

本篇文章為大家帶來了關於mysql的相關知識,其中主要介紹了單列索引和聯合索引的相關問題,利用索引中的附加列,可以縮小搜尋的範圍,但使用一個具有兩個欄位的索引不同於使用兩個單獨的索引,下面一起來看一下,希望對大家有幫助。

推薦學習:mysql影片教學
利用索引中的附加列,可以縮小搜尋的範圍,但使用一個具有兩個欄位的索引不同於使用兩個單獨的索引。
聯合索引的結構與電話簿類似,人名由姓氏和名稱構成,電話簿首先按姓氏進行排序,然後按名字對有相同姓氏的人進行排序。如果您知道姓,電話簿將非常有用,如果您知道姓和名,電話簿則更為有用,但如果您只知道名不知道姓,電話簿將沒有用處。
所以說創建聯合索引時,應該仔細考慮列的順序。對索引中的所有欄位執行搜尋或僅對前幾列執行搜尋時,聯合索引非常有用;僅對後面的任意列執行搜尋時,聯合索引則沒有用處。
多個單列索引在多條件查詢時最佳化器會優先選擇最優索引策略,可能只用一個索引,也可能將多個索引全用上。但多個單列索引底層會建立多個B 索引樹,比較佔用空間,也會浪費一定搜尋效率,故如果只有多條件聯合查詢時最好建聯合索引。
顧名思義是最左優先,以最左邊的為起點任何連續的索引都能匹配上,如果第一個字段是範圍查詢需要單獨構建一個索引,在建立聯合索引時,要根據業務需求,where子句中使用最頻繁的一列放在最左邊。這樣的話擴展性比較好,例如username經常需要作為查詢條件,而age不常使用,則需要把username放在聯合索引的第一位置,也就是最左邊。
ALTER TABLE employee ADD INDEX idx_name_salary (name,salary)
SELECT * FROM employee WHERE NAME='哪吒编程'
SELECT * FROM employee WHERE salary=5000
SELECT * FROM employee WHERE NAME='哪吒编程' AND salary=5000
SELECT * FROM employee WHERE salary=5000 AND NAME='哪吒编程'
複合索引也稱為聯合索引,當我們建立一個聯合索引的時候,如(k1, k2,k3),相當於創建了(k1)、(k1,k2)和(k1,k2,k3)三個索引,這就是最左匹配原則。
聯合索引不滿足最左原則,索引一般會失效。
這個涉及到MySQL本身的查詢最佳化器策略,當一個表格有多條索引可走時,mysql會根據查詢語句的成本來選擇走哪一個索引;
有人說where查詢是依照從左到右的順序,所以篩選力道大的條件盡量放在前面。網路上百度過,確實有這種說法,但我親自測試過,MySQL執行優化器會對其進行最佳化,當不考慮索引時,where條件順序對效率沒有影響,真正有影響的是是否用到了索引!
當創建**(a, b, c)聯合索引時,相當於創建了(a)單列索引,(a, b)聯合索引以及(a, b, c)聯合索引,想要索引生效的話,只能使用者三種組合;當然,我們上面測試過,a, c組合也可以,但實際上只用到了a的索引,c並沒有用到。
1、like子查詢,%放前面;
2、非空判斷 is not null;or語句前後沒有同時使用索引。當or左右查詢字段只有一個是索引,該索引失效,只有當or左右查詢字段均為索引時,才會生效;
3、or語句(前後都有索引才行,SQL優化要避免寫or語句);
4、資料型別出現隱式轉換。如varchar不加單引號的話可能會自動轉換為int型,使索引無效,產生全表掃描。
1、需要加索引的字段,要在where條件中
2、資料量少的字段不需要加索引,因為建索引有一定開銷,如果資料量小則沒有必要建索引,速度範圍慢。
3、聯合索引比每個列建索引更有優勢,因為索引建立得越多就越佔磁碟空間,在更新資料的時候速度會越慢、另外建立多列索引時,順序也是要注意的,應該要講嚴格的索引放在前面,這樣篩選的力道會更大,效率更高。
支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交和回滚。
插入速度快,空间和内存使用比较低。如果表主要是用于插入新纪录和读取记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发要求比较低,也可以使用。
注意,同一个数据库也可以使用多种存储引擎的表。如果一个表要求比较高的事务处理,可以选择InnoDB。这个数据库中可以将查询要求比较高的表选择MyISAM存储。如果该数据库需要一个用于查询的临时表,可以选择MEMORY存储引擎。
在mysql中常用两种索引结构(算法)BTree和Hash,两种算法检索方式不一样,对查询的作用也不一样。
Hash索引的底层实现是由Hash表来实现的,非常适合以 key-value 的形式查询,也就是单个key 查询,或者说是等值查询。
Hash 索引可以比较方便的提供等值查询的场景,由于是一次定位数据,不像BTree索引需 要从根节点到枝节点,最后才能访问到页节点这样多次IO访问,所以检索效率远高于BTree索引。但是对于范围查询的话,就需要进行全表扫描了。
但为什么我们使用BTree比使用Hash多呢?主要Hash本身由于其特殊性,也带来了很多限制和弊端:
Hash索引仅仅能满足“=”,“IN”,“”查询,不能使用范围查询。
联合索引中,Hash索引不能利用部分索引键查询。 对于联合索引中的多个列,Hash是要么全部使用,要么全部不使用,并不支持BTree支持的联合索引的最优前缀,也就是联合索引的前面一个或几个索引键进行查询时,Hash索引无法被利用。
Hash索引无法避免数据的排序操作 由于Hash索引中存放的是经过Hash计算之后的Hash值,而且Hash值的大小关系并不一定和Hash运算前的键值完全一样,所以数据库无法利用索引的数据来避免任何排序运算。
Hash索引任何时候都不能避免表扫描 Hash索引是将索引键通过Hash运算之后,将Hash运算结果的Hash值和所对应的行指针信息存放于一个Hash表中,由于不同索引键存在相同Hash值,所以即使满足某个Hash键值的数据的记录条数,也无法从Hash索引中直接完成查询,还是要通过访问表中的实际数据进行比较,并得到相应的结果。
Hash索引遇到大量Hash值相等的情况后性能并不一定会比BTree高 对于选择性比较低的索引键,如果创建Hash索引,那么将会存在大量记录指针信息存于同一个Hash值相关联。这样要定位某一条记录时就会非常麻烦,会浪费多次表数据访问,而造成整体性能底下。
B+Tree索引是最常用的mysql数据库索引算法,因为它不仅可以被用在=,>,>=,
例如:
select * from user where name like 'jack%'; select * from user where name like 'jac%k%';
如果一通配符开头,或者没有使用常量,则不会使用索引,
例如:
select * from user where name like '%jack'; select * from user where name like simply_name;
在数据库中,数据量相对较大,多路查找树显然更加适合数据库的应用场景,接下来我们就介绍这两类多路查找树,毕竟作为程序员,心里没点B树怎么能行呢?
B树:B树就是B-树,他有着如下的特性:
B树不同于二叉树,他们的一个节点可以存储多个关键字和多个子树指针,这就是B+树的特点;
一个m阶的B树要求除了根节点以外,所有的非叶子子节点必须要有[m/2,m]个子树;
根节点必须只能有两个子树,当然,如果只有根节点一个节点的情况存在;
B树是一个查找二叉树,这点和二叉查找树很像,他都是越靠前的子树越小,并且,同一个节点内,关键字按照大小排序;
B树的一个节点要求子树的个数等于关键字的个数+1;
B+树就是B树的plus版
B+树将所有的查找结果放在叶子节点中,这也就意味着查找B+树,就必须到叶子节点才能返回结果;
B 樹每一個節點的關鍵字個數和子樹指標個數相同;
B 樹的非葉子節點的每一個關鍵字對應一個指針,而關鍵字則是子樹的最大,或者最小值;
將上一節中的B-Tree優化,由於B Tree的非葉子節點只儲存鍵值訊息,假設每個磁碟區塊能儲存4個鍵值及指標訊息,則變成B Tree後其結構如下圖所示:
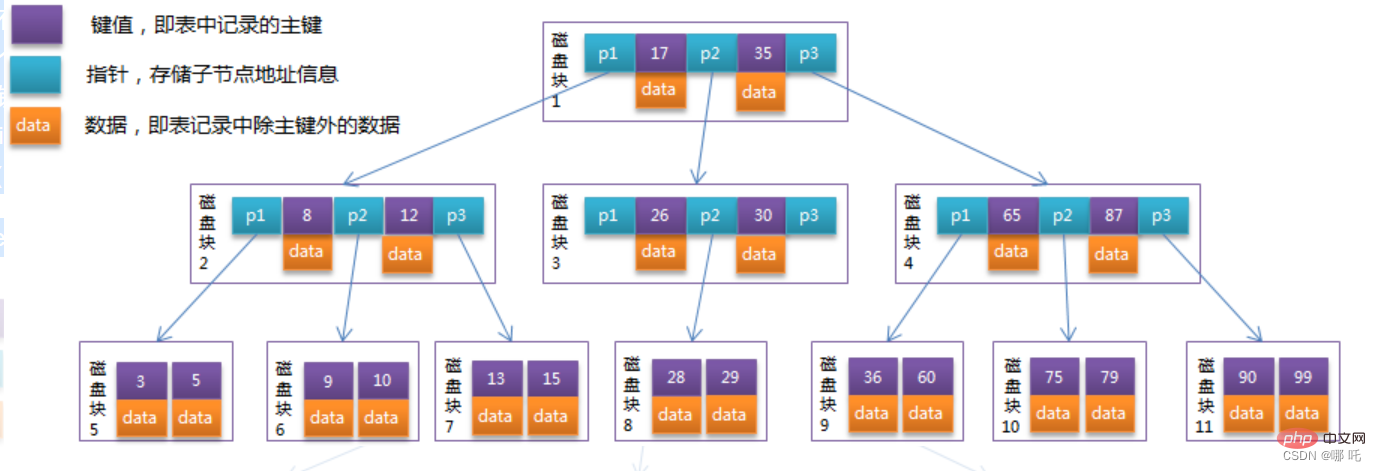
通常在B Tree上有兩個頭指針,一個指向根節點,另一個指向關鍵字最小的葉子節點,而且所有葉子節點(即資料節點)之間是一種鍊式環結構。因此可以對B Tree進行兩種查找運算:一種是對於主鍵的範圍查找和分頁查找,另一種是從根節點開始,進行隨機查找。
可能上面例子中只有22筆資料記錄,看不出B Tree的優點,下面做一個推算:
InnoDB儲存引擎中頁的大小為16KB,一般表的主鍵類型為INT(佔用4個位元組)或BIGINT(佔用8個位元組),指標型別也一般為4或8個位元組,也就是說一個頁(B Tree中的一個節點)中大概儲存 16KB/(8B 8B)=1K個鍵值(因為是估值,為方便計算,這裡的K取值為〖10〗^3)。
也就是說一個深度為3的B Tree索引可以維護10^3 * 10^3 * 10^3 = 10億筆記錄。
實際情況中每個節點可能無法填滿,因此在資料庫中,B Tree的高度一般都在2-4層。 MySQL的InnoDB儲存引擎在設計時是將根節點常駐記憶體的,也就是說尋找某一鍵值的行記錄時最多只需要1~3次磁碟I/O操作。
資料庫中的B Tree索引可以分為聚集索引(clustered index)和輔助索引(secondary index)。上面的B Tree範例圖在資料庫中的實作即為聚集索引,聚集索引的B Tree中的葉子節點存放的是整張表的行記錄資料。輔助索引與聚集索引的區別在於輔助索引的葉子節點並不包含行記錄的全部數據,而是儲存相應行數據的聚集索引鍵,即主鍵。當透過輔助索引來查詢資料時,InnoDB儲存引擎會遍歷輔助索引找到主鍵,然後再透過主鍵在聚集索引中找到完整的行記錄資料。
推薦學習:mysql影片教學
#以上是MySQL單列索引與聯合索引總結的詳細內容。更多資訊請關注PHP中文網其他相關文章!






















