

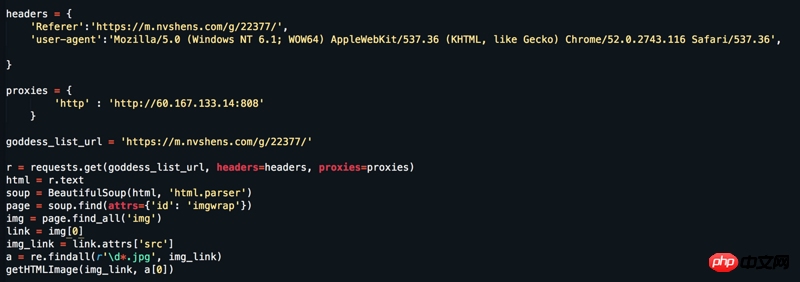
Website: https://www.nvshens.com/g/22377/. Open the website directly in the browser and right-click on the image to download it. Then the image directly requested by my crawler has been blocked. Then I changed the headers and set up the IP proxy, but it still didn't work. But looking at the packet capture, it’s not dynamically loaded data! ! ! Please answer = =















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




The girl is quite pretty.

It can indeed be opened by right-clicking, but after refreshing, it becomes a hotlinked picture. Generally, to prevent hotlinking, the server will check the
Refererfield in the request header, which is why it is not the original image after refreshing (theRefererhas changed after refreshing).Did you miss any parameters by capturing the packet when getting the picture?
I was just looking at the content of the website and almost forgot about it being official.
You can follow all the information you requested
Then try it
Referer According to the design of this website, each page should be more in line with the behavior of pretending to be a human being, instead of using a single Referer
The following is the complete code that can be run to capture all the pictures on page 18