

這篇文章為大家帶來了關於mysql的相關知識,其中主要介紹了explain的相關問題,Mysql中的explain堪稱Mysql的性能優化分析神器,我們可以透過它來分析SQL語句的對應的執行的,希望對大家有幫助。

推薦學習:mysql影片教學
#資料庫效能最佳化是每個後端程式猿必備的基礎技能之一,而Mysql中的explain堪稱Mysql的性能優化分析神器,我們可以透過它來分析SQL語句的對應的執行計劃在Mysql底層到底是如何執行的,它對於我們評估SQL的執行效率以及確定Mysql的性能優化方向具有重要的意義。但許多同學對於如何根據explain對已有SQL進行深度的執行分析還是丈二和尚摸不著頭腦,因此本文詳細闡述透過explain分析定位資料庫效能問題。
對於每個SQL來說,當它被客戶端送到Mysql服務端之後,會經過Mysql的最佳化器元件的分析,主要包括一些特殊的處理、執行順序的改變以確保最優的執行效率,最終產生對應的執行計畫。所謂的執行計劃,實際上就是在儲存引擎層面如何獲取數據的,是透過索引獲取數據還是進行全表掃描獲取數據,獲取到數據後需不需要回表,等等,簡單理解就是Mysql獲取數據的過程。
接下來我們來詳細看下,這個explain到底是何方神聖,為什麼能引導我們進行效能優化。當我們執行如下語句:
explain SELECT * FROM user_info where NAME='mufeng'
執行explain語句之後,我們會得到如下的執行結果,這個類似資料庫表的12個欄位其實就是對Mysql執行怎樣的執行計畫的詳細描述。下面我們來好好研究下這12個欄位分別代表什麼意思,只有搞清楚它們的意義,我們才能明確Mysql到底是怎麼執行資料查詢的。

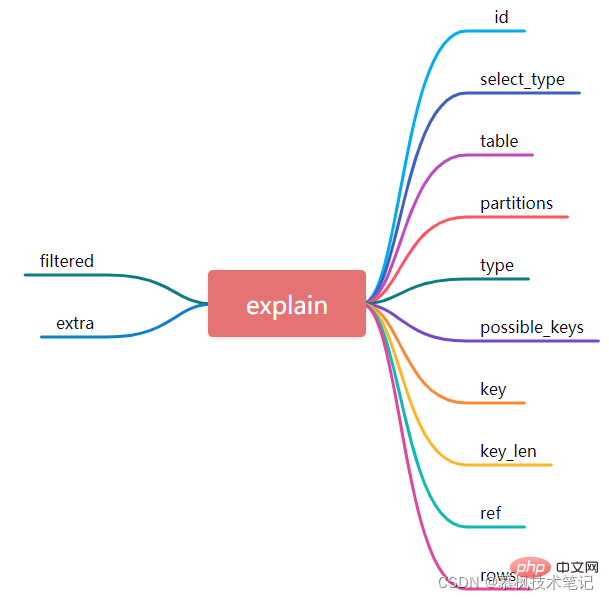
1、id
其實每次select查詢都會對應一個id,它代表SQL執行的順序,如果id值越大,表示對應的SQL語句執行的優先權越高。在一些複雜的查詢SQL語句中常常包含一些子查詢,那麼id序號就會遞增,如果出現巢狀查詢,我們可以發現最裡層的查詢對應的id最大,因此也優先被執行。

如上圖所示,SQL查詢語句中,第一個執行計畫的id為1,第二個執行計畫的id為2,id為1的執行計劃對應的table為order,id為2的執行計劃對應的table是user_info,結合SQL語句,我們知道先執行子查詢select id from user_info,而後再執行關於表order的資料查詢。
2、select_type
select_type表示的執行計劃的對應的查詢是什麼類型,常見的查詢類型主要包括普通查詢、聯合查詢以及子查詢等。 SIMPLE(查詢語句為簡單的查詢不包含子查詢)、PRIMARY(當查詢語句中包含子查詢的時候,對應最外層的查詢類型)、UNION(union之後出現的select語句對應的查詢類型會標記此類型)、SUBQUERY(子查詢會被標記為此類型)、DEPENDENT SUBQUERY(取決於外面的查詢)

3、table
#table代表表格名稱,表示要查詢哪張表格。當然不一定是真實的表的名稱,也可能是表的別名或臨時表。
4、partitions
#partitions代表的是分區的概念,表示在進行查詢時,如果對應的表都會死分區表,那麼這裡就會顯示具體的分區資訊。
5、type
type是非常核心的屬性,需要重點掌握。它表示的是目前透過什麼樣的方式對資料庫表進行分存取。
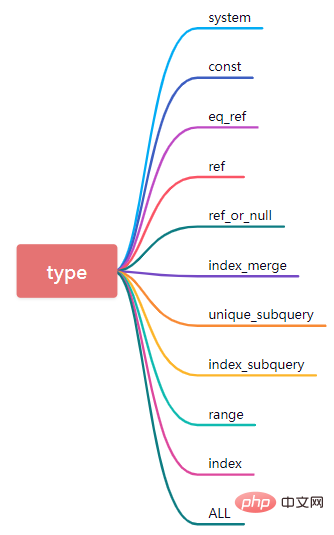
(1)system
表格只有一行(相當於系統表),資料量很小,查詢速度很快,system是const類型的特殊情況。
(2)const
如果type是const,說明在進行資料查詢的時候,命中了primary key或唯一索引,此類資料查詢速度非常快。

(3)eq_ref
在進行資料查詢的過程中,如果SQL語句中在資料表連接情況下可以基於叢集索引或非null值的唯一索引記性資料掃描,那麼此時type對應的值就會顯示為eq_ref。
(4)ref
資料查詢的時候如果命中的索引是二級索引不是唯一索引,測試查詢速度也會很快,但是type是ref。另外如果是多字段的聯合索引,那麼根據最左邊匹配原則,從聯合索引的最左側開始連續多個列的字段進行等值比較也是ref的類型。

(5)ref_or_null
這個連線類型類似 ref,差別在於 MySQL會額外搜尋包含NULL值的行。
(7)unique_subquery
在where條件中的關於in的子查詢條件集合
(8)index_subquery
區別於unique_subquery,用於非唯一索引,可以傳回重複值。
(9)range
使用索引進行行資料檢索,只對指定範圍內的行資料進行檢索。換句話說就是針對一個有索引的字段,在指定範圍中檢索資料。在where語句中使用 bettween...and、<、>、<=、in 等條件查詢 type 都是 range。

(10)index
Index 與ALL 其實都是讀全表,差別在於index是遍歷索引樹讀取,而ALL是從硬碟中讀取。
(11)all
遍歷全表進行資料匹配,此時的資料查詢效能最差。
6、possible_keys
#表示哪些索引可以被Mysql的最佳化器來選擇,也就是索引候選者有哪些。
7、key
在possible_keys中實際選擇的索引
8、key_len
#表示索引的長度,和實際的欄位屬性以及是否為null都有關係。
9、ref
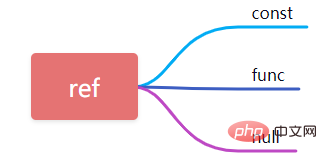
當使用欄位進行常數等值查詢時ref此處為const,當查詢條件中使用了表達式或函數則ref顯示為func,則其他的顯示為null。
10、rows
rows列顯示MySQL認為它執行查詢時必須檢查的行數。行數越少,效率越高!
11、filtered
filtered 這個是一個百分比的值,表裡符合條件的記錄數的百分比。簡單點說,這個欄位表示儲存引擎回傳的資料在經過過濾後,剩下滿足條件的記錄數量的比例。
12、extra
在其他欄位不顯示額外資訊在此列進行展示。
(1)Using index
在進行資料查詢的時候,資料庫使用了覆蓋索引,就是查詢的列被索引覆蓋,使用到覆蓋索引查詢速度會非常快。不是使用select * ,而是使用select phone_number,就會用到覆蓋索引。

(2)Using where
查詢時未找到可用的索引,進而透過where條件過濾取得所需數據,但要注意的是並不是所有帶有where語句的查詢都會顯示Using where。

(3)Using temporary
表示查詢後結果需要使用臨時表來存儲,一般在排序或分組查詢時用到。
(4)Using filesort
此類型表示無法利用索引完成指定的排序操作,也就是ORDER BY的欄位實際上沒有索引,因此此類SQL是需要進行最佳化的。
上文中我们阐述了explain在分析SQL语句时,可以通过12个属性来分析SQL的大致执行过程,并以此来判断SQL存在的性能问题。那么接下来我们通过一个实际的例子,来具体看下如何结合explain来实现SQL的性能分析。
其实所谓的Mysql性能问题,大部分都指的是平台出现了慢查询问题。慢查询实际上是可以通过配置进行记录的,把执行时间超过某个设定的阈值的sql都记录下来,当出现问题的时候可以通过记录的慢查询日志进行问题的定位。但是有的时候,出现大量慢查询会导致数据库连接给占满,导致整个平台的出现异常。
实际上我们在产品评价表product_evaluation中是建立了索引的,正常来说应该是可以使用到对应的索引字段进行查询的。但是实际上查询耗时有几十秒的时间,远远超过我们的预期。那我们猜测是不是由于某种原因导致Mysql优化器没有选择对应的索引进行数据检索,最后造成慢查询的发生。到底执行计划是怎样的,还是得借助于explain来看下。

如上文所说,虽然explain有12个字段属性帮助我们进行执行计划的分析,但是实际上常用的核心字段也就几个。我们可以看的出来在possible_key中实际上包含了我们设置的索引的,但是实际上Mysql却选择了PRIMARY作为其实际使用的。那么问题来了,为什么明明设置了索引,但是实际并没有用上,呗Mysql吃了吗?另外为什么之前的业务中没有出现这个问题,而现在出现了?我们需要进行进一步的分析。
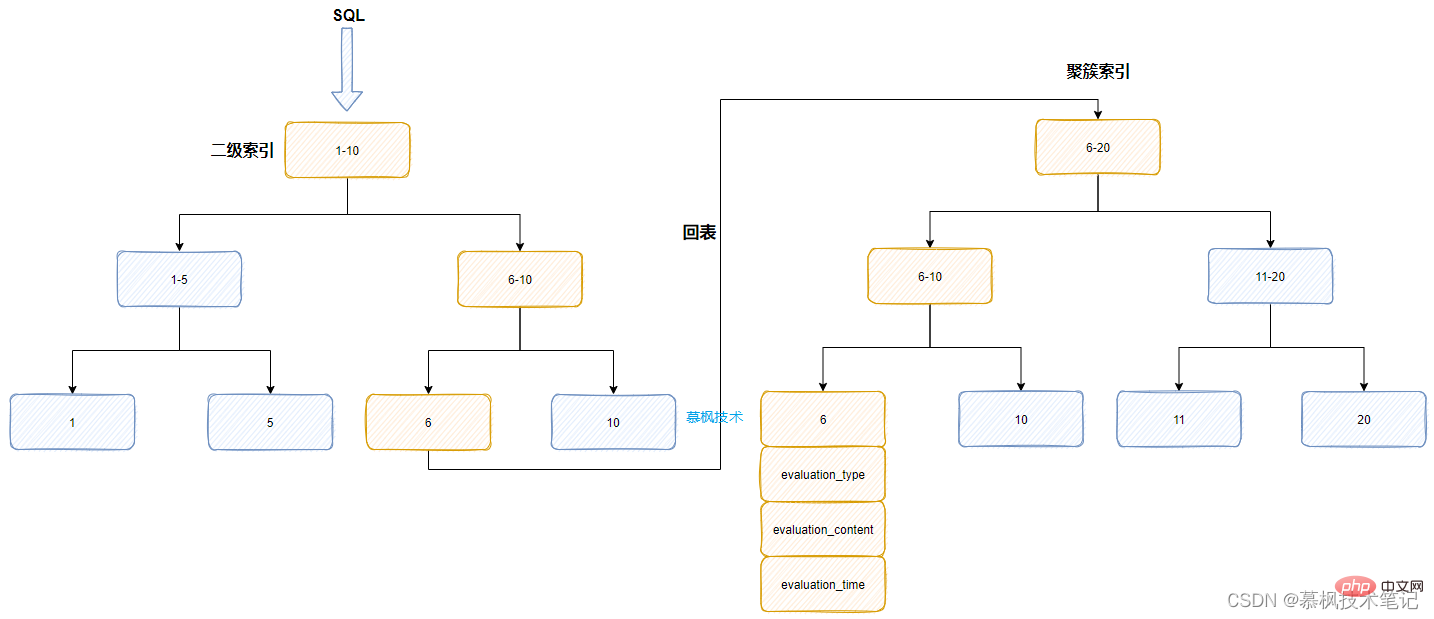
我们所建立的idx_evaluation_type实际上是一个二级索引(叶子节点是主键id),对于数千万一张的大表来说,实际上这个二级索引也是非常大的,而且这个字段本身的值就三个,变化不大。因此Mysql的优化器在分析这个SQL的时候发现,如果按照SQL中的索引来获取数据后再根据where条件进行筛选,筛选后的数据还需要回表到聚簇索引中获取实际的数据。
假如通过二级索引筛选出来的数据有几万条,而后还需要进行排序,这些操作都是基于临时磁盘我恩建进行的,Mysql判断这种方式的性能可能会很差,因此优化器放弃了原有的数据查询方式,直接通过主键id对应的聚簇索引来进行数据的获取,因为id本身就是有序的。
那么知道了查询慢的原因,我们应该怎么进行优化呢?实际上可以在SQL语句中增加force idnex,强制Mysql使用我们设置的二级索引。
SELECT * FROM product_evaluation force index(idx_product_id)WHERE product_id =1 and evaluation_type='GOOD' ORDER BY id desc LIMIT 200
通过上文对于explain使用的介绍,大家在遇到慢SQL问题的时候,可以先通过explain来进行初步的分析,主要明确SQL在Mysql中实际的执行过程是怎样的,如果查询字段没有索引则增加索引,如果有索引就要分析为什么没有用到索引。只要明确具体的执行过程,我们才能确定具体的查询优化方案。
推荐学习:mysql视频教程
以上是完全掌握Mysql的explain的詳細內容。更多資訊請關注PHP中文網其他相關文章!























