

資料歸一化處理的目的在於:使得預處理的資料被限定在一定的範圍內,從而消除奇異樣本資料所導致的不良影響。資料歸一化處理後,可加快梯度下降求最優解的速度,且有可能提高精度(如KNN)。

本教學操作環境:windows7系統、Dell G3電腦。
#在機器學習領域中,不同評估指標(即特徵向量中的不同特徵就是所述的不同評價指標)#往往有不同的量綱和量綱單位,這樣的情況會影響到資料分析的結果,為了消除指標之間的量綱影響,需要進行資料標準化處理,以解決資料指標之間的可比性。原始資料經過資料標準化處理後,各指標為同一數量級,適合進行綜合對照評估。 其中,最典型的就是資料的歸一化處理。 (可參考學習:資料標準化/歸一化)
簡而言之,歸一化的目的就是使得預處理的資料被限定在一定的範圍內(例如[0,1]或[-1,1]),從而消除 #奇異樣本資料導致的不良影響。
1)在統計學中,歸一化的具體作用是歸納統一樣本的統計分佈性。歸一化在0~1之間是統計的機率分佈,歸一化在-1~ 1之間是統計的座標分佈。
2)奇異樣本資料是指相對於其他輸入樣本特別大或特別小的樣本向量(即特徵向量),譬如,下面為具有兩個特徵的樣本資料x1、x2、x3、x4、x5、x6(特徵向量—>列向量),其中x6這個樣本的兩個特徵相對其他樣本而言相差比較大,因此,x6認為是奇異樣本資料。
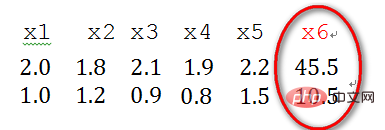
奇異樣本資料的存在會造成訓練時間增大,同時也可能導致無法收斂,因此,
當存在奇異樣本資料時,在進行訓練之前需要對預處理資料進行歸一化;反之,當不存在奇異樣本資料時,則可以不進行歸一化。
#-- 如果不進行歸一化,那麼由於特徵向量中不同特徵的取值相差較大,會導致目標函數變成「扁」。這樣
在進行梯度下降的時候,梯度的方向就會偏離最小值的方向,走很多彎路,也就是訓練時間過長。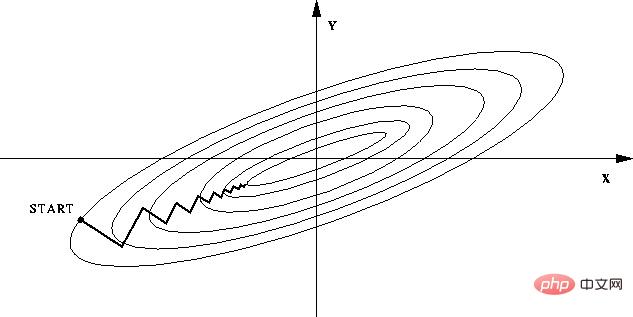
--如果進行歸一化以後,目標函數會呈現比較“圓”,這樣訓練速度大大加快,少走很多彎路。
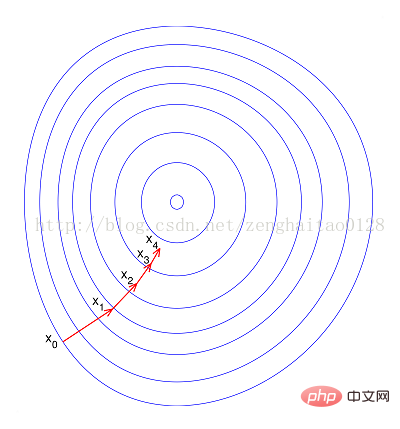
綜上可知,歸一化有以下好處,即
1)歸一化後加快了梯度下降求最優解的速度;
2)歸一化有可能提高精確度(如KNN)
###沒有一種資料標準化的方法,放在每一個問題,放在每一個模型,都能提高演算法精度和加速演算法的收斂速度。 ###############更多相關知識,請造訪###常見問題###欄位! ###
以上是資料歸一化處理的目的是什麼的詳細內容。更多資訊請關注PHP中文網其他相關文章!

























