


Sora serta-merta menjadi trend teratas sebaik sahaja ia keluar, dan populariti topik itu hanya meningkat.
Keupayaan yang hebat untuk menjana video realistik telah membuatkan ramai orang berseru "realiti tidak lagi wujud".
Malah laporan teknikal OpenAI mendedahkan bahawa Sora boleh memahami dengan mendalam dunia fizikal yang sedang bergerak dan boleh dipanggil "model dunia" sebenar.

Dan gergasi Turing LeCun, yang sentiasa memberi tumpuan kepada "model dunia" sebagai fokus penyelidikan, juga terlibat dalam perdebatan ini.
Alasannya ialah netizen mencungkil pandangan yang dinyatakan oleh LeCun pada sidang kemuncak WGS beberapa hari lalu: "Dari segi video AI, kami tidak tahu apa yang perlu dilakukan."
Dia percaya bahawa menjana video realistik berdasarkan gesaan teks semata-mata tidak setara dengan model memahami dunia fizikal. Pendekatan untuk menjana video sangat berbeza daripada model dunia berdasarkan ramalan sebab akibat.

Seterusnya, LeCun menerangkan dengan lebih terperinci:
Walaupun terdapat banyak jenis video yang boleh dibayangkan, sistem penjanaan video hanya perlu mencipta "satu" sampel yang munasabah untuk berjaya.
Untuk video sebenar, terdapat sedikit laluan pembangunan seterusnya yang munasabah Adalah lebih sukar untuk menjana bahagian yang mewakili kemungkinan ini, terutamanya dalam keadaan tindakan tertentu.
Selain itu, menghasilkan kandungan susulan video ini bukan sahaja mahal, tetapi sebenarnya tidak berguna.
Pendekatan yang lebih ideal ialah menjana "perwakilan abstrak" bagi kandungan seterusnya, mengalih keluar butiran adegan yang tidak berkaitan dengan tindakan yang mungkin kami ambil.
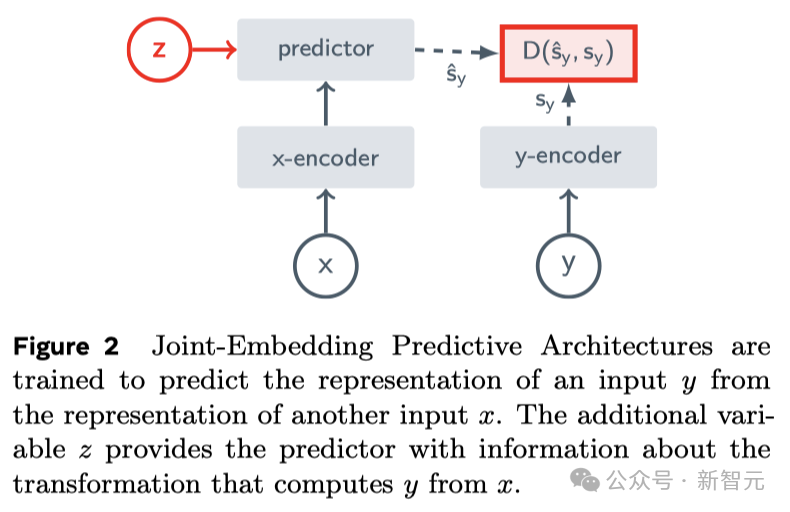
Ini adalah idea teras JEPA (Joint Embedding Prediction Architecture Ia bukan generatif, tetapi meramalkan dalam ruang perwakilan).
Kemudian, dia menggunakan penyelidikannya sendiri tentang VICReg, I-JEPA, V-JEPA dan hasil kerja orang lain untuk membuktikan:
dan seni bina generatif untuk membina semula piksel, seperti pengekod auto variasi (Variational AE), mask Berbanding dengan Masked AE, Denoising AE, dsb., "seni bina benam bersama" boleh menghasilkan ekspresi input visual yang lebih baik.
Apabila menggunakan perwakilan yang dipelajari sebagai input kepada ketua yang diselia dalam tugas hiliran (tanpa memperhalusi tulang belakang), seni bina benam bersama mengatasi prestasi seni bina generatif.
Pada hari model Sora dikeluarkan, Meta melancarkan "model ramalan video" baharu tanpa pengawasan - V-JEPA.
Sejak LeCun mula-mula menyebut JEPA pada 2022, I-JEPA dan V-JEPA mempunyai keupayaan ramalan yang kukuh berdasarkan imej dan video masing-masing.
Ia mendakwa dapat melihat dunia dalam "cara pemahaman manusia" dan menjana bahagian tersumbat melalui ramalan yang abstrak dan cekap.

Alamat kertas: https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/
V-JEPA ia datang kepada tindakan dalam video di bawah, ia berkata "Koyakkan kertas itu kepada separuh."

Untuk contoh lain, jika sebahagian daripada video yang anda lihat disekat, V-JEPA boleh membuat ramalan yang berbeza tentang kandungan pada buku nota.

Perlu disebut bahawa ini adalah kuasa super yang diperolehi V-JEPA selepas menonton 2 juta video.
Hasil eksperimen menunjukkan bahawa hanya melalui pembelajaran ramalan ciri video, "perwakilan visual yang cekap" boleh diperolehi yang boleh digunakan secara meluas untuk pelbagai tugas berdasarkan pertimbangan tindakan dan penampilan, dan tidak memerlukan sebarang pelarasan parameter model.
ViT-H/16 berdasarkan latihan V-JEPA mencapai markah tinggi masing-masing 81.9%, 72.2% dan 77.9% pada penanda aras Kinetics-400, SSv2 dan ImageNet1K.
Pemahaman manusia tentang dunia di sekeliling mereka, terutamanya pada peringkat awal kehidupan, sebahagian besarnya diperoleh melalui "pemerhatian".
Ambil "Hukum Gerakan Ketiga" Newton sebagai contoh Malah bayi atau kucing secara semula jadi boleh memahami selepas menolak sesuatu dari meja berkali-kali dan memerhatikan apa-apa objek akhirnya akan jatuh.
Pemahaman seperti ini tidak memerlukan bimbingan jangka panjang atau membaca buku yang banyak.
Ia boleh dilihat bahawa model dunia dalaman anda - pemahaman situasi berdasarkan pemahaman minda tentang dunia - boleh meramalkan keputusan ini dan sangat berkesan.
Yann LeCun berkata bahawa V-JEPA ialah langkah penting ke arah pemahaman yang lebih mendalam tentang dunia, bertujuan untuk membolehkan mesin membuat penaakulan dan merancang dengan lebih meluas.

Pada tahun 2022, beliau mula-mula mencadangkan Seni Bina Ramalan Penyertaan Bersama (JEPA).
Matlamat kami adalah untuk membina kecerdasan mesin lanjutan (AMI) yang boleh belajar seperti yang dilakukan manusia, belajar, menyesuaikan diri dan merancang dengan cekap untuk menyelesaikan tugas yang kompleks dengan membina model intrinsik dunia di sekeliling mereka.

Sangat berbeza daripada model AI generatif Sora, V-JEPA ialah "model bukan generatif".
Ia belajar dengan meramalkan bahagian video yang tersembunyi atau hilang dalam perwakilan ruang abstrak.
Ini serupa dengan Seni Bina Ramalan Penyertaan Bersama Imej (I-JEPA), yang belajar dengan membandingkan perwakilan abstrak imej dan bukannya membandingkan "piksel" secara terus
Berbeza dengan kaedah generatif yang cuba membina semula setiap piksel yang hilang, V-JEPA mampu membuang maklumat yang sukar diramalkan Pendekatan ini mencapai peningkatan 1.5-6 kali ganda dalam latihan dan kecekapan sampel.
V-JEPA mengamalkan kaedah pembelajaran penyeliaan sendiri dan bergantung sepenuhnya pada data tidak berlabel untuk latihan pra.
Hanya selepas pra-latihan, ia boleh memperhalusi model agar sesuai dengan tugas tertentu dengan melabelkan data.
Hasilnya, seni bina ini lebih cekap berbanding model sebelumnya, baik dari segi bilangan sampel berlabel yang diperlukan dan pelaburan dalam pembelajaran daripada data tidak berlabel.
Apabila menggunakan V-JEPA, penyelidik menyekat kebanyakan video dan hanya menunjukkan sebahagian kecil daripada "konteks".
Kemudian peramal diminta mengisi kandungan yang hilang - bukan melalui piksel tertentu, tetapi dalam bentuk penerangan yang lebih abstrak untuk mengisi kandungan dalam ruang perwakilan ini.
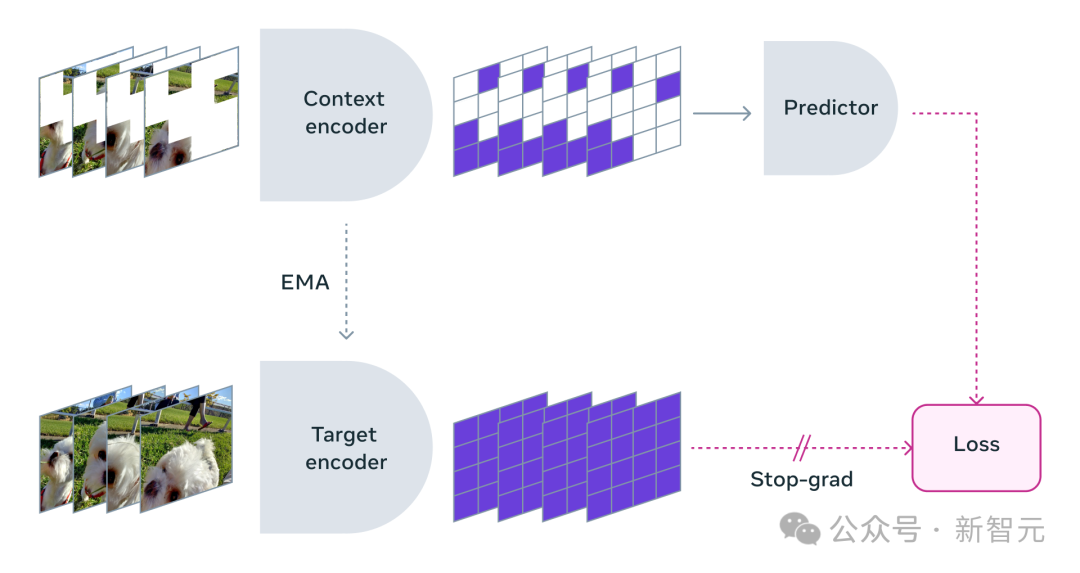
V-JEPA melatih pengekod visual dengan meramalkan kawasan spatio-temporal yang tersembunyi dalam ruang terpendam yang dipelajari
bukan untuk jenis tindakan tertentu JEPA.
Sebaliknya, ia belajar banyak tentang cara dunia berfungsi dengan menerapkan pembelajaran penyeliaan kendiri pada pelbagai video.
Penyelidik meta juga merancang strategi penyamaran dengan teliti:
Jika anda tidak menyekat kebanyakan kawasan video, tetapi hanya memilih beberapa serpihan kecil secara rawak, ini akan menjadikan tugas pembelajaran terlalu mudah, menyebabkan model tidak dapat mempelajari maklumat kompleks tentang dunia.
Sekali lagi, adalah penting untuk ambil perhatian bahawa dalam kebanyakan video, perkara berubah mengikut masa.
Jika anda hanya menutup sebahagian kecil video dalam tempoh yang singkat supaya model dapat melihat apa yang berlaku sebelum dan selepas, ia juga akan mengurangkan kesukaran pembelajaran dan menyukarkan model untuk mempelajari kandungan yang menarik .
Oleh itu, para penyelidik mengambil pendekatan menutup bahagian video secara serentak dalam ruang dan masa, memaksa model untuk belajar dan memahami adegan itu.
Ramalan dalam ruang perwakilan abstrak adalah kritikal kerana ia membolehkan model memfokus pada konsep peringkat tinggi kandungan video tanpa perlu risau tentang butiran yang biasanya tidak penting untuk dicapai tugas.
Lagipun, jika video menunjukkan pokok, anda mungkin tidak akan mengambil berat tentang pergerakan kecil setiap daun.
Apa yang benar-benar mengujakan penyelidik Meta ialah V-JEPA ialah model video pertama yang berprestasi baik pada "penilaian beku".
Pembekuan bermakna selepas semua pra-latihan yang diselia sendiri selesai pada pengekod dan peramal, ia tidak akan diubah suai lagi.
Apabila kami memerlukan model untuk mempelajari kemahiran baharu, kami hanya menambah lapisan atau rangkaian yang kecil dan khusus di atasnya, yang cekap dan pantas.
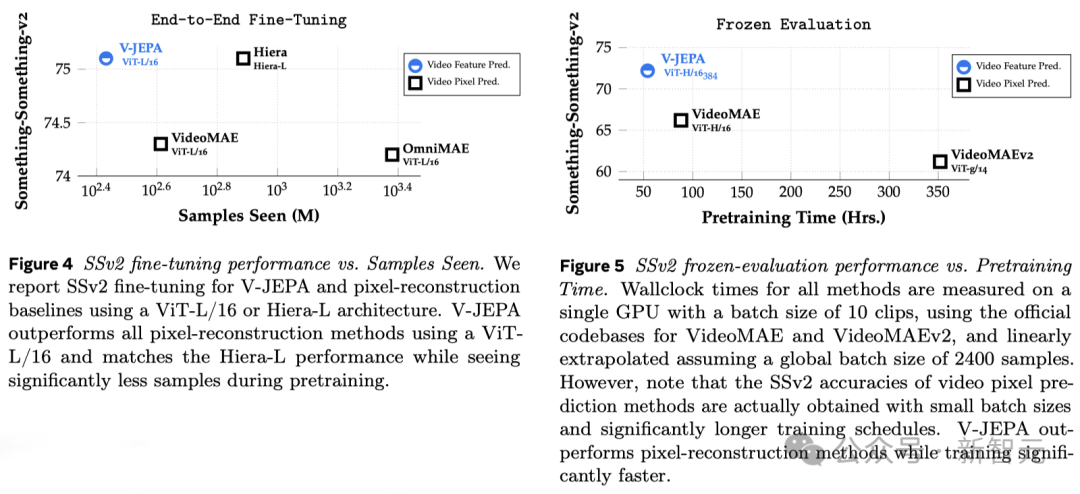
Penyelidikan sebelum ini juga memerlukan penalaan halus yang komprehensif, iaitu, selepas pra-latihan model, agar model dapat melaksanakan tugas dengan baik seperti pengecaman tindakan yang terperinci, semua parameter atau pemberat model perlu diperhalusi.
Secara terang-terangan, model yang ditala halus hanya boleh memfokuskan pada tugasan tertentu dan tidak boleh menyesuaikan diri dengan tugasan lain.
Jika anda mahu model mempelajari tugasan yang berbeza, anda mesti menukar data dan membuat pelarasan khusus pada keseluruhan model.
Penyelidikan V-JEPA menunjukkan bahawa adalah mungkin untuk melatih model sekali gus tanpa bergantung pada sebarang data berlabel, dan kemudian menggunakan model untuk pelbagai tugas yang berbeza, seperti klasifikasi tindakan, pengecaman interaksi objek halus dan penyetempatan aktiviti, membuka kemungkinan baharu.

- Penilaian beku beberapa pukulan
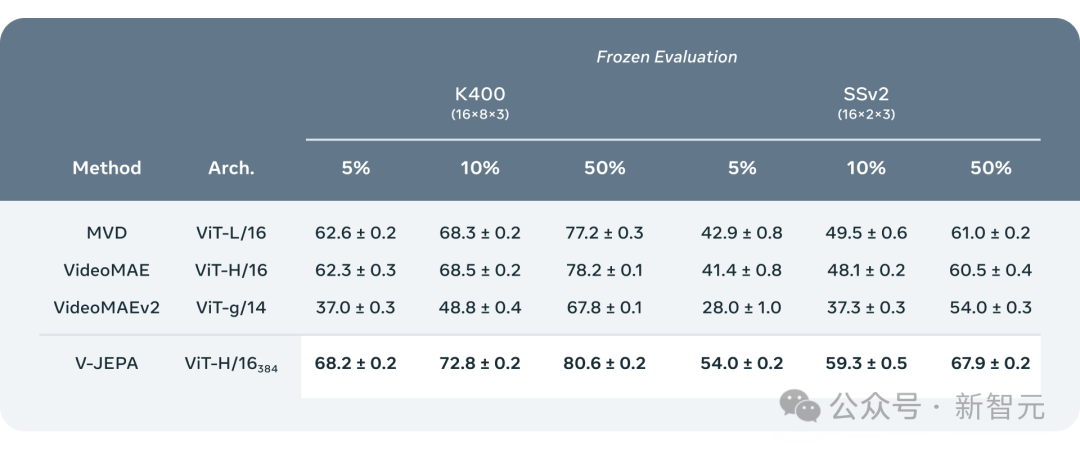
Para penyelidik membandingkan V-JEPA dengan model pemprosesan video lain, memberi perhatian khusus kepada prestasi apabila data kurang diberi keterangan.
Mereka memilih dua set data, Kinetics-400 dan Something-Something-v2, dan memerhati prestasi model semasa memproses video dengan melaraskan perkadaran sampel berlabel yang digunakan untuk latihan (masing-masing 5%, 10% dan 50% ).
Untuk memastikan kebolehpercayaan keputusan, 3 ujian bebas dijalankan pada setiap nisbah, dan purata dan sisihan piawai dikira.
Hasilnya menunjukkan bahawa V-JEPA lebih baik daripada model lain dalam kecekapan penggunaan anotasi Terutama apabila sampel anotasi yang tersedia untuk setiap kategori dikurangkan, jurang prestasi antara V-JEPA dan model lain menjadi lebih jelas.

Walaupun "V" V-JEPA adalah singkatan kepada video, setakat ini, ia tertumpu terutamanya pada menganalisis "elemen visual" video .
Jelas sekali, hala tuju penyelidikan Meta seterusnya ialah melancarkan kaedah berbilang modal yang boleh memproses "maklumat visual dan audio" dalam video secara serentak.
Sebagai model bukti konsep, V-JEPA berprestasi baik dalam mengenal pasti interaksi objek halus dalam video.
Sebagai contoh, dapat membezakan sama ada seseorang meletakkan pen, mengambil pen, atau berpura-pura meletakkan pen tetapi sebenarnya tidak meletakkannya.
Walau bagaimanapun, pengecaman gerakan peringkat tinggi ini berfungsi dengan baik untuk klip video pendek (beberapa saat hingga 10 saat).
Oleh itu, fokus lain dalam langkah penyelidikan seterusnya ialah cara membuat rancangan model dan meramalkan dalam jangka masa yang lebih lama.
Setakat ini, penyelidik Meta yang menggunakan V-JEPA memfokuskan terutamanya pada "persepsi" - memahami situasi masa nyata dunia sekeliling dengan menganalisis strim video.
Dalam seni bina ramalan benam bersama ini, peramal bertindak sebagai "model dunia fizikal" awal yang boleh memberitahu kita secara umum apa yang berlaku dalam video.
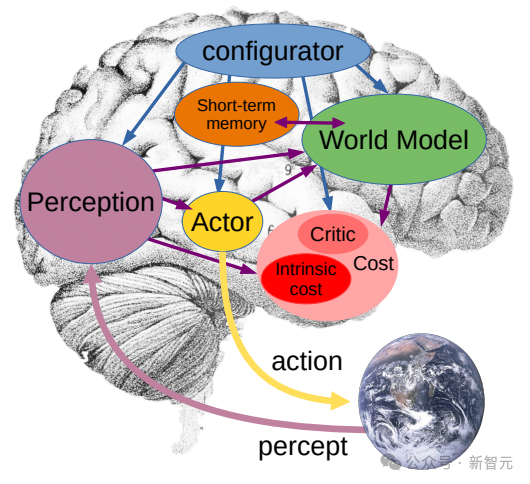
Matlamat Meta seterusnya adalah untuk menunjukkan bagaimana peramal atau model dunia ini boleh digunakan untuk perancangan dan membuat keputusan yang berterusan.
Kita sudah tahu bahawa model JEPA boleh dilatih dengan memerhati video, sama seperti bayi yang memerhati dunia, dan boleh belajar banyak perkara tanpa pengawasan yang kuat.
Dengan cara ini, model boleh mempelajari tugas baharu dengan cepat dan mengenali tindakan berbeza dengan hanya sejumlah kecil data berlabel.
Dalam jangka masa panjang, pemahaman situasi V-JEPA yang kukuh akan menjadi sangat penting kepada pembangunan teknologi AI yang terkandung dan cermin mata realiti tambahan (AR) masa hadapan dalam aplikasi masa hadapan.
Sekarang fikirkan, jika Apple Vision Pro boleh diberkati oleh "Model Dunia", ia akan menjadi lebih kebal.
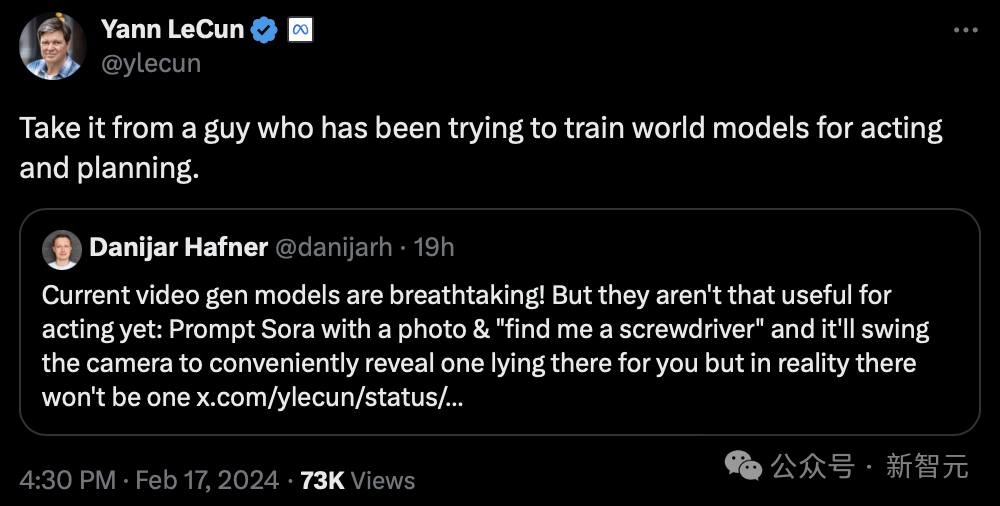
Jelas sekali, LeCun tidak optimistik tentang AI generatif.

"Dengar nasihat seseorang yang telah cuba melatih "model dunia" untuk pembentangan dan perancangan."
Ketua Pegawai Eksekutif Perplexity AI berkata:
Sora, walaupun menakjubkan, tidak bersedia untuk memodelkan fizik dengan tepat. Dan pengarang Sora sangat bijak dan menyebut ini dalam bahagian laporan teknikal blog, seperti kaca pecah tidak boleh dimodelkan dengan baik.
Adalah jelas bahawa dalam jangka pendek, penaakulan berdasarkan simulasi dunia yang begitu kompleks tidak boleh dijalankan serta-merta pada robot rumah.
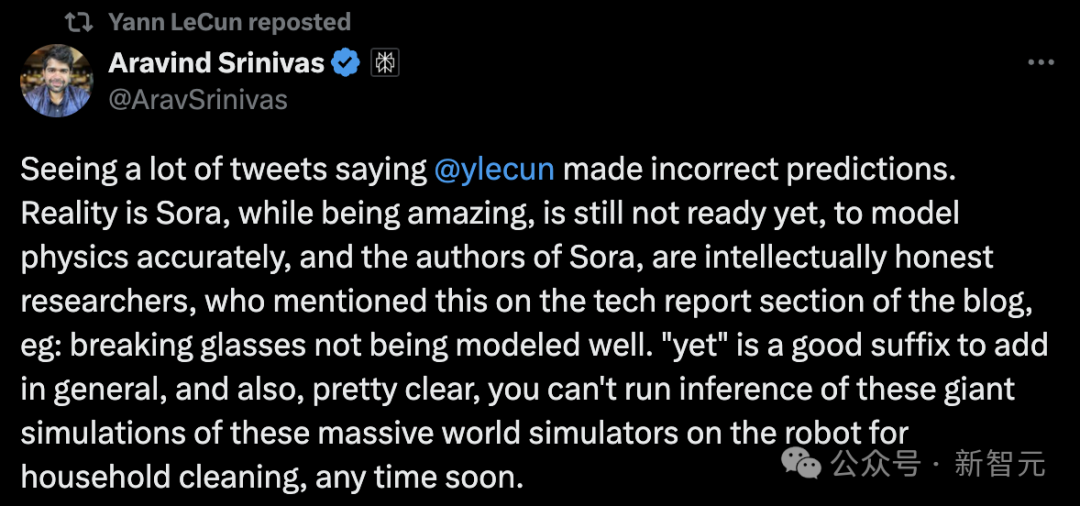
Sebenarnya, nuansa yang sangat penting yang gagal difahami ramai orang ialah:
Menjana kandungan yang kelihatan menarik dalam teks atau video tidak bermakna (dan tidak memerlukan) bahawa ia Memahami” kandungan anda menjana. Model ejen yang mampu membuat penaakulan berdasarkan pemahaman mestilah, pasti, berada di luar model besar atau model penyebaran.

Tetapi sesetengah netizen berkata, "Ini bukan cara manusia belajar."
"Kami hanya mengingati sesuatu yang unik tentang pengalaman masa lalu kami, kehilangan semua butiran. Kami juga boleh memodelkan (mencipta perwakilan) persekitaran pada bila-bila masa dan di mana-mana sahaja kerana kami melihatnya. Bahagian kecerdasan yang paling penting ialah perubahan generalisasi".

Yang lain mendakwa bahawa ia masih merupakan pembenaman ruang terpendam interpolasi, dan setakat ini anda tidak boleh membina "model dunia" dengan cara ini.

Bolehkah Sora dan V-JEPA benar-benar memahami dunia? Apa pendapat kamu?
Atas ialah kandungan terperinci LeCun dengan marah menuduh Sora tidak dapat memahami dunia fizikal! Video AI pertama Meta 'Model Dunia' V-JEPA. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyambung ke pangkalan data dalam vb
Bagaimana untuk menyambung ke pangkalan data dalam vb Apa yang perlu dilakukan dengan kad video
Apa yang perlu dilakukan dengan kad video apakah maksud elk
apakah maksud elk Bagaimana untuk membuka fail format csv
Bagaimana untuk membuka fail format csv Bagaimana untuk menyelesaikan ralat1
Bagaimana untuk menyelesaikan ralat1 Apakah syiling yang tertulis?
Apakah syiling yang tertulis? apa maksud bbs
apa maksud bbs Apakah perbezaan antara JD International dikendalikan sendiri dan JD dikendalikan sendiri
Apakah perbezaan antara JD International dikendalikan sendiri dan JD dikendalikan sendiri




















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



