浪費,高效共享。在一家企業的AI應用中,經常會出現這種情況:同一個特徵被不同的業務部門使用,資料來源來自同一份日誌文件,中間所做的抽取邏輯也是類似的,但因為是在不同的部門或不同的場景下使用,就不能重複使用,相當於同一份邏輯被執行了N遍,而且日誌檔案都是海量的,這對儲存資源和運算資源都是巨大的浪費。
綜上所述,Feature Store主要用於解決高效能的特徵儲存和服務、模型訓練和模型預測的特徵資料一致性、特徵重複使用等問題,資料科學家可以使用Feature Store進行部署和共享。
目前市面上主流的特徵平台產品,大致可分為三大類。
成熟度模型是用來衡量一個系統、一套規則的能力目標,在DevOps領域經常用成熟度模型來評估一個公司的DevOps能力。而在MLOps領域也有對應的成熟度模型,不過目前還沒有形成規範。這裡簡單介紹一下Azure的關於MLOps的成熟度模型。
依照機器學習全流程的自動化程度的高低,把MLOps的成熟模型分成了(0,1,2,3,4)個等級,其中0是沒有自動化的。 (1,2,3)是部分自動化,4是高度自動化.

#成熟度為0,即沒有MLOps。這一階段意味著資料準備是手動的,模型訓練也是手動的,模訓部署也都是手動的。所有的工作全都是手動完成,適合於一些把AI進行創新試點的業務部門來做。
成熟度為1,即有DevOps沒有MLOps。其資料準備工作是自動完成的,但模型訓練是手動完成的。科學家拿到數據之後再完成各種調整和訓練。模型的部署也是手動完成的。
成熟度為2,即自動化訓練。其模型訓練是自動化完成的,簡言之,當資料更新完了之後,立刻啟動類似的pipeline,進行自動化的訓練,不過對訓練結果的評估和上線還是由人工來完成。
成熟度為3,即自動化部署。模型自動化訓練完成之後,對模型的評估和上線是自動完成的,不需要人工干涉。
成熟度為4,即自動化重訓與部署。它在不斷監控線上的模型,當發現Model DK發生線上模型能力退化的時候,會自動會觸發重複訓練。整個過程就全部自動化完成了,這可以稱之為成熟度最高的系統。
更多精彩內容請見大會官網:點擊看
#以上是譚中意:從Model-Centric到Data-Centric MLOps幫助AI多快好省的落地的詳細內容。更多資訊請關注PHP中文網其他相關文章!


































