
Tapak ini menerbitkan lajur dengan kandungan akademik dan teknikal. Dalam tahun-tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Teroka alam baharu pemahaman video, model Mamba menerajui trend baharu dalam penyelidikan penglihatan komputer! Batasan seni bina tradisional telah dipecahkan Model ruang negeri Mamba telah membawa perubahan revolusioner kepada bidang pemahaman video dengan kelebihan uniknya dalam pemprosesan urutan panjang. Sebuah pasukan penyelidik dari Universiti Nanjing, Makmal Kecerdasan Buatan Shanghai, Universiti Fudan dan Universiti Zhejiang mengeluarkan kerja pecah tanah. Mereka melihat secara menyeluruh pelbagai peranan Mamba dalam pemodelan video, mencadangkan Suite Video Mamba untuk 14 model/modul dan menjalankan penilaian yang mendalam ke atas 12 tugas pemahaman video. Hasilnya menarik: Mamba menunjukkan potensi yang kukuh dalam kedua-dua tugasan khusus video dan lisan, mencapai keseimbangan kecekapan dan prestasi yang ideal. Ini bukan sahaja lonjakan teknologi, tetapi juga dorongan kuat untuk penyelidikan pemahaman video masa hadapan. 
- Tajuk kertas: Video Mamba Suite: State Space Model sebagai Alternatif Serbaguna untuk Pemahaman Video
- Pautan kertas: https://arxiv.org/abs/2403.09626
- ://github.com/OpenGVLab/video-mamba-suite
Dalam bidang penglihatan komputer yang pesat membangun hari ini, teknologi pemahaman video telah menjadi salah satu kuasa penggerak utama untuk kemajuan industri. Ramai penyelidik komited untuk meneroka dan mengoptimumkan pelbagai seni bina pembelajaran mendalam untuk mencapai analisis kandungan video yang lebih mendalam. Daripada rangkaian neural berulang awal (RNN) dan rangkaian saraf konvolusi tiga dimensi (3D CNN) kepada model Transformer yang sangat dinanti-nantikan pada masa ini, setiap lonjakan teknologi telah meluaskan pemahaman dan aplikasi data video kami. Khususnya, model Transformer telah mencapai pencapaian yang luar biasa dalam pelbagai bidang pemahaman video dengan prestasi cemerlangnya, termasuk tetapi tidak terhad kepada pengesanan sasaran, pembahagian imej dan menjawab soalan pelbagai mod. Walau bagaimanapun, dalam menghadapi ciri jujukan ultra-panjang yang wujud bagi data video, model Transformer juga mendedahkan batasan yang wujud: disebabkan peningkatan kuadratik dalam kerumitan pengiraan, ia menjadi amat sukar untuk memodelkan jujukan video ultra-panjang secara langsung. Dalam konteks ini, seni bina model angkasa negeri - diwakili oleh Mamba - muncul mengikut keperluan masa Dengan kelebihan kerumitan pengiraan linear, ia menunjukkan potensi yang kuat untuk memproses data jujukan panjang, yang merupakan asas Transformer. model. Penggantian menawarkan kemungkinan. Walaupun begitu, masih terdapat beberapa batasan dalam aplikasi seni bina model angkasa negeri semasa dalam bidang pemahaman video: Pertama, ia memberi tumpuan terutamanya kepada tugas pemahaman video global, seperti klasifikasi dan mendapatkan semula kedua, ia terutamanya meneroka kaedah pemodelan spatiotemporal langsung Walau bagaimanapun, penerokaan kaedah pemodelan yang lebih pelbagai masih tidak mencukupi. Untuk mengatasi batasan ini dan menilai secara menyeluruh potensi model Mamba dalam bidang pemahaman video, pasukan penyelidik membina suite video-mamba (suite video Mamba) dengan teliti. Suite ini bertujuan untuk melengkapkan penyelidikan sedia ada, meneroka peranan Mamba yang pelbagai dan potensi manfaat dalam pemahaman video melalui satu siri eksperimen dan analisis yang mendalam. Pasukan penyelidik membahagikan aplikasi model Mamba kepada empat peranan berbeza, dan dengan itu membina suite video Mamba yang mengandungi 14 model/modul. Selepas penilaian menyeluruh ke atas 12 tugas pemahaman video, keputusan eksperimen bukan sahaja mendedahkan potensi besar Mamba dalam memproses tugasan video dan bahasa video, tetapi juga menunjukkan keseimbangan yang sangat baik antara kecekapan dan prestasi. Penulis mengharapkan kerja ini menyediakan sumber rujukan dan pandangan untuk penyelidikan masa depan dalam bidang pemahaman video. 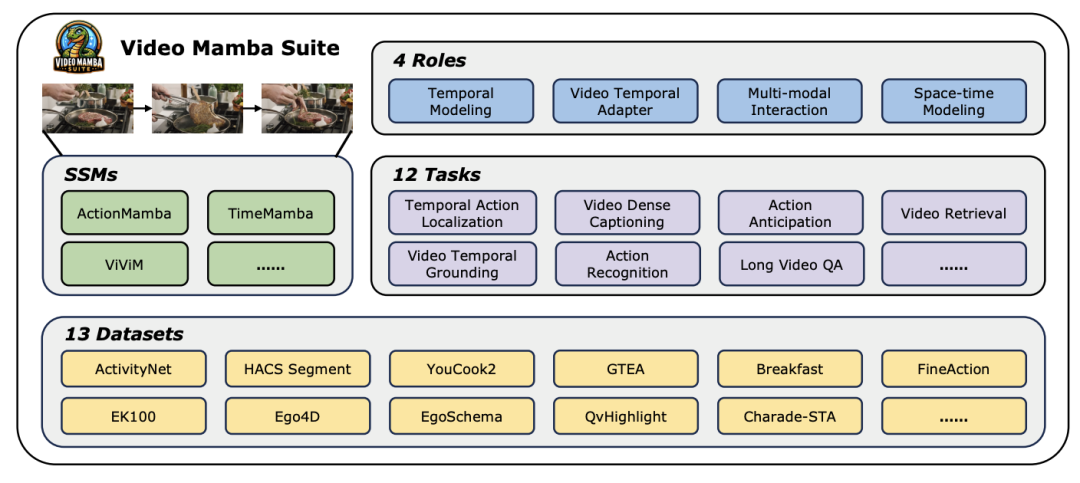
Latar belakang penyelidikanPemahaman video ialah isu asas dalam penyelidikan penglihatan komputer Terasnya adalah untuk menangkap dinamik spatiotemporal dalam video, dan menggunakan satu kaedah untuk mengenal pasti dan membuat kesimpulan sifat aktiviti dan cirinya. proses evolusi. Pada masa ini, penerokaan seni bina untuk pemahaman video terbahagi kepada tiga arah. Pertama, kaedah pengekodan ciri berasaskan bingkai memodelkan pergantungan temporal melalui rangkaian berulang (seperti GRU dan LSTM), tetapi kaedah pemodelan spatiotemporal bersegmen ini sukar untuk menangkap maklumat spatiotemporal bersama. Kedua, penggunaan kernel konvolusi tiga dimensi membolehkan pertimbangan serentak korelasi spatial dan temporal dalam rangkaian saraf konvolusi. Dengan kejayaan besar model Transformer dalam bidang bahasa dan imej, model Transformer video juga telah mencapai kemajuan yang ketara dalam bidang pemahaman video, menunjukkan keupayaan melangkaui RNN dan 3D-CNN. Video Transformer memproses maklumat masa atau spatiotemporal dalam video dengan cara yang bersatu dengan merangkum video dalam satu siri token dan menggunakan mekanisme perhatian untuk merealisasikan interaksi konteks global dan pengiraan dinamik bergantung kepada data. Walau bagaimanapun, disebabkan kecekapan pengiraan Video Transformer yang terhad semasa memproses video panjang, beberapa model varian telah muncul yang mencapai keseimbangan antara kelajuan dan prestasi. Baru-baru ini, model ruang negeri (SSM) telah menunjukkan kelebihannya dalam bidang pemprosesan bahasa semula jadi (NLP). SSM moden mempamerkan keupayaan perwakilan yang kuat dalam pemodelan jujukan panjang sambil mengekalkan kerumitan masa linear. Ini kerana mekanisme pemilihan mereka menghapuskan keperluan untuk menyimpan konteks lengkap. Model Mamba, khususnya, menggabungkan parameter pembolehubah masa ke dalam SSM dan mencadangkan algoritma peka perkakasan untuk mencapai latihan dan inferens yang cekap. Prestasi penskalaan Mamba yang cemerlang menunjukkan bahawa ia boleh menjadi alternatif yang menjanjikan kepada Transformer. Pada masa yang sama, prestasi tinggi dan kecekapan Mamba menjadikannya sangat sesuai untuk tugas pemahaman video. Walaupun terdapat beberapa percubaan awal untuk meneroka aplikasi Mamba dalam pemodelan imej/video, keberkesanannya dalam pemahaman video masih tidak jelas. Kekurangan penyelidikan menyeluruh tentang potensi Mamba dalam pemahaman video mengehadkan penerokaan lanjut keupayaannya dalam pelbagai tugas berkaitan video. Sebagai tindak balas kepada masalah di atas, pasukan penyelidik meneroka potensi Mamba dalam bidang pemahaman video. Matlamat penyelidikan mereka adalah untuk menilai sama ada Mamba boleh menjadi alternatif yang berdaya maju kepada Transformers dalam bidang ini. Untuk melakukan ini, mereka mula-mula menangani persoalan bagaimana untuk memikirkan peranan Mamba yang berbeza dalam memahami video. Berdasarkan ini, mereka terus mengkaji tugas yang Mamba lakukan dengan lebih baik. Makalah ini membahagikan peranan Mamba dalam pemodelan video kepada empat kategori berikut: 1) model temporal, 2) modul temporal, 3) rangkaian interaksi pelbagai mod, 4) model spatiotemporal. Untuk setiap peranan, pasukan penyelidik mengkaji keupayaan pemodelan videonya pada tugas pemahaman video yang berbeza. Untuk menyaingi Manba secara adil dengan Transformer, pasukan penyelidik memilih model dengan teliti untuk perbandingan berdasarkan seni bina Transformer standard atau diubah suai. Berdasarkan ini, mereka memperoleh Suite Video Mamba yang mengandungi 14 model/modul yang sesuai untuk 12 tugas pemahaman video. Pasukan penyelidik berharap Video Mamba Suite boleh menjadi sumber asas untuk meneroka model pemahaman video berasaskan SSM pada masa hadapan. Mamba sebagai model pemasaan video Tugasan pasukan penyelidikan dan masa: Tugasan pasukan penyelidikan sementara Penyetempatan Tindakan (HACS Segmen), Segmentasi Tindakan Temporal (GTEA), Kapsyen Video Padat (ActivityNet, YouCook), Kapsyen Segmen Video (ActivityNet, YouCook) dan Ramalan Tindakan (Epic-Kitchen-100).
Baseline dan Challenger
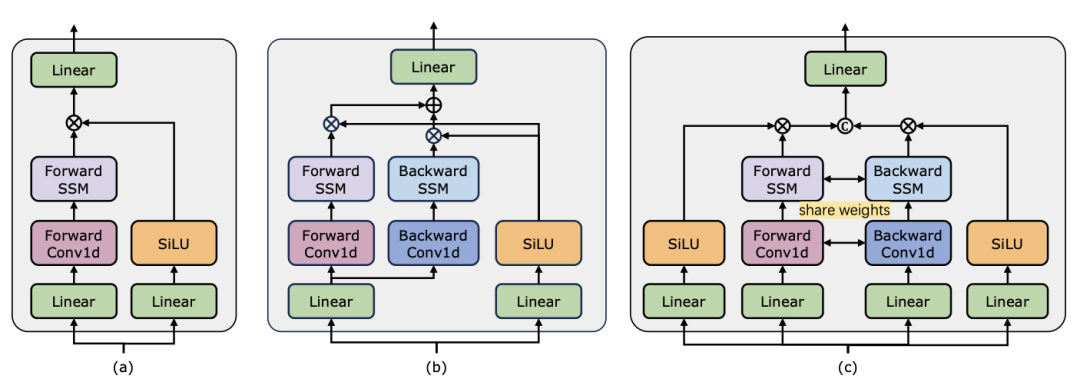
: Pasukan penyelidik memilih model berasaskan Transformer sebagai garis dasar untuk setiap tugas. Khususnya, model garis dasar ini termasuk ActionFormer, ASFormer, Testra dan PDVC. Untuk membina pencabar Mamba, mereka menggantikan modul Transformer dalam model garis dasar dengan modul berasaskan Mamba, termasuk tiga modul seperti yang ditunjukkan di atas, Mamba asal (a), ViM (b) dan DBM (c) asalnya. direka oleh pasukan penyelidik ) modul. Perlu diingat bahawa kertas itu membandingkan prestasi model garis dasar dengan modul Mamba asal dalam tugas ramalan tindakan yang melibatkan inferens sebab akibat.
🎜Keputusan dan Analisis🎜: Kertas kerja menunjukkan hasil perbandingan model berbeza pada empat tugasan. Secara keseluruhan, walaupun beberapa model berasaskan Transformer telah menggabungkan varian perhatian untuk meningkatkan prestasi. Jadual di bawah menunjukkan prestasi unggul siri Mamba berbanding kaedah siri Transformer sedia ada.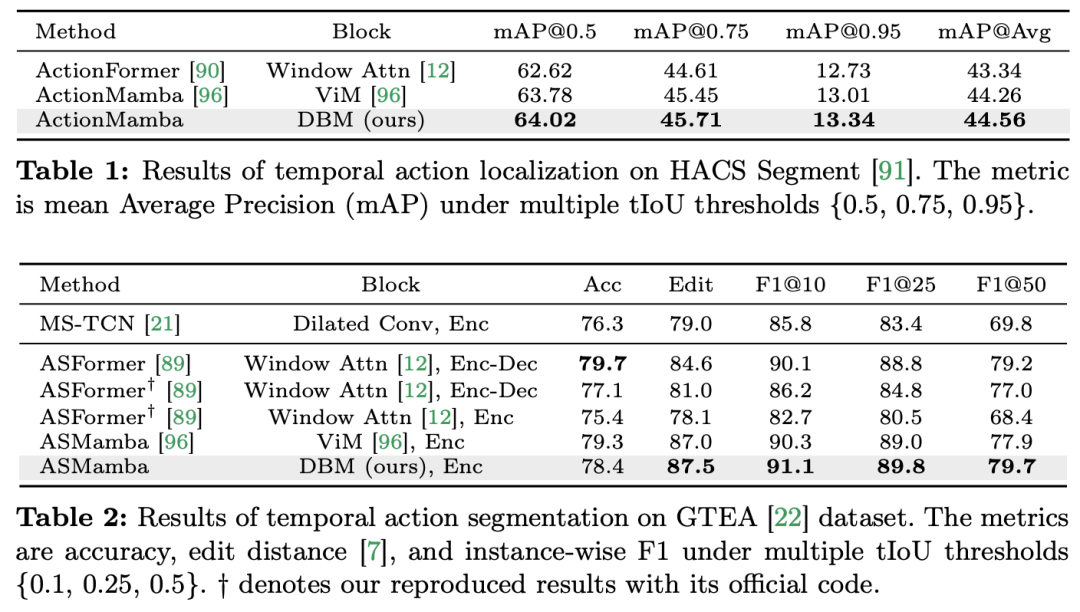
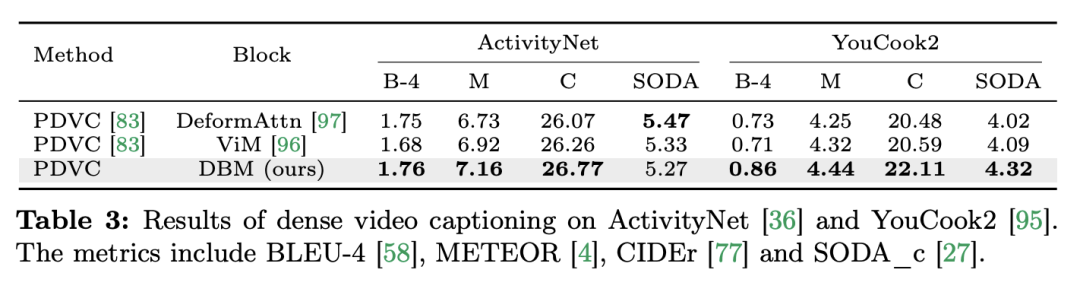
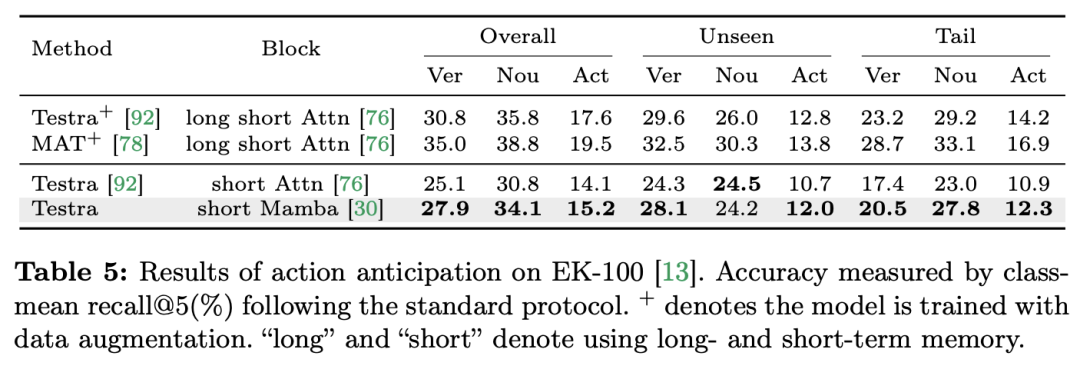
Mamba untuk interaksi multi-modal Pasukan penyelidik bukan sahaja menumpukan pada tugasan merentas mod tunggal, tetapi juga tugasan merentas interaksi mod tunggal, Kertas kerja menggunakan tugasan penyetempatan temporal video (VTG) untuk menilai prestasi Mamba. Set data yang diliputi termasuk QvHighlight dan Charade-STA. Tugas dan data: Pasukan penyelidik menilai prestasi Mamba pada lima tugas temporal video: penyetempatan tindakan temporal (Segmen HACS), segmentasi tindakan temporal (GTEA), sari kata video padat (ActivityNet, YouCook ), sari kata perenggan video (ActivityNet, YouCook) dan ramalan tindakan (Epic-Kitchen-100). Baseline dan Challenger: Pasukan penyelidik menggunakan UniVTG untuk membina model VTG berasaskan Mamba. UniVTG mengguna pakai Transformer sebagai rangkaian interaksi pelbagai mod. Memandangkan ciri video dan ciri teks, mereka mula-mula menambah benam lokasi yang boleh dipelajari dan benam jenis modaliti untuk setiap modaliti untuk mengekalkan maklumat lokasi dan modaliti. Token teks dan video kemudiannya digabungkan untuk membentuk input bersama yang selanjutnya dimasukkan ke dalam pengekod Transformer berbilang modal. Akhir sekali, ciri video ditambah teks diekstrak dan dimasukkan ke dalam kepala ramalan. Untuk mencipta pesaing Mamba rentas mod, pasukan penyelidik memilih untuk menyusun blok Mamba dwiarah untuk membentuk pengekod Mamda berbilang modal untuk menggantikan garis dasar Transformer. Keputusan dan Analisis: Kertas kerja ini menguji prestasi berbilang model melalui QvHighlight. Mamba mempunyai purata mAP 44.74, yang merupakan peningkatan yang ketara berbanding Transformer. Pada Charade-STA, kaedah berasaskan Mamba menunjukkan daya saing yang serupa dengan Transformer. Ini menunjukkan bahawa Mamba mempunyai potensi untuk mengintegrasikan pelbagai modaliti dengan berkesan. 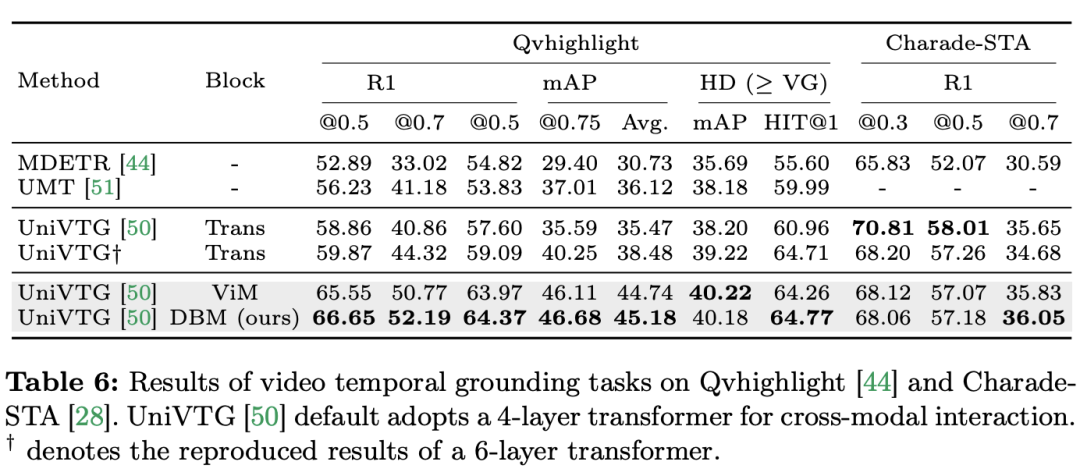
Memandangkan Mamba adalah model berdasarkan pengimbasan linear, manakala Transformer berdasarkan interaksi tanda global, pasukan penyelidik secara intuitif percaya bahawa kedudukan teks dalam urutan markah mungkin mempengaruhi kesan pengagregatan berbilang modal. Untuk menyiasat perkara ini, mereka memasukkan kaedah gabungan teks-visual yang berbeza dalam jadual dan menunjukkan empat susunan markah yang berbeza dalam rajah. Kesimpulannya ialah keputusan terbaik diperoleh apabila keadaan teks digabungkan dengan bahagian kiri ciri visual. QvHighlight mempunyai pengaruh yang kurang pada gabungan ini, manakala Charade-STA amat sensitif terhadap kedudukan teks, yang mungkin dikaitkan dengan ciri set data. 
Mamba sebagai penyesuai pemasaan video Di samping menilai prestasi Mamba dalam pemodelan pasca pemasaan, pasukan penyelidik juga mengkaji keberkesanannya sebagai penyesuai pemasaan video. Model Two Towers telah dilatih terlebih dahulu dengan melaksanakan pembelajaran kontrastif teks video pada data egosentrik, yang mengandungi 4 juta klip video dengan penceritaan yang terperinci. Tugas dan data: Pasukan penyelidik menilai prestasi Mamba pada lima tugas temporal video, termasuk: Penyetempatan Tindakan Temporal (Segmen HACS), Segmentasi Tindakan Temporal (GTEA), Sarikata Video Padat ( ActivityNet, YouCook), video sari kata perenggan (ActivityNet, YouCook) dan ramalan tindakan (Epic-Kitchen-100). Baseline dan Challenger: TimeSformer menggunakan blok perhatian spatiotemporal yang berasingan untuk memodelkan hubungan spatial dan temporal secara berasingan dalam video. Untuk tujuan ini, pasukan penyelidik memperkenalkan blok Mamba dwiarah sebagai penyesuai masa untuk menggantikan perhatian kendiri pemasaan asal dan meningkatkan interaksi spatiotemporal yang berasingan. Untuk perbandingan yang saksama, lapisan perhatian spatial dalam TimeSformer kekal tidak berubah. Di sini, pasukan penyelidik menggunakan blok ViM sebagai modul pemasaan dan memanggil model yang dihasilkan TimeMamba. Perlu diperhatikan bahawa blok ViM standard mempunyai lebih banyak parameter (lebih sedikit daripada 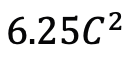 ) daripada blok perhatian diri, dengan C ialah dimensi ciri. Oleh itu, nisbah pengembangan E blok ViM ditetapkan kepada 1 dalam kertas, mengurangkan saiz parameternya kepada
) daripada blok perhatian diri, dengan C ialah dimensi ciri. Oleh itu, nisbah pengembangan E blok ViM ditetapkan kepada 1 dalam kertas, mengurangkan saiz parameternya kepada 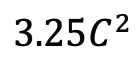 untuk perbandingan yang saksama. Sebagai tambahan kepada bentuk sambungan baki biasa yang digunakan oleh TimeSformer, pasukan penyelidik juga meneroka penyesuaian gaya Frozen. Berikut ialah 5 struktur penyesuai:
untuk perbandingan yang saksama. Sebagai tambahan kepada bentuk sambungan baki biasa yang digunakan oleh TimeSformer, pasukan penyelidik juga meneroka penyesuaian gaya Frozen. Berikut ialah 5 struktur penyesuai: 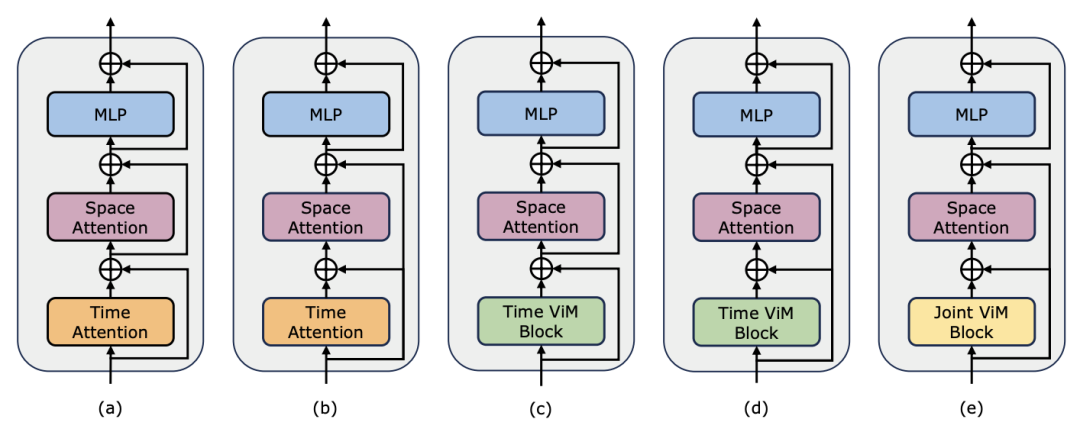
1. Pendapatan berbilang contoh sifar. Pasukan penyelidik mula-mula menilai model yang berbeza dengan interaksi spatiotemporal yang berasingan dalam jadual dan mendapati bahawa sambungan baki gaya Beku yang dihasilkan semula dalam kertas adalah konsisten dengan LaViLa. Apabila membandingkan gaya asal dan Frozen, tidak sukar untuk diperhatikan bahawa gaya Frozen sentiasa menghasilkan hasil yang lebih baik. Tambahan pula, di bawah kaedah penyesuaian yang sama, modul temporal berasaskan ViM sentiasa mengatasi modul temporal berasaskan perhatian. Perlu diperhatikan bahawa blok temporal ViM yang digunakan dalam kertas mempunyai parameter yang lebih sedikit daripada blok perhatian kendiri temporal, menyerlahkan penggunaan parameter yang lebih baik dan keupayaan pengekstrakan maklumat pengimbasan terpilih Mamba. Selain itu, pasukan penyelidik mengesahkan lagi blok ViM ruang masa. Blok ViM spatiotemporal menggantikan blok ViM temporal dengan pemodelan spatiotemporal bersama ke atas keseluruhan jujukan video. Yang menghairankan, walaupun terdapat pengenalan pemodelan global, blok ViM spatiotemporal sebenarnya mengakibatkan kemerosotan prestasi. Untuk tujuan ini, pasukan penyelidik membuat spekulasi bahawa spatio-temporal berasaskan imbasan boleh memusnahkan blok perhatian spatial yang telah terlatih untuk menghasilkan pengedaran ciri spatial. Berikut ialah keputusan percubaan: 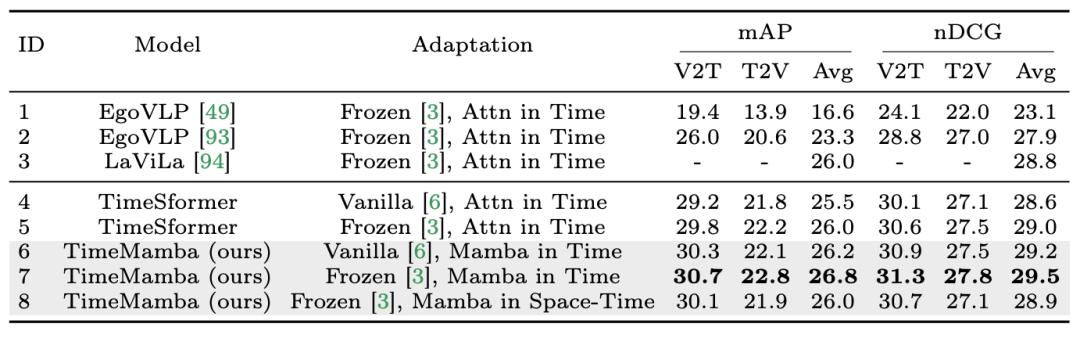
2. Penalaan halus pengambilan berbilang contoh dan pengecaman tindakan. Pasukan penyelidik terus menggunakan model pra-latihan yang diperhalusi 16 bingkai pada set data Epic-Kitchens-100 untuk mendapatkan semula berbilang contoh dan pengecaman tindakan. Daripada keputusan percubaan, TimeMamba dapat dilihat dengan ketara mengatasi TimeSformer dalam konteks pengecaman kata kerja, melebihi 2.8 mata peratusan, yang menunjukkan bahawa TimeMamba boleh memodelkan pemasaan yang terperinci dengan berkesan. 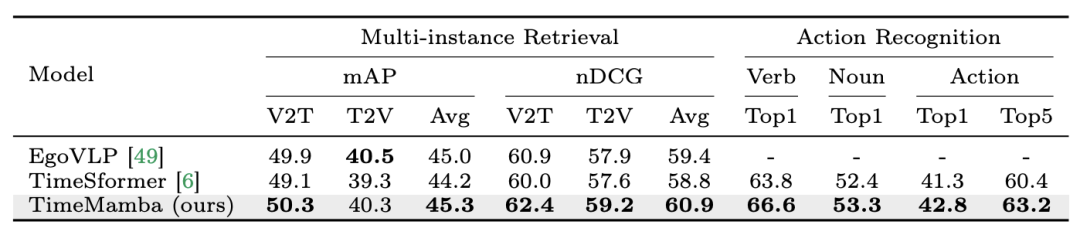
3. Sifar sampel video Soal Jawab. Pasukan penyelidik selanjutnya menilai prestasi Soal Jawab video panjang model pada set data EgoSchema. Berikut adalah keputusan percubaan: 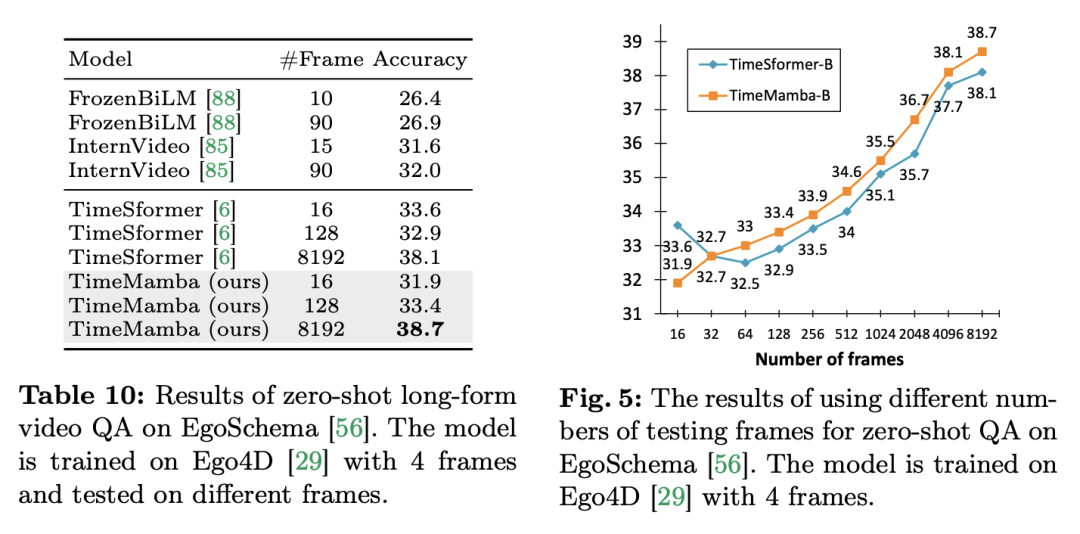
Kedua-dua TimeSformer dan TimeMamba, selepas pra-latihan pada Ego4D, melebihi prestasi model pra-latihan berskala besar (seperti InternVideo). Selain itu, pasukan penyelidik terus meningkatkan bilangan bingkai ujian bermula daripada video pada FPS tetap untuk meneroka kesan keupayaan pemodelan temporal video panjang blok ViM. Walaupun kedua-dua model dilatih dengan 4 bingkai, prestasi TimeMamba dan TimeSformer terus bertambah baik apabila bilangan bingkai bertambah. Sementara itu, peningkatan ketara dapat diperhatikan apabila menggunakan 8192 bingkai. Apabila bingkai input melebihi 32, TimeMamba secara amnya mendapat manfaat daripada lebih banyak bingkai daripada TimeSformer, menunjukkan keunggulan blok ViM Temporal dalam perhatian diri sementara. Mamba untuk pemodelan spatiotemporalTugas dan data: Di samping itu, kertas kerja ini juga menilai keupayaan model Mamba secara khusus dalam keupayaan masa dalam pengambilan sifar berbilang contoh dinilai pada 100 set data. Baseline dan Pesaing: ViViT dan TimeSformer mengkaji transformasi ViT dengan perhatian spatial menjadi model dengan perhatian spatial-temporal bersama. Berdasarkan ini, pasukan penyelidik mengembangkan lagi pengimbasan terpilih spatial model ViM untuk memasukkan pengimbasan terpilih spatiotemporal. Namakan model lanjutan ini ViViM. Pasukan penyelidik menggunakan model ViM yang dipralatih pada ImageNet-1K untuk pemula. Model ViM mengandungi token cls yang dimasukkan ke tengah-tengah jujukan token rata. Rajah di bawah menunjukkan cara menukar model ViM kepada ViViM. Untuk input tertentu yang mengandungi bingkai M, masukkan token cls di tengah-tengah jujukan token yang sepadan dengan setiap bingkai. Di samping itu, pasukan penyelidik menambah pembenaman kedudukan temporal, dimulakan kepada sifar untuk setiap bingkai. Urutan video yang diratakan kemudian dimasukkan ke dalam model ViViM. Output model diperoleh dengan mengira purata token cls untuk setiap bingkai. 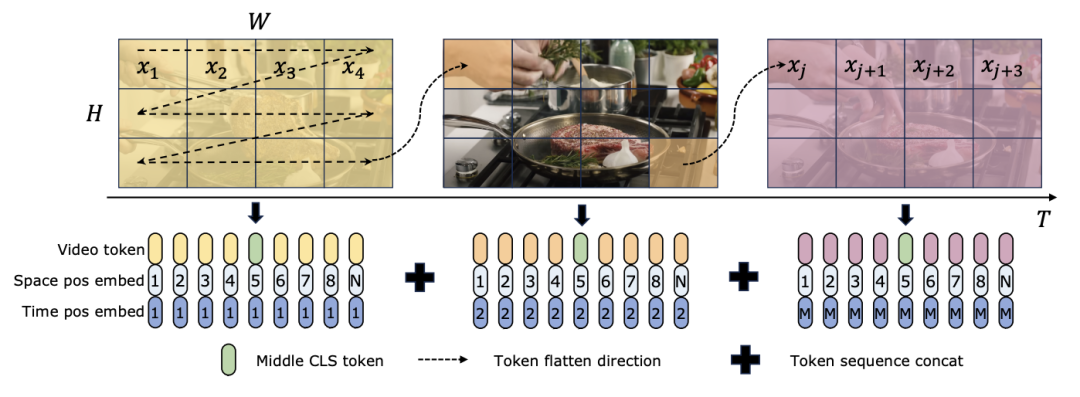
Keputusan dan Analisis: Kertas kerja mengkaji lebih lanjut keputusan ViViM dalam pengambilan berbilang contoh sifar Keputusan eksperimen ditunjukkan dalam jadual berikut: 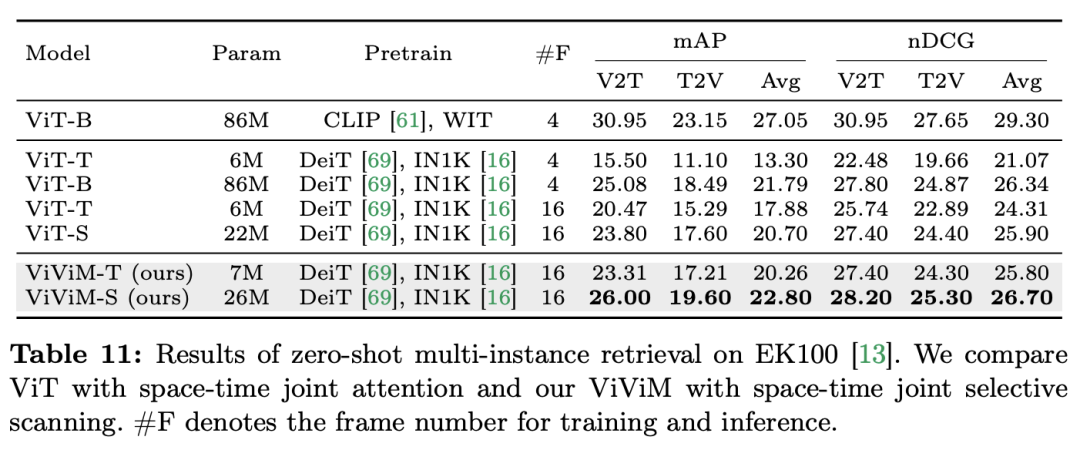
Keputusan menunjukkan bahawa berbeza. model temporal melakukan pengambilan berbilang contoh sifar Prestasi pada perolehan. Apabila membandingkan ViT dan ViViM, kedua-duanya dipralatih pada ImageNet-1K, dapat diperhatikan bahawa ViViM mengatasi prestasi ViT. Menariknya, walaupun jurang prestasi antara ViT-S dan ViM-S pada ImageNet-1K adalah kecil (79.8 vs 80.5), ViViM-S menunjukkan peningkatan ketara pada pengambilan berbilang contoh sifar tangkapan (+2.1 mAP @Avg), yang menunjukkan bahawa ViViM sangat berkesan dalam memodelkan urutan panjang, sekali gus meningkatkan prestasi. Kertas ini menunjukkan potensi Mamba sebagai alternatif yang berdaya maju kepada Transformers tradisional dengan menilai secara menyeluruh prestasinya dalam bidang pemahaman video. Melalui Video Mamba Suite, yang terdiri daripada 14 model/modul untuk 12 tugas pemahaman video, pasukan penyelidik menunjukkan keupayaan Mamba untuk mengendalikan dinamik spatiotemporal yang kompleks dengan cekap. Mamba bukan sahaja memberikan prestasi unggul, tetapi juga mencapai keseimbangan prestasi kecekapan yang lebih baik. Penemuan ini bukan sahaja menyerlahkan kesesuaian Mamba untuk tugasan analisis video, tetapi juga membuka jalan baharu untuk aplikasinya dalam bidang penglihatan komputer. Kerja masa depan boleh meneroka lebih lanjut kebolehsuaian Mamba dan memperluaskan utilitinya kepada cabaran pemahaman video multimodal yang lebih kompleks. Atas ialah kandungan terperinci Dalam 12 tugas pemahaman video, Mamba pertama kali mengalahkan Transformer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 Bina pelayan git anda sendiri
Bina pelayan git anda sendiri
 Perbezaan antara git dan svn
Perbezaan antara git dan svn
 git undo menyerahkan komit
git undo menyerahkan komit
 Formula pilih atur dan gabungan yang biasa digunakan
Formula pilih atur dan gabungan yang biasa digunakan
 Bagaimana untuk membatalkan ralat komit git
Bagaimana untuk membatalkan ralat komit git
 Bagaimana untuk membandingkan kandungan fail dua versi dalam git
Bagaimana untuk membandingkan kandungan fail dua versi dalam git
 Pengenalan kepada komponen laravel
Pengenalan kepada komponen laravel
 Nombor telefon mudah alih maya untuk menerima kod pengesahan
Nombor telefon mudah alih maya untuk menerima kod pengesahan








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



