

在每個功能發布之前,我都會進行用戶驗收測試(“UAT”)以發現錯誤並確保業務邏輯正確轉換為代碼。
我只在 UAT 100% 成功後才清除發布功能。
我的推理很簡單:你只有一次機會給最終用戶留下良好的第一印象,而糟糕的發布會讓它加倍困難。

雖然這是一個 MVP 功能,並不適合生產發布,但我認為做一些 UAT 來保持我的技能新鮮會很好。
在我提出的 19 個 UAT 場景中,有一個因 託管人聲明 PDF 模板的更改而失敗。
我在 Discovery 期間就預見到了這種風險,但說實話,我沒想到這個問題會這麼快出現。
我將在本文後面詳細介紹錯誤修復細節。
我的 UAT 流程涉及使用業務邏輯或功能需求作為參考來建立測試場景和預期結果。
測試場景不需要很複雜。它們可以很簡單:「該功能會在 30 秒內產生 CSV 檔案」。
對於 UAT,我處理了來自 10 個託管人聲明 PDF 的 71 頁 文件。這應該是一個足夠大的樣本集。
預期輸出是三個CSV 文件,其中包含託管人聲明PDF 的基金持有、證券持有 和現金持有 部分的特定數據點。
我想出了以下測試案例:
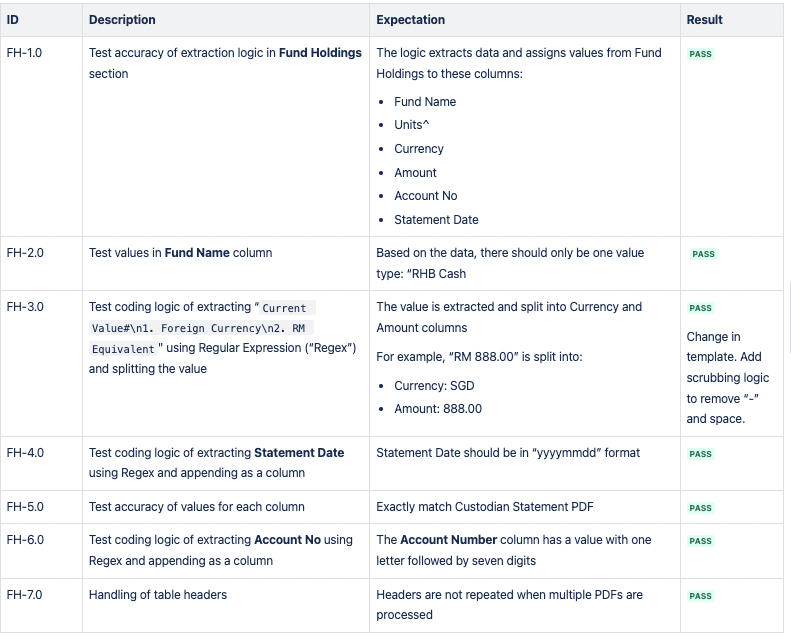
CSV 1:基金持有量
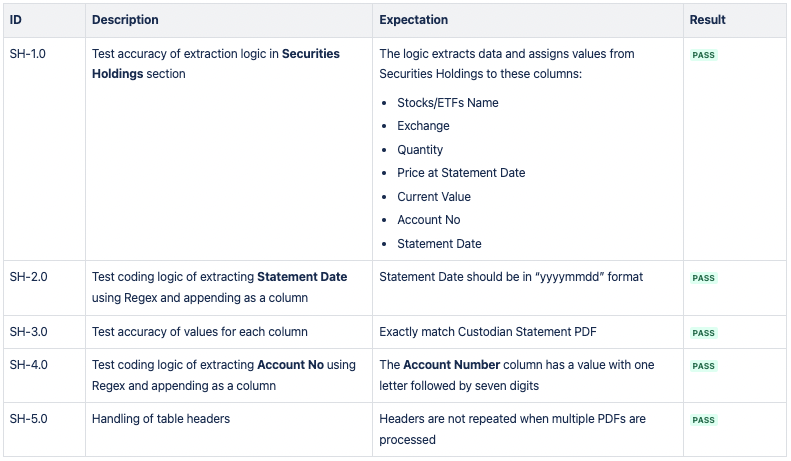
CSV 2:證券持有
CSV 3:現金持有

測試失敗是因為託管人聲明 PDF 的範本在 11 月發生了輕微變化。更具體地說,基金持有表的「當前值#1.外幣2.RM等值」欄位中的值現在有一個額外的「-n」前綴。
例如,先前的 PDF 中的值為“USD 10,000”,現在的值為“- USD10,000”。
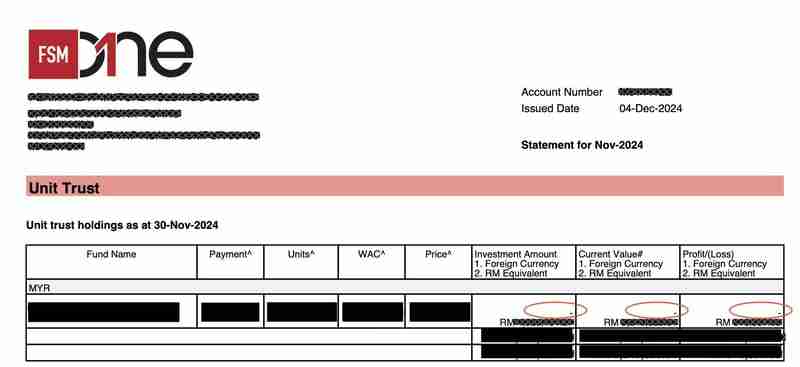
這個小變化導致了以下問題:

我諮詢了 ChatGPT 進行修復,它建議添加以下清理邏輯以刪除不正確的“-/n”前綴。
清理工作成功了,基金控股 CSV 輸出現在如預期般輸出。
我現在很滿意提取 PDF 資料的程式碼可以正常運作。也就是說,我認為 CSV 檔案不是儲存所有這些資料的最佳位置。
雖然 CSV 對我來說是用戶友好的,但將資料儲存在資料庫中可以更輕鬆地根據最終用戶的要求檢索和操作資料。
我在資料庫方面的經驗非常有限。因此,我接下來要做的是在資料庫應用程式上進行 Discovery,我可以快速上手。
--結束
以上是#|自動擷取 PDF 資料:使用者驗收測試的詳細內容。更多資訊請關注PHP中文網其他相關文章!





















