python - Use scrapy framework to crawl Baidu pictures and get blocked
给我你的怀抱2017-05-24 11:34:48
0
3
731
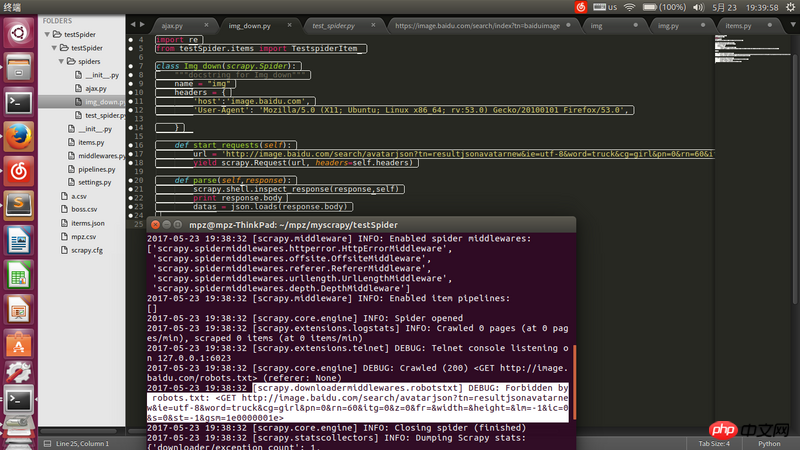
The request address url is the address of json obtained through firefox. It can be opened with a browser, but it was banned when crawling with scrapy. Please solve it.
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Try it at
settings.py将ROBOTSTXT_OBEY = False.Try without adding hearingers
I agree with the upstairs, if there will still be a wall. The method of scrapy+selenium+phantomjs can be used.