

根据网页所给的字符编码将其字节数据decode('gb2312')
用的是scrapy,从给出的url获取body
def parse(self, response):
body = response.body.decode('gb2312')
print(body)
学分:1.5 # body就是这样之类的,中间的冒号是中文的冒号
# 想弄成的效果就是['学分','1.5']
body = body.split(':') # 就这样使用中文的冒号符来分割,但是出错
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
请问怎么解决?















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Look at the above error again, it is
byte 0xa3So I tried it several times on the terminal and found that the colon gb2312 encode
So it should be that python uses the default utf-8 to decode the body of gb2312, so one way I can think of is to modify the default encoding value, which is the statement in the first line:
# -*- coding: gb2312 -*-Then the operation was successful. Is there anything else? method?
Python3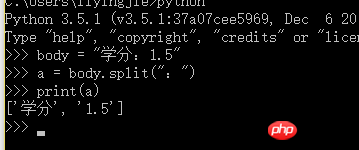
After decoding, the body should be unicode encoded, use the following method:
Another encoding issue, you can refer to: Character Encoding for Human-Computer Interaction and Defeating Python Character Encoding in Five Minutes.