

Course 2672
Course Introduction:Golang has an in-depth understanding of the GPM scheduler model and full scenario analysis. I hope you will gain something from watching this video; it includes the origin and analysis of the scheduler, an introduction to the GMP model, and a summary of 11 scenarios.

Course 5963
Course Introduction:The flex property is used to set or retrieve how the child elements of the flex box model object allocate space. It is the shorthand property for the flex-grow, flex-shrink and flex-basis properties. Note: The flex property has no effect if the element is not a child of the flexbox model object.

Course 2857
Course Introduction:Course introduction: 1. Cross-domain processing, token management, route interception; 2. Real interface debugging, API layer encapsulation; 3. Secondary encapsulation of Echarts and paging components; 4. Vue packaging optimization and answers to common problems.

Course 1795
Course Introduction:Apipost is an API R&D collaboration platform that integrates API design, API debugging, API documentation, and automated testing. It supports grpc, http, websocket, socketio, and socketjs type interface debugging, and supports privatized deployment. Before formally learning ApiPost, you must understand some related concepts, development models, and professional terminology. Apipost official website: https://www.apipost.cn

Course 5521
Course Introduction:(Consult WeChat: phpcn01) The comprehensive practical course aims to consolidate the learning results of the first two stages, achieve flexible application of front-end and PHP core knowledge points, complete your own projects through practical training, and provide guidance on online implementation. Comprehensive practical key practical courses include: social e-commerce system backend development, product management, payment/order management, customer management, distribution/coupon system design, the entire WeChat/Alipay payment process, Alibaba Cloud/Pagoda operation and maintenance, and project online operation. .....
2023-11-17 08:50:36 0 0 84
2023-11-14 12:58:58 0 1 292
Using Laravel 8's blade asset to display images but loading from resources subfolder
2023-11-09 12:47:02 0 1 314
2023-11-09 11:42:58 0 1 207
Indirect modification of the overloaded attribute of App\Models\User::$profile is invalid.
2023-11-08 11:50:44 0 1 270
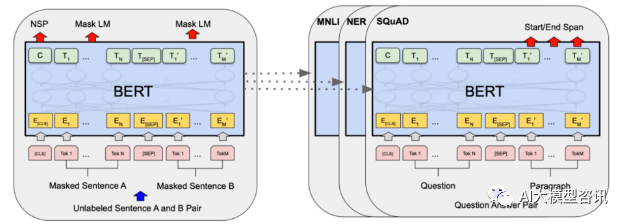
Course Introduction:In 2018, Google released BERT. Once it was released, it defeated the State-of-the-art (Sota) results of 11 NLP tasks in one fell swoop, becoming a new milestone in the NLP world. The structure of BERT is shown in the figure below. On the left is the BERT model preset. The training process, on the right is the fine-tuning process for specific tasks. Among them, the fine-tuning stage is for fine-tuning when it is subsequently used in some downstream tasks, such as text classification, part-of-speech tagging, question and answer systems, etc. BERT can be fine-tuned on different tasks without adjusting the structure. Through the task design of "pre-trained language model + downstream task fine-tuning", it brings powerful model effects. Since then, "pre-training language model + downstream task fine-tuning" has become the mainstream training in the NLP field.
2023-10-07 comment 0 909

Course Introduction:Fine-tuning refers to making slight adjustments to a pre-trained model on a specific task to improve performance. In sentiment analysis, pre-trained natural language processing models (such as BERT, RoBERTa, ALBERT) can be used as the basic model and fine-tuned in combination with specific sentiment analysis data sets to achieve more accurate sentiment analysis results. Through fine-tuning, the model can be adapted according to the needs of specific tasks and improve the performance of the model on specific tasks. The purpose of fine-tuning the model is to fine-tune the general natural language processing model to improve its recognition ability and prediction accuracy in sentiment analysis tasks. Through fine-tuning, we can transfer the learning capabilities of the model to specific areas, making it better suited to specific task requirements. Such fine-tuning
2024-01-22 comment 0 745

Course Introduction:ReFT (Representation Finetuning) is a breakthrough method that promises to redefine the way we fine-tune large language models. According to a recent (April) paper published on arxiv by researchers at Stanford University, ReFT is significantly different from traditional weight-based fine-tuning methods, providing a more efficient and effective way to adapt to these large-scale models to Adapt to new tasks and areas! Before introducing this paper, let's take a look at PeFT. Parameter Efficient Fine-Tuning PeFTParameterEfficientFine-Tuning (PEFT) is an efficient fine-tuning method for fine-tuning a small number or additional model parameters. Fine-tuning with traditional predictive networks
2024-04-15 comment 812
Course Introduction:OpenAI has announced major enhancements to its fine-tuning API, as well as an expansion of its custom model routine. These updates will give developers unprecedented control to fine-tune AI models and provide new ways to build customized models for specific business needs. Since its launch in August 2023, GPT-3.5’s fine-tuning API has become a turning point in combining refined AI models to perform specific tasks. Fine-tuning tools play a vital role in the development of AI models. They allow developers to optimize model performance based on specific data sets and application scenarios. In April 2022, OpenAI released a series of improvements to its fine-tuning API. These improvements not only improve the flexibility and accuracy of the model, but also provide developers with more
2024-04-07 comment 844

Course Introduction:We know that large language models (LLMs), from Google T5 models to the OpenAI GPT series of large models, have demonstrated impressive generalization capabilities, such as context learning and thought chain reasoning. At the same time, in order to make LLMs follow natural language instructions and complete real-world tasks, researchers have been exploring instruction fine-tuning methods for LLMs. This is done in two ways: using human-annotated prompts and feedback to fine-tune models on a wide range of tasks, or using public benchmarks and datasets augmented with manually or automatically generated instructions to supervise fine-tuning. Among these methods, Self-Instruct fine-tuning is a simple and effective method that fine-tunes teachers from SOTA instructions
2023-04-10 comment 0 1200