


Untuk dikatakan sebagai syarikat yang paling menyedihkan baru-baru ini, Google pastinya salah satu daripadanya: miliknya Gemini 1.5 baru sahaja dikeluarkan, dan ia telah dicuri oleh Sora OpenAI, yang boleh dipanggil "Wang Feng" dalam industri AI.
Secara khusus, apa yang dilancarkan oleh Google kali ini ialah versi pertama Gemini 1.5 untuk ujian awal - Gemini 1.5 Pro. Ia ialah model berbilang mod bersaiz sederhana (merentasi teks, video, audio) dengan tahap prestasi yang serupa dengan model terbesar Google setakat ini, 1.0 Ultra, dan memperkenalkan ciri percubaan yang tercanggih dalam pemahaman konteks panjang. Ia boleh mengendalikan sehingga 1 juta token secara stabil (bersamaan dengan 1 jam video, 11 jam audio, lebih daripada 30,000 baris kod, atau 700,000 perkataan), dengan had 10 juta token (bersamaan dengan "Lord of the Rings" " trilogi), Tetapkan rekod untuk tetingkap konteks terpanjang.
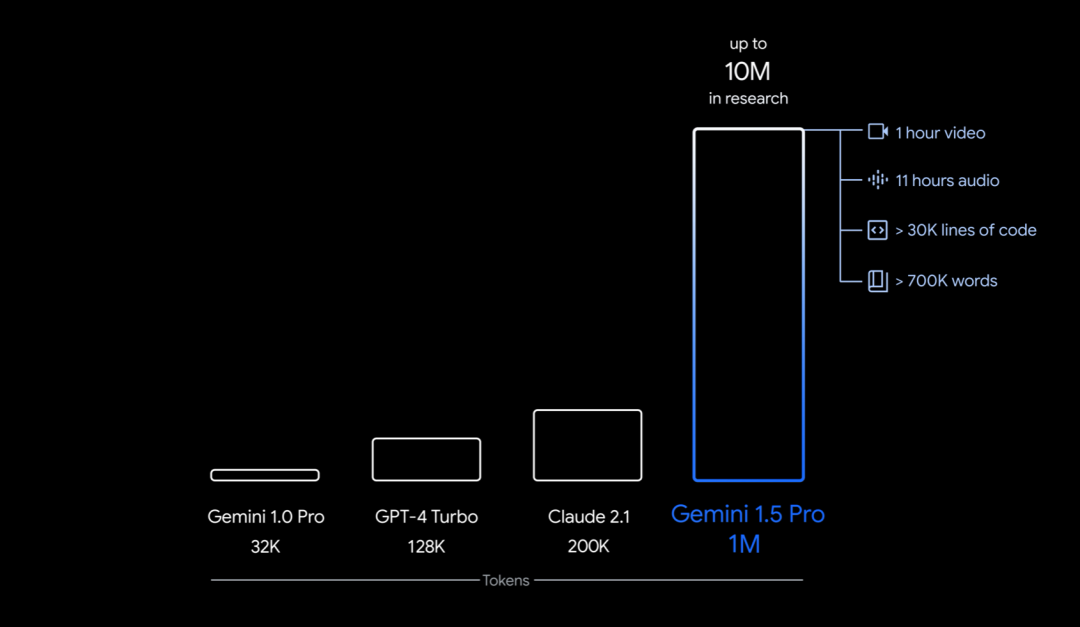
Selain itu, ia juga boleh mempelajari terjemahan bahasa kecil dengan hanya buku tatabahasa 500 muka surat, 2000 entri dwibahasa dan 400 ayat selari tambahan (tiada maklumat yang berkaitan di Internet), Mencapai tahap hampir dengan pelajar manusia dalam terjemahan.
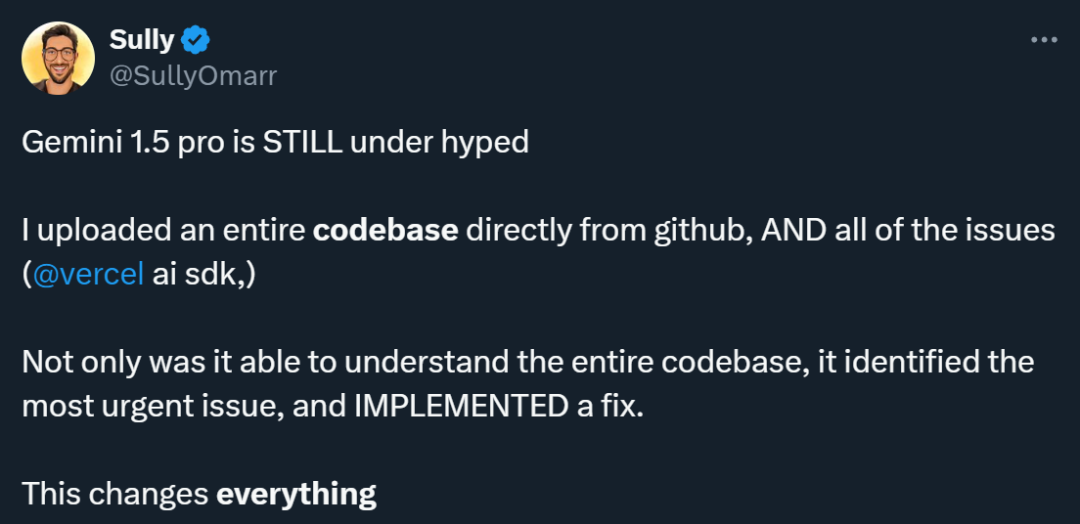
Ramai orang yang telah menggunakan Gemini 1.5 Pro berpendapat model ini dipandang rendah. Seseorang menjalankan percubaan dan memasukkan pangkalan kod lengkap yang dimuat turun daripada Github dan isu berkaitan ke dalam Gemini 1.5 Pro Hasilnya mengejutkan: bukan sahaja ia memahami keseluruhan pangkalan kod, tetapi ia juga dapat mengenal pasti isu yang paling mendesak dan membetulkannya. .
Dalam ujian berkaitan kod lain, Gemini 1.5 Pro menunjukkan keupayaan carian yang sangat baik, dapat mencari contoh yang paling relevan dalam pangkalan kod dengan cepat. Selain itu, ia menunjukkan pemahaman yang kukuh dan dapat mencari kod yang mengawal animasi dengan tepat dan memberikan cadangan kod yang diperibadikan. Begitu juga, Gemini 1.5 Pro juga menunjukkan keupayaan rentas mod yang sangat baik, dapat menentukan kandungan demo melalui tangkapan skrin dan menyediakan panduan untuk mengedit kod imej.

Model sebegini harus menarik perhatian semua orang. Selain itu, perlu diperhatikan bahawa keupayaan Gemini 1.5 Pro untuk mengendalikan konteks ultra panjang juga telah membuatkan ramai penyelidik mula berfikir, adakah kaedah RAG tradisional masih diperlukan?
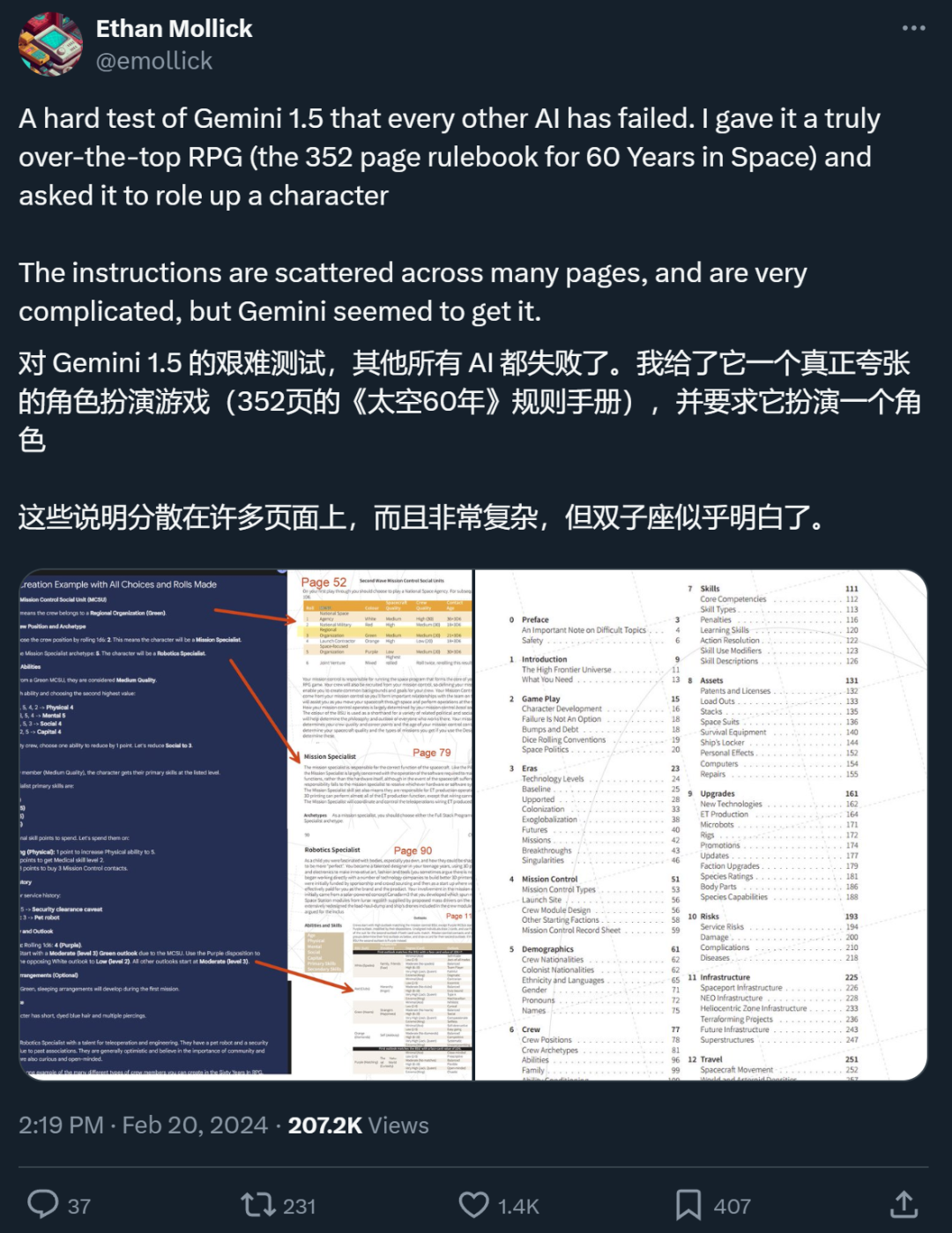
Seorang netizen X berkata bahawa dalam ujian yang dijalankannya, Gemini 1.5 Pro, yang menyokong konteks ultra-panjang, melakukan perkara yang tidak dapat dilakukan oleh RAG.
"Model dengan tetingkap konteks token 10 juta menjadikan kebanyakan rangka kerja RAG sedia ada tidak diperlukan, iaitu, 10 juta konteks token membunuh RAG," Fu Yao, seorang pelajar PhD di Universiti Edinburgh menulis dalam catatan menyemak Gemini 1.5 Pro.

RAG ialah singkatan daripada "Retrieval-Augmented Generation", yang boleh diterjemahkan sebagai "Retrieval Enhanced Generation" dalam bahasa Cina. RAG biasanya terdiri daripada dua peringkat: mendapatkan semula maklumat berkaitan konteks dan menggunakan pengetahuan yang diperoleh untuk membimbing proses penjanaan. Sebagai contoh, sebagai pekerja, anda boleh bertanya secara langsung kepada model besar, "Apakah hukuman untuk kelewatan dalam syarikat kami Tanpa membaca "Buku Panduan Pekerja", model besar itu tidak mempunyai cara untuk menjawab. Walau bagaimanapun, dengan bantuan kaedah RAG, kami boleh terlebih dahulu membenarkan model carian mencari jawapan yang paling berkaitan dalam "Buku Panduan Pekerja", dan kemudian menghantar soalan anda dan jawapan berkaitan yang ditemuinya kepada model penjanaan, membenarkan model besar untuk menjana Jawapan. Ini menyelesaikan masalah bahawa tetingkap konteks banyak model besar sebelumnya tidak cukup besar (contohnya, ia tidak dapat memuatkan "Buku Panduan Pekerja"), tetapi RAGfangfa kurang dalam menangkap hubungan halus antara konteks.
Fu Yao percaya bahawa jika model boleh memproses maklumat kontekstual 10 juta token secara langsung, tidak perlu melalui langkah-langkah perolehan tambahan untuk mencari dan menyepadukan maklumat yang berkaitan. Pengguna boleh meletakkan semua data yang mereka perlukan terus ke dalam model sebagai konteks dan kemudian berinteraksi dengan model seperti biasa. "Model bahasa yang besar itu sendiri sudah menjadi pencari yang sangat berkuasa, jadi mengapa perlu bersusah payah membina pencari yang lemah dan menghabiskan banyak tenaga kejuruteraan untuk memotong, membenam, mengindeks, dan lain-lain?"

Walau bagaimanapun, pandangan Fu Yao telah disangkal oleh ramai penyelidik. Dia berkata bahawa banyak bantahan adalah munasabah, dan dia juga menyusun pendapat ini secara sistematik:
1. Isu kos: Pengkritik menegaskan bahawa RAG lebih murah daripada model konteks panjang. Fu Yao mengakui perkara ini, tetapi dia membandingkan sejarah pembangunan teknologi yang berbeza, menunjukkan bahawa walaupun model kos rendah (seperti BERT-kecil atau n-gram) sememangnya murah, dalam sejarah pembangunan AI, kos teknologi canggih akhirnya akan berkurangan. Maksudnya adalah untuk mengejar prestasi model pintar terlebih dahulu, dan kemudian mengurangkan kos melalui kemajuan teknologi, kerana lebih mudah untuk menjadikan model pintar murah daripada menjadikan model murah pintar.
2. Penyepaduan pengambilan semula dan penaakulan: Fu Yao menekankan bahawa model konteks panjang mampu mencampurkan perolehan semula dan penaakulan sepanjang proses penyahkodan, manakala RAG hanya melakukan pencarian semula pada permulaan. Model konteks panjang boleh diambil pada setiap lapisan dan setiap token, yang bermaksud bahawa model boleh menentukan secara dinamik maklumat yang akan diambil berdasarkan keputusan inferens awal, mencapai penyepaduan pengambilan dan inferens yang lebih rapat.
3 Bilangan token yang disokong: Walaupun bilangan token yang disokong oleh RAG telah mencapai tahap trilion, dan model konteks panjang kini menyokong tahap juta, Fu Yao percaya bahawa dalam dokumen input yang diedarkan secara semula jadi, kebanyakannya memerlukan. Keadaan carian semuanya di bawah paras juta. Beliau memetik analisis dokumen undang-undang dan pembelajaran mesin pembelajaran sebagai contoh, dan percaya bahawa jumlah input dalam kes ini tidak akan melebihi berjuta-juta.

4. Mekanisme caching: Berkenaan masalah yang model konteks panjang memerlukan memasukkan semula keseluruhan dokumen, Fu Yao menegaskan bahawa terdapat mekanisme caching KV (nilai utama), yang boleh mereka bentuk hierarki cache dan memori yang kompleks untuk membuat input Ia hanya perlu dibaca sekali dan pertanyaan seterusnya boleh menggunakan semula cache KV. Beliau juga menyebut bahawa walaupun cache KV boleh menjadi besar, beliau optimis bahawa algoritma pemampatan cache KV yang cekap akan muncul pada masa hadapan.
5. Keperluan untuk menghubungi enjin carian: Dia mengakui bahawa dalam jangka pendek, memanggil enjin carian untuk mendapatkan semula masih diperlukan. Walau bagaimanapun, beliau mencadangkan idea yang berani, iaitu membenarkan model bahasa mengakses terus keseluruhan indeks carian Google untuk menyerap semua maklumat, yang mencerminkan imaginasi hebat tentang potensi masa depan teknologi AI.
6 Isu prestasi: Fu Yao mengakui bahawa Gemini 1.5 semasa adalah perlahan apabila memproses konteks 1M, tetapi dia optimis tentang peningkatan kelajuan dan percaya bahawa kelajuan model konteks panjang akan dipertingkatkan dengan ketara pada masa hadapan, dan akhirnya boleh mencapai tahap yang sama dengan kelajuan RAG.

Selain Fu Yao, ramai penyelidik lain juga telah menyatakan pandangan mereka tentang prospek RAG di platform X, seperti blogger AI @elvis.
Secara umum, dia tidak fikir model konteks panjang boleh menggantikan RAG Sebabnya termasuk:
1 Cabaran jenis data tertentu: @elvis mencadangkan senario di mana data mempunyai struktur yang kompleks dan berubah dengan kerap, dan mempunyai dimensi masa yang penting (seperti suntingan/perubahan kod dan log web). Jenis data ini mungkin disambungkan ke titik data sejarah dan mungkin lebih banyak titik data pada masa hadapan. @elvis percaya bahawa model bahasa konteks panjang hari ini sahaja tidak boleh mengendalikan kes penggunaan yang bergantung pada data sedemikian kerana data mungkin terlalu kompleks untuk LLM dan tetingkap konteks maksimum semasa tidak boleh dilaksanakan untuk data tersebut. Apabila berurusan dengan data seperti ini, anda mungkin memerlukan beberapa mekanisme pengambilan semula yang bijak.
2 Pemprosesan maklumat dinamik: LLM konteks panjang hari ini berprestasi baik dalam memproses maklumat statik (seperti buku, rakaman video, PDF, dsb.), tetapi belum lagi diuji dalam amalan apabila melibatkan pemprosesan yang sangat dinamik. maklumat dan pengetahuan. @elvis percaya bahawa walaupun kami akan membuat kemajuan ke arah menyelesaikan beberapa cabaran (seperti "hilang di tengah-tengah") dan menangani data berstruktur dan dinamik yang lebih kompleks, kami masih mempunyai perjalanan yang jauh.

3. @elvis mencadangkan agar untuk menyelesaikan jenis masalah ini, RAG dan konteks panjang LLM boleh digabungkan untuk membina sistem berkuasa yang boleh mendapatkan dan menganalisis maklumat sejarah penting dengan berkesan dan cekap. Beliau menegaskan bahawa walaupun ini mungkin tidak mencukupi dalam banyak kes. Terutama kerana sejumlah besar data boleh berubah dengan cepat, ejen berasaskan AI menambah lebih kerumitan. @elvis berpendapat bahawa untuk kes penggunaan yang kompleks, kemungkinan besar ia akan menjadi gabungan idea ini dan bukannya tujuan umum atau konteks panjang LLM yang menggantikan segala-galanya.
4. Permintaan untuk pelbagai jenis LLM: @elvis menegaskan bahawa tidak semua data adalah statik, dan banyak data adalah dinamik. Apabila mempertimbangkan aplikasi ini, ingatlah tiga Vs data besar: halaju, volum dan kepelbagaian. @elvis mempelajari pelajaran ini melalui pengalaman bekerja di syarikat carian. Beliau percaya bahawa pelbagai jenis LLM akan membantu menyelesaikan pelbagai jenis masalah, dan kita perlu beralih daripada idea bahawa satu LLM akan menguasai kesemuanya. . habis. RAG sebenarnya mempunyai beberapa ciri yang sangat bagus. Bukan sahaja sifat ini boleh dipertingkatkan oleh model konteks panjang, tetapi model konteks panjang juga boleh dipertingkatkan oleh RAG. RAG membolehkan kami mencari maklumat yang berkaitan, tetapi cara model mengakses maklumat ini mungkin menjadi terlalu terhad disebabkan oleh pemampatan data. Model konteks panjang boleh membantu merapatkan jurang ini, agak serupa dengan cara cache L1/L2 dan memori utama berfungsi bersama dalam CPU moden. Dalam model kolaboratif ini, cache dan memori utama masing-masing memainkan peranan yang berbeza tetapi saling melengkapi, dengan itu meningkatkan kelajuan dan kecekapan pemprosesan. Begitu juga, penggunaan gabungan RAG dan konteks yang panjang boleh mencapai perolehan dan penjanaan maklumat yang lebih fleksibel dan cekap, menggunakan sepenuhnya kelebihan masing-masing untuk mengendalikan data dan tugas yang kompleks.

Nampaknya "sama ada era RAG akan berakhir" masih belum diputuskan. Tetapi ramai orang mengatakan bahawa Gemini 1.5 Pro benar-benar dipandang rendah sebagai model tetingkap konteks yang lebih panjang. @elvis juga memberikan keputusan ujiannya.

Gemini 1.5 Pro Laporan Penilaian Awal Analisis Dokumen Keupayaan Analisis Dokumen Menunjukkan keupayaan Gemini 1.5 Pro untuk memproses dan menganalisis dokumen, @elvis bermula dengan tugas menjawab soalan yang sangat asas. Dia memuat naik fail PDF dan bertanya soalan mudah: Apakah kertas ini?
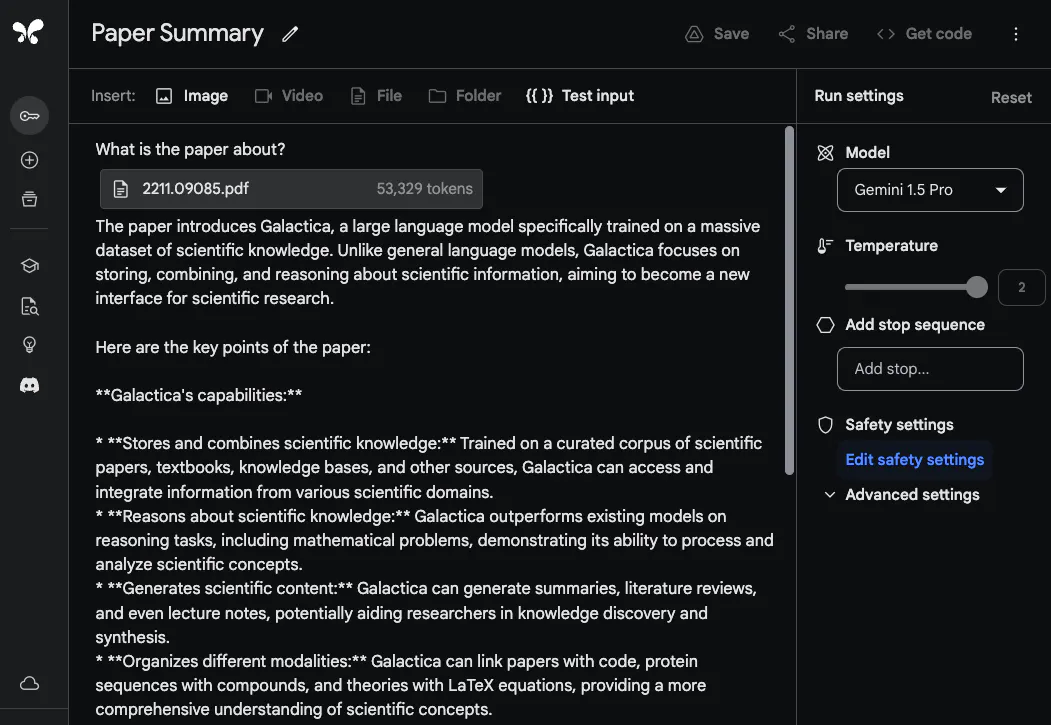
Respons model adalah tepat dan ringkas kerana ia menyediakan ringkasan kertas Galactica yang boleh diterima. Contoh di atas menggunakan gesaan bentuk bebas dalam Google AI Studio, tetapi anda juga boleh menggunakan format sembang untuk berinteraksi dengan PDF yang dimuat naik. Ini adalah ciri yang sangat berguna jika anda mempunyai banyak soalan yang anda ingin jawab daripada dokumentasi yang disediakan.
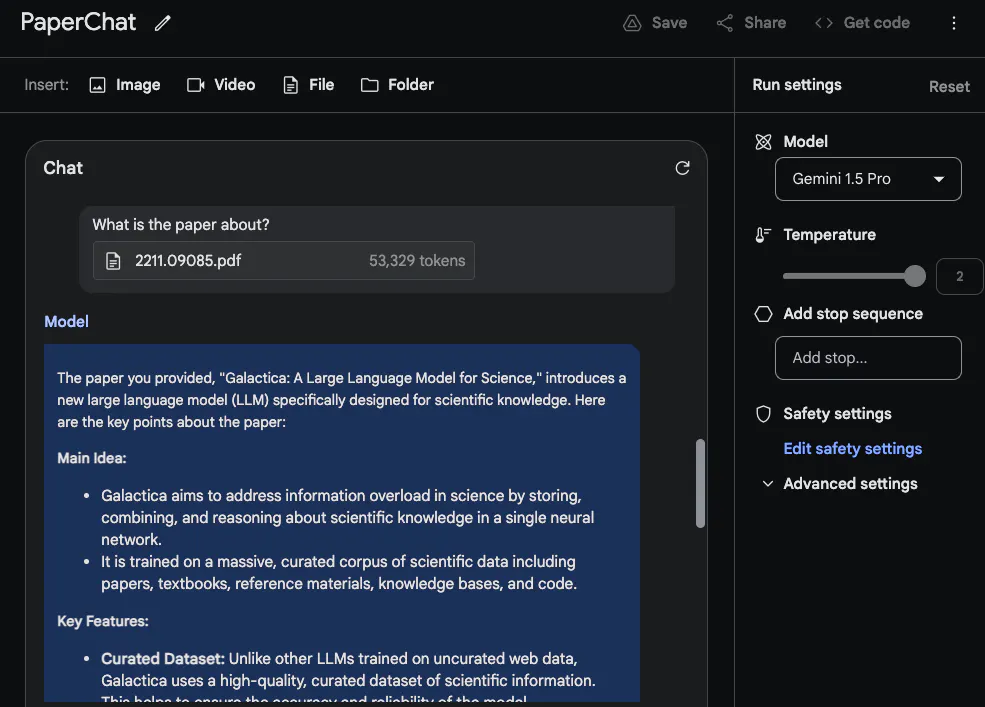
Untuk memanfaatkan sepenuhnya tetingkap konteks yang panjang, @elvis seterusnya memuat naik dua PDF untuk ujian dan bertanya soalan yang merangkumi kedua-dua PDF. Maklum balas yang diberikan oleh
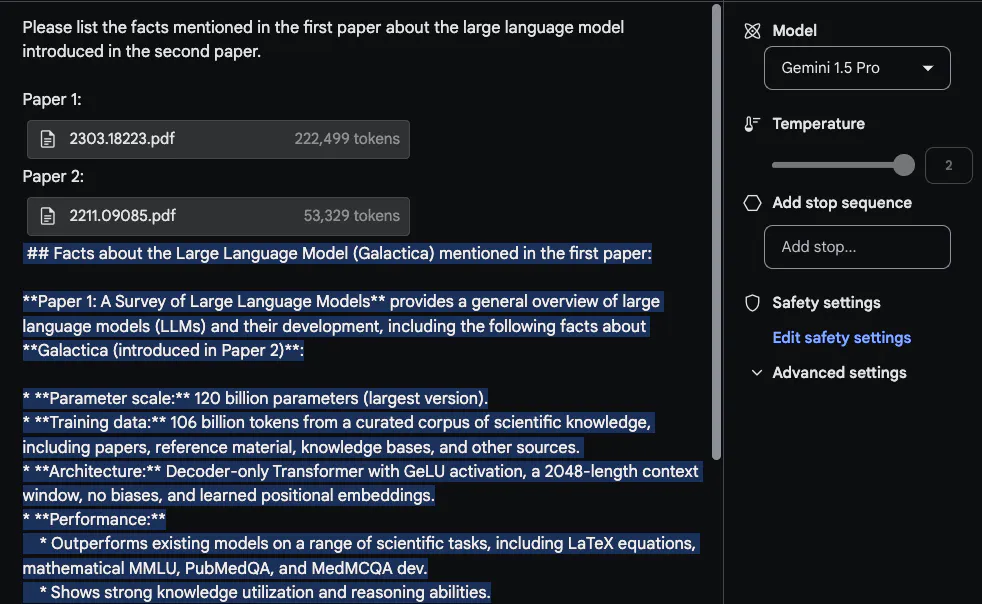
Gemini 1.5 Pro adalah munasabah. Menariknya, maklumat yang diekstrak daripada kertas pertama (kertas ulasan tentang LLM) datang daripada jadual. Maklumat "seni bina" juga kelihatan betul. Walau bagaimanapun, bahagian "Prestasi" tidak tergolong dalam bahagian ini kerana ia tidak disertakan dalam kertas pertama. Dalam tugasan ini, adalah penting untuk meletakkan gesaan "Sila senaraikan fakta yang disebut dalam kertas pertama tentang model bahasa besar yang diperkenalkan dalam kertas kedua" di bahagian atas dan labelkan kertas itu, seperti "Kertas 1" dan "Kertas 2 ". Satu lagi tugas susulan yang berkaitan dengan makmal ini ialah menulis kerja berkaitan dengan memuat naik satu set kertas dan arahan tentang cara meringkaskannya. Satu lagi tugas yang menarik meminta model itu memasukkan kertas LLM yang lebih baharu dalam semakan.
Pemahaman Video
Gemini 1.5 Pro dilatih mengenai data berbilang modal dari awal. @elvis menguji beberapa gesaan menggunakan video kuliah LLM Andrej Karpathy baru-baru ini:
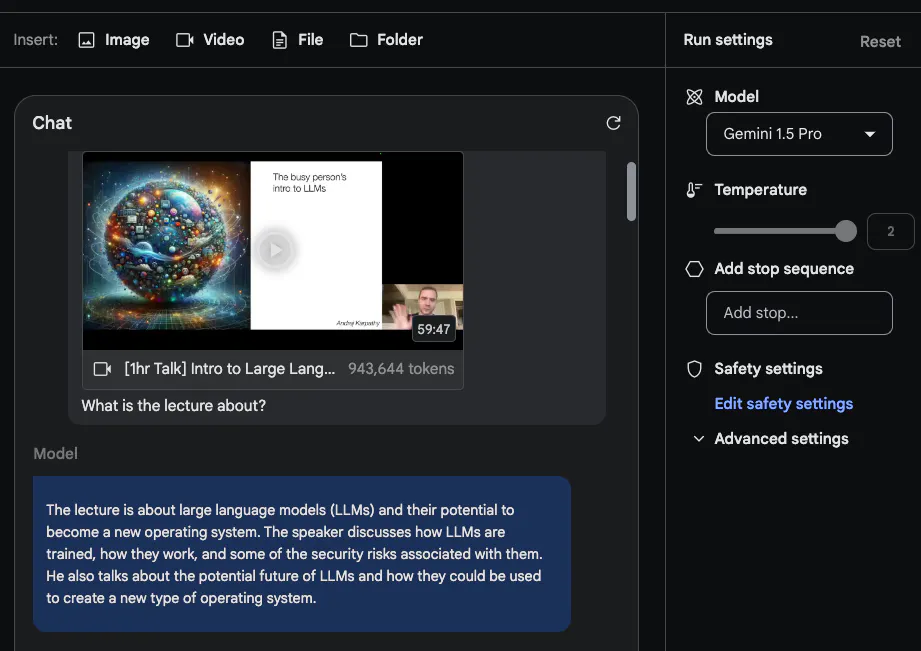
Tugas kedua yang dia minta model itu selesaikan ialah menyediakan rangka kuliah yang ringkas dan padat (sepanjang satu halaman). Jawapannya adalah seperti berikut (diedit untuk ringkas):

Ringkasan yang diberikan oleh Gemini 1.5 Pro sangat padat dan meringkaskan kandungan kuliah dan perkara utama dengan baik.
Apabila butiran khusus penting, sila ambil perhatian bahawa model kadangkala mungkin "halusinasi" atau mendapatkan maklumat yang salah atas pelbagai sebab. Sebagai contoh, apabila model ditanya soalan berikut: "Apakah FLOP yang dilaporkan untuk Llama 2 dalam kuliah?", jawapannya ialah "Kuliah melaporkan bahawa latihan Llama 2 70B memerlukan lebih kurang 1 trilion FLOP", yang tidak tepat . Jawapan yang betul mestilah "~1e24 FLOPs". Laporan teknikal itu mengandungi banyak contoh di mana model konteks panjang ini tersandung apabila ditanya soalan khusus tentang video.
Tugas seterusnya ialah mengekstrak maklumat jadual daripada video. Keputusan ujian menunjukkan bahawa model ini mampu menjana jadual dengan beberapa butiran betul dan beberapa tidak betul. Sebagai contoh, lajur jadual adalah betul, tetapi label untuk salah satu baris adalah salah (iaitu Resolusi Konsep hendaklah Resolusi Coref). Penguji menguji beberapa tugas pengekstrakan ini dengan jadual lain dan elemen lain yang berbeza (seperti kotak teks) dan mendapati ketidakkonsistenan yang serupa.
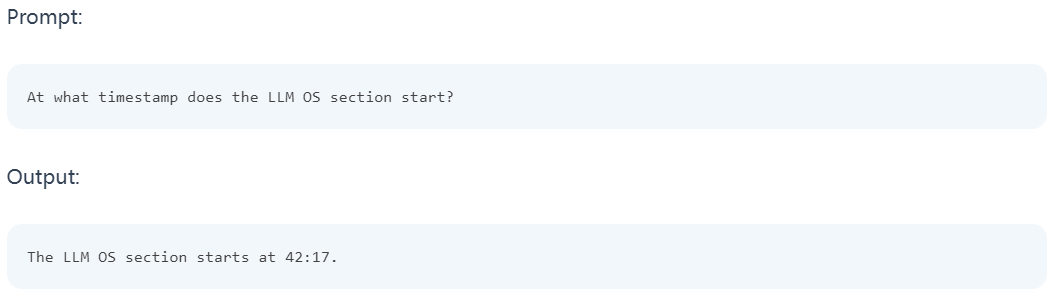
Contoh menarik yang didokumenkan dalam laporan teknikal ialah keupayaan model untuk mendapatkan butiran daripada video berdasarkan adegan atau cap masa tertentu. Dalam contoh pertama, penguji bertanya model di mana bahagian tertentu bermula. Model itu menjawab dengan betul.
Dalam contoh seterusnya, dia meminta model menerangkan graf dalam slaid. Model ini nampaknya menggunakan maklumat yang diberikan dengan baik untuk menerangkan keputusan dalam graf.

Di bawah ialah petikan tayangan slaid yang sepadan:
@elvis berkata bahawa dia telah memulakan ujian pusingan kedua, dan pelajar yang berminat boleh pergi ke platform X untuk menonton.
Atas ialah kandungan terperinci Tetingkap konteks 10M Google membunuh RAG? Adakah Gemini dipandang rendah selepas dicuri daripada perhatian oleh Sora?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



