

Course Intermediate 11331
Course Introduction:"Self-study IT Network Linux Load Balancing Video Tutorial" mainly implements Linux load balancing by performing script operations on web, lvs and Linux under nagin.

Course Advanced 17634
Course Introduction:"Shangxuetang MySQL Video Tutorial" introduces you to the process from installing to using the MySQL database, and introduces the specific operations of each link in detail.

Course Advanced 11348
Course Introduction:"Brothers Band Front-end Example Display Video Tutorial" introduces examples of HTML5 and CSS3 technologies to everyone, so that everyone can become more proficient in using HTML5 and CSS3.
Ways to fix issue 2003 (HY000): Unable to connect to MySQL server 'db_mysql:3306' (111)
2023-09-05 11:18:47 0 1 825
Experiment with sorting after query limit
2023-09-05 14:46:42 0 1 726
CSS Grid: Create new row when child content overflows column width
2023-09-05 15:18:28 0 1 615
PHP full text search functionality using AND, OR and NOT operators
2023-09-05 15:06:32 0 1 578
Shortest way to convert all PHP types to string
2023-09-05 15:34:44 0 1 1006

Course Introduction:Scalable Maps: Scalable Map Learning for Online Long-Distance Vectorized HD Map Construction Please click the following link to read the paper: https://arxiv.org/pdf/2310.13378.pdf Code link: https://github.com/ jingy1yu/ScalableMap The author is from Wuhan University. Paper idea: This paper proposes a novel end-to-end process for building online long-distance vectorized high-precision (HD) maps using vehicle-mounted camera sensors. Vectorized representations of high-precision maps use polylines and polygons to represent map features, which are widely used by downstream tasks. However, previous solutions designed with reference to dynamic target detection ignored the linear map
2023-10-31 comment 0 1246
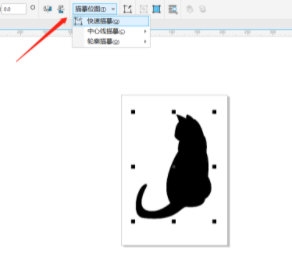
Course Introduction:CorelDRAW is a very easy-to-use picture design software. It has many powerful functions that can help users design a variety of beautiful and creative pictures and text. Today, let us take a look at how to create silhouette text. Most of these text effects are made with silhouettes of small animals or plants, so we need to prepare this type of vector material. Let’s take a look at the details! The specific operations are as follows: 1. Open the CorelDRAW software and substitute the vector material. If it is not a vector image, click [Tracing Bitmap] to convert it. 2. Use the [Pen Tool] to circle the part where you want to replace the text. 3. Select the silhouette material and the drawn curve. , click Intersect, extract the tail and click Simplify to remove the tail from the original material. 4. Input
2024-02-09 comment 0 1253

Course Introduction:Written before: The author’s personal understanding is that constructing vectorized high-precision maps based on sensor data in real time is crucial for downstream tasks such as prediction and planning, and can effectively make up for the poor real-time performance of offline high-precision maps. With the development of deep learning, online vectorized high-precision map construction has gradually emerged, and representative works such as HDMapNet, MapTR, etc. have emerged one after another. However, existing online vectorized high-precision map construction methods lack exploration of the geometric properties of map elements (including the shape of elements, vertical, parallel and other geometric relationships). Geometric properties of vectorized high-precision maps Vectorized high-precision maps highly abstract the elements on the road and represent each map element as a two-dimensional point sequence. The design of urban roads has specific specifications, for example, pedestrian
2023-12-15 comment 0 590

Course Introduction:IT House reported on June 1 that last weekend the beta version of Adobe Photoshop launched an AI image synthesis tool called "GenerativeFill". This function has been popular among netizens since its launch. Many netizens use it to expand the covers of classic music albums. Many highly creative works were produced. The "GenerativeFill" function uses the "Adobe Firefly" image synthesis model, which learns from millions of Adobe material images to generate reasonable extensions based on a given image. Users can also input text prompts to guide the AI to generate specific scenes, thereby obtaining more fantastic results. For example, some netizens used this tool to expand Mike’s
2023-06-04 comment 0 1114

Course Introduction:VisionTransformer (VIT) is a Transformer-based image classification model proposed by Google. Different from traditional CNN models, VIT represents images as sequences and learns the image structure by predicting the class label of the image. To achieve this, VIT divides the input image into multiple patches and concatenates the pixels in each patch through channels and then performs linear projection to achieve the desired input dimensions. Finally, each patch is flattened into a single vector, forming the input sequence. Through Transformer's self-attention mechanism, VIT is able to capture the relationship between different patches and perform effective feature extraction and classification prediction. This serialized image representation is
2024-01-23 comment 0 1397
