

代码
'{"code":"A00185","data":"\\u5bf9\\u4e0d\\u8d77\\uff0c\\u60a8\\u77ed\\u65f6\\u95f4\\u53d1\\u8868\\u535a\\u6587\\u8fc7\\u591a\\uff0c\\u8bf7\\u591a\\u4f11\\u606f\\uff0c\\u6ce8\\u610f\\u8eab\\u4f53\\uff01\\u611f\\u8c22\\u60a8\\u5bf9\\u65b0\\u6d6a\\u535a\\u5ba2\\u7684\\u652f\\u6301\\u548c\\u5173\\u6ce8\\uff01"}'用正则不行,用replace不行,应该是\是属于转义符,不过因为访问的源码中,想把这个替换一下,要怎么处理!?
问题补充:
我是想把\\替换成\ 请问要怎么处理?
错如如下!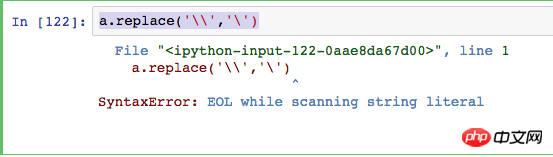
楼下一楼的大哥一直答不对题,我也是比较郁闷.我就想把一个字符串
\\的替换成\
然后想要如下结果:

其他的原理什么的其实我一点也不关心,最好是用一行代码就能回答问题的,万分感谢!















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




In the case of transferred characters,
\=.The original poster said no, so I tested it specifically.
The result is
I saw the code snippet in the poster’s new post, and after updating it, the poster turned red without seeing the code prompt?
This sentence is originally written incorrectly because
'转义将一个右引号转义了之后,第二个字符串就不完整了,当然会报错。另外,按照题主的要求,本来就不需要替换,因为这个字符串本来就是一个
,在定义字符串的时候,写两个\,才等于真正的一个.Can be verified with the following code:
Output results
After several negotiations, I finally found out the purpose of the question, which is to parse out the Chinese in json. . .
It’s very simple
Output