


Walaupun model bahasa visual (VLM) telah mencapai kemajuan yang ketara dalam banyak tugas, termasuk penerangan imej, jawapan soalan visual, perancangan yang terkandung dan pengecaman tindakan, cabaran masih wujud dalam penaakulan spatial. Banyak model masih menghadapi kesukaran memahami lokasi atau perhubungan ruang sasaran dalam ruang tiga dimensi. Ini menunjukkan bahawa dalam proses membangunkan lagi model bahasa visual, adalah perlu untuk menumpukan pada penyelesaian masalah penaakulan spatial untuk meningkatkan ketepatan dan kecekapan model dalam memproses tugas visual yang kompleks.
Para penyelidik sering meneroka isu ini melalui pengalaman fizikal manusia dan perkembangan evolusi. Manusia mempunyai kemahiran penaakulan spatial semula jadi yang membolehkan mereka dengan mudah menentukan hubungan ruang, seperti kedudukan relatif objek, dan menganggar jarak dan saiz, tanpa memerlukan proses pemikiran yang kompleks atau pengiraan mental.
Kecekapan dalam tugas penaakulan spatial langsung ini berbeza dengan batasan keupayaan model bahasa visual semasa dan menimbulkan persoalan kajian yang menarik: sama ada model bahasa visual boleh dikurniakan keupayaan penaakulan spatial seperti manusia?
Baru-baru ini, Google mencadangkan model bahasa visual dengan keupayaan penaakulan spatial: SpatialVLM.

Sebaliknya, penyelidikan ini memfokuskan pada mengekstrak maklumat spatial secara langsung menggunakan data dunia sebenar untuk menunjukkan kepelbagaian dan kerumitan dunia 3D sebenar. Kaedah ini diilhamkan oleh teknologi pemodelan visual terkini dan secara automatik boleh menjana anotasi spatial 3D daripada imej 2D.
Fungsi utama sistem SpatialVLM ialah memproses data dunia sebenar beranotasi padat berskala besar menggunakan teknologi seperti pengesanan objek, anggaran kedalaman, pembahagian semantik dan model penerangan pusat objek untuk meningkatkan keupayaan penaakulan ruang model bahasa visual . Sistem SpatialVLM mencapai matlamat penjanaan data dan latihan model bahasa visual dengan menukar data yang dijana oleh model visual kepada format data hibrid yang boleh digunakan untuk penerangan, VQA dan penaakulan spatial. Usaha penyelidik telah membolehkan sistem ini memahami dan memproses maklumat visual dengan lebih baik, dengan itu meningkatkan prestasinya dalam tugas penaakulan spatial yang kompleks. Pendekatan ini membantu melatih model bahasa visual untuk lebih memahami dan memproses perhubungan antara imej dan teks, dengan itu meningkatkan ketepatan dan kecekapannya dalam pelbagai tugas visual.
Penyelidikan menunjukkan bahawa model bahasa visual yang dicadangkan dalam artikel ini mempamerkan keupayaan yang memuaskan dalam pelbagai bidang. Pertama, ia menunjukkan peningkatan yang ketara dalam mengendalikan masalah spatial kualitatif. Kedua, model ini mampu menghasilkan anggaran kuantitatif dengan pasti walaupun dengan kehadiran bunyi dalam data latihan. Keupayaan ini bukan sahaja melengkapkannya dengan pengetahuan akal tentang saiz sasaran, tetapi juga menjadikannya berguna dalam mengendalikan tugas penyusunan semula dan anotasi ganjaran perbendaharaan kata terbuka. Akhir sekali, digabungkan dengan model bahasa berskala besar yang berkuasa, model bahasa visual spatial boleh melaksanakan rantaian penaakulan spatial dan menyelesaikan tugasan penaakulan spatial yang kompleks berdasarkan antara muka bahasa semula jadi.
Untuk melengkapkan model bahasa visual dengan keupayaan penaakulan spatial kualitatif dan kuantitatif, para penyelidik mencadangkan untuk menjana set data VQA spatial berskala besar untuk melatih model bahasa visual. Khususnya, ia adalah untuk mereka bentuk rangka kerja penjanaan data yang komprehensif yang pertama kali menggunakan model penglihatan komputer di luar rak, termasuk pengesanan kosa kata terbuka, anggaran kedalaman metrik, segmentasi semantik dan model penerangan berpusatkan sasaran, untuk mengekstrak maklumat latar belakang berpusatkan sasaran, A pendekatan berasaskan templat kemudiannya diguna pakai untuk menjana data VQA spatial berskala besar dengan kualiti yang munasabah. Dalam makalah ini, penyelidik menggunakan set data yang dijana untuk melatih SpatialVLM untuk mempelajari keupayaan penaakulan spatial langsung, dan kemudian menggabungkannya dengan penaakulan akal budi peringkat tinggi yang tertanam dalam LLM untuk membuka kunci penaakulan spatial pemikiran rantai. .

1. Penapisan semantik: Dalam proses sintesis data artikel ini, langkah pertama ialah menggunakan model klasifikasi perbendaharaan kata terbuka berasaskan CLIP untuk mengklasifikasikan semua imej dan mengecualikan imej yang tidak sesuai.
2. Pengekstrakan imej 2D latar belakang berpusatkan sasaran: Langkah ini memperoleh entiti berpusat sasaran yang terdiri daripada gugusan piksel dan perihalan perbendaharaan kata terbuka.3. Maklumat latar belakang 2D kepada maklumat latar belakang 3D: Selepas anggaran kedalaman, piksel 2D mata tunggal dinaik taraf kepada awan titik 3D skala metrik. Makalah ini adalah yang pertama untuk meningkatkan imej berskala Internet kepada awan titik 3D berpusat objek dan menggunakannya untuk mensintesis data VQA dengan penyeliaan inferens spatial 3D.
 4. Nyahkekaburan: Kadangkala mungkin terdapat berbilang objek kategori yang serupa dalam imej, mengakibatkan kekaburan dalam label penerangannya. Oleh itu, sebelum bertanya soalan tentang matlamat ini, anda perlu memastikan bahawa ungkapan rujukan tidak mengandungi kekaburan.
4. Nyahkekaburan: Kadangkala mungkin terdapat berbilang objek kategori yang serupa dalam imej, mengakibatkan kekaburan dalam label penerangannya. Oleh itu, sebelum bertanya soalan tentang matlamat ini, anda perlu memastikan bahawa ungkapan rujukan tidak mengandungi kekaburan.
Set data VQA penaakulan spatial berskala besar
Penyelidik menyepadukan keupayaan penaakulan spatial "intuitif" ke dalam VLM dengan menggunakan data sintetik untuk pra-latihan. Oleh itu, sintesis melibatkan pasangan soal jawab penaakulan ruang tidak lebih daripada dua objek (ditandakan A dan B) dalam imej. Dua jenis soalan berikut terutamanya dipertimbangkan di sini:
1. Soalan kualitatif: bertanya tentang pertimbangan hubungan ruang tertentu. Contohnya, "Diberi dua objek A dan B, yang manakah lebih jauh ke kiri
2. Soalan kuantitatif: Minta jawapan yang lebih terperinci, termasuk nombor dan unit. Sebagai contoh, "Berapa jauh ke kiri objek A berbanding objek B?", "Berapa jauh objek A dari B?" Soalan mengandungi kira-kira 20 templat soalan dan 10 templat jawapan.Rajah 3 menunjukkan contoh pasangan soalan-jawapan sintetik yang diperolehi dalam artikel ini. Para penyelidik mencipta set data besar-besaran 10 juta imej dan 2 bilion pasangan soalan-jawapan penaakulan spatial langsung (50% kualitatif, 50% kuantitatif).
Belajar penaakulan spatial
Penaakulan spatial langsung: Model bahasa visual menerima imej I dan pertanyaan Q sebagai jawapan, dan tugasan output yang dibentangkan dalam format teks, tanpa perlu menggunakan alat luaran atau berinteraksi dengan model besar lain. Artikel ini menggunakan proses seni bina dan latihan yang sama seperti PaLM-E, kecuali tulang belakang PaLM digantikan oleh PaLM 2-S. Latihan model kemudiannya dilakukan menggunakan campuran set data PaLM-E asal dan set data pengarang, dengan 5% daripada token digunakan untuk tugas inferens spatial.
Pemikiran Berantai Penaakulan Spatial: SpatialVLM menyediakan antara muka bahasa semula jadi yang boleh digunakan untuk bertanya soalan dengan konsep asas, dan apabila digabungkan dengan LLM yang berkuasa, boleh melakukan penaakulan spatial yang kompleks.
Sama seperti kaedah dalam Model Socratic dan penyelaras LLM, artikel ini menggunakan LLM (teks-davinci-003) untuk menyelaraskan komunikasi dengan SpatialVLM untuk menyelesaikan masalah kompleks dalam gesaan pemikiran berantai, seperti yang ditunjukkan dalam Rajah 4.

Para penyelidik membuktikan dan menjawab soalan-soalan berikut melalui eksperimen:
Soalan 1: Adakah penjanaan data proses VQA yang direka bentuk ini meningkatkan prestasi data umum spatial dan proses latihan ini VLM? Dan bagaimana prestasinya?
Soalan 2: Apakah kesan data VQA spatial sintetik yang penuh dengan data bising dan strategi latihan yang berbeza terhadap prestasi pembelajaran?
Soalan 3: Bolehkah VLM dilengkapi dengan keupayaan penaakulan spatial "langsung" membuka kunci keupayaan baharu seperti penaakulan pemikiran berantai dan perancangan yang terkandung?
Para penyelidik melatih model dengan menggunakan campuran set latihan PaLM-E dan set data VQA spatial yang direka dalam artikel ini. Untuk mengesahkan sama ada pengehadan VLM dalam penaakulan spatial ialah masalah data, mereka memilih model bahasa visual terkini yang terkini sebagai garis dasar. Tugas penerangan semantik menduduki bahagian yang besar dalam proses latihan model ini, dan bukannya menggunakan set data VQA ruang artikel ini untuk latihan.
Prestasi VQA ruang
VQA spatial kualitatif. Untuk soalan ini, kedua-dua jawapan beranotasi manusia dan output VLM adalah dalam bahasa semula jadi bentuk bebas. Oleh itu, untuk menilai prestasi VLM, kami menggunakan penilai manusia untuk menentukan sama ada jawapan adalah betul, dan kadar kejayaan bagi setiap VLM ditunjukkan dalam Jadual 1.
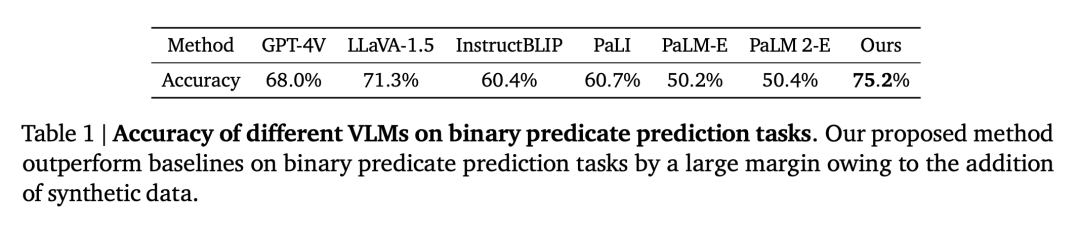
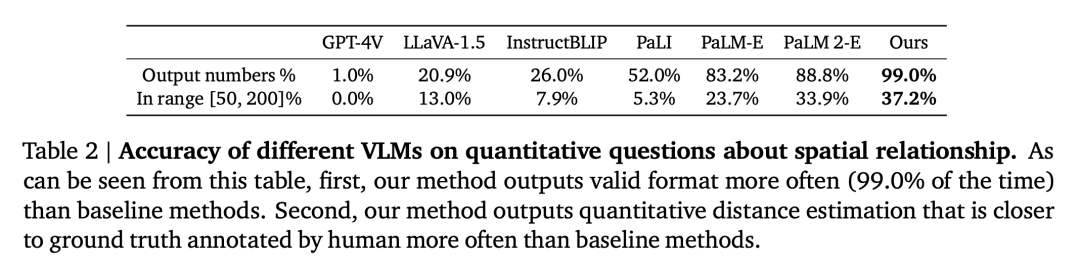
VQA spatial kuantitatif. Seperti yang ditunjukkan dalam Jadual 2, model kami berprestasi lebih baik daripada garis dasar pada kedua-dua metrik dan jauh di hadapan.
Impak data VQA spatial pada VQA umum
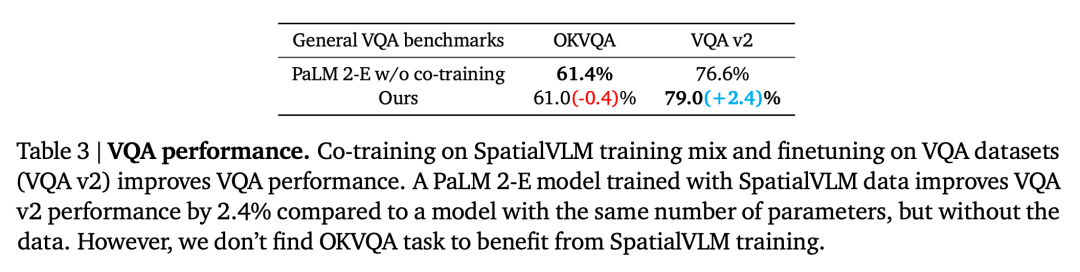
Soalan kedua ialah sama ada prestasi VLM pada tugas-tugas lain VQA akan terjejas oleh VQA bersama-sama data. Dengan membandingkan model kami dengan asas PaLM 2-E yang dilatih pada penanda aras VQA umum tanpa menggunakan data VQA spatial, seperti yang diringkaskan dalam Jadual 3, model kami mencapai prestasi yang setanding dengan PaLM 2-E pada penanda aras OKVQA, yang merangkumi spatial terhad masalah inferens, adalah lebih baik sedikit pada penanda aras ujian-dev VQA-v2, yang termasuk masalah inferens spatial.
Kesan pengekod ViT pada penaakulan spatial
Adakah ViT Beku (dilatih mengenai sasaran maklumat yang berbeza) mengekodkan spatial yang cukup untuk penaakulan maklumat yang berbeza? Untuk meneroka perkara ini, eksperimen penyelidik bermula pada langkah latihan 110,000 dan dibahagikan kepada dua larian latihan, satu ViT Beku dan satu lagi ViT Tidak Beku. Dengan melatih kedua-dua model untuk 70,000 langkah, keputusan penilaian ditunjukkan dalam Jadual 4.

Impak jawapan spatial kuantitatif yang bising
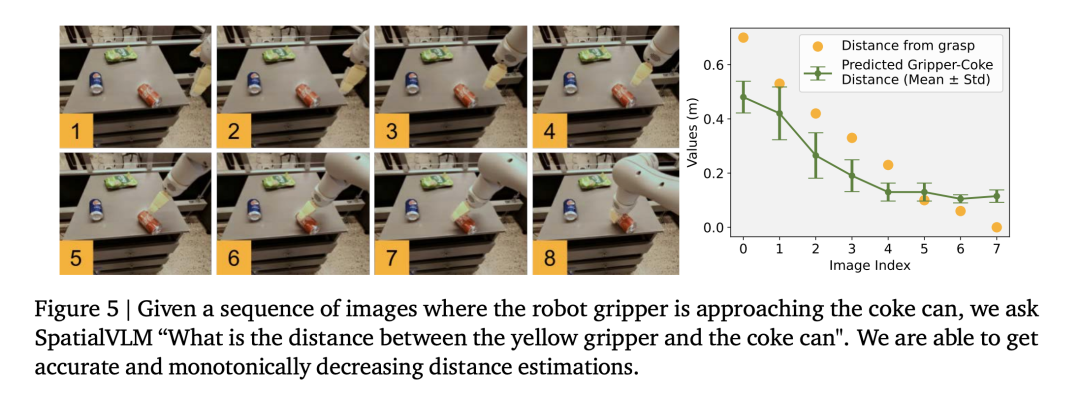
Para penyelidik menggunakan set data operasi robot untuk melatih model bahasa visual dan mendapati bahawa model jarak yang baik dapat dilakukan. domain operasi (Rajah 5), seterusnya membuktikan ketepatan data.
Jadual 5 membandingkan kesan sisihan piawai hingar Gaussian yang berbeza pada prestasi VLM keseluruhan dalam VQA spatial kuantitatif.

1. Model bahasa visual sebagai anotasi ganjaran yang padat
Model bahasa visual mempunyai aplikasi penting dalam bidang robotik. Penyelidikan terkini telah menunjukkan bahawa model bahasa visual dan model bahasa besar boleh berfungsi sebagai anotasi ganjaran perbendaharaan kata terbuka umum dan pengesan kejayaan untuk tugas robotik, yang boleh digunakan untuk membangunkan strategi kawalan yang berkesan. Walau bagaimanapun, keupayaan pelabelan ganjaran VLM selalunya dihadkan oleh kesedaran spatial yang tidak mencukupi. SpatialVLM sesuai secara unik sebagai anotasi ganjaran padat kerana keupayaannya untuk menganggarkan jarak atau dimensi secara kuantitatif daripada imej. Pengarang menjalankan eksperimen robotik dunia sebenar, menentukan tugas dalam bahasa semula jadi dan meminta SpatialVLM untuk memberi anotasi ganjaran untuk setiap bingkai dalam trajektori.
Setiap titik dalam Rajah 6 mewakili lokasi sasaran, dan warnanya mewakili ganjaran beranotasi. Apabila robot maju ke arah matlamat tertentu, ganjaran dilihat meningkat secara monoton, menunjukkan keupayaan SpatialVLM sebagai anotasi ganjaran yang padat.

2 pemikiran berantai penaakulan spatial
Penyelidik juga mengkaji sama ada kebolehan melaksanakan tugasan asas spatial VLM yang boleh digunakan untuk melaksanakan tugasan asas VLM. Meningkatkan kemahiran menjawab. Penulis menunjukkan beberapa contoh dalam Rajah 1 dan 4. Apabila model bahasa besar (GPT-4) dilengkapi dengan SpatialVLM sebagai submodul penaakulan spatial, ia boleh melaksanakan tugas penaakulan spatial yang kompleks, seperti menjawab sama ada 3 objek dalam persekitaran boleh membentuk "segitiga sama kaki".
Sila rujuk kertas asal untuk butiran lanjut teknikal dan keputusan percubaan.
Atas ialah kandungan terperinci Biarkan model bahasa visual melakukan penaakulan spatial dan Google baharu semula. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





























![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



