


Berapa banyak pengetahuan manusia yang boleh disimpan oleh model bahasa skala 7B LLM? Bagaimana untuk mengukur nilai ini? Bagaimanakah perbezaan dalam masa latihan dan seni bina model akan mempengaruhi nilai ini? Apakah kesan pengkuantitian mampatan titik terapung, model pakar campuran MoE dan perbezaan kualiti data (pengetahuan ensiklopedia vs. sampah Internet) terhadap kapasiti pengetahuan LLM?
Penyelidikan terkini "Fizik Model Bahasa Bahagian 3.3: Menskala Undang-undang Pengetahuan" oleh Zhu Zeyuan (Meta AI) dan Li Yuanzhi (MBZUAI) menggunakan eksperimen besar-besaran (50,000 tugasan, sejumlah 4,200,000 jam GPU) , iaitu Kapasiti pengetahuan LLM di bawah fail yang berbeza menyediakan kaedah pengukuran yang lebih tepat.

Pengarang pertama kali menegaskan bahawa adalah tidak realistik untuk mengukur undang-undang penskalaan LLM dengan prestasi model sumber terbuka pada set data penanda aras (penanda aras). Sebagai contoh, LLaMA-70B berprestasi 30% lebih baik daripada LLaMA-7B pada set data pengetahuan Ini tidak bermakna mengembangkan model sebanyak 10 kali hanya boleh meningkatkan kapasiti sebanyak 30%. Jika model dilatih menggunakan data rangkaian, sukar juga untuk menganggarkan jumlah pengetahuan yang terkandung di dalamnya.
Untuk contoh lain, apabila kita membandingkan kualiti model Mistral dan Llama, adakah perbezaan itu disebabkan oleh seni bina model mereka yang berbeza, atau adakah ia disebabkan oleh penyediaan data latihan mereka yang berbeza?
Berdasarkan pertimbangan di atas, penulis mengguna pakai idea teras siri kertas "Fizik Model Bahasa" mereka, iaitu untuk mencipta data yang disintesis secara buatan dan mengawal ketat bit pengetahuan dalam data dengan mengawal jumlah dan jenis pengetahuan dalam data). Pada masa yang sama, pengarang menggunakan LLM dengan saiz dan seni bina yang berbeza untuk melatih data sintetik, dan memberikan takrifan matematik untuk mengira dengan tepat berapa banyak bit pengetahuan yang telah dipelajari oleh model terlatih daripada data tersebut. .

Pengarang mengkaji tiga jenis data sintetik: bioS, bioR, bioD. bioS ialah biografi yang ditulis menggunakan templat bahasa Inggeris, bioR ialah biografi yang ditulis dengan bantuan model LlaMA2 (jumlah 22GB), dan bioD ialah data pengetahuan maya yang boleh mengawal lebih lanjut butiran (contohnya, panjang dan perbendaharaan kata pengetahuan boleh dikawal Tunggu butiran). Pengarang
memfokuskan pada seni bina model bahasa berdasarkan GPT2, LlaMA dan Mistral, antaranya GPT2 menggunakan teknologi Rotary Position Embedding (RoPE) yang dikemas kini .
.
 Gambar kiri menunjukkan undang-undang skala dengan masa latihan yang mencukupi, dan gambar kanan menunjukkan undang-undang skala dengan masa latihan yang tidak mencukupi
Gambar kiri menunjukkan undang-undang skala dengan masa latihan yang mencukupi, dan gambar kanan menunjukkan undang-undang skala dengan masa latihan yang tidak mencukupi
Sekiranya masa latihan mencukupi, penulis mendapati tidak kira seni bina model mana yang digunakan, GPT2 atau LlaMA/Mistral, kecekapan penyimpanan model boleh mencapai 2bit/param - iaitu setiap parameter model boleh menyimpan 2 sedikit maklumat secara purata. Ini tiada kaitan dengan kedalaman model, hanya saiz model. Dalam erti kata lain, model 7B, jika dilatih dengan secukupnya, boleh menyimpan 14B bit pengetahuan, yang lebih daripada pengetahuan manusia dalam Wikipedia dan semua buku teks bahasa Inggeris digabungkan!
Apa yang lebih mengejutkan ialah walaupun teori tradisional percaya bahawa pengetahuan dalam model transformer terutamanya disimpan dalam lapisan MLP, kajian penulis menyangkal pandangan ini. Mereka mendapati bahawa walaupun semua lapisan MLP dialih keluar, model itu masih boleh mencapai 2bit/ Kecekapan penyimpanan param.
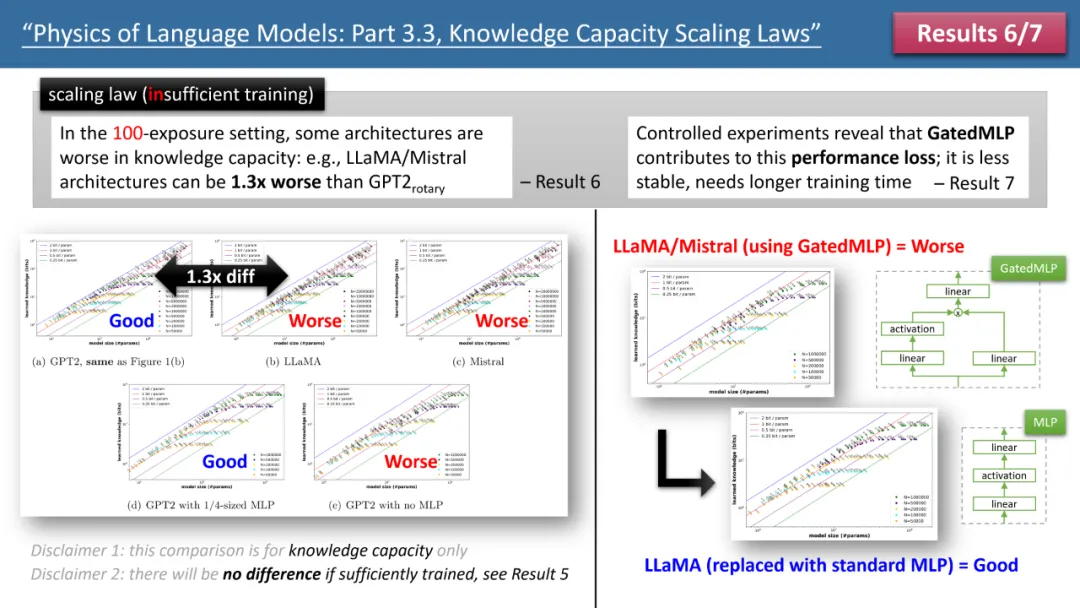
Rajah 2: Menskala undang-undang di bawah masa latihan yang tidak mencukupi
Walau bagaimanapun, apabila kita melihat kes masa latihan yang tidak mencukupi, perbezaan antara model menjadi jelas. Seperti yang ditunjukkan dalam Rajah 2 di atas, dalam kes ini, model GPT2 boleh menyimpan lebih daripada 30% lebih pengetahuan daripada LlaMA/Mistral, yang bermaksud bahawa model dari beberapa tahun lalu mengatasi model hari ini dalam beberapa aspek Kenapa ini terjadi? Pengarang membuat pelarasan seni bina pada model LlaMA, menambah atau menolak setiap perbezaan antara model dan GPT2, dan akhirnya mendapati bahawa GatedMLP menyebabkan kerugian 30%.
Untuk menekankan, GatedMLP tidak menyebabkan perubahan dalam kadar storan "akhir" model - kerana Rajah 1 memberitahu kita bahawa mereka tidak akan berbeza jika latihan mencukupi. Walau bagaimanapun, GatedMLP akan membawa kepada latihan yang tidak stabil, jadi pengetahuan yang sama memerlukan masa latihan yang lebih lama, dengan kata lain, untuk pengetahuan yang jarang muncul dalam set latihan, kecekapan penyimpanan model akan berkurangan. . 3 di atas. Satu keputusan ialah memampatkan model terlatih daripada float32/16 kepada int8 tidak mempunyai kesan ke atas storan pengetahuan, walaupun untuk model yang telah mencapai had storan 2bit/param.
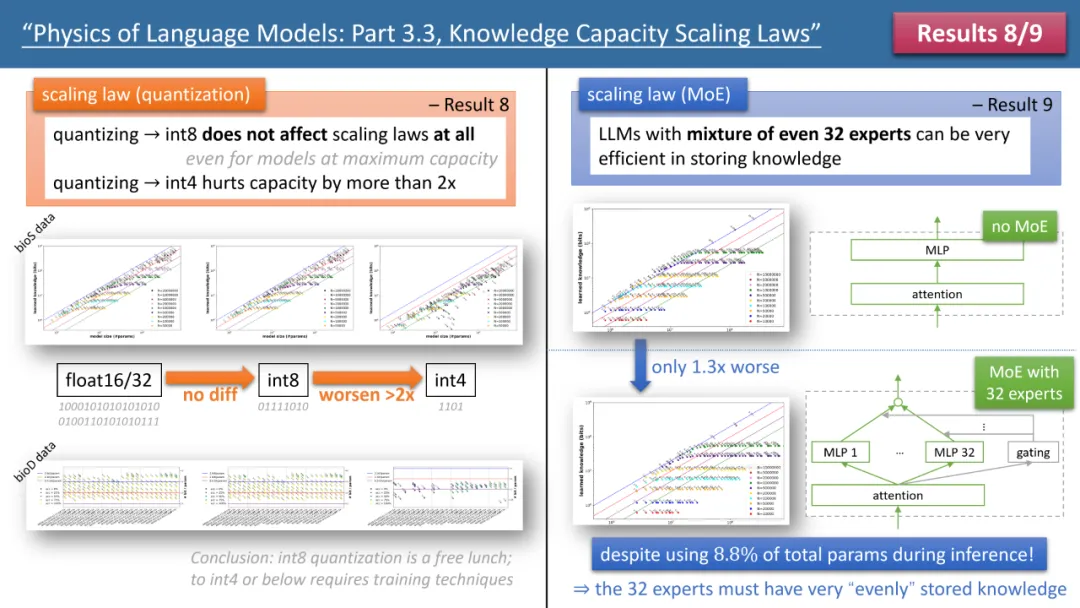 Ini bermakna LLM boleh mencapai 1/4 daripada "had teori maklumat" - kerana parameter int8 hanya 8 bit, tetapi secara purata setiap parameter boleh menyimpan 2 bit pengetahuan. Penulis menegaskan bahawa ini adalah undang-undang sejagat dan tidak ada kaitan dengan bentuk ungkapan pengetahuan.
Ini bermakna LLM boleh mencapai 1/4 daripada "had teori maklumat" - kerana parameter int8 hanya 8 bit, tetapi secara purata setiap parameter boleh menyimpan 2 bit pengetahuan. Penulis menegaskan bahawa ini adalah undang-undang sejagat dan tidak ada kaitan dengan bentuk ungkapan pengetahuan.
Hasil yang paling menarik datang daripada undang-undang pengarang 10-12 (lihat Rajah 4). Jika data (pra-) latihan kami, 1/8 datang daripada pangkalan pengetahuan berkualiti tinggi (seperti Ensiklopedia Baidu), dan 7/8 datang daripada data berkualiti rendah (seperti rangkak biasa atau perbualan forum, atau malah sampah rawak sepenuhnya data).
Jadi,
adakah data berkualiti rendah menjejaskan penyerapan pengetahuan berkualiti tinggi LLM? Hasilnya mengejutkan. Walaupun masa latihan untuk data berkualiti tinggi kekal konsisten, "kewujudan sendiri" data berkualiti rendah mungkin mengurangkan penyimpanan pengetahuan berkualiti tinggi model sebanyak 20 kali! Walaupun masa latihan pada data berkualiti tinggi dilanjutkan sebanyak 3 kali, rizab pengetahuan masih akan dikurangkan sebanyak 3 kali. Ini seperti membuang emas ke dalam pasir, dan data berkualiti tinggi dibazirkan.
Adakah ada cara untuk memperbaikinya? Penulis mencadangkan strategi yang mudah tetapi sangat berkesan, yang hanya menambah token nama domain tapak web anda sendiri pada semua data latihan (pra). Contohnya, tambahkan semua data Wikipedia pada wikipedia.org. Model ini tidak memerlukan sebarang pengetahuan terdahulu untuk mengenal pasti tapak web mana yang mempunyai pengetahuan "emas", tetapi boleh secara automatik menemui tapak web dengan pengetahuan berkualiti tinggi semasa proses pra-latihan, dan
secara automatikmengosongkan ruang storan untuk kualiti tinggi ini data . Pengarang mencadangkan percubaan mudah untuk mengesahkan: jika data berkualiti tinggi ditambah dengan token khas (sebarang token khas akan berjaya, model tidak perlu mengetahui token mana itu terlebih dahulu), maka pengetahuan model storan boleh meningkat dengan serta-merta 10 kali ganda, bukankah ia menakjubkan? Oleh itu, menambah token nama domain pada data pra-latihan ialah operasi penyediaan data yang sangat penting. . model dilatih Kaedah jumlah pengetahuan yang diperoleh dalam proses boleh menyediakan sistem pemarkahan yang sistematik dan tepat untuk "menilai seni bina model, kaedah latihan dan penyediaan data". Ini berbeza sama sekali daripada perbandingan penanda aras tradisional dan lebih dipercayai. Mereka berharap ini akan membantu pereka LLM masa hadapan membuat keputusan yang lebih termaklum.
Atas ialah kandungan terperinci Adakah seni bina Llama lebih rendah daripada GPT2? Token ajaib meningkatkan ingatan 10 kali ganda?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Bagaimana untuk membuka fail zip
Bagaimana untuk membuka fail zip
 Kad kedua telefon bimbit
Kad kedua telefon bimbit
 python mengkonfigurasi pembolehubah persekitaran
python mengkonfigurasi pembolehubah persekitaran
 Windows 11 pemindahan komputer saya ke tutorial desktop
Windows 11 pemindahan komputer saya ke tutorial desktop
 Apakah maksud konteks?
Apakah maksud konteks?
 Kaedah pembaikan ralat Kernelutil.dll
Kaedah pembaikan ralat Kernelutil.dll
 Langkah-langkah penyimpanan penyulitan data
Langkah-langkah penyimpanan penyulitan data








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



