在剛結束的全球開發者大會上,蘋果宣布了 Apple intelligence, 這是一款深度整合於 iOS 18、iPadOS 18 和 macOS Sequoia 的全新個人化智慧系統。

蘋果+智慧由多種高度智慧的生成模型組成,這些模型專為使用者的日常任務設計。在蘋果剛更新的部落格中,他們詳細介紹了其中兩款模型。
一個擁有約30 億參數的設備端語言模型;
一個更大的基於伺服器的語言模型,該模型透過私有雲運算在蘋果伺服器上運行。
這兩個基礎模型是蘋果生成模型家族的一部分,蘋果表示,他們會在不久的將來分享更多關於這個模型家族的信息。
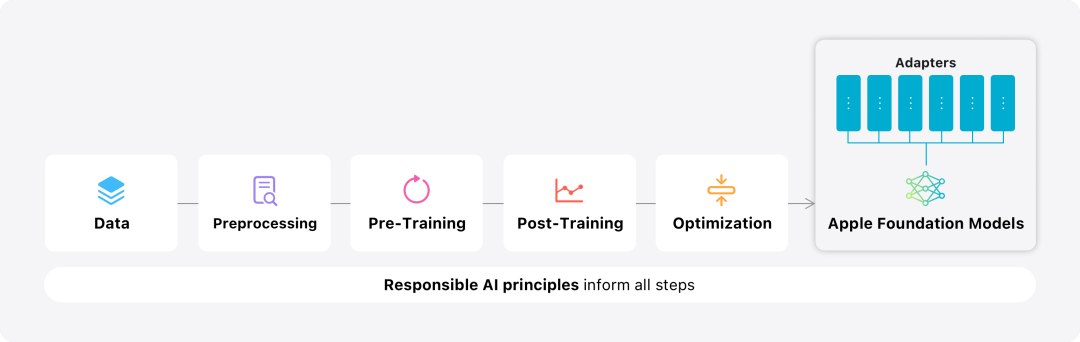
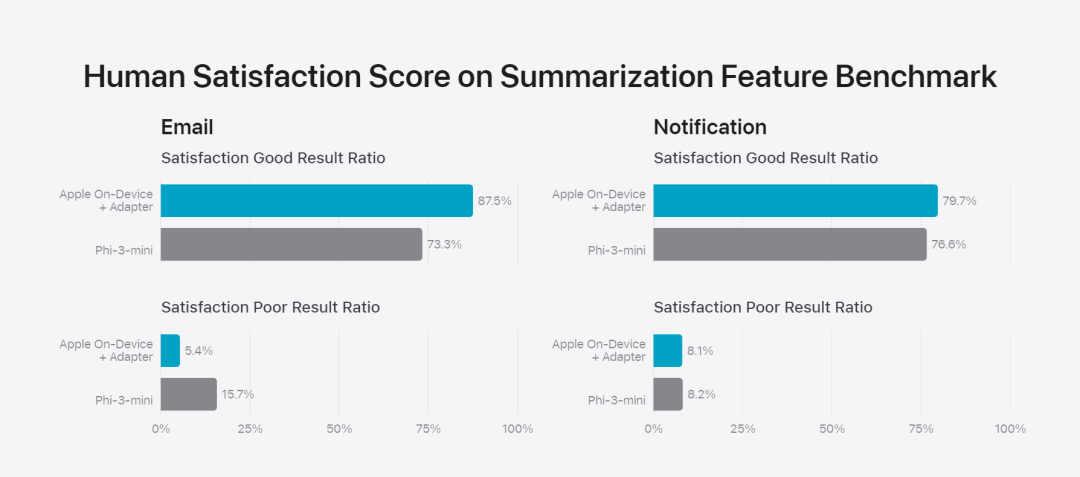
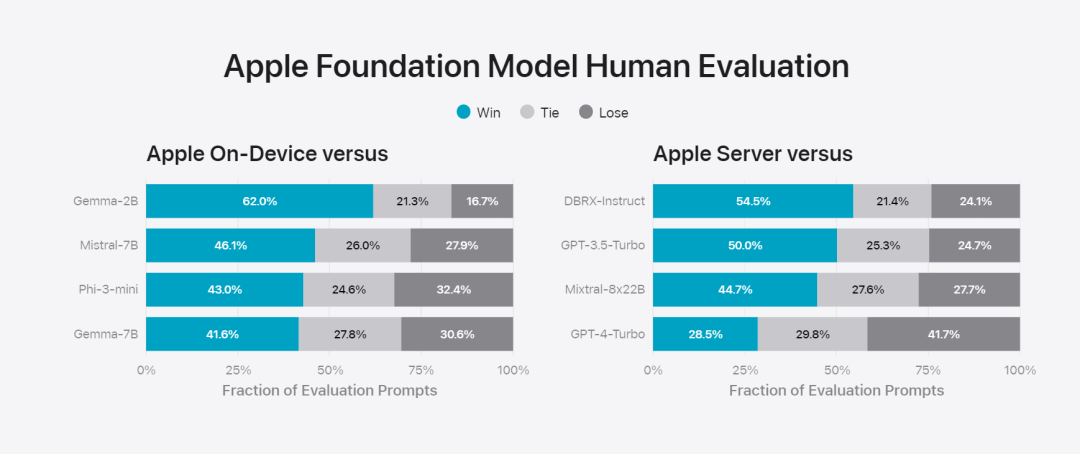
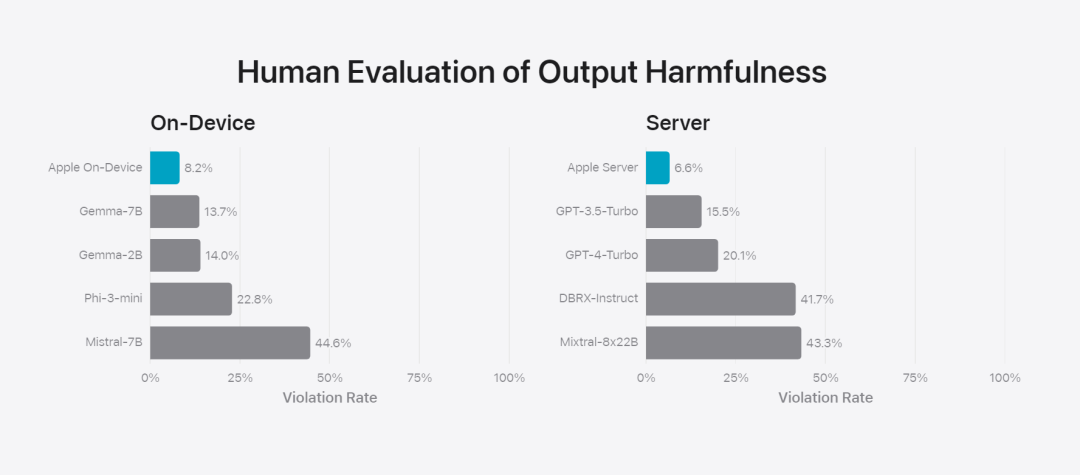
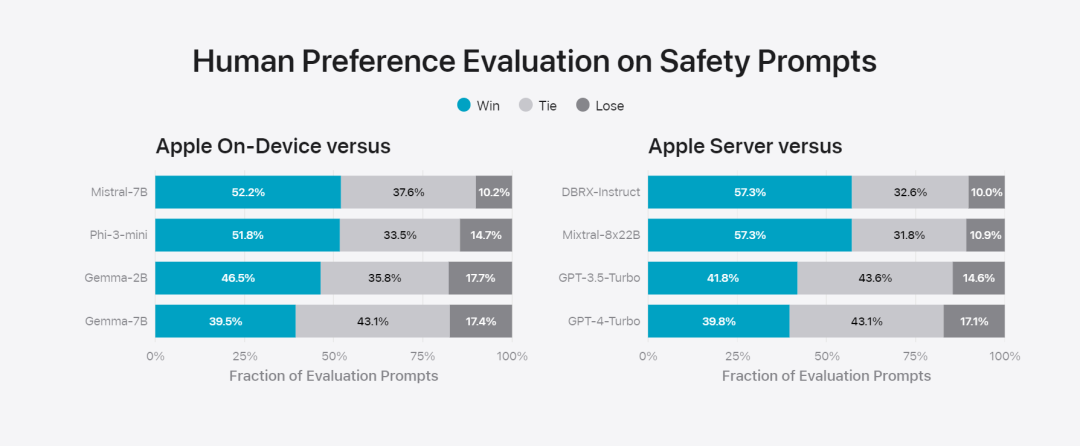
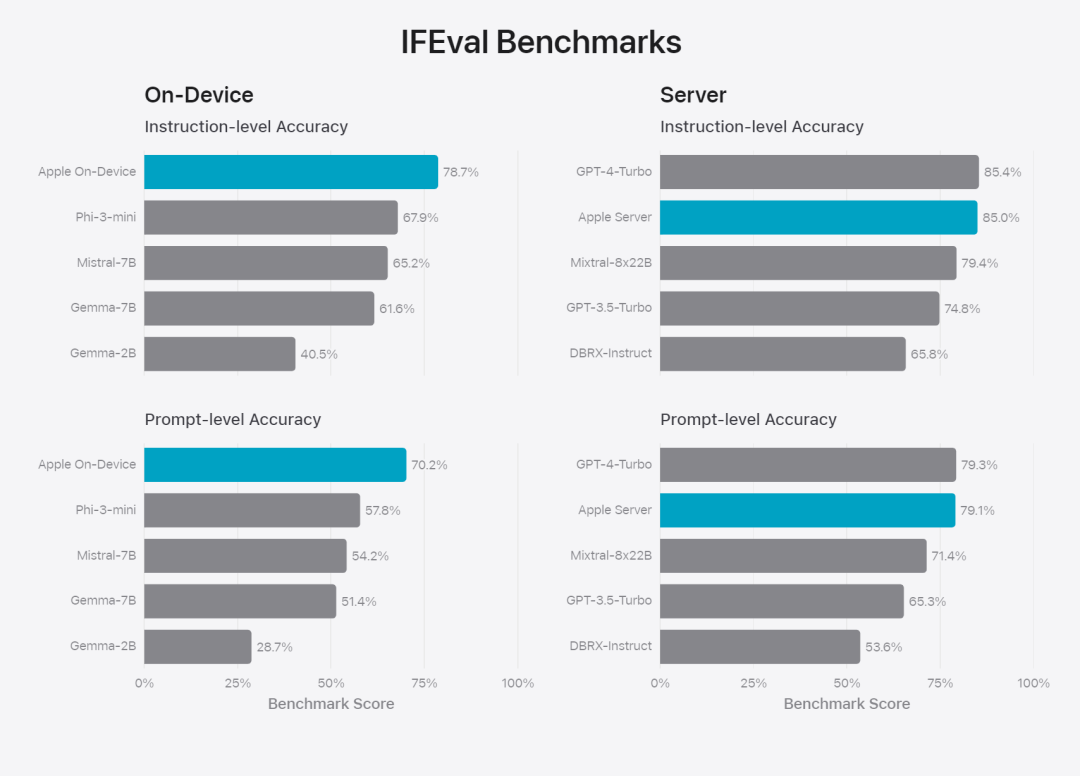
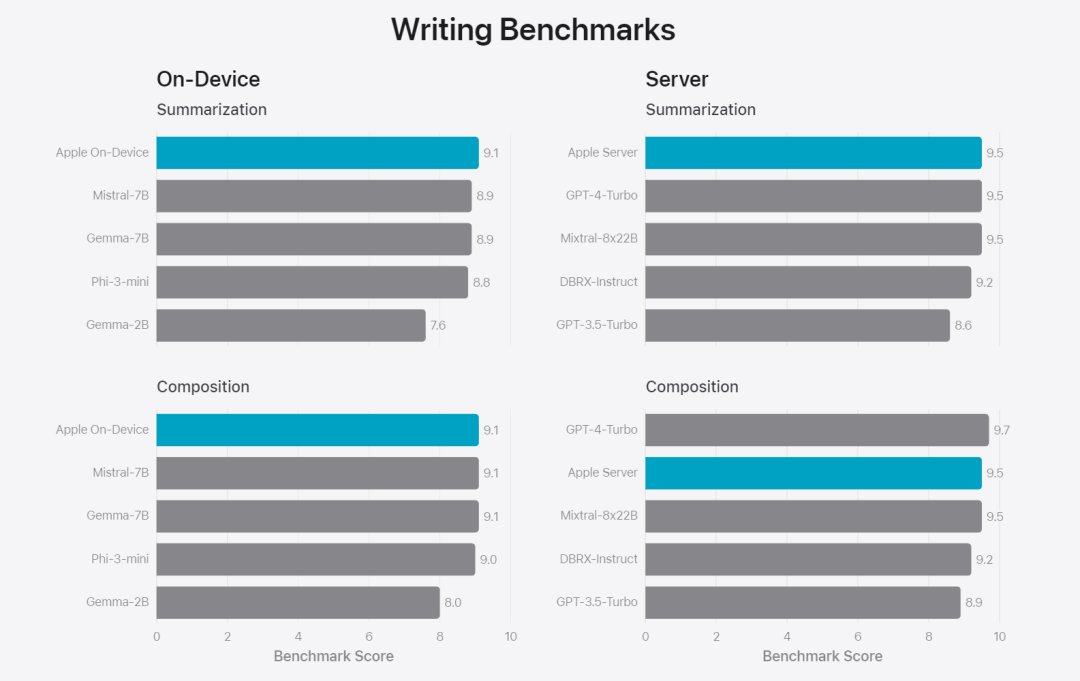
在這篇部落格中,蘋果用大量篇幅介紹了他們是如何開發高性能、快速且節能的模型;如何進行這些模型的訓練;如何為特定用戶需求微調適配器;以及如何評估模型在提供幫助和避免意外傷害方面的表現。 基礎模型是在AXLearn 框架上訓練而成的,這是蘋果在2023 年發布的一個開源專案。該框架建立在 JAX 和 XLA 之上,使得用戶能夠在各種硬體和雲端平台上高效且可擴展地訓練模型,包括 TPU 以及雲端和本地的 GPU。此外,蘋果使用資料並行、張量並行、序列並行和 FSDP 等技術,沿著多個維度(如資料、模型和序列長度)擴展訓練。 蘋果在訓練其基礎模型時,使用了經過授權的數據,這些數據包括為了增強某些特定功能而特別選擇的數據,以及由蘋果的網頁爬蟲AppleBot 從公開的網路上收集的資料。網頁內容的發佈者可以透過設定資料使用控制,選擇不讓他們的網頁內容用來訓練 Apple Intelligence。 蘋果在訓練基礎模型時,從不使用使用者的私人資料。為了保護隱私,他們會使用過濾器去除公開在網路上的個人可識別信息,例如信用卡號碼。此外,他們還會過濾掉粗俗語言和其他低品質的內容,以防這些內容進入訓練資料集。除了這些過濾措施之外,Apple 還會進行資料擷取和去重,並使用基於模型的分類器來識別並選擇高品質的文件進行訓練。 蘋果發現資料品質對模型至關重要,因此在訓練流程中採用了混合數據策略,即手動標註數據和合成數據,並進行全面的數據管理和過濾程序。蘋果在後訓練階段開發了兩種新演算法:(1) 帶有「teacher committee」的拒絕採樣微調演算法,(2) 使用帶有鏡像下降策略優化以及留一優勢估計器的從人類反饋中進行強化學習(RLHF)演算法。這兩種演算法顯著提高了模型的指令跟隨品質。 # 除了保證產生模型本身的高效能,Apple 也採用了多種創新技術,在裝置端和私有雲上對模型進行最佳化,以提升速度和效率。特別是,他們對模型在生成第一個 token(單個字元或詞語的基本單位)和後續 token 的推理過程都進行了大量優化,以確保模型的快速響應和高效運行。 蘋果在裝置端模型和伺服器模型中都採用了分組查詢注意力機制,以提高效率。為了減少記憶體需求和推理成本,他們使用了共享的輸入和輸出詞彙嵌入表,這些表在映射時沒有重複。設備端模型的詞彙量為 49,000,而伺服器模型的詞彙量為 100,000。 對於裝置端推理,蘋果使用了低位 palletization,這是一個關鍵的最佳化技術,能夠滿足必要的記憶體、功耗和效能要求。為了保持模型質量,蘋果還開發了一個新的框架,使用 LoRA 適配器,結合了混合的 2 位和 4 位配置策略 —— 平均每個權重 3.5 位 —— 以實現與未壓縮模型相同的準確率。 此外,蘋果還使用互動式模型延遲和功耗分析工具Talaria,以及激活量化和嵌入量化,並開發了一種在神經引擎上實現高效鍵值(KV) 快取更新的方法。 透過這一系列最佳化,在iPhone 15 Pro 上, 當模型接收到一個提示字時,從接收到這個提示字到產生第一個token 所需的時間約為0.6 毫秒,這個延遲時間非常短,表示模型在產生反應時非常快速產生速率為每秒30 個token。 蘋果將基礎模型針對用戶的日常活動進行了微調,並且可以動態地專門針對當前的任務。研究團隊利用適配器(可以插入預訓練模型各層的小型神經網路模組)來針對特定任務微調模型。具體來說,研究團隊調整了注意力矩陣、注意力投影矩陣和逐點(point-wise)前饋網路中的全連接層。 透過僅微調適配器層,預先訓練基礎模型的原始參數保持不變,保留模型的一般知識,同時自訂適配器層以支援特定任務。  圖 2:適配器是覆蓋在公共基礎模型上的模型權重的小型集合。它們可以動態載入和交換 —— 使基礎模型能夠動態地專門處理目前的任務。 Apple Intelligence 包括一組廣泛的適配器,每個適配器都針對特定功能進行了微調。這是擴展其基礎模型功能的有效方法。 研究團隊使用16 bit 來表徵適配器參數的值,對於約30 億參數的裝置模型,16 適配器的參數通常需要10 兆位元組。適配器模型可以動態載入、臨時快取在記憶體中以及交換。這使基礎模型能夠動態地專門處理當前的任務,同時有效地管理記憶體並保證作業系統的回應能力。 為了促進適配器的訓練,蘋果創建了一個高效的基礎設施,以在基本模型或訓練資料更新時快速重新訓練、測試和部署適配器。 #蘋果正在對模型進行基準測試時,專注於人類評估,因為人類評估的結果與產品的使用者體驗高度相關。 為了評估特定於產品的摘要功能,研究團隊使用了針對每個用例仔細採樣的一組 750 個回應。評估資料集強調產品功能在生產中可能面臨的各種輸入,並包括不同內容類型和長度的單一文件和堆疊文件的分層混合。實驗結果發現有適配器的模型能夠比類似模型產生更好的摘要。 作為負責任開發的一部分,蘋果識別並評估了摘要固有的特定風險。例如,摘要有時會刪除重要的細微差別或其他細節。然而,研究團隊發現摘要適配器沒有放大超過 99% 的目標對抗樣本中的敏感內容。 除了評估基礎模型和適配器支援的特定功能之外,研究團隊還評估了設備上模型和基於伺服器的模型的一般功能。具體來說,研究團隊採用一組全面的現實世界prompt 來測試模型功能,涵蓋了腦力激盪、分類、封閉式問答、編碼、提取、數學推理、開放式問答、重寫、安全、總結和寫作等任務。 研究團隊將模型與開源模型(Phi-3、Gemma、Mistral、DBRX)和規模相當的商業模型(GPT-3.5-Turbo、GPT-4- Turbo)進行比較。結果發現,與大多數同類競爭模型相比,蘋果的模型更受人類評估者青睞。例如,蘋果的裝置上模型具有約3B 參數,其效能優於較大的模型,包括Phi-3-mini、Mistral-7B 和Gemma-7B;伺服器模型與DBRX-Instruct、Mixtral-8x22B 和GPT-3.5 -Turbo 相比毫不遜色,同時效率很高。 研究團隊也使用一組不同的對抗性prompt 來測試模型在有害內容、敏感主題和事實方面的性能,測量了人類評估者評估的模型違規率,數字越低越好。面對對抗性 prompt,設備上模型和伺服器模型都很強大,其違規率低於開源和商業模型。 圖 5中不良內容、敏感度主體與事實性的違規反應比例上(低越越好)。當面對對抗性 prompt 時,蘋果的模型非常穩健。 考慮到大型語言模型的廣泛功能,蘋果正在積極與內部和外部團隊進行手動和自動紅隊合作,以進一步評估模型的安全性。 圖 6:在安全 prompt 方面,蘋果基礎模型與同類模型的平行評估中首選反應的比例。人類評估者發現蘋果基礎模型的反應更安全、更有幫助。 為了進一步評估模型,研究團隊使用指令追蹤評估 (IFEval) 基準來將其指令追蹤能力與同等大小的模型進行比較。結果表明,設備上模型和伺服器模型都比同等規模的開源模型和商業模型更好地遵循詳細指令。 圖 7中:蘋果基礎模型與類似尺寸模型的追蹤能力時(使用 IFEval 基準)。 最後,我們來看看蘋果在 Apple Intelligence 背後技術的介紹影片。
圖 2:適配器是覆蓋在公共基礎模型上的模型權重的小型集合。它們可以動態載入和交換 —— 使基礎模型能夠動態地專門處理目前的任務。 Apple Intelligence 包括一組廣泛的適配器,每個適配器都針對特定功能進行了微調。這是擴展其基礎模型功能的有效方法。 研究團隊使用16 bit 來表徵適配器參數的值,對於約30 億參數的裝置模型,16 適配器的參數通常需要10 兆位元組。適配器模型可以動態載入、臨時快取在記憶體中以及交換。這使基礎模型能夠動態地專門處理當前的任務,同時有效地管理記憶體並保證作業系統的回應能力。 為了促進適配器的訓練,蘋果創建了一個高效的基礎設施,以在基本模型或訓練資料更新時快速重新訓練、測試和部署適配器。 #蘋果正在對模型進行基準測試時,專注於人類評估,因為人類評估的結果與產品的使用者體驗高度相關。 為了評估特定於產品的摘要功能,研究團隊使用了針對每個用例仔細採樣的一組 750 個回應。評估資料集強調產品功能在生產中可能面臨的各種輸入,並包括不同內容類型和長度的單一文件和堆疊文件的分層混合。實驗結果發現有適配器的模型能夠比類似模型產生更好的摘要。 作為負責任開發的一部分,蘋果識別並評估了摘要固有的特定風險。例如,摘要有時會刪除重要的細微差別或其他細節。然而,研究團隊發現摘要適配器沒有放大超過 99% 的目標對抗樣本中的敏感內容。 除了評估基礎模型和適配器支援的特定功能之外,研究團隊還評估了設備上模型和基於伺服器的模型的一般功能。具體來說,研究團隊採用一組全面的現實世界prompt 來測試模型功能,涵蓋了腦力激盪、分類、封閉式問答、編碼、提取、數學推理、開放式問答、重寫、安全、總結和寫作等任務。 研究團隊將模型與開源模型(Phi-3、Gemma、Mistral、DBRX)和規模相當的商業模型(GPT-3.5-Turbo、GPT-4- Turbo)進行比較。結果發現,與大多數同類競爭模型相比,蘋果的模型更受人類評估者青睞。例如,蘋果的裝置上模型具有約3B 參數,其效能優於較大的模型,包括Phi-3-mini、Mistral-7B 和Gemma-7B;伺服器模型與DBRX-Instruct、Mixtral-8x22B 和GPT-3.5 -Turbo 相比毫不遜色,同時效率很高。 研究團隊也使用一組不同的對抗性prompt 來測試模型在有害內容、敏感主題和事實方面的性能,測量了人類評估者評估的模型違規率,數字越低越好。面對對抗性 prompt,設備上模型和伺服器模型都很強大,其違規率低於開源和商業模型。 圖 5中不良內容、敏感度主體與事實性的違規反應比例上(低越越好)。當面對對抗性 prompt 時,蘋果的模型非常穩健。 考慮到大型語言模型的廣泛功能,蘋果正在積極與內部和外部團隊進行手動和自動紅隊合作,以進一步評估模型的安全性。 圖 6:在安全 prompt 方面,蘋果基礎模型與同類模型的平行評估中首選反應的比例。人類評估者發現蘋果基礎模型的反應更安全、更有幫助。 為了進一步評估模型,研究團隊使用指令追蹤評估 (IFEval) 基準來將其指令追蹤能力與同等大小的模型進行比較。結果表明,設備上模型和伺服器模型都比同等規模的開源模型和商業模型更好地遵循詳細指令。 圖 7中:蘋果基礎模型與類似尺寸模型的追蹤能力時(使用 IFEval 基準)。 最後,我們來看看蘋果在 Apple Intelligence 背後技術的介紹影片。
以上是蘋果智慧背後模型發表:3B模型優於Gemma-7B,伺服器模型媲美GPT-3.5-Turbo的詳細內容。更多資訊請關注PHP中文網其他相關文章!























 0
0 1
1 338
338













