

这段代码一直出现异常,但只要把导入的库稍加更改在python2.x中运行是没有问题的,请问大神问题出在哪?
出现的异常也总变,小弟初学爬虫,请赐教!
import urllib.error
import urllib.request
import urllib.parse
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=https://www.baidu.com/link HTTP/1.1'
data = {}
data['type']= 'AUTO'
data['i'] = 'I am fine !'
data['doctype'] = 'json'
data['xmlVersion'] = '1.8'
data['keyfrom'] = 'fanyi.web'
data['ue'] = 'UTF-8'
data['action'] = 'FY_BY_CLICKBUTTON'
data['typoResult'] = 'true'
head = {}
head['User-Agent']= 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0'
try:
data = urllib.parse.urlencode(data).encode('utf-8')
req = urllib.request.Request(url,data,head)
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
print(html)
except urllib.error.HTTPError as e:
print ('Error code : ',e.code)
except urllib.error.URLError as e:
print ('The reason: ',e.reason)昨天是这样的: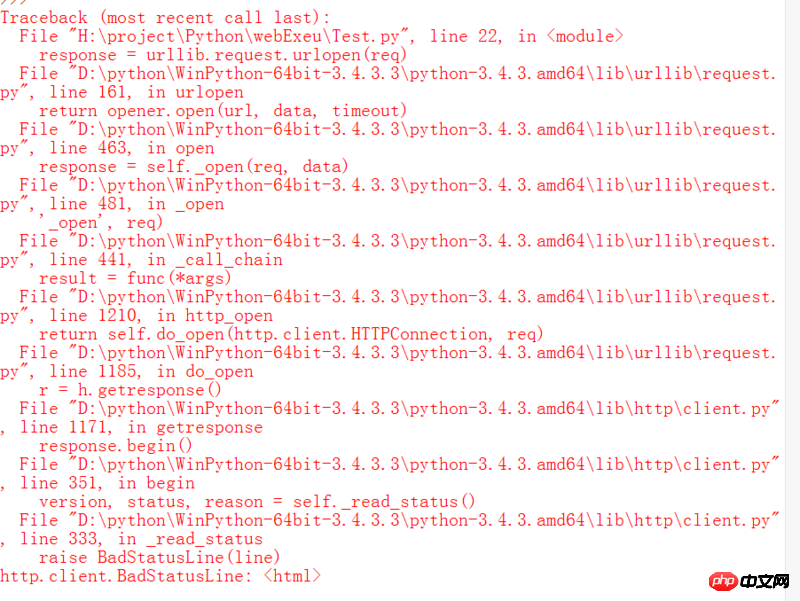
今天运行就这样了:















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Delete HTTP/1.1 after the url, why add it after the url? .
Python3 does not require decoding and encoding, and the usage of some modules is different. Take a look at the Python3 documentation yourself