

剛開始接觸Python,看很多人玩爬蟲我也想玩,找來找去發現很多人用網路爬蟲幹的第一件事就是模擬登陸,增加點難度就是模擬登陸後在獲取數據,但是網上好少有Python 3.x的模擬登陸Demo可以參考,加上自己也不怎麼懂Html,所以這第一個Python爬蟲寫的異常艱難,不過最終結果還是盡如人意的,下面把這次學習的過程整理一下。 #工具
系統:win7 64位元系統
查詢,輸入公共的帳號密碼進入,最後輸入相關資訊取得成績表格,這裡登陸不需要驗證碼省了我一番功夫,這樣我們先進入成績查詢系統登陸介面,先看看怎麼模擬登陸這個過程,在Chrome瀏覽器下按F12打開開發者面板:
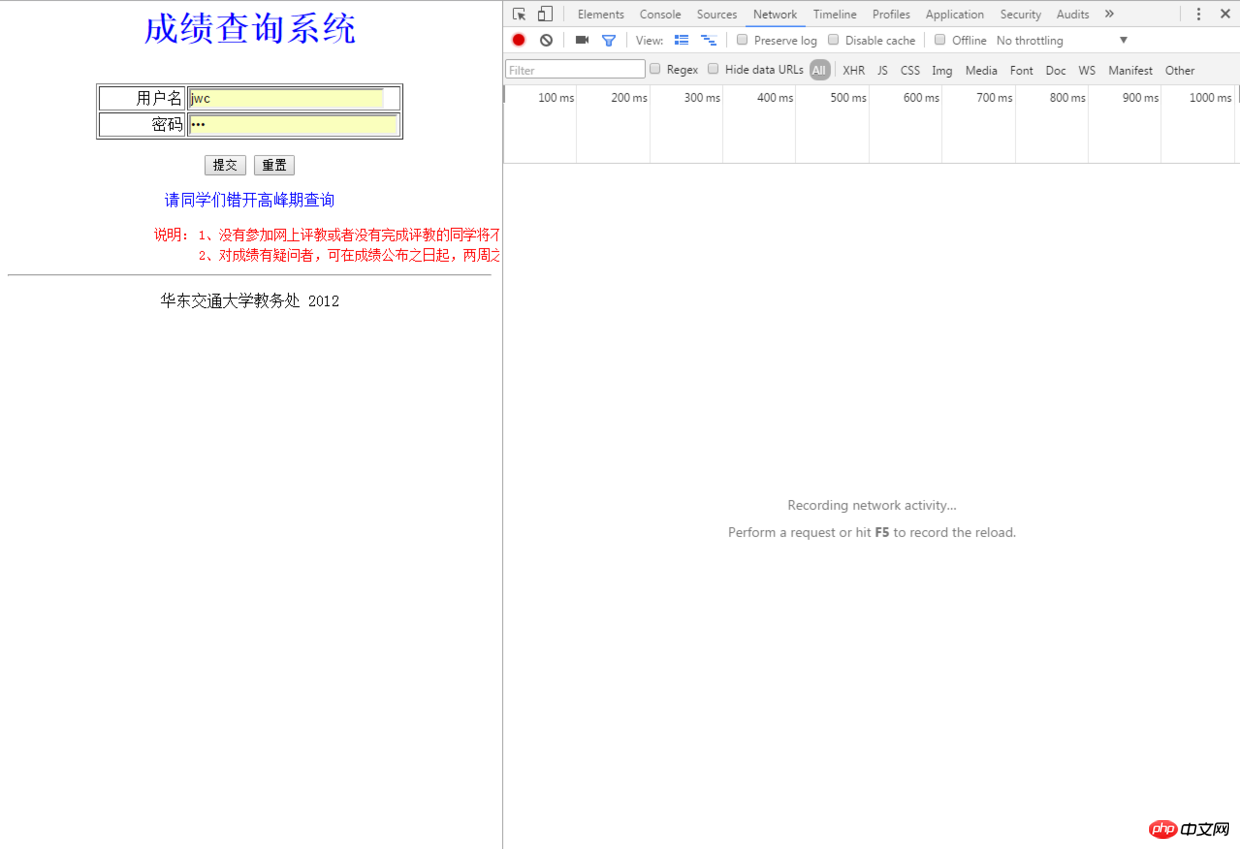 開發者面板
開發者面板
POST請求
: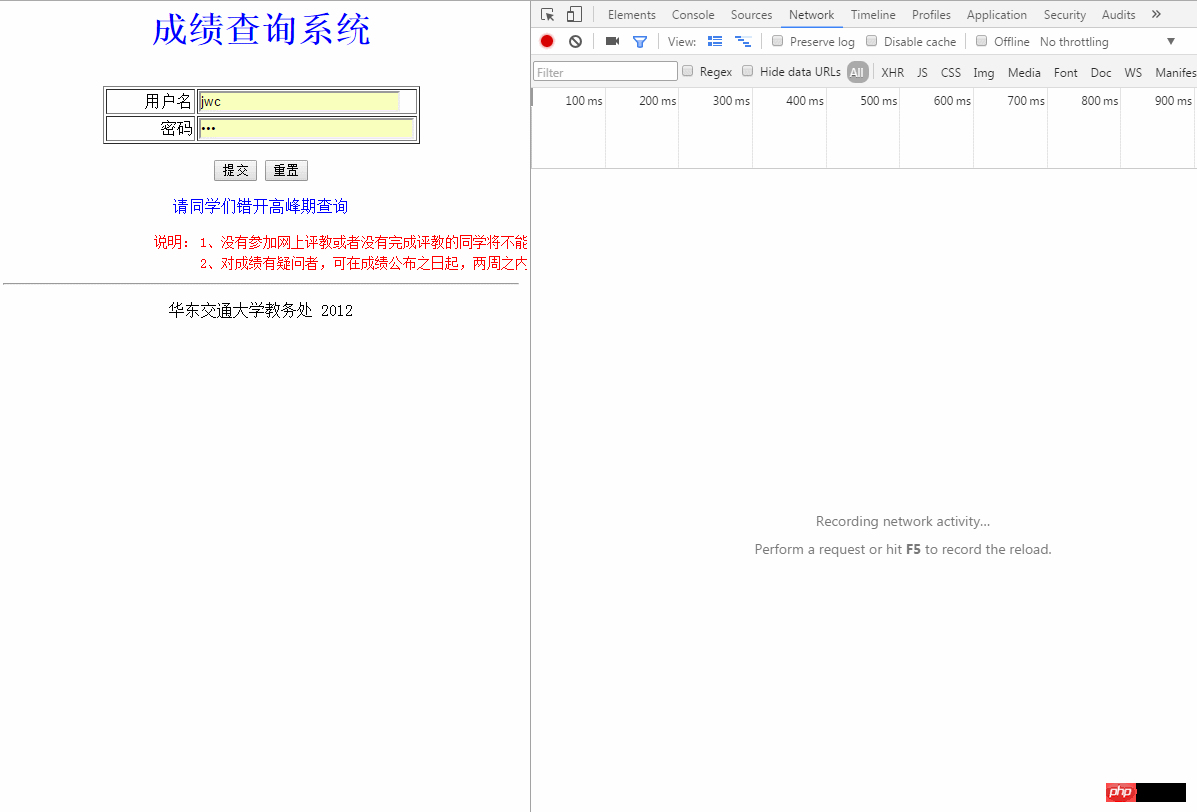 #注意post請求
#注意post請求
##發現了什麼,好像Chrome並沒有把Post提交的表單資訊保留下來直接跳到了另一個介面然後展示另一個介面的數據,這裡就需要我們自己動手操作一下,注意開發者面板左上角的小紅點表示這時候正在抓取數據,如果點擊一下就會變成灰色,就可以變相地保存下當時抓取到的包,我在點擊登陸後新界面未刷新出來之前點擊了這個小紅點,如願以償的得到了Post的表單數據:
得到post表單數據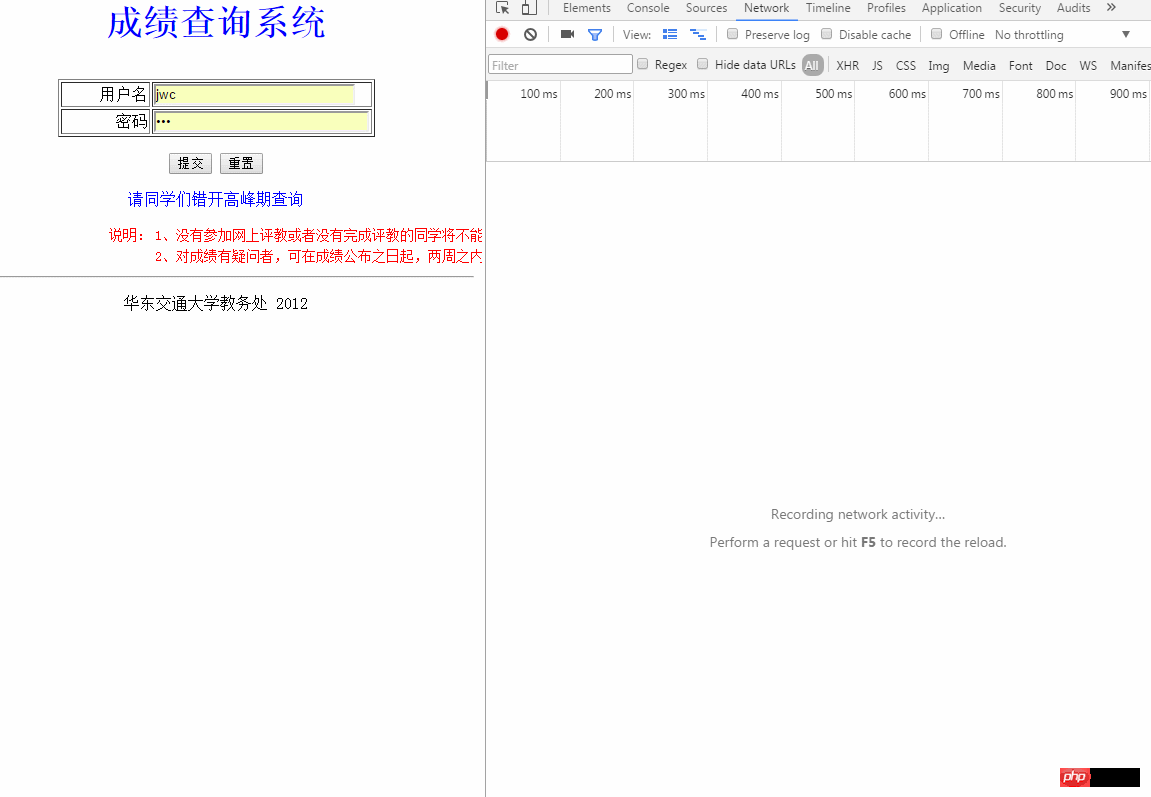
#這樣就獲取了瀏覽器在登陸時候向伺服器傳遞的表單數據,看一下這個表單都有些什麼:
檢視表單資料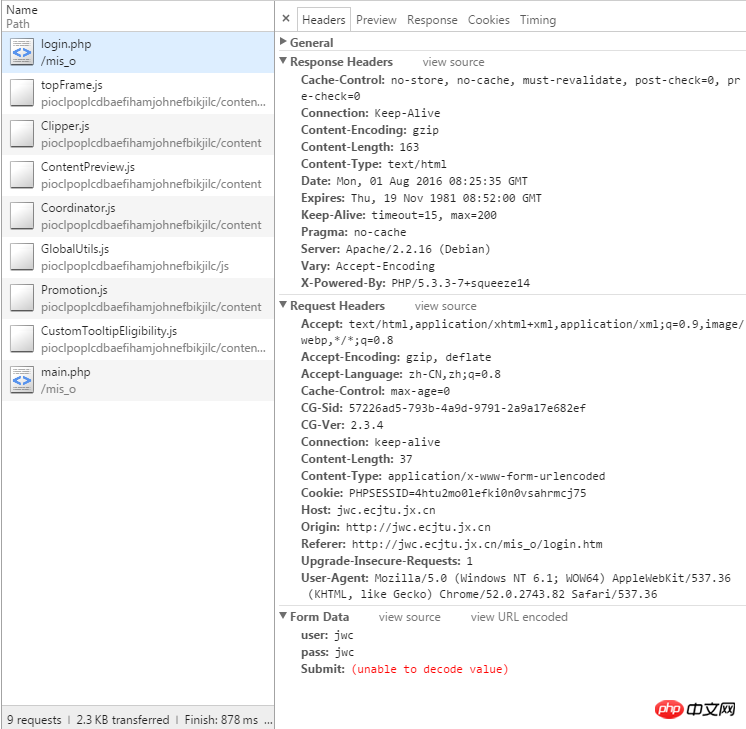
這裡看到我們需要傳遞三個參數,分別是:user、pass、Submit,可以很容易的理解這幾個單字的字面意思,這樣有了思路,我們就可以寫出這次代碼的第一步:
直接上代碼:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
url = 'http://jwc.ecjtu.jx.cn/mis_o/login.php'
datas = {'user': 'jwc',
'pass': 'jwc',
'Submit': '%CC%E1%BD%BB'
}
headers = {'Referer': 'http://jwc.ecjtu.jx.cn/mis_o/login.htm',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8',
}
sessions = requests.session()
response = sessions.post(url, headers=headers, data=datas)
print(response.status_code)程式碼輸出:說明我們模擬登陸成功了,這裡用到了Requests模組,還不會使用的可以查看中文文檔,它給自己的定義是:HTTP 200
登入後複製
Humans,因為簡單易用易上手,我們只需要傳入Url地址,構造請求頭,傳入post方法需要的數據,就可以模擬瀏覽器登陸了,這裡因為有進一步獲取成績的操作所以使用了session來保持連接,這裡單看最後的返回碼的話我們是成功了的,具體如何還要看下一步操作,接下來:
抓包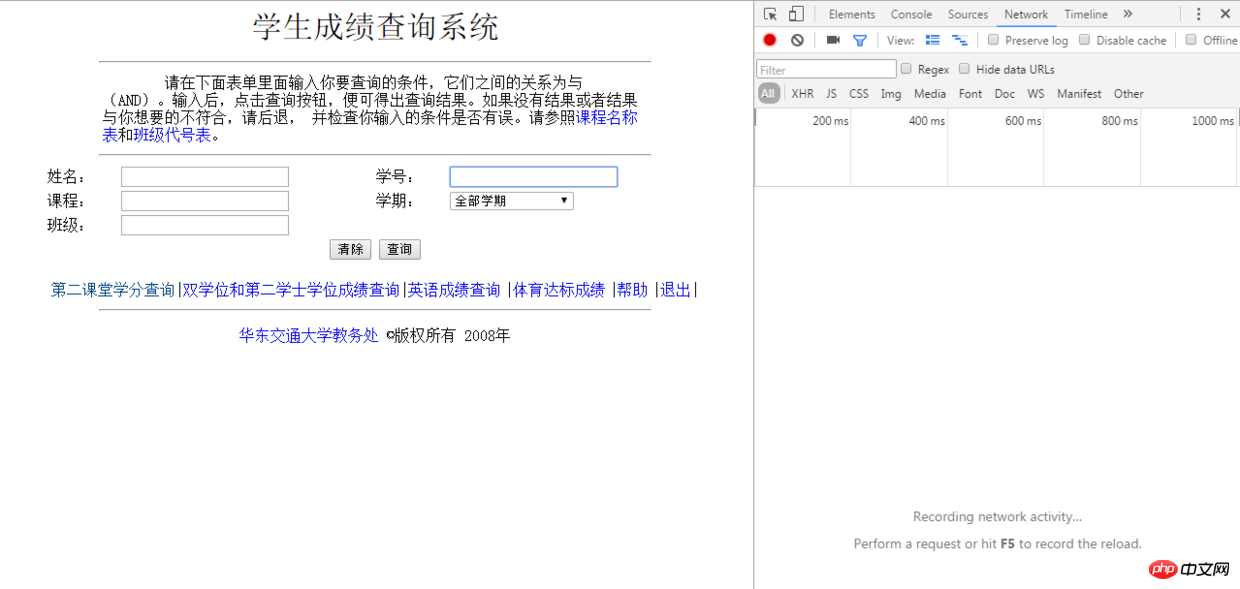
這裡為了簡單程式碼我們設定輸入學號查詢所有成績,減少其他判斷,同樣對Post資料進行抓包:
對post資料抓包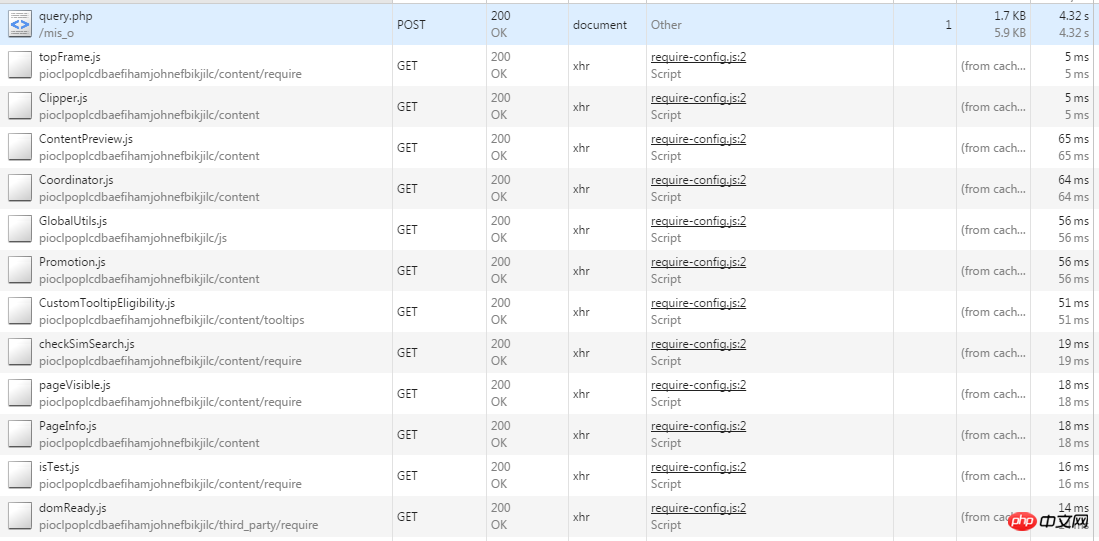
同樣查看Post的資料:
#查看post資料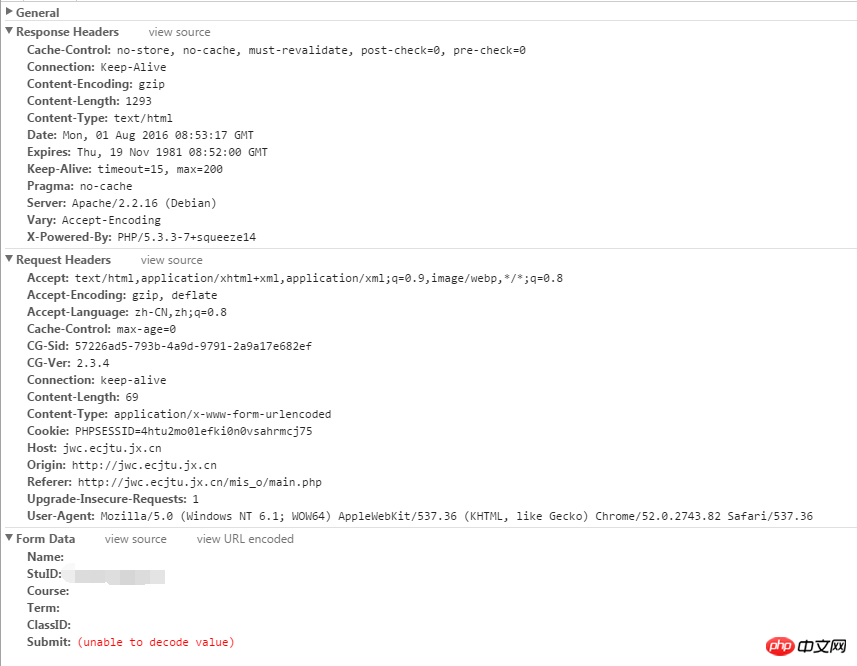 ##因為這裡就分析輸入學號的情況所以其他都為空,這樣我們就可以寫出查詢成績的程式碼:
##因為這裡就分析輸入學號的情況所以其他都為空,這樣我們就可以寫出查詢成績的程式碼:
score_healders = {'Connection': 'keep-alive',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Content - Type': 'application / x - www - form - urlencoded',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Content - Length': '69',
'Host': 'jwc.ecjtu.jx.cn',
'Referer': 'http: // jwc.ecjtu.jx.cn / mis_o / main.php',
'Upgrade - Insecure - Requests': '1',
'Accept - Language': 'zh - CN, zh;q = 0.8'
}
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(
pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
score_data = {'Name': '',
'StuID': num,
'Course': '',
'Term': '',
'ClassID': '',
'Submit': '%B2%E9%D1%AF'
}
score_response = sessions.post(score_url, data=score_data, headers=score_healders)
content = score_response.content这里解释一下上面的代码,上面的score_url 并不是浏览器上显示的地址,我们要获取真正的地址,在Chrome下右键--查看网页源代码,找到这么一行:
a href=query.php?start=1&job=see&=&Name=&Course=&ClassID=&Term=&StuID=xxxxxxx
这个才是真正的地址,点击这个地址转入的才是真正的界面,因为这里成绩数据较多,所以这里采用了分页显示,这个start=1说明是第一页,这个参数是可变的需要我们传入,还有StuID后面的是我们输入的学号,这样我们就可以拼接出Url地址:
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
同样使用Post方法传递数据并获取响应的内容:
score_response = sessions.post(score_url, data=score_data,headers=score_healders) content = score_response.content
这里采用Beautiful Soup 4.2.0来解析返回的响应内容,因为我们要获取的是成绩,这里到教务处成绩查询界面,查看获取到的成绩在网页中是以表格的形式存在:
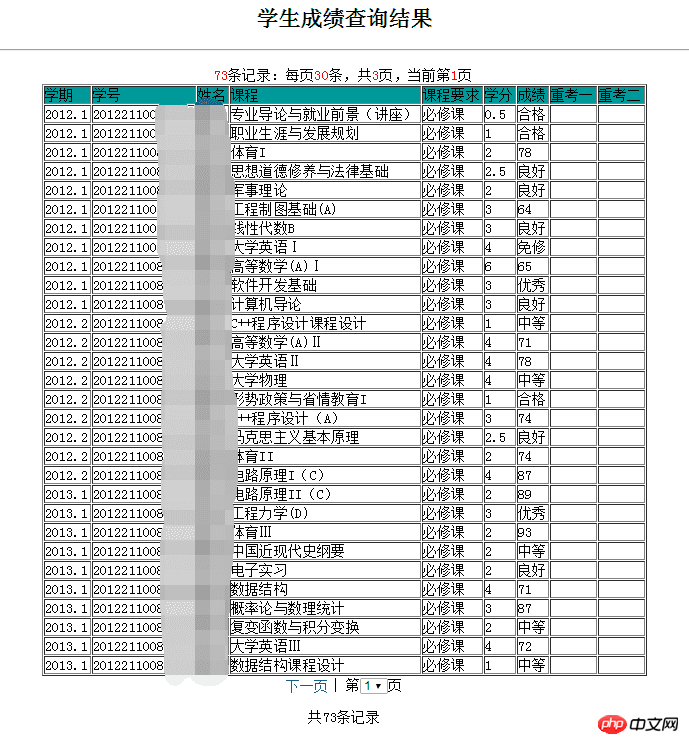
网页源代码
观察表格的网页源代码:
<table align=center border=1> <tr><td bgcolor=009999>学期</td> <td bgcolor=009999>学号</td> <td bgcolor=009999>姓名</td> <td bgcolor=009999>课程</td> <td bgcolor=009999>课程要求</td> <td bgcolor=009999>学分</td> <td bgcolor=009999>成绩</td> <td bgcolor=009999>重考一</td> <td bgcolor=009999>重考二</td></tr> ... ... </tr></table>
这里拿出第一行举例,虽然我不太懂Html但是从这里可以看出来<tr> 代表的是一行,而<td>应该是代表这一行中的每一列,这样就好办了,取出每一行然后分解出每一列,打印输出就可以得到我们要的结果:
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, 'html.parser')
# 找到每一行
target = soup.findAll('tr')这里分解每一列的时候要小心,因为这里表格分成了三页显示,每页最多显示30条数据,这里因为只是收集已经毕业的学生的成绩数据所以不对其他数据量不足的学生成绩的情况做统计,默认收集的都是大四毕业的学生成绩数据。这里采用两个变量i和j分别代表行和列:
# 注:这里的print单纯是我为了验证结果打印在PyCharm的控制台上而已
i=0, j=0
for tag in target[1:]:
tds = tag.findAll('td')
# 每一次都是从列头开始获取
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
i += 1这里查了很多别人的博客都是用正则表达式来分解数据,表示自己的正则写的并不好也尝试了但是没成功,所以无奈选择这种方式,如果有人有测试成功的正则欢迎跟我说一声,我也学习学习。
把数据保存到Excel
因为已经清楚了这个网页保存成绩的具体结构,所以顺着每次循环解析将数据不断加以保存就是了,这里使用xlwt写入数据到Excel,因为xlwt模块打印输出到Excel中的样式宽度偏小,影响观看,所以这里还加入了一个方法去控制打印到Excel表格中的样式:
file = xlwt.Workbook(encoding='utf-8')
table = file.add_sheet('achieve')
# 设置Excel样式
def set_style(name, height, bold=False):
style = xlwt.XFStyle() # 初始化样式
font = xlwt.Font() # 为样式创建字体
font.name = name # 'Times New Roman'
font.bold = bold
font.color_index = 4
font.height = height
style.font = font
return style运用到代码中:
for tag in target[1:]:
tds = tag.findAll('td')
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
table.write(i, j, semester, set_style('Arial', 220))
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
table.write(i, j, studentid, set_style('Arial', 220))
table.col(i).width = 256 * 16
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
table.write(i, j, name, set_style('Arial', 220))
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
table.write(i, j, course, set_style('Arial', 220))
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
table.write(i, j, requirments, set_style('Arial', 220))
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
table.write(i, j, scredit, set_style('Arial', 220))
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, achievement, set_style('Arial', 220))
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, reexaminef, set_style('Arial', 220))
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
table.write(i, j, reexamines, set_style('Arial', 220))
i += 1
file.save('demo.xls')最后稍加整合,写成一个方法:
# 获取成绩
# 这里num代表输入的学号,pagenum代表页数,总共76条数据,一页30条所以总共有三页
def getScore(num, pagenum, i, j):
score_healders = {'Connection': 'keep-alive',
'User - Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.82 Safari/537.36',
'Content - Type': 'application / x - www - form - urlencoded',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Content - Length': '69',
'Host': 'jwc.ecjtu.jx.cn',
'Referer': 'http: // jwc.ecjtu.jx.cn / mis_o / main.php',
'Upgrade - Insecure - Requests': '1',
'Accept - Language': 'zh - CN, zh;q = 0.8'
}
score_url = 'http://jwc.ecjtu.jx.cn/mis_o/query.php?start=' + str(
pagenum) + '&job=see&=&Name=&Course=&ClassID=&Term=&StuID=' + num
score_data = {'Name': '',
'StuID': num,
'Course': '',
'Term': '',
'ClassID': '',
'Submit': '%B2%E9%D1%AF'
}
score_response = sessions.post(score_url, data=score_data, headers=score_healders)
# 输出到文本
with open('text.txt', 'wb') as f:
f.write(score_response.content)
content = score_response.content
soup = BeautifulSoup(content, 'html.parser')
target = soup.findAll('tr')
try:
for tag in target[1:]:
tds = tag.findAll('td')
j = 0
# 学期
semester = str(tds[0].string)
if semester == 'None':
break
else:
print(semester.ljust(6) + '\t\t\t', end='')
table.write(i, j, semester, set_style('Arial', 220))
# 学号
studentid = tds[1].string
print(studentid.ljust(14) + '\t\t\t', end='')
j += 1
table.write(i, j, studentid, set_style('Arial', 220))
table.col(i).width = 256 * 16
# 姓名
name = tds[2].string
print(name.ljust(3) + '\t\t\t', end='')
j += 1
table.write(i, j, name, set_style('Arial', 220))
# 课程
course = tds[3].string
print(course.ljust(20, ' ') + '\t\t\t', end='')
j += 1
table.write(i, j, course, set_style('Arial', 220))
# 课程要求
requirments = tds[4].string
print(requirments.ljust(10, ' ') + '\t\t', end='')
j += 1
table.write(i, j, requirments, set_style('Arial', 220))
# 学分
scredit = tds[5].string
print(scredit.ljust(2, ' ') + '\t\t', end='')
j += 1
table.write(i, j, scredit, set_style('Arial', 220))
# 成绩
achievement = tds[6].string
print(achievement.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, achievement, set_style('Arial', 220))
# 重考一
reexaminef = tds[7].string
print(reexaminef.ljust(2) + '\t\t', end='')
j += 1
table.write(i, j, reexaminef, set_style('Arial', 220))
# 重考二
reexamines = tds[8].string
print(reexamines.ljust(2) + '\t\t')
j += 1
table.write(i, j, reexamines, set_style('Arial', 220))
i += 1
except:
print('出了一点小Bug')
file.save('demo.xls')在模拟登陆操作后增加一个判断:
# 判断是否登陆
def isLogin(num):
return_code = response.status_code
if return_code == 200:
if re.match(r"^\d{14}$", num):
print('请稍等')
else:
print('请输入正确的学号')
return True
else:
return False最后在main中这么调用:
if name == 'main':
num = input('请输入你的学号:')
if isLogin(num):
getScore(num, pagenum=0, i=0, j=0)
getScore(num, pagenum=1, i=31, j=0)
getScore(num, pagenum=2, i=62, j=0)在PyCharm下按alt+shift+x快捷键运行程序:

控制台输出
控制台会有如下输出(这里只截取部分,不要吐槽没有对齐,这里我也用了格式化输出还是不太行,不过最起码出来了结果,而且我们的目的是输出到Excel中不是吗)
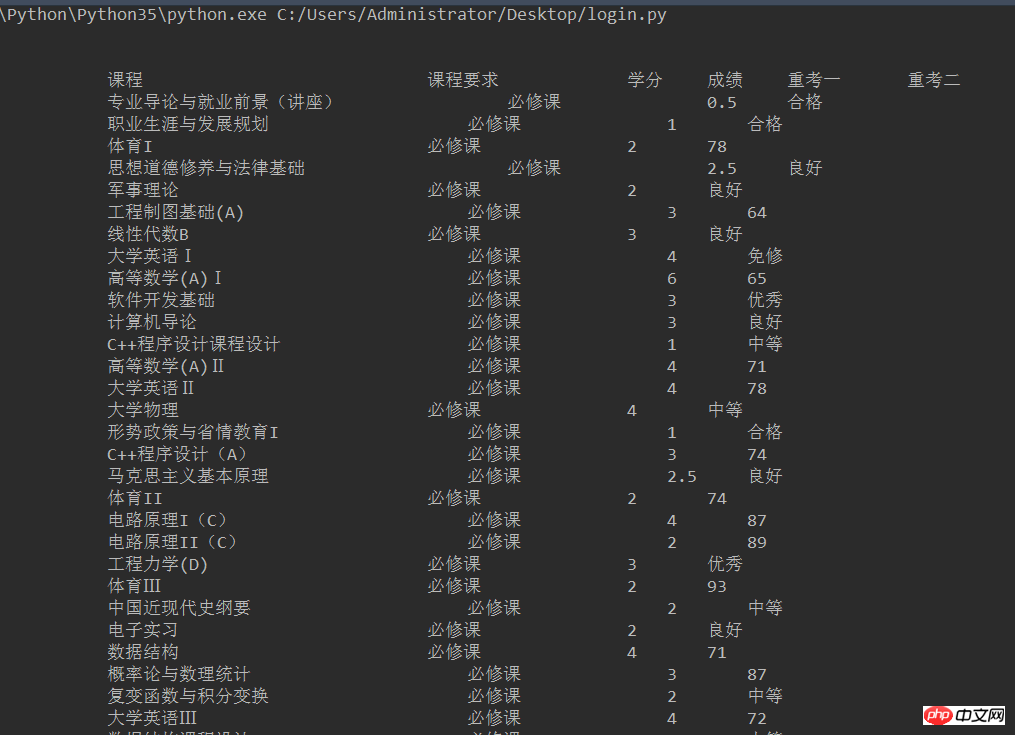
控制台输出
然后去程序根目录找看看有没有生成一个叫demo.xls的文件,我的程序就放在桌面,所以去桌面找:
桌面图标
点开查看是否成功获取:
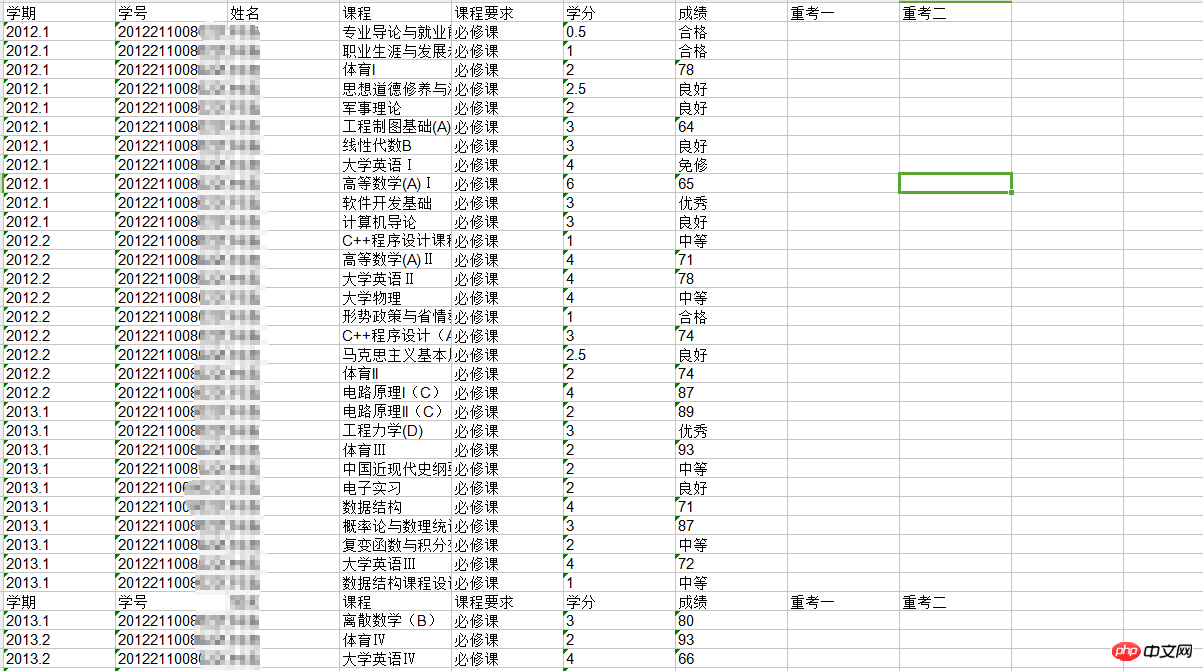
最终获取结果
至此,大功告成
以上是Python爬蟲模擬登陸教務處並且儲存資料到本地的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















