

譯者 | 布加迪
審校 | 孫淑娟
目前,沒有用於建構和管理機器學習(ML)應用程式的標準實務。機器學習專案組織得不好,缺乏可重複性,而且從長遠來看容易徹底失敗。因此,我們需要一套流程來幫助自己在整個機器學習生命週期中保持品質、永續性、穩健性和成本管理。
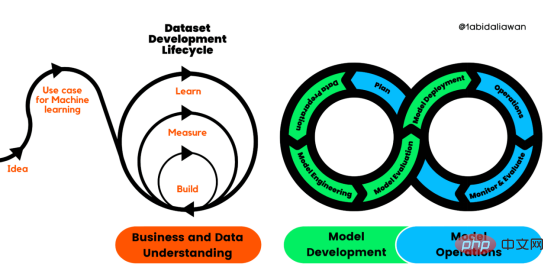
圖1.機器學習開發生命週期流程
使用品質保證方法開發機器學習應用程式的跨產業標準流程(CRISP-ML(Q ))是CRISP-DM的升級版,以確保機器學習產品的品質。
CRISP-ML(Q)有六個單獨的階段:
1. 業務和資料理解
2. 資料準備
#3.模型工程
4. 模型評估
5. 模型部署
6. 監控與維護
這些階段需要不斷迭代和探索,以建構更好的解決方案。即使框架中有順序之分,後一階段的輸出可以決定我們要不要重新檢查前一階段。
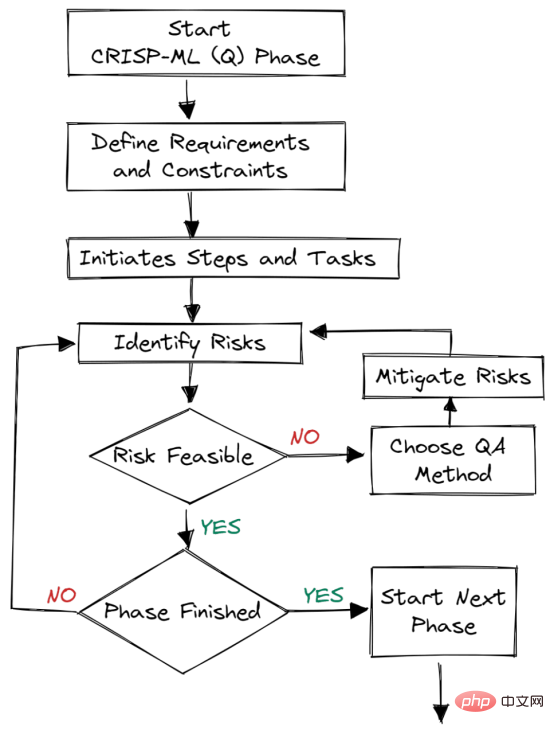
圖2. 每個階段的品質保證
品質保證方法被引入框架的每個階段。這套方法有要求和約束,例如性能指標、數據品質要求和穩健性。它有助於降低影響機器學習應用程式成功的風險。它可以透過持續監控和維護整個系統來實現。
比如說:在電子商務企業,資料和概念漂移會導致模型退化;如果我們沒有部署系統來監控這些變化,公司就會蒙受損失,也就是失去客戶。
開發流程一開始,我們需要確定專案範圍、成功標準和ML應用程式的可行性。之後,我們開始資料收集和品質驗證過程。這個過程漫長而充滿挑戰。
範圍:我們希望透過使用機器學習流程來實現的目標。是留住客戶,還是透過自動化降低營運成本?
成功標準:我們必須定義清晰且可衡量的業務、機器學習(統計指標)和經濟(KPI)成功指標。
可行性:我們需要確保資料可用性、機器學習應用程式的適用性、法律約束、穩健性、可擴展性、可解釋性和資源需求。
資料收集:透過收集數據,對其進行版本控制以實現可重複性,並確保源源不斷的真實資料和生成資料。
資料品質驗證:透過維護資料描述、要求和驗證來確保品質。
為了確保品質和可重複性,我們需要記錄資料的統計屬性和資料產生過程。
第二階段很簡單。我們將為建模階段準備資料。這包括資料選擇、資料清洗、特徵工程、資料增強和標準化。
1. 我們從特徵選擇、資料選擇以及透過過採樣或欠採樣來處理不平衡類入手。
2. 然後,專注於減少雜訊和處理缺失值。出於品質保證的目的,我們將添加資料單元測試,以減少錯誤值。
3. 視模型而定,我們執行特徵工程和資料增強,例如獨熱編碼和聚類。
4. 規範化和擴展資料。這可降低特徵有偏差的風險。
為了確保可重複性,我們創建了資料建模、轉換和特徵工程管道。
業務和資料理解階段的限制和要求將決定建模階段。我們需要了解業務問題以及我們將如何開發機器學習模型來解決這些問題。我們將專注於模型選擇、最佳化和訓練,將確保模型效能指標、穩健性、可擴展性、可解釋性,並優化儲存和運算資源。
1. 模型架構和類似業務問題的研究。
2. 定義模型效能指標。
3. 模型選擇。
4. 透過整合專家來了解領域知識。
5. 模型訓練。
6. 模型壓縮與整合。
為確保品質和可重複性,我們將儲存模型元資料並進行版本控制,例如模型架構、訓練和驗證資料、超參數以及環境描述。
最後,我們將追蹤ML試驗,並建立ML管道,以建立可重複的訓練流程。
這是我們測試並確保模型已準備好部署的階段。
為了品質保證,評估階段的每一步都被記錄下來。
模型部署是我們將機器學習模型整合到現有系統中的階段。該模型可以部署在伺服器、瀏覽器、軟體和邊緣設備。來自模型的預測可用於BI儀表板、API、Web應用程式和外掛程式。
模型部署流程:
生產環境中的模型需要持續監控和維護。我們將監控模型時效性、硬體效能和軟體效能。
持續監控是流程的第一部分;如果效能降到閾值以下,自動做出決定,針對新資料重新訓練模型。此外,維護部分不僅限於模型的重新訓練。它需要決策機制,獲取新資料、更新軟硬體以及根據業務用例改進ML流程。
簡而言之,就是持續整合、訓練和部署ML模型。
訓練和驗證模型是ML應用程式的一小部分。將最初的想法變成現實需要幾個過程。我們在本文中介紹了CRISP-ML(Q) 以及它如何專注於風險評估和品質保證。
我們先定義業務目標、收集和清理資料、建置模型、拿測試資料集驗證模型,然後再部署到生產環境中。
此框架的關鍵元件是持續監控和維護。我們將監控資料和軟硬體指標,以確定是重新訓練模型還是升級系統。
如果您不熟悉機器學習操作,想了解更多信息,請閱讀DataTalks.Club評述的免費MLOps課程。您將獲得所有六個階段的上手經驗,以了解CRISP-ML的實際實施。
原文標題:#Making Sense of CRISP-ML(Q): The Machine Learning Lifecycle Process##,作者:Abid Ali Awan
以上是解讀CRISP-ML(Q):機器學習生命週期流程的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















