现有问题如下表格:
怎么快速统计到匹配的结果有多少条记录呢?
问题描述:因为分页的原因,我要知道总记录条数,统计的方式为常规方式,直接count后面加条件统计的。相关索引也已经加上。带入查询条件后,上面有查询条件,相关数值会发生变化,数据表格中的类容也会发生变化。后来发现,如果数据量比较大,查询的很多时间都浪费在查询总记录数上,因为加了相关索引,即使是查询数据,也会只显示固定的10条或者20条,时间不会太久,数据库使用的是MySql数据库,请问各位有没有遇到类似的问题,怎么快速统计到匹配的结果有多少条记录呢?
我看了这个,但是这个不能添加查询条件吧 http://www.jb51.net/article/60753.htm

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




The idea is to avoid actually retrieving the entire table (only get results from the index, index-only scan)
First of all, how to write count?
count(*)andcount(列)are differentCreate appropriate indexes and force index use if necessary (select count() FORCE INDEX)
For details, see http://dev.mysql.com/doc/refman/5.7/en/how-to-avoid-table-scan.html
If conditions are used to count the total number of rows, it will be very slow.
There seems to be no good solution. If the data does not change frequently, you can use caching
I once struggled with the need to count the total number of rows for paging
The solution is stupid and funny
Because there are not many filtering conditions
So I added a trigger to this table and created a table specifically to count the total number of rows
Add, update and delete the table will be triggered. After analyzing the conditions, the corresponding fields of the statistical table will be accumulated directly
When querying, you can directly read the corresponding fields in the statistical table. The accuracy is no problem, but the performance has not been tested
However, there seems to be no slow query after the table has more than 100,000 data
1. You are right. The method in the reference URL you gave does not work for conditional queries.
2. This typical application does need to use the same condition count once, and then fetch the corresponding data according to paging. You're doing the right thing.
3. You have added related indexes, but it will still be slow when the amount of data is large---your index may not be working. The question that needs to be explored is why your index is not working, or how to optimize your SQL.
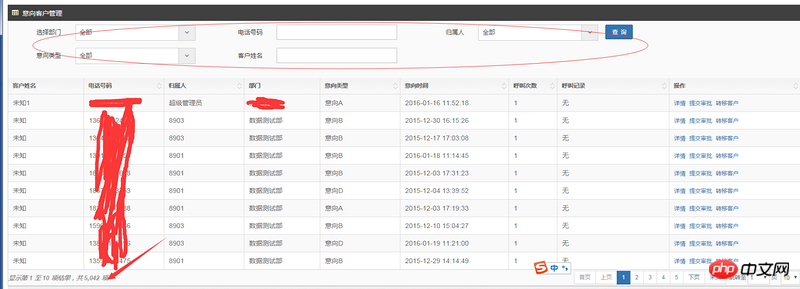
3.1 Your conditions are 5. Department, owner, and intention type should be precise queries with a single value (in theory, multiple selections are more user-friendly); phone numbers and customer names should be fuzzy queries with a single value. And all conditions may be blank. Blank or unchecked theoretically means "all". Therefore, your SQL formation process may be as follows (pseudocode):
It can be seen that SQL is more complex, and if it is a fuzzy query, it is generally not possible to optimize the use of indexes (except in special cases).
If a combined index is created for the three precise query fields, the use effect will also be affected by the field order restrictions of the combined index.
So, your index may not be working. . . You can check the query plan, which should be available in general databases.
See whether an index is used (under different conditions) or a full table scan.
Conclusion: Your index is not working, so the speed is still slow even with large amounts of data
3.2 How big is your data volume? How slow is it?
3.3 The laziest and most effective way to deal with performance problems: add hardware.
3.4 Actually there is no more. What development needs to do is to clarify the content in 3.2. Find another DBA to check. How much data is in what environment, and how much concurrency and IO can be accommodated is a very complicated matter. You can use hardware or set up multiple servers for master-slave/load balancing/read-write separation, etc. (many high-level terms) . If you know more, you can post more data.
3.5 The WEB system can improve response and reduce the load on DB through caching.
The above is for reference.