


Pengurangan dimensi merujuk kepada mengekalkan maklumat utama data sebanyak mungkin sambil mengurangkan bilangan ciri dalam set data. Algoritma pengurangan dimensi ialah pembelajaran tanpa pengawasan, dan algoritma dilatih melalui data tidak berlabel.

Walaupun terdapat banyak jenis kaedah pengurangan dimensi, semuanya boleh dikelaskan kepada dua kategori utama: linear dan bukan linear.
Kaedah linear menayangkan data secara linear daripada ruang berdimensi tinggi kepada ruang berdimensi rendah (oleh itu dinamakan unjuran linear). Contohnya termasuk PCA dan LDA.
Kaedah tak linear ialah cara untuk melakukan pengurangan dimensi tak linear, selalunya digunakan untuk menemui struktur tak linear data asal. Kaedah pengurangan dimensi bukan linear amat penting apabila data asal tidak mudah dipisahkan secara linear. Dalam sesetengah kes, pengurangan dimensi tak linear juga dikenali sebagai pembelajaran manifold Kaedah ini boleh mengendalikan data berdimensi tinggi dengan lebih cekap dan membantu mendedahkan struktur asas data. Melalui pengurangan dimensi tak linear, kami dapat memahami dengan lebih baik hubungan antara data, menemui corak dan peraturan tersembunyi dalam data, dan memberikan sokongan padu untuk analisis dan aplikasi data selanjutnya.
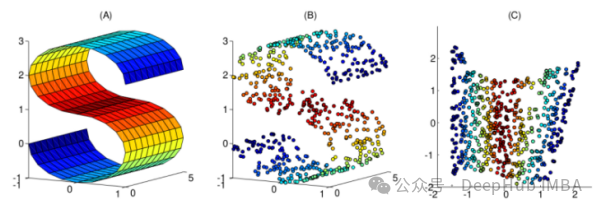
Artikel ini telah menyusun 10 teknik pengurangan dimensi tak linear yang biasa digunakan untuk membantu anda memilih dalam kerja harian anda
Kedua-dua analisis komponen utama dan analisis komponen utama kernel boleh digunakan untuk pengurangan dimensi, tetapi PCA kernel lebih berkesan dalam memproses data yang tidak boleh dipisahkan secara linear. Kelebihan utama kernel PCA adalah untuk mengubah data tidak boleh dipisahkan secara linear kepada data boleh dipisahkan secara linear sambil mengurangkan dimensi data. Kernel PCA boleh menangkap struktur tak linear dalam data dengan memperkenalkan teknik kernel, dengan itu meningkatkan prestasi klasifikasi data. Oleh itu, kernel PCA mempunyai kebolehan ekspresif dan generalisasi yang lebih kukuh apabila berurusan dengan set data yang kompleks.
Kami mula-mula mencipta data yang sangat klasik:
import matplotlib.pyplot as plt plt.figure(figsize=[7, 5]) from sklearn.datasets import make_moons X, y = make_moons(n_samples=100, noise=None, random_state=0) plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='plasma') plt.title('Linearly inseparable data')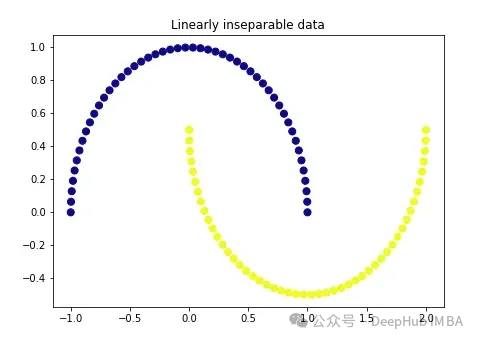 Dua warna ini mewakili dua kategori yang tidak boleh dipisahkan secara linear. Adalah mustahil untuk melukis garis lurus di sini untuk memisahkan kedua-dua kategori ini.
Dua warna ini mewakili dua kategori yang tidak boleh dipisahkan secara linear. Adalah mustahil untuk melukis garis lurus di sini untuk memisahkan kedua-dua kategori ini.
Kami bermula dengan PCA biasa.
import numpy as np from sklearn.decomposition import PCA pca = PCA(n_components=1) X_pca = pca.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(X_pca[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('First component after linear PCA') plt.xlabel('PC1')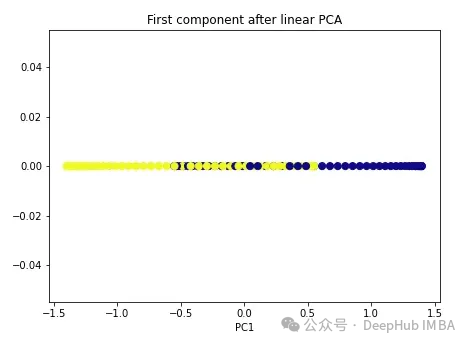 Seperti yang anda lihat, kedua-dua kelas ini masih tidak boleh dipisahkan secara linear, sekarang mari cuba PCA kernel.
Seperti yang anda lihat, kedua-dua kelas ini masih tidak boleh dipisahkan secara linear, sekarang mari cuba PCA kernel.
import numpy as np from sklearn.decomposition import KernelPCA kpca = KernelPCA(n_components=1, kernel='rbf', gamma=15) X_kpca = kpca.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(X_kpca[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.axvline(x=0.0, linestyle='dashed', color='black', linewidth=1.2) plt.title('First component after kernel PCA') plt.xlabel('PC1')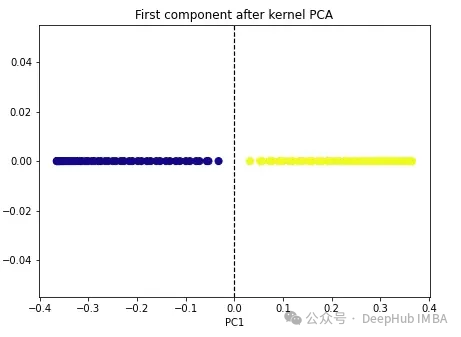 Kedua-dua kelas menjadi boleh dipisahkan secara linear, dan algoritma PCA kernel menggunakan kernel yang berbeza untuk mengubah data dari satu bentuk ke bentuk yang lain. Kernel PCA ialah proses dua langkah. Pertama, fungsi kernel menayangkan sementara data asal ke dalam ruang dimensi tinggi, di mana kelas boleh dipisahkan secara linear. Algoritma kemudian menayangkan data ini kembali ke dimensi yang lebih rendah yang dinyatakan dalam hiperparameter n_components (bilangan dimensi yang ingin kita simpan).
Kedua-dua kelas menjadi boleh dipisahkan secara linear, dan algoritma PCA kernel menggunakan kernel yang berbeza untuk mengubah data dari satu bentuk ke bentuk yang lain. Kernel PCA ialah proses dua langkah. Pertama, fungsi kernel menayangkan sementara data asal ke dalam ruang dimensi tinggi, di mana kelas boleh dipisahkan secara linear. Algoritma kemudian menayangkan data ini kembali ke dimensi yang lebih rendah yang dinyatakan dalam hiperparameter n_components (bilangan dimensi yang ingin kita simpan).
Terdapat empat pilihan kernel dalam sklearn: linear', 'poly', 'rbf' dan 'sigmoid'. Jika kita menentukan kernel sebagai "linear", PCA biasa akan dilakukan. Sebarang kernel lain akan melaksanakan PCA tak linear. Kernel rbf (fungsi asas jejari) adalah yang paling biasa digunakan.
2. Penskalaan berbilang dimensi (MDS)
Untuk melakukan ini dalam Scikit-lear kita boleh menggunakan kelas MDS().
from sklearn.manifold import MDS mds = MDS(n_components, metric) mds_transformed = mds.fit_transform(X)
Kami menggunakan dua jenis algoritma MDS pada data tak linear berikut.
import numpy as np from sklearn.manifold import MDS mds = MDS(n_components=1, metric=True) # Metric MDS X_mds = mds.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(X_mds[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('Metric MDS') plt.xlabel('Component 1')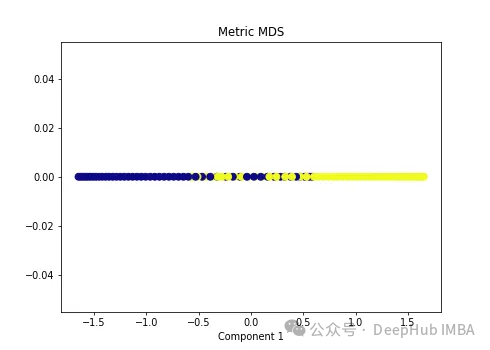
import numpy as np from sklearn.manifold import MDS mds = MDS(n_components=1, metric=False) # Non-metric MDS X_mds = mds.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(X_mds[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('Non-metric MDS') plt.xlabel('Component 1')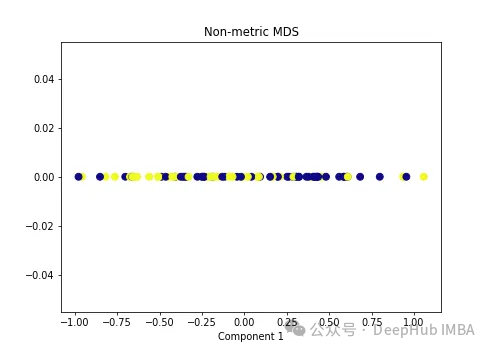
可以看到MDS后都不能使数据线性可分,所以可以说MDS不适合我们这个经典的数据集。
Isomap(Isometric Mapping)在保持数据点之间的地理距离,即在原始高维空间中的测地线距离或者近似的测地线距离,在低维空间中也被保持。Isomap的基本思想是通过在高维空间中计算数据点之间的测地线距离(通过最短路径算法,比如Dijkstra算法),然后在低维空间中保持这些距离来进行降维。在这个过程中,Isomap利用了流形假设,即假设高维数据分布在一个低维流形上。因此,Isomap通常在处理非线性数据集时表现良好,尤其是当数据集包含曲线和流形结构时。
import matplotlib.pyplot as plt plt.figure(figsize=[7, 5]) from sklearn.datasets import make_moons X, y = make_moons(n_samples=100, noise=None, random_state=0) import numpy as np from sklearn.manifold import Isomap isomap = Isomap(n_neighbors=5, n_components=1) X_isomap = isomap.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(X_isomap[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('First component after applying Isomap') plt.xlabel('Component 1')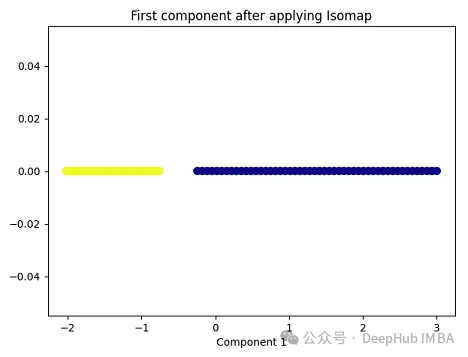
就像核PCA一样,这两个类在应用Isomap后是线性可分的!
与Isomap类似,LLE也是基于流形假设,即假设高维数据分布在一个低维流形上。LLE的主要思想是在局部邻域内保持数据点之间的线性关系,并在低维空间中重构这些关系。
from sklearn.manifold import LocallyLinearEmbedding lle = LocallyLinearEmbedding(n_neighbors=5,n_components=1) lle_transformed = lle.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(lle_transformed[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('First component after applying LocallyLinearEmbedding') plt.xlabel('Component 1')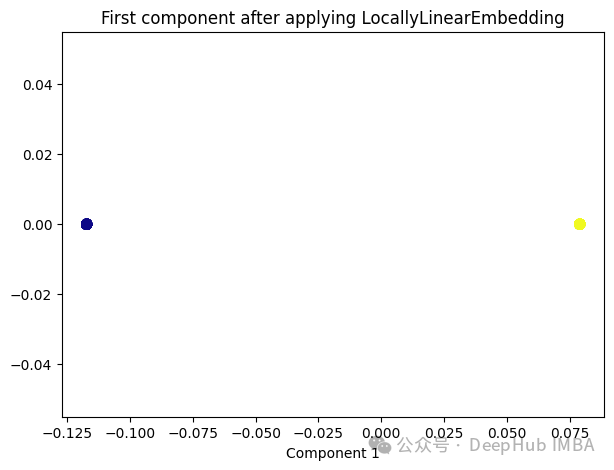
只有2个点,其实并不是这样,我们打印下这个数据
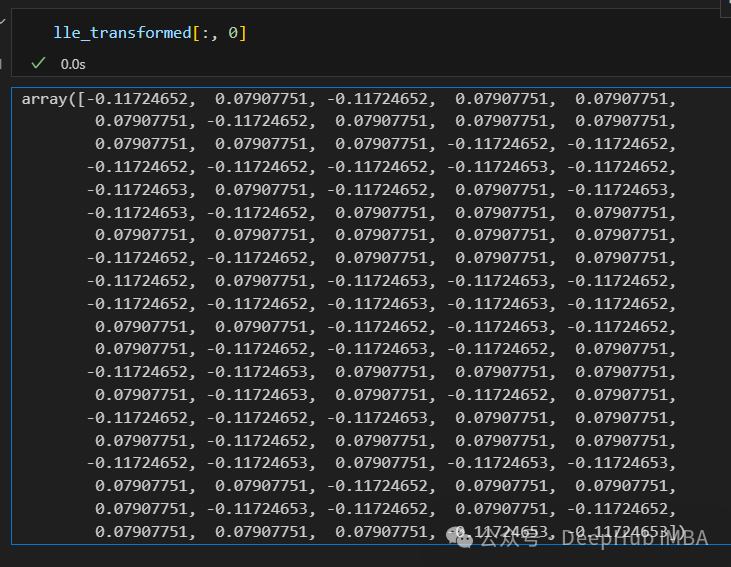
可以看到数据通过降维变成了同一个数字,所以LLE降维后是线性可分的,但是却丢失了数据的信息。
Spectral Embedding是一种基于图论和谱理论的降维技术,通常用于将高维数据映射到低维空间。它的核心思想是利用数据的相似性结构,将数据点表示为图的节点,并通过图的谱分解来获取低维表示。
from sklearn.manifold import SpectralEmbedding sp_emb = SpectralEmbedding(n_components=1, affinity='nearest_neighbors') sp_emb_transformed = sp_emb.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(sp_emb_transformed[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('First component after applying SpectralEmbedding') plt.xlabel('Component 1')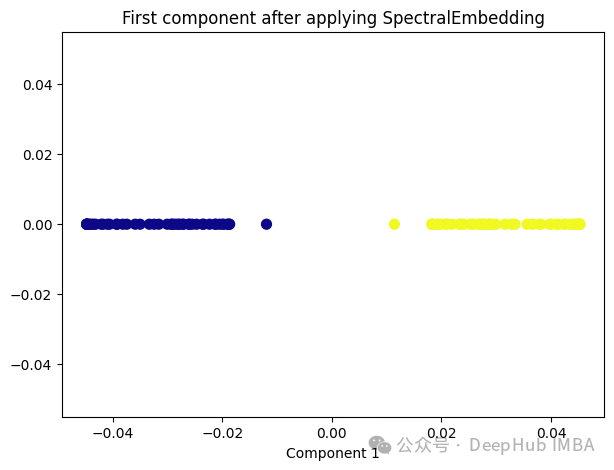
t-SNE的主要目标是保持数据点之间的局部相似性关系,并在低维空间中保持这些关系,同时试图保持全局结构。
from sklearn.manifold import TSNE tsne = TSNE(1, learning_rate='auto', init='pca') tsne_transformed = tsne.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(tsne_transformed[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('First component after applying TSNE') plt.xlabel('Component 1')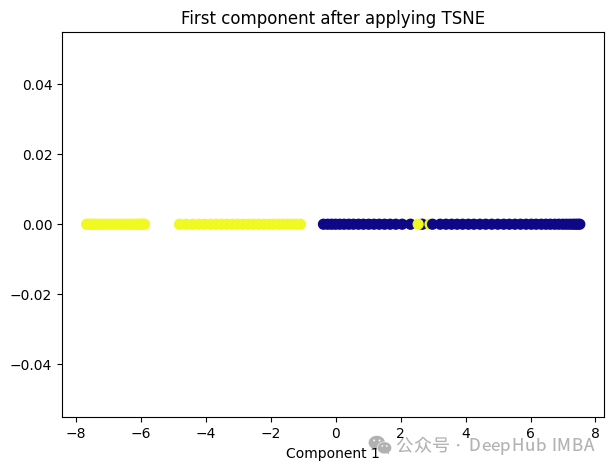
t-SNE好像也不太适合我们的数据。
Random Trees Embedding是一种基于树的降维技术,常用于将高维数据映射到低维空间。它利用了随机森林(Random Forest)的思想,通过构建多棵随机决策树来实现降维。
Random Trees Embedding的基本工作流程:
Random Trees Embedding的优势在于它的计算效率高,特别是对于大规模数据集。由于使用了随机森林的思想,它能够很好地处理高维数据,并且不需要太多的调参过程。
RandomTreesEmbedding使用高维稀疏进行无监督转换,也就是说,我们最终得到的数据并不是一个连续的数值,而是稀疏的表示。所以这里就不进行代码展示了,有兴趣的看看sklearn的sklearn.ensemble.RandomTreesEmbedding
Dictionary Learning是一种用于降维和特征提取的技术,它主要用于处理高维数据。它的目标是学习一个字典,该字典由一组原子(或基向量)组成,这些原子是数据的线性组合。通过学习这样的字典,可以将高维数据表示为一个更紧凑的低维空间中的稀疏线性组合。
Dictionary Learning的优点之一是它能够学习出具有可解释性的原子,这些原子可以提供关于数据结构和特征的重要见解。此外,Dictionary Learning还可以产生稀疏表示,从而提供更紧凑的数据表示,有助于降低存储成本和计算复杂度。
from sklearn.decomposition import DictionaryLearning dict_lr = DictionaryLearning(n_components=1) dict_lr_transformed = dict_lr.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(dict_lr_transformed[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('First component after applying DictionaryLearning') plt.xlabel('Component 1')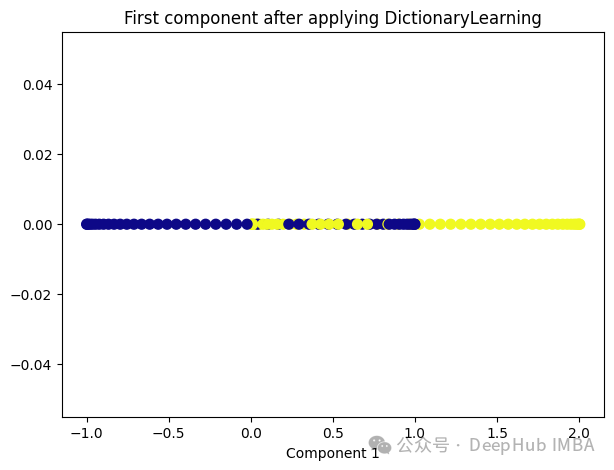
Independent Component Analysis (ICA) 是一种用于盲源分离的统计方法,通常用于从混合信号中估计原始信号。在机器学习和信号处理领域,ICA经常用于解决以下问题:
ICA的基本假设是,混合信号中的各个成分是相互独立的,即它们的统计特性是独立的。这与主成分分析(PCA)不同,PCA假设成分之间是正交的,而不是独立的。因此ICA通常比PCA更适用于发现非高斯分布的独立成分。
from sklearn.decomposition import FastICA ica = FastICA(n_components=1, whiten='unit-variance') ica_transformed = dict_lr.fit_transform(X) plt.figure(figsize=[7, 5]) plt.scatter(ica_transformed[:, 0], np.zeros((100,1)), c=y, s=50, cmap='plasma') plt.title('First component after applying FastICA') plt.xlabel('Component 1')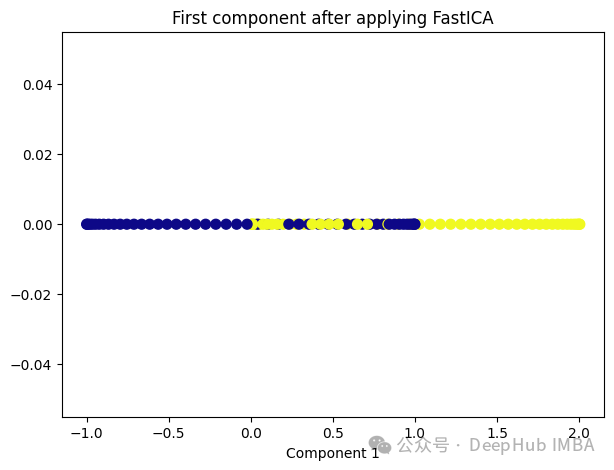
到目前为止,我们讨论的NLDR技术属于通用机器学习算法的范畴。而自编码器是一种基于神经网络的NLDR技术,可以很好地处理大型非线性数据。当数据集较小时,自动编码器的效果可能不是很好。
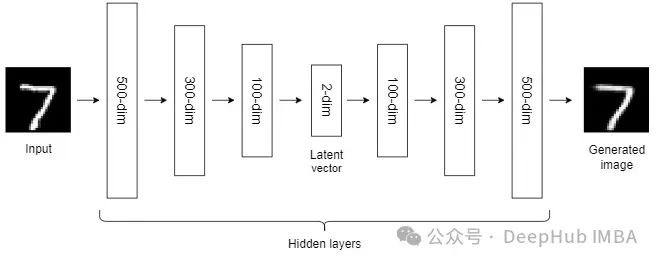
自编码器我们已经介绍过很多次了,所以这里就不详细说明了。
非线性降维技术是一类用于将高维数据映射到低维空间的方法,它们通常适用于数据具有非线性结构的情况。
大多数NLDR方法基于最近邻方法,该方法要求数据中所有特征的尺度相同,所以如果特征的尺度不同,还需要进行缩放。
另外这些非线性降维技术在不同的数据集和任务中可能表现出不同的性能,因此在选择合适的方法时需要考虑数据的特征、降维的目标以及计算资源等因素。
Atas ialah kandungan terperinci Ringkasan perbandingan sepuluh teknik pengurangan dimensi tak linear dalam pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah format fail mkv?
Apakah format fail mkv?
 Penggunaan tali serut
Penggunaan tali serut
 Adakah java front-end atau back-end?
Adakah java front-end atau back-end?
 Apa yang salah dengan telefon bimbit saya yang boleh membuat panggilan tetapi tidak melayari Internet?
Apa yang salah dengan telefon bimbit saya yang boleh membuat panggilan tetapi tidak melayari Internet?
 Sebab jadual excel tidak boleh dibuka
Sebab jadual excel tidak boleh dibuka
 Bagaimana untuk menyediakan VPS selamat
Bagaimana untuk menyediakan VPS selamat
 Bagaimana untuk memasukkan video dalam html
Bagaimana untuk memasukkan video dalam html
 kaedah tampalan naik taraf win10
kaedah tampalan naik taraf win10








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



