這篇文章為大家帶來了關於mysql中的相關知識,其中主要介紹了mysql事務的相關問題,事務是MySQL區別於NoSQL的重要特徵,是保證關係型資料庫數據一致性的關鍵技術,希望對大家有幫助。

推薦學習:mysql學習影片教學
交易是MySQL區別於NoSQL的重要特徵,是保證關係型資料庫資料一致性的關鍵技術。事務可視為對資料庫操作的基本執行單元,可能包含一個或多個SQL語句。這些語句在執行時,要麼都執行,要麼都不執行。
交易的執行主要包括兩個操作,提交和回滾。
提交:commit,將交易執行結果寫入資料庫。
回滾:rollback,回滾所有已經執行的語句,傳回修改之前的資料。
MySQL事務包含四個特性,號稱ACID四大天王。
原子性(Atomicity) :語句要麼全執行,要麼全不執行,是事務最核心的特性,事務本身就是以原子性來定義的;實現主要基於undo log日誌實現的。
持久性(Durability :保證事務提交後不會因為宕機等原因導致資料遺失;實現主要基於redo log日誌。
隔離性(Isolation) :保證事務執行盡可能不受其他事務影響;InnoDB預設的隔離等級是RR,RR的實作主要基於鎖定機制、資料的隱藏欄位、undo log和類別next-key lock機制。
一致性(Consistency) :事務追求的最終目標,一致性的實現既需要資料庫層面的保障,也需要應用層面的保障。
鎖定機制
交易之間的隔離,是透過鎖定機制實現的。當一個交易需要修改資料庫中的某行資料時,需要先給數據加鎖;加了鎖的數據,其它事務是不運行操作的,只能等待當前事務提交或回滾將鎖釋放。鎖機制並不是一個陌生的概念,在許多場景中都會利用到不同實現的鎖對資料進行保護和同步。而在MySQL中,依照不同的分割標準,也可將鎖分為不同的種類。依粒度劃分:行鎖、表鎖、頁鎖依使用方式分割:共享鎖定、排它鎖定依照思想分割:悲觀鎖、樂觀鎖鎖定機制的知識點很多,由於篇幅不好全部展開講。這裡對按照粒度劃分的鎖進行簡單介紹。
粒度:指資料倉儲的資料單位中保存資料的細化或綜合程度的等級。細化程度越高,粒度級就越小;相反,細化程度越低,粒度級就越大。MySQL依照鎖定的粒度劃分可以分為行鎖定、表格鎖定和頁鎖定。
行鎖:粒度最小的鎖,表示只針對目前操作的行加鎖;
表鎖定:粒度最大的鎖,表示目前的操作對整張表加鎖;
頁鎖定:粒度介於行級鎖定和表格層級鎖定中間的一種鎖定,表示對頁進行加鎖。
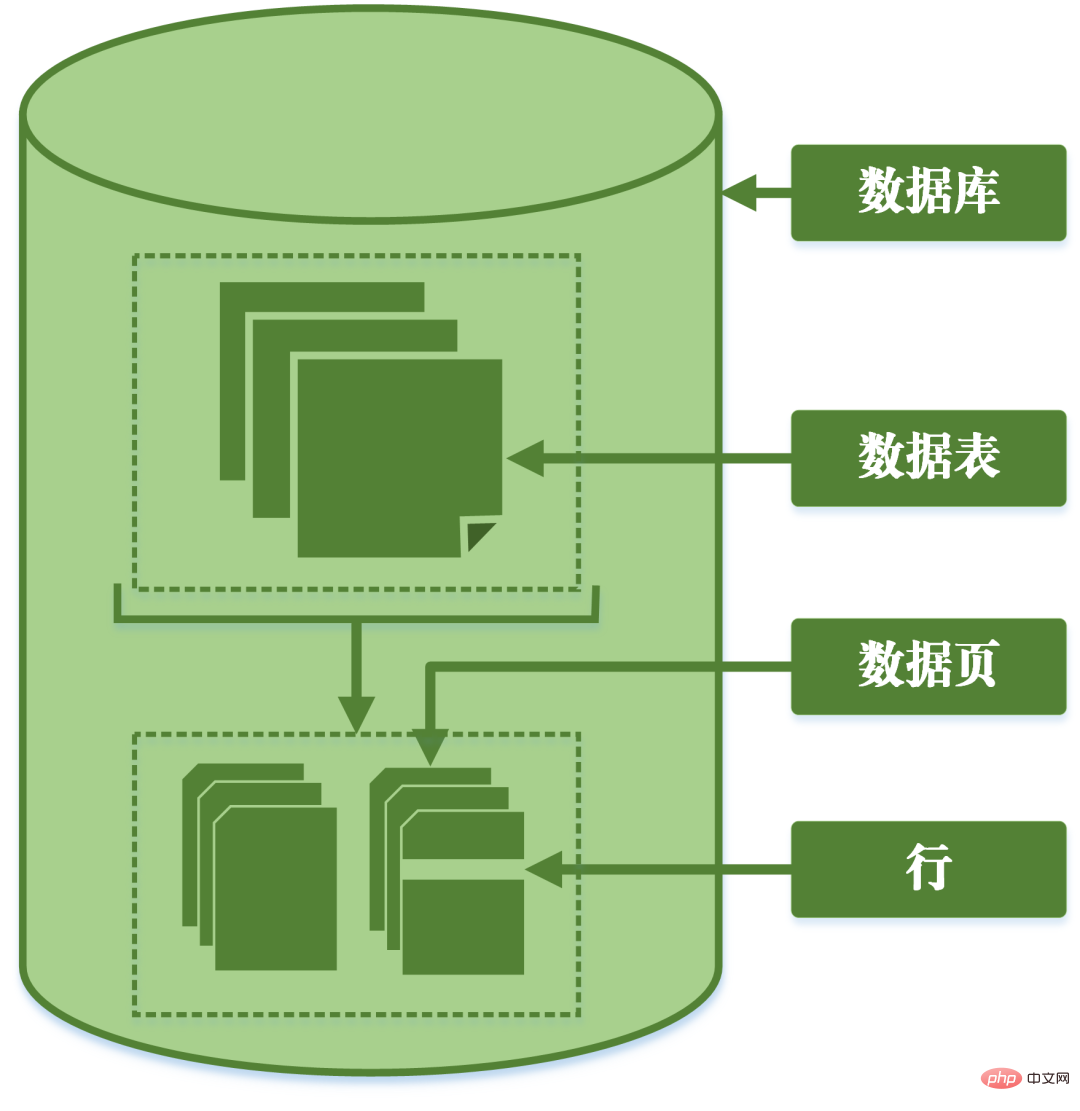
資料庫的粒度分割
這三種鎖定是在不同層次上對資料進行鎖定,由於粒度的不同,其帶來的好處和劣勢也不一而同。
表鎖在操作資料時會鎖定整張表,因而並發效能較差;
行鎖則只鎖定需要操作的數據,並發效能好。但由於加鎖本身需要消耗資源(取得鎖、檢查鎖、釋放鎖等都需要消耗資源),因此在鎖定資料較多情況下使用表鎖可以節省大量資源。
MySQL中不同的儲存引擎能夠支援的鎖定也是不一樣的。 MyIsam只支援表鎖,而InnoDB同時支援表鎖和行鎖,且出於效能考慮,絕大多數情況下使用的都是行鎖。
並發讀寫問題
在並發情況下,MySQL的同時讀寫可能會導致三類問題,髒讀、不可重複度和幻讀。
(1)髒讀:目前事務中讀到其他交易未提交的數據,也就是髒數據。
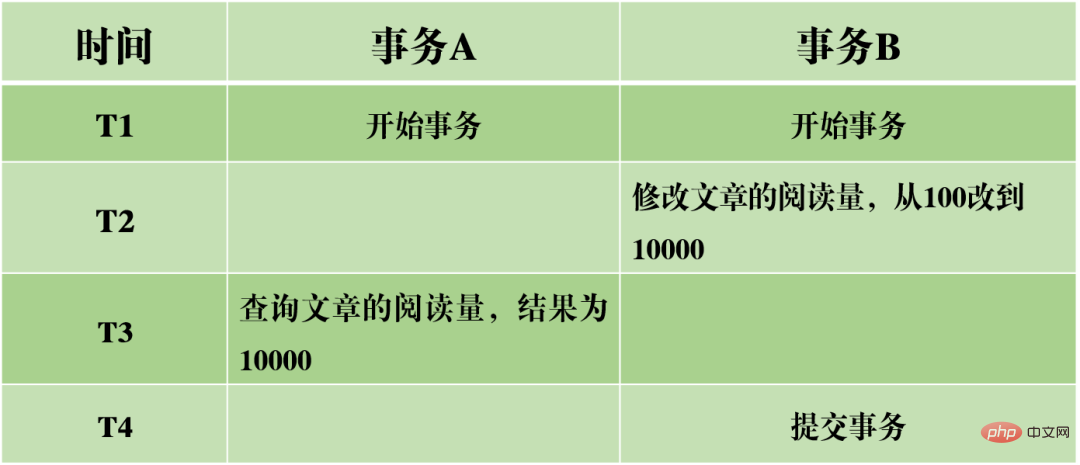
以上圖為例,事務A在讀取文章的閱讀量時,讀取到了交易B為提交的資料。如果事務B最後沒有順利提交,導致事務回滾,那麼實際上閱讀量並沒有修改成功,而事務A卻是讀到的修改後的值,顯然不合情理。
(2)不可重複讀:在事務A中先後兩次讀取同一個數據,但是兩次讀取的結果不一樣。髒讀與不可重複讀的差別在於:前者讀到的是其他交易未提交的數據,後者讀到的是其他交易已提交的數據。
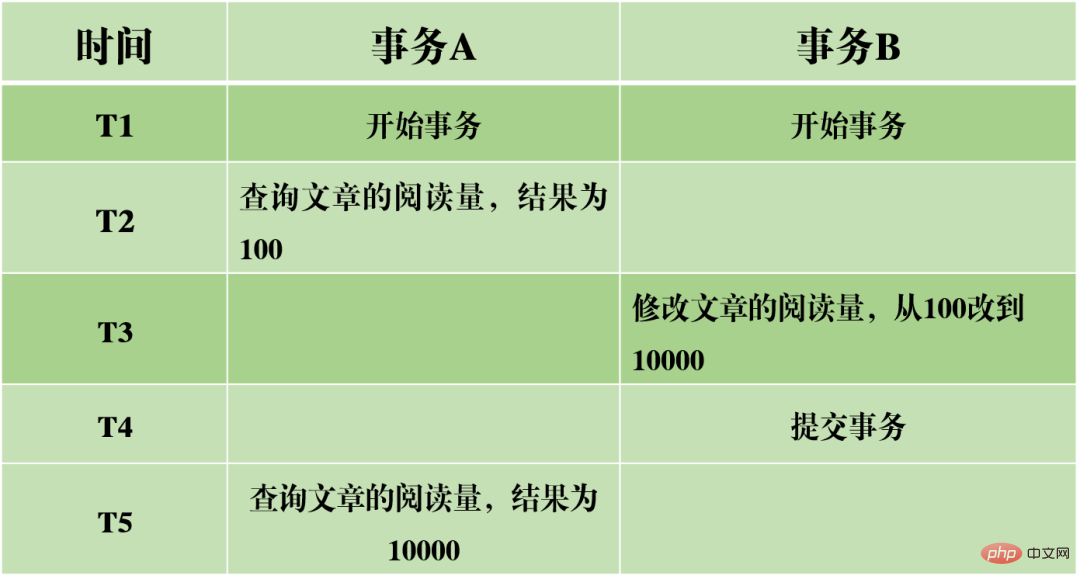
以上圖為例,當事務A先後讀取文章閱讀量的資料時,結果卻不一樣。說明事務A在執行的過程中,閱讀量的值被其它事務給修改了。這使得資料的查詢結果不再可靠,同樣也不合實際。
(3)幻讀:在事務A中依照某個條件先後兩次查詢資料庫,兩次查詢結果的行數不同,這種現象稱為幻讀。不可重複讀與幻讀的差異可以通俗的理解為:前者是資料變了,後者是資料的行數變了。
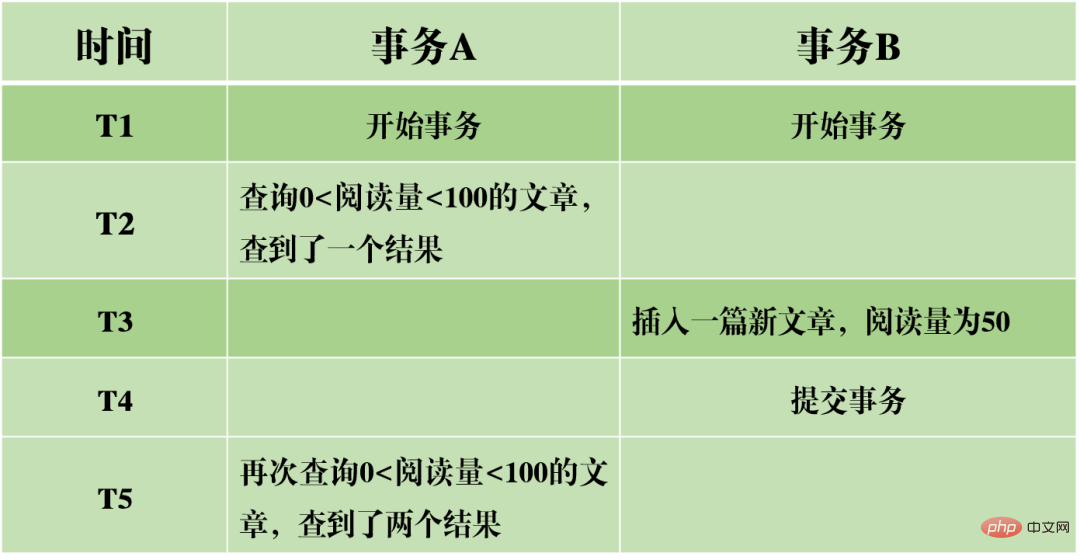
以上圖為例,當對0<閱讀量<100的文章進行查詢時,先查到了一個結果,後來查詢到了兩個結果。這表示同一個事務的查詢結果數不一,行數不一致。這樣的問題使得在根據某些條件對資料篩選的時候,前後篩選結果不具可靠性。
隔離級別
根據上面這三種問題,產生了四種隔離級別,顯示資料庫不同程度的隔離性質。
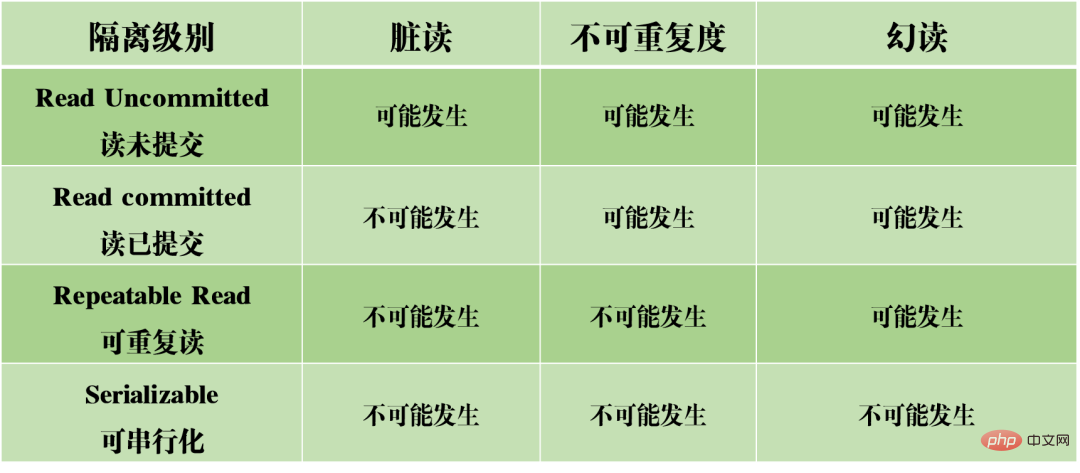
在實際的資料庫設計中,隔離等級越高,導致資料庫的並發效率會越低;而隔離等級太低,又會導致資料庫在讀寫過程中會遇到各種亂七八糟的問題。
因此在大多數資料庫系統中,預設的隔離等級時讀已提交(如Oracle)或可重複讀取RR(MySQL的InnoDB引擎)。
MVCC
又是一個難嚼的大塊頭。 MVCC就是用來實現上面的第三個隔離級別,可重複讀RR。
MVCC:Multi-Version Concurrency Control,即多版本的並發控制協定。
MVCC的特點是在同一時刻,不同事務可以讀取到不同版本的數據,從而可以解決髒讀和不可重複讀的問題。
MVCC其實就是透過資料的隱藏列和回溯日誌(undo log),實現多個版本資料的共存。這樣的好處是,使用MVCC進行讀取資料的時候,不用加鎖,從而避免了同時讀寫的衝突。
在實作MVCC時,每一行的資料中會額外保存幾個隱藏的列,例如目前行建立時的版本號和刪除時間和指向undo log的回溯指標。這裡的版本號碼並不是實際的時間值,而是系統版本號。每開始新的事務,系統版本號碼就會自動遞增。事務開始時的系統版本號會作為事務的版本號,用來和查詢每行記錄的版本號進行比較。
每個交易都有自己的版本號,這樣事務內執行資料操作時,就透過版本號的比較來達到資料版本控制的目的。
另外,InnoDB實現的隔離等級RR時可以避免幻讀現象的,這是透過next-key lock機制實現的。
next-key lock其實就是行鎖的一種,只不過它不只是會鎖住目前行記錄的本身,還會鎖定一個範圍。例如上面幻讀的例子,開始查詢0<閱讀量<100的文章時,只查到了一個結果。 next-key lock會將查詢出的這一行鎖定,同時也會對0<閱讀量<100這個範圍加鎖,這其實是一種間隙鎖。間隙鎖能夠防止其他事務在這個間隙修改或插入記錄。這樣一來,就保證了在0<閱讀量<100這個間隙中,只存在原來的一行數據,從而避免了幻讀。
間隙鎖定:封鎖索引記錄中的間隔
雖然InnoDB使用next-key lock能夠避免幻讀問題,但卻並不是真正的可串列化隔離。再來看一個例子吧。
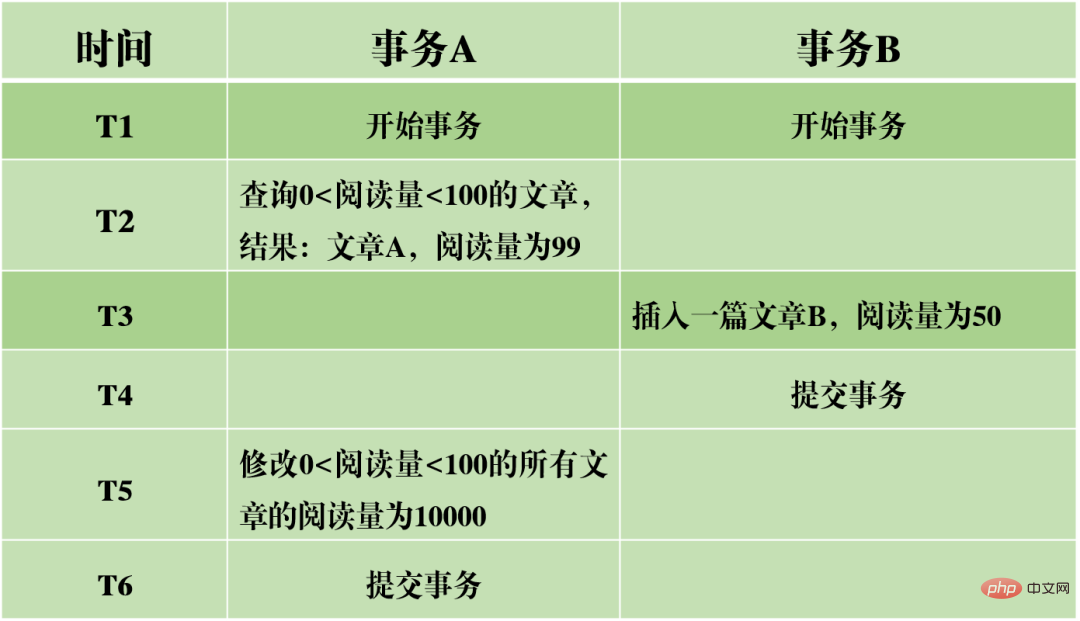
先提一個問題:
在T6時間,事務A提交事務之後,猜一猜文章A和文章B的閱讀量為多少?
答案是,文章AB的閱讀量都被修改成了10000。這代表著事務B的提交實際上對事務A的執行產生了影響,顯示兩個事務之間並不是完全隔離的。雖然能夠避免幻讀現象,但卻沒有達到可串列化的等級。
這也說明,避免髒讀、不可重複讀和幻讀,是達到可串列化的隔離等級的必要不充分條件。可串行化是都能夠避免髒讀、不可重複讀和幻讀,但是避免髒讀、不可重複讀和幻讀卻不一定達到了可串行化。
一致性
一致性是指交易執行結束後,資料庫的完整性限制沒有被破壞,交易執行的前後都是合法的資料狀態。
一致性是交易追求的最終目標,原子性、持久性和隔離性,實際上都是為了保證資料庫狀態的一致性而存在的。
這就不多說了吧。你細品。
了解完MySQL的基本架構,大體上能夠對MySQL的執行流程有了比較清晰的認知。接下來我將為大家介紹一下日誌系統。
MySQL日誌系統是資料庫的重要元件,用於記錄資料庫的更新和修改。若資料庫發生故障,可透過不同日誌記錄復原資料庫的原先資料。因此實際上日誌系統直接決定MySQL運行的穩健性和穩健性。
MySQL的日誌有很多種,如二進位日誌(binlog)、錯誤日誌、查詢日誌、慢查詢日誌等,此外InnoDB儲存引擎也提供了兩種日誌:redo log(重做日誌)和undo log(回溯日誌)。這裡將重點針對InnoDB引擎,對重做日誌、回滾日誌和二進位日誌這三種進行分析。
重做日誌(redo log)
重做日誌(redo log)是InnoDB引擎層的日誌,用來記錄交易操作引起資料的變化,記錄的是資料頁的物理修改。
重做日記的作用其實很好理解,我打個比方。資料庫中資料的修改就好比你寫的論文,萬一哪天論文丟了怎麼呢?以防這種不幸的發生,我們可以在寫論文的時候,每一次修改都拿個小本本記錄一下,記錄什麼時間對某一頁進行了怎麼樣的修改。這就是重做日誌。
InnoDB引擎對資料的更新,是先將更新記錄寫入redo log日誌,然後會在系統空閒的時候或是依照設定的更新策略再將日誌中的內容更新到磁碟之中。這就是所謂的預寫式技巧(Write Ahead logging)。這種技術可以大幅減少IO操作的頻率,提升資料刷新的效率。
骯髒資料刷盤
值得注意的是,redo log日誌的大小是固定的,為了能夠持續不斷的對更新記錄進行寫入,在redo log日誌中設定了兩個標誌位置,checkpoint和write_pos,分別表示記錄擦除的位置和記錄寫入的位置。 redo log日誌的資料寫入示意圖可見下圖。
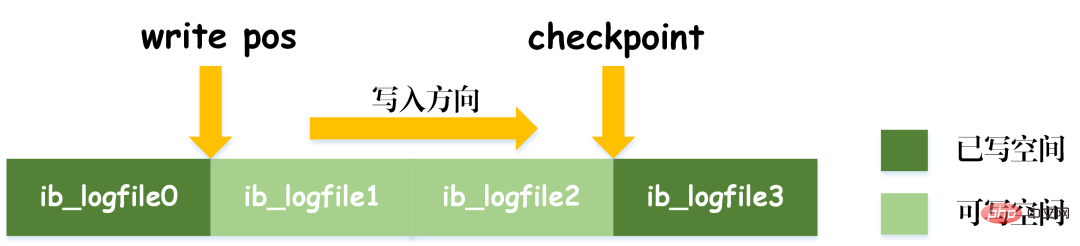
當write_pos標誌到了日誌結尾時,會從結尾跳至日誌頭進行重新循環寫入。所以redo log的邏輯結構並不是線性的,而是可看成一個圓週運動。 write_pos與checkpoint中間的空間可用於寫入新數據,寫入和擦除都是往後推移,循環往復的。
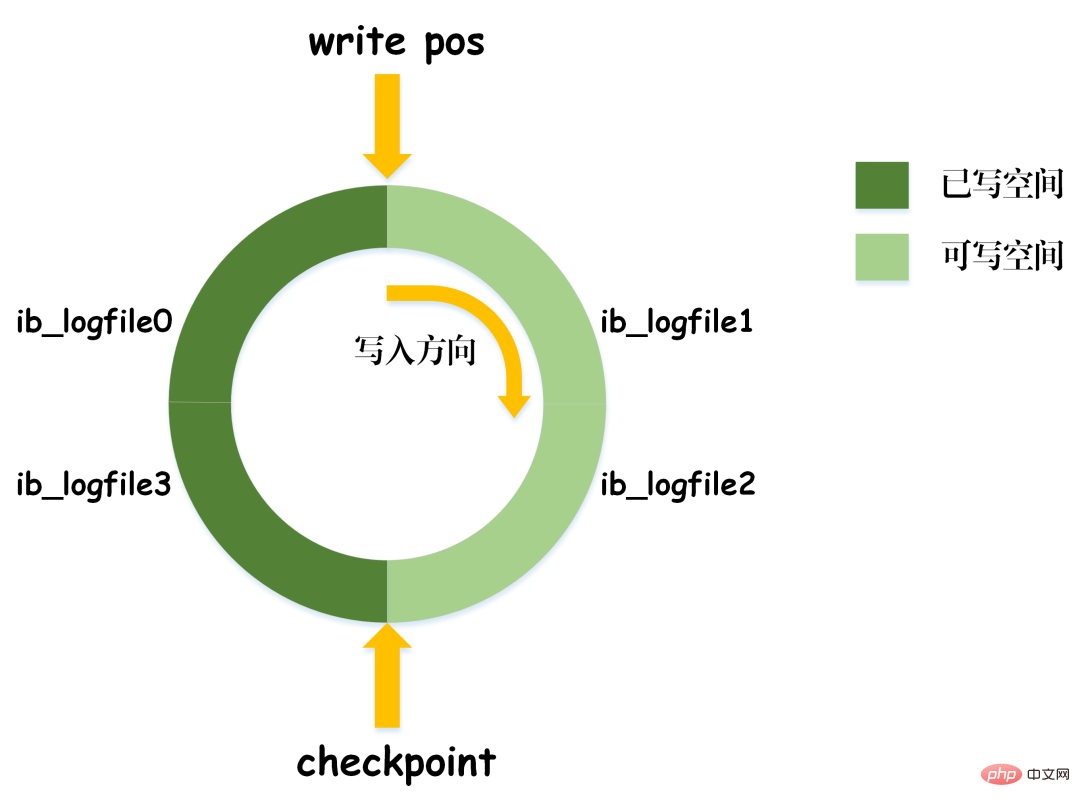
當write_pos追上checkpoint時,表示redo log日誌已經寫滿。這時不能繼續執行新的資料庫更新語句,需要停下來先刪除一些記錄,執行checkpoint規則騰出可寫空間。
checkpoint規則:checkpoint觸發後,將buffer中髒資料頁和髒日誌頁都刷到磁碟。
髒資料:指記憶體中未刷到磁碟的資料。
redo log中最重要的概念是緩衝池buffer pool,這是在記憶體中分配的一個區域,包含了磁碟中部分資料頁的映射,作為存取資料庫的緩衝。
當請求讀取資料時,會先判斷是否在緩衝池命中,如果未命中才會在磁碟上進行檢索後放入緩衝池;
當請求寫入資料時,會先寫入緩衝池,緩衝池中修改的資料會定期刷新到磁碟中。這個過程也被稱之為刷髒 。
因此,當資料修改時,除了修改buffer pool中的數據,也會在redo log中記錄這次操作;當交易提交時,會根據redo log的記錄對資料進行刷盤。如果MySQL宕機,重啟時可以讀取redo log中的數據,對資料庫進行恢復,從而保證了事務的持久性,使得資料庫獲得crash-safe能力。
髒日誌刷盤
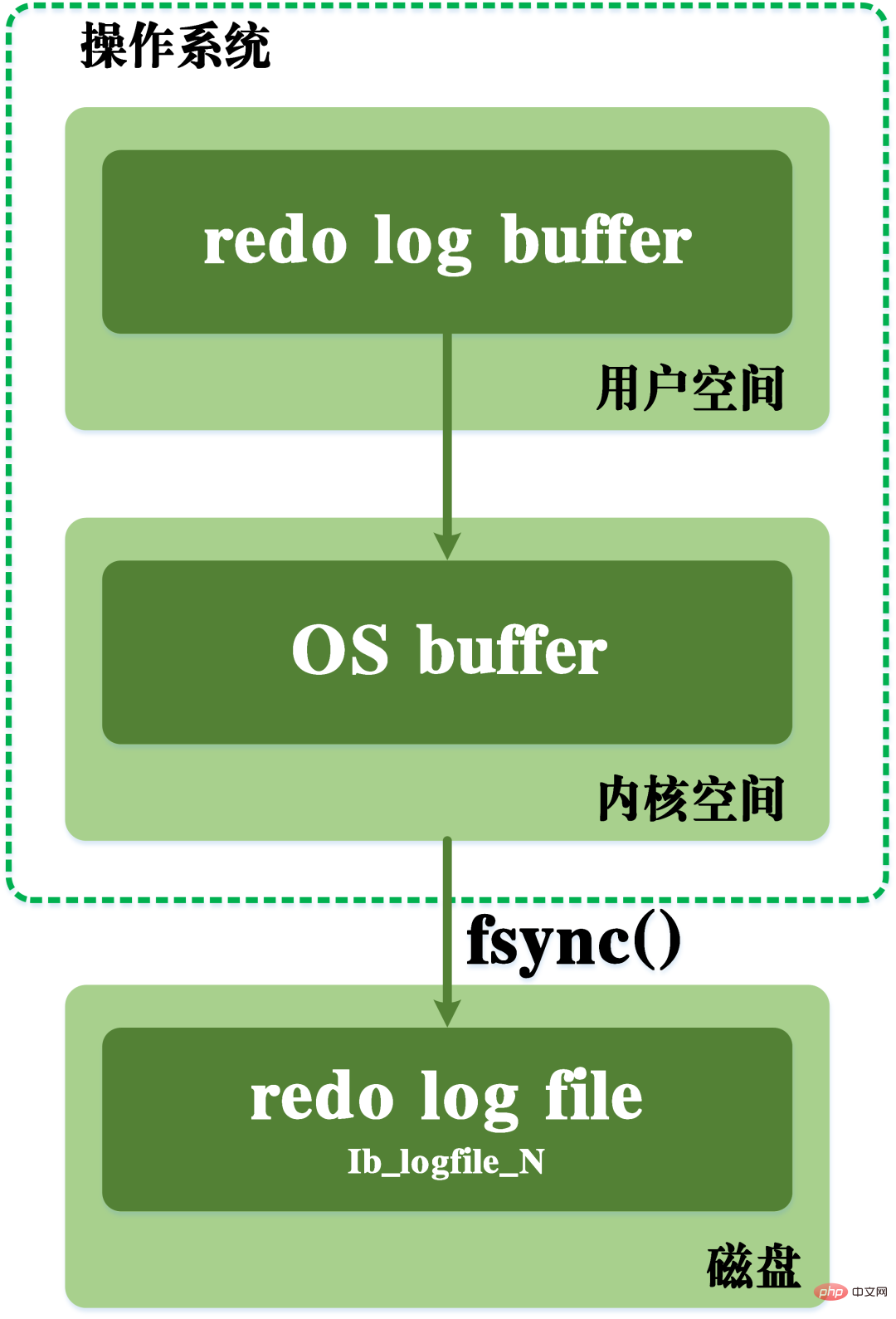
除了上面提到的對於髒資料的刷盤,實際上redo log日誌在記錄時,為了保證日誌檔案的持久化,也需要經歷將日誌記錄從記憶體寫入磁碟的過程。 redo log日誌可分為兩個部分,一是存在易失性記憶體中的快取日誌redo log buff,二是保存在磁碟上的redo log日誌檔redo log file。
為了確保每次記錄都能夠寫入磁碟中的日誌中,每次將redo log buffer中的日誌寫入redo log file的過程中都會呼叫一次作業系統的fsync動作。
fsync函數:包含在UNIX系統頭檔#include
中,用於同步記憶體中所有已修改的檔案資料到儲存裝置。 在寫入的過程中,還需要經過作業系統核心空間的os buffer。 redo log日誌的寫入過程可見下圖。
redo log日誌刷盤流程
#二進位日誌(binlog)
二進位日誌binlog是服務層的日誌,也稱為歸檔日誌。 binlog主要記錄資料庫的變更情況,內容包括資料庫所有的更新操作。所有涉及資料變動的操作,都要記錄進二進位日誌中。因此有了binlog可以很方便的對資料進行複製和備份,因而也常用作主從庫的同步。
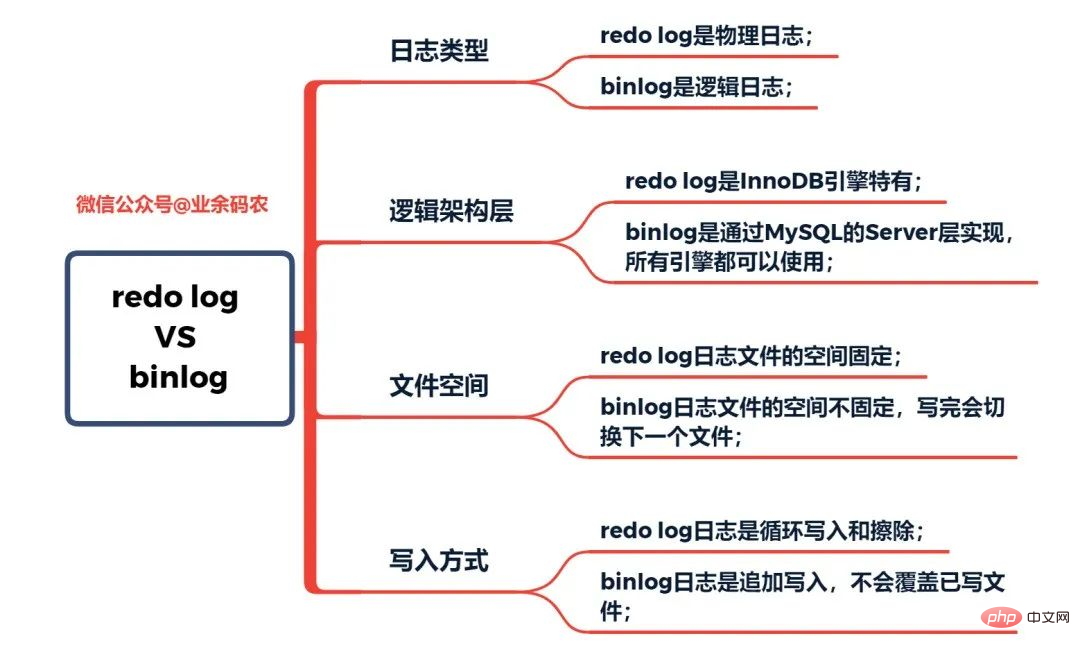
這裡binlog所儲存的內容看起來似乎跟redo log很相似,但其實不然。 redo log是一種實體日誌,記錄的是實際上對某個資料進行了怎麼樣的修改;而binlog是邏輯日誌,記錄的是SQL語句的原始邏輯,例如」給ID=2這一行的a字段加1 "。 binlog日誌中的內容是二進位的,根據日記格式參數的不同,可能基於SQL語句、基於資料本身或二者的混合。一般常用記錄的都是SQL語句。
這裡的物理和邏輯的概念,我的個人理解是:
物理的日誌可看作是實際資料庫中資料頁上的變化信息,只看重結果,而不在乎是透過「何種途徑」導致了這種結果;
邏輯的日誌可看作是透過了某一種方法或操作手段導致資料發生了變化,儲存的是邏輯性的操作。
同時,redo log是基於crash recovery,保證MySQL宕機後的資料恢復;而binlog是基於point-in-time recovery,保證伺服器可以基於時間點對資料進行恢復,或者對資料進行備份。
事實上最開始MySQL是沒有redo log日誌的。因為起先MySQL是沒有InnoDB引擎的,自備的引擎是MyISAM。 binlog是服務層的日誌,因此所有引擎都能夠使用。但光靠binlog日誌只能提供歸檔的作用,無法提供crash-safe能力,所以InnoDB引擎就採用了學自Oracle的技術,也就是redo log,這才擁有了crash-safe能力。這裡對redo log日誌和binlog日誌的特性分別進行了比較:
# redo log與binlog的特點比較
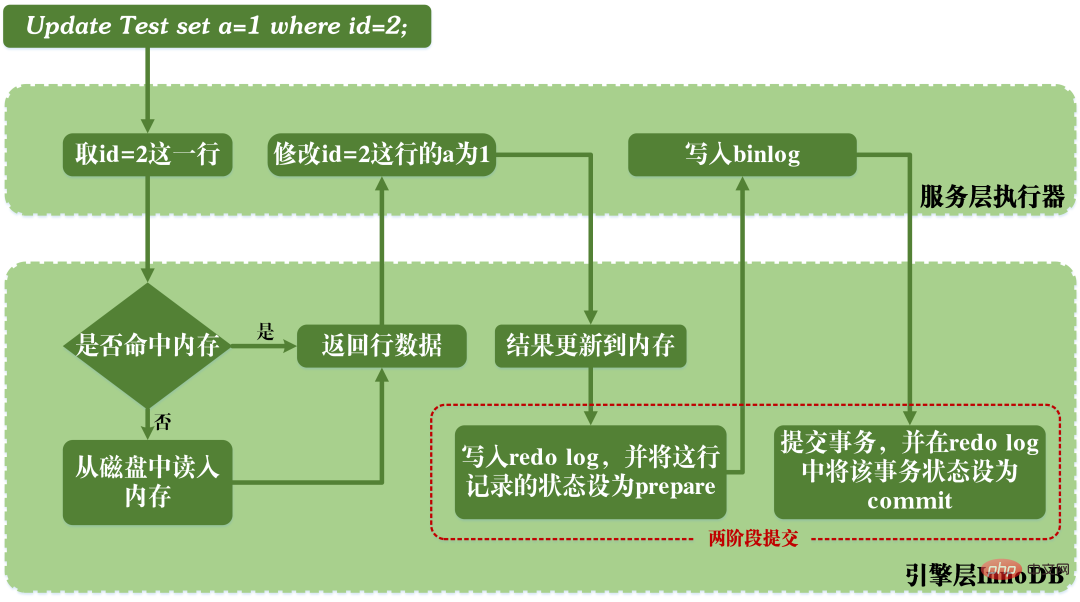
在MySQL執行更新語句時,都會涉及到redo log日誌和binlog日誌的讀寫。一條更新語句的執行過程如下:
MySQL更新語句的執行過程
從上圖可以看出,MySQL在執行更新語句的時候,在服務層進行語句的解析和執行,在引擎層進行資料的擷取與儲存;同時在服務層對binlog進行寫入,並在InnoDB內進行redo log的寫入。
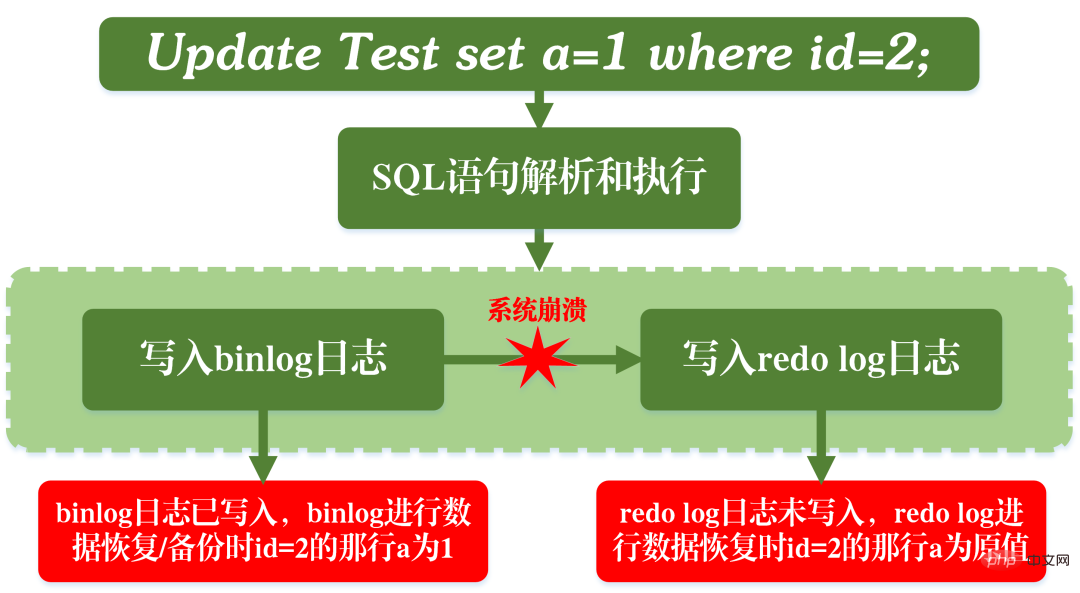
不僅如此,在對redo log寫入時有兩個階段的提交,一是binlog寫入之前prepare狀態的寫入,二是binlog寫入之後commit狀態的寫入。
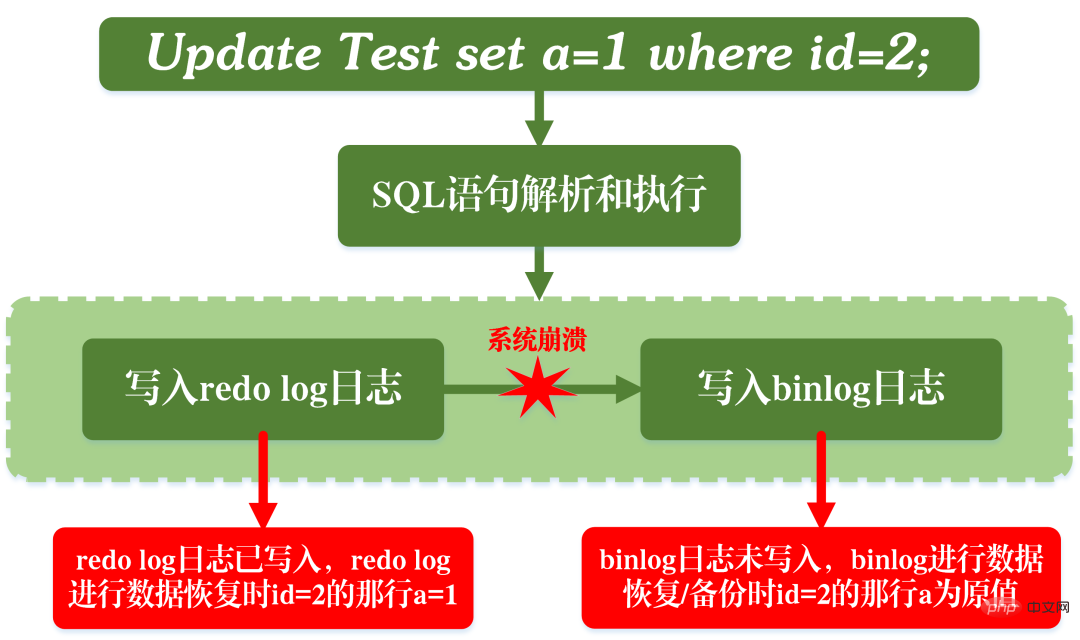
之所以要安排這麼兩階段提交,自然是有它的道理的。現在我們可以假設不採用兩階段提交的方式,而是採用「單階段」進行提交,即要么先寫入redo log,後寫入binlog;要么先寫入binlog,後寫入redo log。這兩種方式的提交都會導致原先資料庫的狀態和恢復後的資料庫的狀態不一致。
先寫入redo log,後寫入binlog:
#在寫完redo log之後,資料此時具有crash-safe能力,因此系統崩潰,數據會恢復成事務開始之前的狀態。但是,若在redo log寫完時候,binlog寫入之前,系統發生了宕機。此時binlog並未對上面的更新語句進行保存,導致當使用binlog進行資料庫的備份或還原時,就少了上述的更新語句。從而使得id=2這一行的資料沒有被更新。
先寫redo log後寫binlog的問題
先寫入binlog,然後寫入redo log:
#寫完binlog之後,所有的語句都被保存,所以透過binlog複製或恢復出來的資料庫中id=2這一行的資料會被更新為a=1。但如果在redo log寫入之前,系統崩潰,那麼redo log中記錄的這個事務會無效,導致實際資料庫中id=2這一行的資料並沒有更新。
先寫binlog後寫redo log的問題
由此可見,兩階段的提交就是為了避免上述的問題,使得binlog和redo log中保存的資訊是一致的。
回滾日誌(undo log)
#回溯日誌(undo log)回滾日誌同樣也是InnoDB引擎提供的日誌,顧名思義,回溯日誌的作用就是對資料進行回溯。當交易對資料庫進行修改,InnoDB引擎不僅會記錄redo log,還會產生對應的undo log日誌;如果交易執行失敗或呼叫了rollback,導致交易需要回滾,就可以利用undo log中的資訊將資料回滾到修改之前的樣子。 但是undo log不redo log不一樣,它屬於邏輯日誌。它會對SQL語句執行相關的資訊進行記錄。當發生回溯時,InnoDB引擎會根據undo log日誌中的記錄做與先前相反的工作。例如對於每個資料插入操作(insert),回滾時會執行資料刪除操作(delete);對於每個資料刪除操作(delete),回滾時會執行資料插入操作(insert);對於每個資料更新操作(update),回滾時會執行一個相反的資料更新操作(update),把資料改回去。 undo log由兩個作用,一是提供回滾,二是實現MVCC。
三、
主從複製主從複製的概念很簡單,就是從原來的資料庫複製一個完全一樣的資料庫,原來的資料庫稱為主資料庫,複製的資料庫稱為從資料庫。從資料庫會與主資料庫進行資料同步,保持二者的資料一致性。
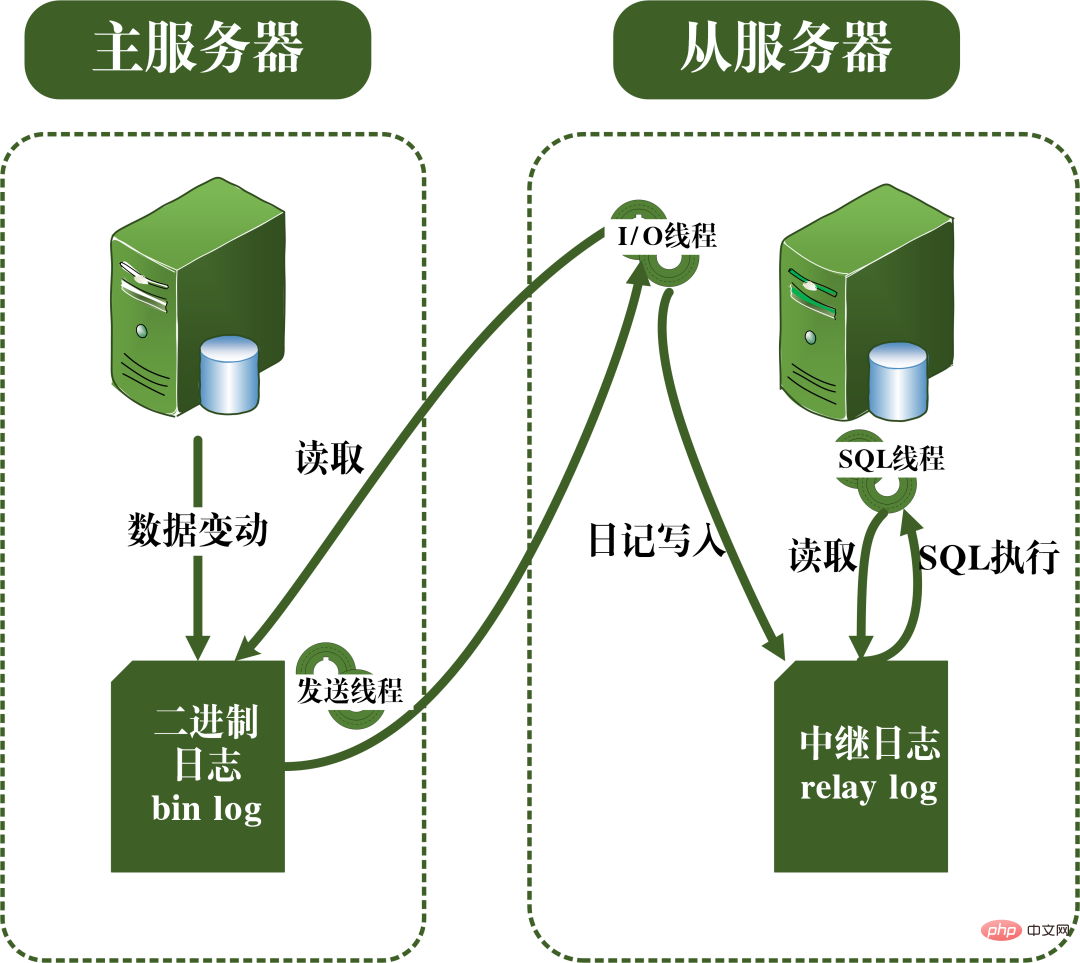
主從複製的原理其實就是透過bin log日誌實現的。 bin log日誌中保存了資料庫中所有SQL語句,透過對bin log日誌中SQL的複製,然後再進行語句的執行即可實現從資料庫與主資料庫的同步。
主從複製的過程可見下圖。主從複製的過程主要是靠三個線程進行的,一個運行在主伺服器中的發送線程,用於發送binlog日誌到從伺服器。兩外兩個運行在從伺服器上的I/O線程和SQL線程。 I/O執行緒用來讀取主伺服器傳送過來的binlog日誌內容,並拷貝到本地的中繼日誌中。 SQL執行緒用於讀取中繼日誌中關於資料更新的SQL語句並執行,從而實現主從庫的資料一致。主從複製原理之所以需要實作主從複製,實際上是由實際應用情境所決定的。主從複製所能帶來的好處有:#########1. 透過複製實現資料的異地備份,當主資料庫故障時,可切換從資料庫,避免資料遺失。 ###2. 可實現架構的擴展,當業務量越來越大,I/O存取頻率過高時,採用多庫的存儲,可以降低磁碟I/O存取的頻率,提高單一機器的I/ O性能。
3. 可實現讀寫分離,使資料庫支援更大的並發。
4. 實現伺服器的負載平衡,透過在主伺服器和從伺服器之間切分處理客戶查詢的負荷。
總結
MySQL資料庫應該算是程式設計師必須掌握的技術之一了。無論是專案過程中或是面試中,MySQL都是非常重要的基礎知識。不過,對於MySQL來說,真的東西太多了。我在寫這篇文章的時候,查閱了大量的資料,發現越看不懂的越多。還真是應了那句話:
你知道的越多,不知道的就越多。
這篇文章著重是從理論的角度去解析MySQL基本的事務和日誌系統的基本原理,我在表述的時候盡可能的避免採用實際的程式碼去描述。即便是這篇將近一萬字 近二十副純手工繪製的圖解,也難以將MySQL的博大精深分析透徹。
但我相信,對於初學者而言,這些理論能夠讓你對MySQL有一個整體的感知,讓你對「何謂關係型資料庫」這麼一個問題有了比較清晰的認知;而對於熟練MySQL的大佬來說,或許本文也能喚醒你塵封已久的底層理論基礎,對你之後的面試也會有一定幫助。
技術這種東西沒有絕對的對錯,倘若文中有誤還請諒解,並歡迎與我討論。自主思考永遠比被動接受更有效。
推薦學習:mysql影片教學
#以上是一起來分析一下MySQL事務日誌的詳細內容。更多資訊請關注PHP中文網其他相關文章!