Found a total of 10000 related content

By changing one line of code, PyTorch training is three times faster. These 'advanced technologies' are the key
Article Introduction:Recently, Sebastian Raschka, a well-known researcher in the field of deep learning and chief artificial intelligence educator of LightningAI, delivered a keynote speech "ScalingPyTorchModelTrainingWithMinimalCodeChanges" at CVPR2023. In order to share the research results with more people, Sebastian Raschka compiled the speech into an article. The article explores how to scale PyTorch model training with minimal code changes, and shows that the focus is on leveraging mixed-precision methods and multi-GPU training modes rather than low-level machine optimizations. Article usage view
2023-08-14
comment 0
923

Research on biases and self-correction methods of language models
Article Introduction:The bias of a language model is that it may be biased towards certain groups of people, themes or topics when generating text, resulting in the text being unbiased, neutral or discriminatory. This bias may arise from factors such as training data selection, training algorithm design, or model structure. To solve this problem, we need to focus on data diversity and ensure that training data includes a variety of backgrounds and perspectives. Additionally, we should review training algorithms and model structures to ensure their fairness and neutrality to improve the quality and inclusivity of generated text. For example, there may be an over-bias toward certain categories in the training data, causing the model to favor those categories more when generating text. This bias may cause the model to perform poorly when dealing with other categories, affecting the performance of the model. In addition, there may be some discrepancies in the design of the model.
2024-01-22
comment 0
432

Python implements support vector machine (SVM) classification: detailed explanation of algorithm principles
Article Introduction:In machine learning, support vector machines (SVM) are often used for data classification and regression analysis, and are discriminant algorithm models based on separation hyperplanes. In other words, given labeled training data, the algorithm outputs an optimal hyperplane for classifying new examples. The support vector machine (SVM) algorithm model represents examples as points in space. After mapping, examples of different categories are divided as much as possible. In addition to performing linear classification, support vector machines (SVMs) can efficiently perform nonlinear classification, implicitly mapping their inputs into a high-dimensional feature space. What does a support vector machine do? Given a set of training examples, each training example is marked with a category according to two categories, and then a model is built through the support vector machine (SVM) training algorithm to classify the new examples into
2024-01-24
comment 0
1131

Breaking through the dimensional wall, X-Dreamer brings high-quality text to 3D generation, integrating the fields of 2D and 3D generation.
Article Introduction:In recent years, significant progress has been made in automatically converting text into 3D content, driven by the development of pre-trained diffusion models [1, 2, 3]. Among them, DreamFusion[4] introduced an efficient method that leverages a pre-trained 2D diffusion model[5] to automatically generate 3D assets from text without the need for a specialized 3D asset dataset. A key innovation introduced by DreamFusion is Fractional distillation sampling (SDS) algorithm. The algorithm utilizes a pre-trained 2D diffusion model to evaluate a single 3D representation, such as NeRF [6], thereby optimizing it to ensure that the rendered image from any camera perspective maintains a high consistency with the given text. Inspired by the seminal SDS algorithm, several
2023-12-15
comment 0
559

ConvNeXt V2 is here, using only the simplest convolution architecture, the performance is not inferior to Transformer
Article Introduction:After decades of basic research, the field of visual recognition has ushered in a new era of large-scale visual representation learning. Pretrained large-scale vision models have become an essential tool for feature learning and vision applications. The performance of a visual representation learning system is greatly affected by three main factors: the model's neural network architecture, the method used to train the network, and the training data. Improvements in each factor contribute to improvements in overall model performance. Innovations in neural network architecture design have always played an important role in the field of representation learning. The convolutional neural network architecture (ConvNet) has had a significant impact on computer vision research, enabling the use of universal feature learning methods in various visual recognition tasks without relying on artificial intelligence.
2023-04-11
comment 0
1416

Basic principles and examples of KNN algorithm classification
Article Introduction:The KNN algorithm is a simple and easy-to-use classification algorithm suitable for small-scale data sets and low-dimensional feature spaces. It performs well in fields such as image classification and text classification, and is popular because of its simplicity of implementation and ease of understanding. The basic idea of the KNN algorithm is to find the closest K neighbors by comparing the characteristics of the sample to be classified with the characteristics of the training sample, and determine the category of the sample to be classified based on the categories of these K neighbors. The KNN algorithm uses a training set with labeled categories and a test set to be classified. The classification process of the KNN algorithm includes the following steps: first, calculate the distance between the sample to be classified and all training samples; second, select the K nearest neighbors; then, vote according to the categories of the K neighbors to obtain the Classification sample category; most
2024-01-23
comment 0
745

'White Wattle Corridor' joint training ground gameplay introduction
Article Introduction:How to play at the Baijing Corridor Joint Training Ground? The Joint Training Ground is one of the gameplay modes of White Wattle Corridor. Many players don’t know how to play it specifically. Players can refer to the article content to learn about the gameplay of the Joint Training Ground. The details are in this White Wattle Corridor Joint Training Ground gameplay introduction. I believe It will definitely be helpful to you, let’s take a look. "Baijing Corridor" joint training ground gameplay introduction gameplay introduction: 1. First, players need to capture four defense zones A, B, C, and D in order of time. There are 3 partitions under A, B, C, and D. 2. The player places a character each in the square camp corner and the rhombus profession to fight and will be stationed here. 3. Finally, the score is based on the battle results. Scoring rules: 1. Every 1,000 scores increases the number of deduction seats by 5%, and the deduction progress indicates the maximum
2024-01-12
comment 0
1191

Symbolic algorithm for returning to the origin
Article Introduction:The symbolic regression algorithm is a machine learning algorithm that automatically builds mathematical models. Its main goal is to predict the value of the output variable by analyzing the functional relationship between the variables in the input data. This algorithm combines the ideas of genetic algorithms and evolutionary strategies to gradually improve the accuracy of the model by randomly generating and combining mathematical expressions. By continuously optimizing the model, symbolic regression algorithms can help us better understand and predict complex data relationships. The process of the symbolic regression algorithm is as follows: 1. Define the problem: determine the input variables and output variables. 2. Initialize the population: Randomly generate a set of mathematical expressions as the population. Evaluate fitness: Use the mathematical expression of each individual to predict the data in the training set, and calculate the error between the predicted value and the actual value as the adaptation
2024-01-23
comment 0
1406

Functions and methods for optimizing hyperparameters
Article Introduction:Hyperparameters are parameters that need to be set before training the model. They cannot be learned from training data and need to be manually adjusted or determined by automatic search. Common hyperparameters include learning rate, regularization coefficient, number of iterations, batch size, etc. Hyperparameter tuning is the process of optimizing algorithm performance and is very important to improve the accuracy and performance of the algorithm. The purpose of hyperparameter tuning is to find the best combination of hyperparameters to improve the performance and accuracy of the algorithm. If the tuning is insufficient, it may lead to poor algorithm performance and problems such as overfitting or underfitting. Tuning can enhance the generalization ability of the model and make it perform better on new data. Therefore, it is crucial to fully tune the hyperparameters. There are many methods for hyperparameter tuning. Common methods include grid search, random search, and Bayesian optimization.
2024-01-22
comment 0
764

Automatic learning machine (AutoML)
Article Introduction:Automatic Machine Learning (AutoML) is a game changer in the field of machine learning. It can automatically select and optimize algorithms, making the process of training machine learning models simpler and more efficient. Even if you have no machine learning experience, you can easily train a model with excellent performance with the help of AutoML. AutoML provides an explainable AI approach to enhance model interpretability. This way, data scientists can gain insights into the model’s prediction process. This is particularly useful in the fields of healthcare, finance, and autonomous systems. It can help identify biases in data and prevent incorrect predictions. AutoML leverages machine learning to solve real-world problems, including tasks such as algorithm selection, hyperparameter optimization, and feature engineering. Here are some commonly used methods: God
2024-01-22
comment 0
908

Deep Thinking | Where is the capability boundary of large models?
Article Introduction:If we have infinite resources, such as infinite data, infinite computing power, infinite models, perfect optimization algorithms and generalization performance, can the resulting pre-trained model be used to solve all problems? This is a question that everyone is very concerned about, but existing machine learning theories cannot answer it. It has nothing to do with the expressive ability theory, because the model is infinite and the expressive ability is naturally infinite. It is also irrelevant to optimization and generalization theory, because we assume that the optimization and generalization performance of the algorithm are perfect. In other words, the problems of previous theoretical research no longer exist here! Today, I would like to introduce to you the paper OnthePowerofFoundationModels that I published at ICML'2023. From the perspective of category theory,
2023-09-08
comment 0
1267

Able to align humans without RLHF, performance comparable to ChatGPT! Chinese team proposes Wombat model
Article Introduction:OpenAI’s ChatGPT is able to understand a wide variety of human instructions and perform well in different language tasks. This is possible thanks to a novel large-scale language model fine-tuning method called RLHF (Aligned Human Feedback via Reinforcement Learning). The RLHF method unlocks the ability of language models to follow human instructions, making the capabilities of language models consistent with human needs and values. Currently, RLHF's research work mainly uses the PPO algorithm to optimize language models. However, the PPO algorithm contains many hyperparameters and requires multiple independent models to cooperate with each other during the algorithm iteration process, so wrong implementation details may lead to poor training results. At the same time, reinforcement learning algorithms are not necessary from a human alignment perspective. Argument
2023-05-03
comment 0
1323

Overfitting problem in machine learning algorithms
Article Introduction:The over-fitting problem in machine learning algorithms requires specific code examples. In the field of machine learning, the over-fitting problem of models is one of the common challenges. When a model overfits the training data, it becomes overly sensitive to noise and outliers, causing the model to perform poorly on new data. In order to solve the over-fitting problem, we need to take some effective methods during the model training process. A common approach is to use regularization techniques such as L1 regularization and L2 regularization. These techniques limit the complexity of the model by adding a penalty term to prevent the model from overdoing the
2023-10-09
comment 0
984

How do features influence the choice of model type?
Article Introduction:Features play an important role in machine learning. When building a model, we need to carefully choose the features for training. The selection of features will directly affect the performance and type of the model. This article explores how features affect model type. 1. Number of features The number of features is one of the important factors affecting the type of model. When the number of features is small, traditional machine learning algorithms such as linear regression, decision trees, etc. are usually used. These algorithms are suitable for processing a small number of features and the calculation speed is relatively fast. However, when the number of features becomes very large, the performance of these algorithms usually degrades because they have difficulty processing high-dimensional data. Therefore, in this case, we need to use more advanced algorithms such as support vector machines, neural networks, etc. These algorithms are capable of handling high-dimensional
2024-01-24
comment 0
998
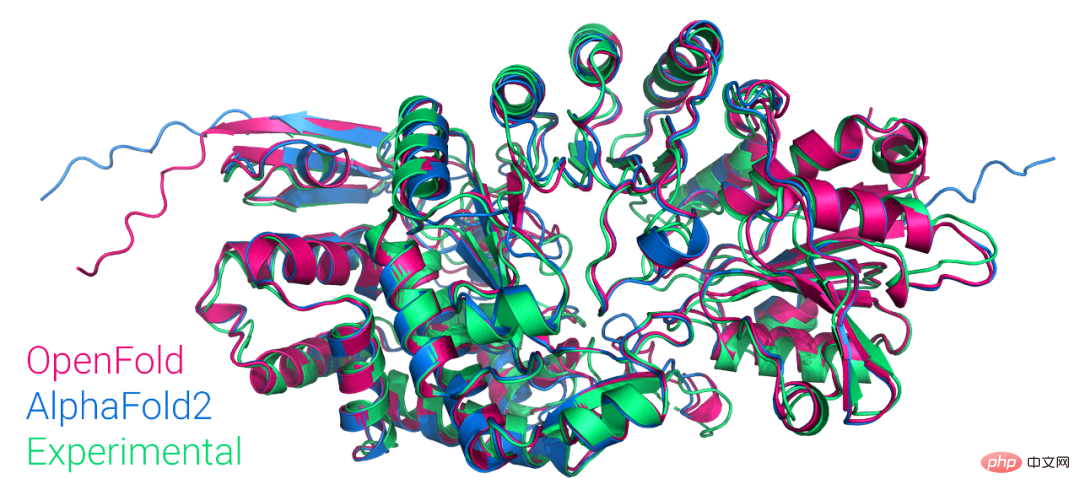
The first public-available PyTorch version of AlphaFold2 is reproduced, open sourced by Columbia University, and has more than 1,000 stars
Article Introduction:Just now, Mohammed AlQuraishi, assistant professor of systems biology at Columbia University, announced on Twitter that they have trained a model called OpenFold from scratch, which is a trainable PyTorch reappearance of AlphaFold2. Mohammed AlQuraishi also said that this is the first reproduction of AlphaFold2 available to the public. AlphaFold2 can periodically predict protein structures with atomic precision, using technology designed to leverage multi-sequence alignment and deep learning algorithms, combined with physical and biological knowledge about protein structures to improve predictions. It achieves excellent results in predicting 2/3 protein structures.
2023-04-13
comment 0
1206

Machine Learning Model Evaluation Tips in Python
Article Introduction:Machine learning is a complex field that encompasses numerous techniques and methods that require frequent testing and evaluation of model performance when solving real-world problems. Machine learning model evaluation techniques are very important skills in Python because they help developers determine when a model is reliable and how it performs on a specific data set. Here are some common machine learning model evaluation techniques in Python: Cross-validation Cross-validation is a statistical technique commonly used to evaluate the performance of machine learning algorithms. The data set is divided into training
2023-06-10
comment 0
1670

The first LLM that supports 4-bit floating point quantization is here to solve the deployment problems of LLaMA, BERT, etc.
Article Introduction:Large language model (LLM) compression has always attracted much attention, and post-training quantization (Post-training Quantization) is one of the commonly used algorithms. However, most of the existing PTQ methods are integer quantization, and when the number of bits is less than 8, after quantization The accuracy of the model will drop significantly. Compared with Integer (INT) quantification, FloatingPoint (FP) quantification can better represent long-tail distribution, so more and more hardware platforms begin to support FP quantification. This article gives a solution to FP quantification of large models. The article was published on EMNLP2023. Paper address: https://arxiv.org/abs/2310.16
2023-11-18
comment 0
1122

The night shooting performance of Redmi K70 Pro has been greatly improved, thanks to the help of Xiaomi Night Owl algorithm
Article Introduction:According to news on November 27, Redmi recently released its latest mobile phone K70Pro. This phone is not only equipped with OIS optical anti-shake technology, but also introduces the Night Owl algorithm developed by Xiaomi for the first time, providing users with an unprecedented night shooting experience. According to the editor's understanding, the Night Owl algorithm originally debuted on Xiaomi 11 Ultra. An important feature. This algorithm focuses on solving common noise problems in night photography. Through the independently developed night scene noise calibration system, it conducts accurate mathematical modeling of the distribution and shape of night scene noise. In order to improve the effect of the Night Owl algorithm, Xiaomi's engineering team adopted an innovative method to increase the diversity of simulated noise data by adding noise to the simulation, thereby enriching the training data of the algorithm and making the denoising process
2023-11-27
comment 0
1646

Understand reinforcement learning and its application scenarios
Article Introduction:The best way to train a dog is to use a reward system to reward it for good behavior and punish it for bad behavior. The same strategy can be used for machine learning, called reinforcement learning. Reinforcement learning is a branch of machine learning that trains models through decision-making to find the best solution to a problem. To improve model accuracy, positive rewards can be used to encourage the algorithm to get closer to the correct answer, while negative rewards can be given to punish deviations from the target. You only need to clarify the goals and then model the data. The model will start to interact with the data and propose solutions on its own without manual intervention. Reinforcement Learning Example Let’s take dog training as an example. We provide rewards such as dog biscuits to make the dog perform various actions. The dog pursues rewards according to a certain strategy, so it follows commands and learns new actions, such as begging
2024-01-22
comment 0
1377

China Unicom releases large image and text AI model that can generate images and video clips from text
Article Introduction:Driving China News on June 28, 2023, today during the Mobile World Congress in Shanghai, China Unicom released the graphic model "Honghu Graphic Model 1.0". China Unicom said that the Honghu graphic model is the first large model for operators' value-added services. China Business News reporter learned that Honghu’s graphic model currently has two versions of 800 million training parameters and 2 billion training parameters, which can realize functions such as text-based pictures, video editing, and pictures-based pictures. In addition, China Unicom Chairman Liu Liehong also said in today's keynote speech that generative AI is ushering in a singularity of development, and 50% of jobs will be profoundly affected by artificial intelligence in the next two years.
2023-06-29
comment 0
1476

