


Sistem pengesyoran adalah penting untuk menangani cabaran lebihan maklumat, kerana mereka menyediakan pengesyoran tersuai berdasarkan pilihan peribadi pengguna. Dalam beberapa tahun kebelakangan ini, teknologi pembelajaran mendalam telah banyak menggalakkan pembangunan sistem pengesyoran dan menambah baik cerapan tentang tingkah laku dan pilihan pengguna.
Walau bagaimanapun, kaedah pembelajaran tradisional yang diselia menghadapi cabaran dalam aplikasi praktikal disebabkan masalah keterlanjuran data, yang mengehadkan keupayaan mereka untuk mempelajari prestasi pengguna dengan berkesan.
Untuk melindungi dan mengatasi masalah ini, teknologi pembelajaran penyeliaan kendiri (SSL) digunakan kepada pelajar, yang menggunakan struktur data yang wujud untuk menjana isyarat penyeliaan dan tidak bergantung sepenuhnya pada data berlabel.
Kaedah ini menggunakan sistem pengesyoran yang boleh mengekstrak maklumat bermakna daripada data yang tidak berlabel dan membuat ramalan dan pengesyoran yang tepat walaupun data adalah terhad.

Alamat artikel: https://arxiv.org/abs/2404.03354
Pangkalan data sumber terbuka: https://github.com/HKUDS/Awesome-SSLRec🜎sumber Pustaka kod: https://github.com/HKUDS/SSLRec
Artikel ini menyemak rangka kerja pembelajaran penyeliaan sendiri yang direka untuk sistem pengesyor dan menjalankan analisis mendalam terhadap lebih daripada 170 kertas kerja berkaitan. Kami meneroka sembilan senario aplikasi yang berbeza untuk mendapatkan pemahaman yang komprehensif tentang cara SSL boleh meningkatkan sistem pengesyoran dalam senario yang berbeza.
Untuk setiap domain, kami membincangkan paradigma pembelajaran penyeliaan sendiri yang berbeza secara terperinci, termasuk pembelajaran kontrastif, pembelajaran generatif dan pembelajaran menentang, menunjukkan cara SSL boleh meningkatkan prestasi sistem pengesyoran dalam situasi yang berbeza.
1 Sistem yang disyorkan
dan set item, dilambangkan sebagai 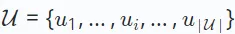 .
. 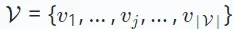 Kemudian, gunakan matriks interaksi
Kemudian, gunakan matriks interaksi
untuk mewakili interaksi yang direkodkan antara pengguna dan item. Dalam matriks ini, entri Ai,j matriks diberikan nilai 1 jika pengguna ui telah berinteraksi dengan item vj, jika tidak ia adalah 0. 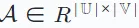 Takrifan interaksi boleh disesuaikan dengan konteks dan set data yang berbeza (cth., menonton filem, mengklik tapak e-dagang atau membuat pembelian).
Takrifan interaksi boleh disesuaikan dengan konteks dan set data yang berbeza (cth., menonton filem, mengklik tapak e-dagang atau membuat pembelian).
Selain itu, dalam tugas pengesyoran yang berbeza, terdapat data pemerhatian tambahan yang berbeza, direkodkan sebagai dan perhubungan yang sepadan.
Dan dalam pengesyoran sosial, X termasuk perhubungan peringkat pengguna, seperti persahabatan. Berdasarkan definisi di atas, model pengesyoran mengoptimumkan fungsi ramalan f(⋅), bertujuan untuk menganggarkan skor keutamaan dengan tepat antara mana-mana pengguna u dan item v:
Skor keutamaan yu,v mewakili pengguna u dan perkara v Kemungkinan interaksi. 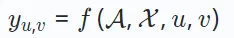
Berdasarkan skor ini, sistem pengesyor boleh mengesyorkan item tidak berinteraksi kepada setiap pengguna dengan menyediakan senarai kedudukan item berdasarkan anggaran skor keutamaan. Dalam semakan, kami meneroka lebih lanjut bentuk data (A,X) dalam senario pengesyoran yang berbeza dan peranan pembelajaran penyeliaan kendiri di dalamnya.
Dalam beberapa tahun kebelakangan ini, rangkaian saraf dalam telah menunjukkan prestasi yang baik dalam pembelajaran terselia, yang telah ditunjukkan dalam pelbagai bidang termasuk penglihatan komputer, pemprosesan bahasa semula jadi dan sistem pengesyoran. Walau bagaimanapun, disebabkan pergantungan yang tinggi pada data berlabel, pembelajaran yang diselia menghadapi cabaran dalam menangani keterbatasan label, yang juga merupakan masalah biasa dalam sistem pengesyor.
Untuk menangani batasan ini, pembelajaran penyeliaan sendiri muncul sebagai kaedah yang menjanjikan, yang menggunakan data itu sendiri sebagai label yang dipelajari. Pembelajaran penyeliaan kendiri dalam sistem pengesyor termasuk tiga paradigma berbeza: pembelajaran kontrastif, pembelajaran generatif dan pembelajaran menentang.
Sebagai kaedah pembelajaran penyeliaan kendiri yang menonjol, matlamat utama pembelajaran kontrastif adalah untuk memaksimumkan ketekalan antara pandangan berbeza yang dipertingkatkan daripada data yang berbeza. Dalam pembelajaran kontrastif sistem pengesyoran, matlamatnya adalah untuk meminimumkan fungsi kehilangan berikut:
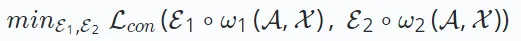
E∗
∘ω∗ mewakili operasi penciptaan pandangan kontrastif berdasarkan operasi pembelajaran kontrastif dan berbeza mempunyai proses penciptaan yang berbeza. Pembinaan setiap paparan terdiri daripada proses penambahan data ω∗ (yang mungkin melibatkan nod/tepi dalam graf ditambah) dan proses pengekodan pembenaman E∗. Matlamat  meminimumkan
meminimumkan
Matlamat pembelajaran generatif adalah untuk memahami struktur dan corak data untuk mempelajari perwakilan yang bermakna. Ia mengoptimumkan model penyahkod pengekod dalam yang membina semula data input yang hilang atau rosak. Pengekod 
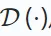 mencipta perwakilan terpendam daripada input, manakala penyahkod
mencipta perwakilan terpendam daripada input, manakala penyahkod
membina semula data asal daripada output pengekod. Matlamatnya adalah untuk meminimumkan perbezaan antara data yang dibina semula dan asal seperti berikut: 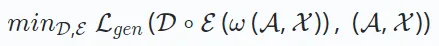
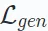 Di sini, ω mewakili operasi seperti penyamaran atau gangguan. D∘E mewakili proses pengekodan dan penyahkodan untuk membina semula output. Penyelidikan terkini juga telah memperkenalkan seni bina penyahkod sahaja yang membina semula data dengan cekap tanpa persediaan penyahkod pengekod. Pendekatan ini menggunakan model tunggal (cth. Transformer) untuk pembinaan semula dan biasanya digunakan pada pengesyoran bersiri berdasarkan pembelajaran generatif. Format fungsi kehilangan
Di sini, ω mewakili operasi seperti penyamaran atau gangguan. D∘E mewakili proses pengekodan dan penyahkodan untuk membina semula output. Penyelidikan terkini juga telah memperkenalkan seni bina penyahkod sahaja yang membina semula data dengan cekap tanpa persediaan penyahkod pengekod. Pendekatan ini menggunakan model tunggal (cth. Transformer) untuk pembinaan semula dan biasanya digunakan pada pengesyoran bersiri berdasarkan pembelajaran generatif. Format fungsi kehilangan
Adversarial Learning ialah kaedah latihan yang menggunakan penjana G(⋅) untuk menjana output berkualiti tinggi dan mengandungi diskriminator Ω(⋅), yang mana sampel yang diberikan menentukan sama ada adalah nyata atau dihasilkan. Tidak seperti pembelajaran generatif, pembelajaran lawan berbeza dengan memasukkan diskriminasi yang menggunakan interaksi kompetitif untuk meningkatkan keupayaan penjana menghasilkan output berkualiti tinggi untuk memperdayakan diskriminator.
🎜Oleh itu, matlamat pembelajaran pembelajaran adversarial boleh ditakrifkan seperti berikut: 🎜🎜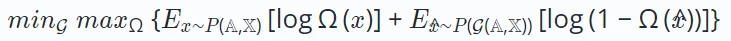
Di sini, pembolehubah x mewakili sampel sebenar yang diperoleh daripada pengedaran data asas, manakala  mewakili sampel sintetik yang dijana oleh penjana G(⋅). Semasa latihan, kedua-dua penjana dan diskriminator meningkatkan keupayaan mereka melalui interaksi kompetitif. Akhirnya, penjana berusaha untuk menghasilkan output berkualiti tinggi yang bermanfaat untuk tugas hiliran.
mewakili sampel sintetik yang dijana oleh penjana G(⋅). Semasa latihan, kedua-dua penjana dan diskriminator meningkatkan keupayaan mereka melalui interaksi kompetitif. Akhirnya, penjana berusaha untuk menghasilkan output berkualiti tinggi yang bermanfaat untuk tugas hiliran.
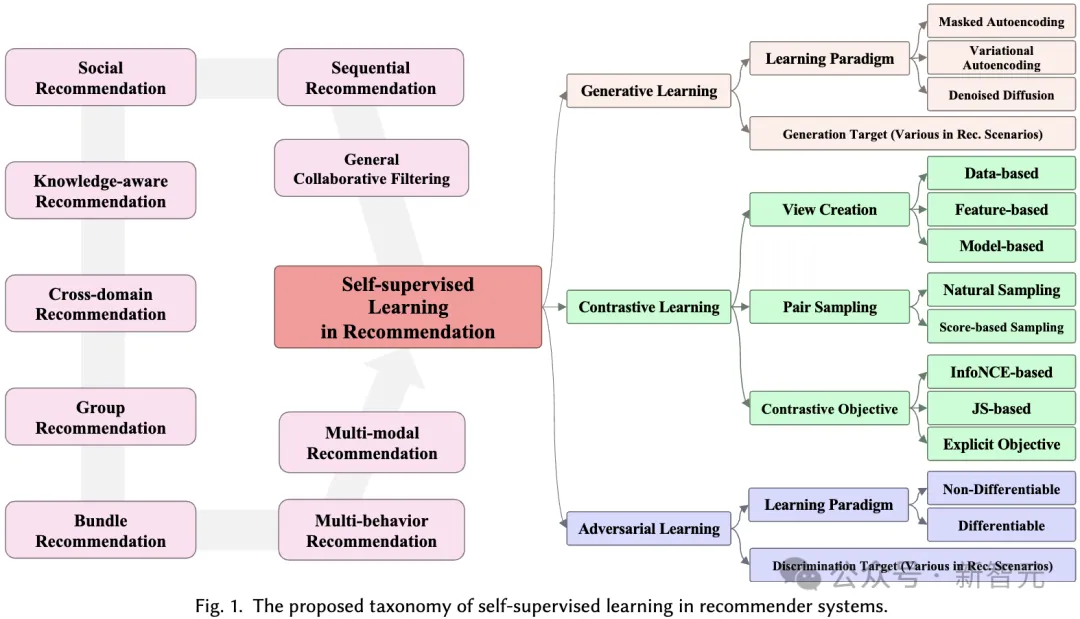
Dalam bahagian ini, kami mencadangkan sistem pengelasan komprehensif untuk aplikasi pembelajaran penyeliaan kendiri dalam sistem pengesyoran. Seperti yang dinyatakan sebelum ini, paradigma pembelajaran penyeliaan kendiri boleh dibahagikan kepada tiga kategori: pembelajaran kontrastif, pembelajaran generatif, dan pembelajaran menentang. Oleh itu, sistem klasifikasi kami dibina berdasarkan tiga kategori ini, memberikan pandangan yang lebih mendalam ke dalam setiap kategori.
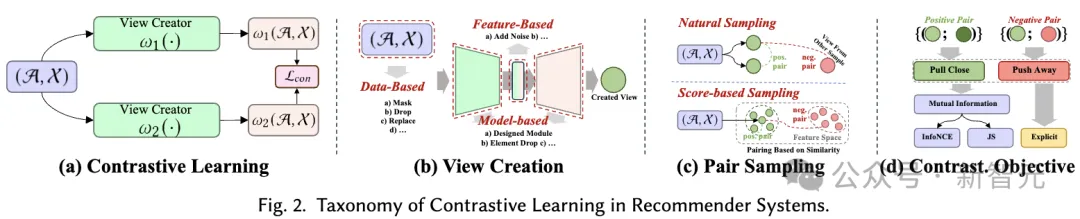
Prinsip asas pembelajaran kontrastif (CL) adalah untuk memaksimumkan pandangan yang berbeza. Oleh itu, kami mencadangkan taksonomi tertumpu pandangan yang terdiri daripada tiga komponen utama untuk dipertimbangkan apabila menggunakan pembelajaran kontrastif: mencipta pandangan, memasangkan pandangan untuk memaksimumkan konsistensi dan mengoptimumkan konsistensi.
Lihat Ciptaan. Buat pandangan yang menekankan pelbagai aspek data yang difokuskan oleh model. Ia boleh menggabungkan maklumat kerjasama global untuk meningkatkan keupayaan sistem pengesyoran untuk mengendalikan perhubungan global, atau memperkenalkan hingar rawak untuk meningkatkan keteguhan model.
Kami menganggap peningkatan data input (cth., graf, jujukan, ciri input) sebagai penciptaan paparan peringkat data, manakala peningkatan ciri terpendam semasa inferens dianggap sebagai penciptaan paparan peringkat ciri. Kami mencadangkan sistem klasifikasi hierarki yang merangkumi teknik penciptaan paparan daripada peringkat data asas kepada tahap model saraf.
Pensampelan Berpasangan. Proses penciptaan paparan menjana sekurang-kurangnya dua paparan berbeza untuk setiap sampel dalam data. Teras pembelajaran kontrastif adalah untuk memaksimumkan penjajaran pandangan tertentu (iaitu, mendekatkannya) sambil menolak pandangan lain.
Untuk melakukan ini, kuncinya adalah untuk mengenal pasti pasangan sampel positif yang harus dibawa lebih dekat, dan mengenal pasti pandangan lain yang membentuk pasangan sampel negatif. Strategi ini dipanggil persampelan berpasangan, dan ia terutamanya terdiri daripada dua kaedah persampelan berpasangan:
Objektif Kontrastif. Matlamat pembelajaran dalam pembelajaran kontrastif adalah untuk memaksimumkan maklumat bersama antara pasangan sampel positif, yang seterusnya dapat meningkatkan prestasi model pengesyoran pembelajaran. Memandangkan tidak dapat dilaksanakan untuk mengira maklumat bersama secara langsung, sempadan bawah yang boleh dilaksanakan biasanya digunakan sebagai sasaran pembelajaran dalam pembelajaran kontrastif. Walau bagaimanapun, terdapat juga matlamat yang jelas untuk merapatkan pasangan positif.

Dalam memaksimumkan pembelajaran penyeliaan kendiri secara generatif, matlamat utama adalah untuk memaksimumkan data seliaan kendiri. Ini membolehkan perwakilan yang dipelajari dan bermakna untuk menangkap struktur dan corak asas dalam data, yang kemudiannya boleh digunakan dalam tugas hiliran. Dalam sistem pengelasan kami, kami mempertimbangkan dua aspek untuk membezakan kaedah cadangan berasaskan pembelajaran generatif yang berbeza: paradigma pembelajaran generatif dan matlamat generatif.
Paradigma Pembelajaran Generatif. Dalam konteks pengesyoran, kaedah penyeliaan kendiri menggunakan pembelajaran generatif boleh dikelaskan kepada tiga paradigma:
Sasaran Generasi. Dalam pembelajaran generatif, corak data yang dianggap sebagai label yang dijana merupakan satu lagi isu yang perlu dipertimbangkan untuk membawa isyarat penyeliaan kendiri bantu yang bermakna. Secara umum, matlamat penjanaan berbeza untuk kaedah yang berbeza dan dalam senario pengesyoran yang berbeza. Sebagai contoh, dalam pengesyoran jujukan, sasaran penjanaan boleh menjadi item dalam jujukan, dengan tujuan mensimulasikan hubungan antara item dalam jujukan. Dalam pengesyoran graf interaktif, sasaran penjanaan boleh menjadi nod/tepi dalam graf, bertujuan untuk menangkap korelasi topologi peringkat tinggi dalam graf.
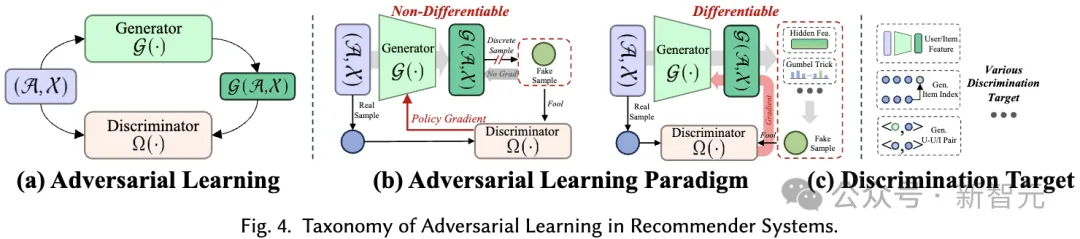
Dalam pembelajaran lawan sistem pengesyor, diskriminasi memainkan peranan penting dalam menjana sampel sebenar. Sama seperti pembelajaran generatif, sistem klasifikasi yang kami cadangkan meliputi kaedah pembelajaran bermusuhan dalam sistem pengesyor daripada dua perspektif: paradigma pembelajaran dan matlamat diskriminasi:
Paradigma Pembelajaran Bermusuhan. Dalam sistem pengesyor, pembelajaran bermusuhan terdiri daripada dua paradigma berbeza, bergantung pada sama ada kehilangan diskriminasi diskriminasi boleh disebarkan kembali kepada penjana dengan cara yang boleh dibezakan.
Sasaran Diskriminasi. Algoritma pengesyoran yang berbeza menyebabkan penjana menghasilkan input yang berbeza, yang kemudiannya disalurkan kepada diskriminasi untuk diskriminasi. Proses ini bertujuan untuk meningkatkan keupayaan penjana untuk menghasilkan kandungan berkualiti tinggi yang lebih dekat dengan realiti. Matlamat diskriminasi khusus direka bentuk berdasarkan tugas pengesyoran khusus.
Dalam ulasan ini, kami membincangkan secara mendalam reka bentuk kaedah pembelajaran penyeliaan kendiri yang berbeza daripada sembilan cadangan berikut baca artikel untuk butiran):
Artikel ini menyediakan ulasan menyeluruh tentang aplikasi pembelajaran penyeliaan kendiri (SSL) dalam sistem pengesyoran, dengan analisis mendalam lebih daripada 170 kertas kerja. Kami mencadangkan sistem klasifikasi yang diselia sendiri yang meliputi sembilan senario pengesyoran, membincangkan tiga paradigma SSL pembelajaran kontrastif, pembelajaran generatif dan pembelajaran menentang secara terperinci, dan membincangkan hala tuju penyelidikan masa depan dalam artikel.
Kami menekankan kepentingan SSL dalam mengendalikan kesederhanaan data dan meningkatkan prestasi sistem pengesyoran, dan menunjukkan potensi untuk menyepadukan model bahasa besar ke dalam sistem pengesyoran, persekitaran pengesyoran dinamik adaptif dan mewujudkan asas teori untuk paradigma SSL . Kami berharap semakan ini dapat menyediakan sumber yang berharga untuk penyelidik, memberi inspirasi kepada idea penyelidikan baharu dan menggalakkan pembangunan selanjutnya sistem pengesyoran.
Atas ialah kandungan terperinci Menyemak 170 algoritma pengesyoran 'pembelajaran kendiri', HKU mengeluarkan SSL4Rec: kod dan pangkalan data adalah sumber terbuka sepenuhnya!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



