


Retrieval Augmented Generation (RAG) dan fine-tuning (Fine-tuning) ialah dua kaedah biasa untuk meningkatkan prestasi model bahasa besar, jadi kaedah manakah yang lebih baik? Yang manakah lebih cekap apabila membina aplikasi dalam domain tertentu? Kertas kerja daripada Microsoft ini adalah untuk rujukan anda semasa memilih.
Apabila membina aplikasi model bahasa yang besar, dua pendekatan sering digunakan untuk menggabungkan data proprietari dan domain khusus: penjanaan peningkatan perolehan dan penalaan halus. Penjanaan yang dipertingkatkan semula meningkatkan keupayaan penjanaan model dengan memperkenalkan data luaran, manakala penalaan halus menggabungkan pengetahuan tambahan ke dalam model itu sendiri. Walau bagaimanapun, pemahaman kita tentang kebaikan dan keburukan kedua-dua pendekatan ini tidak mencukupi.
Artikel ini memperkenalkan fokus baharu yang dicadangkan oleh penyelidik Microsoft, iaitu untuk mencipta pembantu AI dengan konteks khusus dan keupayaan tindak balas penyesuaian untuk industri pertanian. Dengan memperkenalkan proses model bahasa besar yang komprehensif, soalan dan jawapan yang berkualiti tinggi dan khusus industri boleh dihasilkan. Proses ini terdiri daripada satu siri langkah yang sistematik, bermula dengan pengenalan dan pengumpulan dokumen berkaitan yang meliputi pelbagai topik pertanian. Dokumen ini kemudiannya dibersihkan dan distrukturkan untuk menghasilkan pasangan soalan-jawapan yang bermakna menggunakan model GPT asas. Akhir sekali, pasangan soalan-jawapan yang dihasilkan dinilai dan ditapis berdasarkan kualitinya. Pendekatan ini menyediakan industri pertanian alat yang berkuasa yang boleh memberikan maklumat yang tepat dan praktikal untuk membantu petani dan pengamal berkaitan menangani pelbagai isu dan cabaran dengan lebih baik.
Artikel ini bertujuan untuk mencipta sumber pengetahuan yang berharga untuk industri pertanian, menggunakan pertanian sebagai kajian kes. Matlamat utamanya adalah untuk menyumbang kepada pembangunan LLM dalam sektor pertanian.

Alamat kertas: https://arxiv.org/pdf/2401.08406.pdf
Tajuk kertas: RAG vs Fine-tuning: Pipelines, Tradeoffs🜎🜎
Agriculture Matlamat proses kertas ini adalah untuk menjana soalan dan jawapan khusus domain yang memenuhi keperluan profesional industri tertentu dan pihak berkepentingan. Dalam industri ini, jawapan yang diharapkan daripada pembantu AI hendaklah berdasarkan faktor khusus industri yang berkaitan.Penjanaan Soal Jawab, Penjanaan Peningkatan Pendapatan dan Proses Penalaan Halus
. Penjanaan soalan-jawapan mencipta pasangan soalan-jawapan berdasarkan maklumat dalam set data pertanian, dan penjanaan tambahan perolehan menggunakannya sebagai sumber pengetahuan. Data yang dijana diperhalusi dan digunakan untuk memperhalusi berbilang model, yang kualitinya dinilai melalui set metrik yang dicadangkan. Melalui pendekatan komprehensif ini, manfaatkan kuasa model bahasa yang besar untuk memberi manfaat kepada industri pertanian dan pihak berkepentingan lain.Kertas kerja ini memberikan beberapa sumbangan khusus kepada pemahaman model bahasa besar dalam bidang pertanian Sumbangan ini boleh diringkaskan seperti berikut:
1,Penilaian komprehensif LLMs
: Kertas kerja ini menjalankan penilaian yang meluas terhadap model bahasa besar, termasuk LlaMa2- 13B, GPT-4, dan Vicuna untuk menjawab soalan berkaitan pertanian. Set data penanda aras dari negara pengeluar utama pertanian telah digunakan untuk penilaian. Dalam analisis ini, GPT-4 secara konsisten mengatasi model lain, tetapi kos yang berkaitan dengan penalaan halus dan inferensnya perlu dipertimbangkan.2. Impak teknologi perolehan semula dan penalaan halus terhadap prestasi
: Kertas kerja ini mengkaji kesan teknologi perolehan semula dan penalaan halus terhadap prestasi LLM. Penyelidikan telah mendapati bahawa kedua-dua penjanaan peningkatan perolehan dan penalaan halus adalah teknik yang berkesan untuk meningkatkan prestasi LLM.3 Impak aplikasi berpotensi LLM dalam industri berbeza
: Untuk proses yang ingin mewujudkan teknologi RAG dan penalaan halus untuk aplikasi dalam LLM, artikel ini mengambil langkah perintis dan menggalakkan kerjasama antara pelbagai industri.Metodologi
Bahagian 2 artikel ini memperincikan metodologi yang diterima pakai, termasuk proses pemerolehan data, proses pengekstrakan maklumat, penjanaan soal jawab dan penalaan halus model. Metodologi berkisar pada proses yang direka bentuk untuk menjana dan menilai pasangan soalan-jawapan untuk membina pembantu khusus domain, seperti yang ditunjukkan dalam Rajah 1 di bawah.
Proses bermula dengan pemerolehan data, yang termasuk mendapatkan data daripada pelbagai repositori berkualiti tinggi, seperti agensi kerajaan, pangkalan data pengetahuan saintifik dan menggunakan data proprietari apabila perlu. 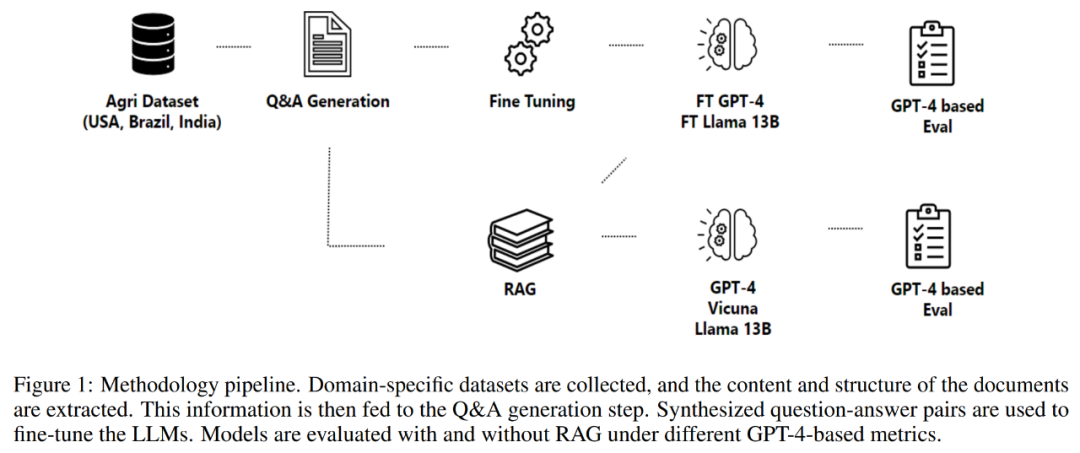
Komponen proses seterusnya ialah penjanaan soal jawab. Matlamat di sini adalah untuk menjana soalan berasaskan konteks dan berkualiti tinggi yang menggambarkan kandungan teks yang diekstrak dengan tepat. Kaedah ini menggunakan rangka kerja untuk mengawal komposisi struktur input dan output, dengan itu meningkatkan kesan keseluruhan tindak balas yang dijana oleh model bahasa.
Proses itu kemudian menjana jawapan kepada soalan yang dirumus. Pendekatan yang digunakan di sini memanfaatkan penjanaan yang dipertingkatkan semula, menggabungkan keupayaan mekanisme perolehan semula dan penjanaan untuk mencipta jawapan berkualiti tinggi.
Akhir sekali, proses memperhalusi model melalui Soal Jawab. Proses pengoptimuman menggunakan kaedah seperti pelarasan peringkat rendah (LoRA) untuk memastikan pemahaman yang menyeluruh tentang kandungan dan konteks kesusasteraan saintifik, menjadikannya sumber yang berharga dalam pelbagai bidang atau industri.
Datasets
Kajian ini menilai model bahasa yang dijana oleh penalaan halus dan peningkatan perolehan, menggunakan set data soalan dan jawapan berkaitan konteks daripada tiga negara pengeluar tanaman utama: Amerika Syarikat, Brazil dan India. Dalam kes artikel ini, pertanian digunakan sebagai latar belakang perindustrian. Data yang tersedia berbeza-beza secara meluas dalam format dan kandungan, bermula daripada dokumen pengawalseliaan kepada laporan saintifik kepada pemeriksaan agronomik kepada pangkalan data pengetahuan.
Artikel ini mengumpulkan maklumat daripada dokumen, manual dan laporan dalam talian yang tersedia untuk umum daripada Jabatan Pertanian A.S., agensi pertanian dan perkhidmatan pengguna negeri, dan lain-lain.
Dokumen yang tersedia termasuk maklumat peraturan dan dasar persekutuan tentang pengurusan tanaman dan ternakan, penyakit dan amalan terbaik, jaminan kualiti dan peraturan eksport, butiran program bantuan serta panduan insurans dan harga. Data yang dikumpul berjumlah lebih 23,000 fail PDF yang mengandungi lebih 50 juta token dan meliputi 44 negeri AS. Penyelidik memuat turun dan memproses semula fail-fail ini untuk mengekstrak maklumat teks yang boleh digunakan sebagai input kepada proses penjanaan soalan dan jawapan.
Untuk menanda aras dan menilai model, artikel ini menggunakan dokumen yang berkaitan dengan negeri Washington, yang merangkumi 573 fail yang mengandungi lebih daripada 2 juta token. Penyenaraian 5 di bawah menunjukkan contoh kandungan dalam fail ini.

Metrik
Tujuan utama bahagian ini adalah untuk mewujudkan set metrik yang komprehensif dengan tujuan membimbing penilaian kualiti proses penjanaan soalan dan jawapan, terutamanya penilaian penalaan halus dan peningkatan perolehan kaedah penjanaan.
Apabila membangunkan metrik, beberapa faktor utama mesti dipertimbangkan. Pertama, subjektiviti yang wujud dalam kualiti soalan menimbulkan cabaran yang ketara.
Kedua, metrik mesti mengambil kira perkaitan masalah dan pergantungan praktikal pada konteks.
Ketiga, kepelbagaian dan kebaharuan soalan yang dihasilkan perlu dinilai. Sistem penjanaan soalan yang kukuh seharusnya dapat menjana pelbagai soalan yang merangkumi semua aspek kandungan tertentu. Walau bagaimanapun, mengukur kepelbagaian dan kebaharuan boleh menjadi mencabar, kerana ia melibatkan penilaian keunikan soalan dan persamaannya dengan kandungan, soalan lain yang dihasilkan.
Akhir sekali, soalan yang baik sepatutnya dapat dijawab berdasarkan kandungan yang disediakan. Menilai sama ada soalan boleh dijawab dengan tepat menggunakan maklumat yang ada memerlukan pemahaman yang mendalam tentang kandungan dan keupayaan untuk mengenal pasti maklumat yang relevan untuk menjawab soalan.
Metrik ini memainkan peranan penting dalam memastikan jawapan yang diberikan oleh model menjawab soalan dengan tepat, relevan dan berkesan. Walau bagaimanapun, terdapat kekurangan ketara metrik yang direka khusus untuk menilai kualiti soalan.
Menyedari kekurangan ini, kertas kerja ini memfokuskan pada pembangunan metrik yang direka untuk menilai kualiti soalan. Memandangkan peranan kritikal soalan dalam mendorong perbualan yang bermakna dan menjana jawapan yang berguna, memastikan kualiti soalan anda adalah sama pentingnya dengan memastikan kualiti jawapan anda.
Metrik yang dibangunkan dalam artikel ini bertujuan untuk mengisi jurang dalam penyelidikan terdahulu dalam bidang ini dan menyediakan cara untuk menilai kualiti soalan secara menyeluruh, yang akan memberi impak yang ketara ke atas kemajuan proses penjanaan soalan dan jawapan.
Penilaian Masalah
Metrik yang dibangunkan dalam kertas ini untuk menilai masalah adalah seperti berikut:
Kaitan
Global Relevance
Bertindih
Pelbagai Seksualiti
Perincian
Penilaian model
Untuk menilai model berbeza yang diperhalusi, artikel ini menggunakan GPT-4 sebagai penilai. Kira-kira 270 pasangan soalan dan jawapan telah dihasilkan daripada dokumen pertanian menggunakan GPT-4 sebagai set data dunia sebenar. Bagi setiap model yang diperhalusi dan model generatif dipertingkatkan semula, jawapan kepada soalan ini dijana.
Kertas ini menilai LLM pada beberapa metrik berbeza:
Penilaian dengan Garis Panduan: Untuk setiap pasangan soalan-jawapan dunia sebenar, kertas ini menggesa GPT-4 untuk menjana panduan penilaian yang menyenaraikan jawapan yang betul harus Apa yang disertakan . GPT-4 kemudiannya digesa untuk menjaringkan setiap jawapan pada skala dari 0 hingga 1 berdasarkan kriteria dalam panduan penilaian. Berikut ialah contoh:
Ringkas : Buat rubrik yang menerangkan jawapan ringkas dan panjang yang mungkin disertakan. Berdasarkan rubrik ini, jawapan situasi sebenar dan jawapan LLM menggesa GPT-4 diminta untuk penilaian pada skala 1 hingga 5.
Ketepatan: Artikel ini mencipta rubrik yang menerangkan perkara yang sepatutnya mengandungi jawapan yang lengkap, separa betul atau salah. Berdasarkan rubrik ini, jawapan situasi sebenar dan jawapan LLM menggesa GPT-4 diminta untuk penilaian yang betul, salah atau separa betul.
Eksperimen
Eksperimen kertas ini dibahagikan kepada beberapa eksperimen bebas, setiap satu memfokuskan pada aspek khusus penjanaan dan penilaian soal jawab, penjanaan peningkatan perolehan dan penalaan halus.
Eksperimen ini meneroka bidang berikut:
Kualiti Soal Jawab
Kajian kontekstual
Model kepada pengiraan metrik
binMengambil semula kajian ablasi
Penalaan halus
Kualiti Soal JawabPercubaan ini menilai kualiti pasangan soalan dan jawapan yang dijana oleh tiga model bahasa besar, iaitu GPT-3, GPT-3.5 dan GPT-4, di bawah tetapan konteks yang berbeza. Penilaian kualiti adalah berdasarkan berbilang metrik, termasuk perkaitan, liputan, pertindihan dan kepelbagaian.
Kajian Konteks
Dalam tetapan bebas konteks, GPT-4 mempunyai liputan dan saiz pembayang tertinggi antara tiga model, menunjukkan bahawa ia boleh merangkumi lebih banyak bahagian teks, tetapi menjana soalan yang lebih panjang. Walau bagaimanapun, ketiga-tiga model mempunyai nilai berangka yang sama untuk kepelbagaian, pertindihan, perkaitan dan kelancaran.
Apabila konteks disertakan, GPT-3.5 mempunyai sedikit peningkatan dalam liputan berbanding GPT-3, manakala GPT-4 mengekalkan liputan tertinggi. Untuk Prompt Saiz, GPT-4 mempunyai nilai terbesar, menunjukkan keupayaannya untuk menjana soalan dan jawapan yang lebih panjang.
Dari segi kepelbagaian dan pertindihan, ketiga-tiga model ini mempunyai prestasi yang sama. Untuk perkaitan dan kelancaran, GPT-4 menunjukkan sedikit peningkatan berbanding model lain.
Dalam tetapan konteks luaran, terdapat situasi yang sama.
Selain itu, apabila melihat setiap model, tetapan bebas konteks nampaknya memberikan keseimbangan terbaik untuk GPT-4 dari segi liputan purata, kepelbagaian, pertindihan, perkaitan dan kelancaran, tetapi menghasilkan pasangan soalan-jawapan yang lebih pendek. Tetapan konteks menghasilkan pasangan soalan-jawapan yang lebih panjang dan penurunan sedikit dalam metrik lain kecuali saiz. Tetapan konteks luaran menghasilkan pasangan soalan-jawapan terpanjang tetapi mengekalkan liputan purata dan sedikit meningkatkan purata perkaitan dan kelancaran.
Secara keseluruhan, untuk GPT-4, tetapan bebas konteks nampaknya memberikan keseimbangan terbaik dari segi liputan purata, kepelbagaian, pertindihan, perkaitan dan kelancaran, tetapi menjana jawapan yang lebih pendek. Tetapan kontekstual menghasilkan gesaan yang lebih panjang dan sedikit penurunan dalam metrik lain. Tetapan konteks luaran menjana gesaan terpanjang tetapi mengekalkan liputan purata dengan sedikit peningkatan dalam purata perkaitan dan kelancaran. Jadi pilihan antara ketiga-tiga ini bergantung pada keperluan khusus tugas. Jika panjang gesaan tidak dipertimbangkan, konteks luaran mungkin merupakan pilihan terbaik kerana skor perkaitan dan kefasihan yang lebih tinggi.
Model to Metric ComputationPercubaan ini membandingkan prestasi GPT-3.5 dan GPT-4 dalam pengiraan metrik yang digunakan untuk menilai kualiti pasangan soalan-jawapan. Secara keseluruhan, walaupun GPT-4 secara amnya menilai pasangan soalan-jawapan yang dijana sebagai lebih fasih dan sahih dari segi konteks, ia adalah kurang pelbagai dan kurang relevan daripada penilaian GPT-3.5. Perspektif ini penting untuk memahami cara model yang berbeza melihat dan menilai kualiti kandungan yang dijana. Perbandingan antara generasi gabungan dan generasi individu
Secara keseluruhan, kaedah penjanaan soalan sahaja memberikan liputan yang lebih baik dan kepelbagaian yang lebih rendah, manakala kaedah penjanaan gabungan mendapat skor yang lebih tinggi dari segi pertindihan dan korelasi. Dari segi kefasihan, kedua-dua kaedah mempunyai prestasi yang sama. Oleh itu, pilihan antara dua kaedah ini bergantung pada keperluan khusus tugas.
Jika matlamatnya adalah untuk merangkumi lebih banyak maklumat dan mengekalkan lebih banyak kepelbagaian, maka pendekatan soalan sahaja akan diutamakan. Walau bagaimanapun, jika tahap pertindihan yang tinggi dengan bahan sumber ingin dikekalkan, maka pendekatan penjanaan gabungan akan menjadi pilihan yang lebih baik.
Kajian Ablasi Pengambilan semula
Percubaan ini menilai keupayaan mendapatkan semula penjanaan peningkatan perolehan, kaedah yang meningkatkan pengetahuan sedia ada LLM dengan menyediakan konteks tambahan semasa menjawab soalan.
Kertas kerja ini mengkaji kesan bilangan serpihan yang diambil semula (iaitu top-k) ke atas keputusan dan membentangkan keputusan dalam Jadual 16. Dengan mempertimbangkan lebih banyak serpihan, penjanaan yang dipertingkatkan dapatan dapat memulihkan petikan asal dengan lebih konsisten.
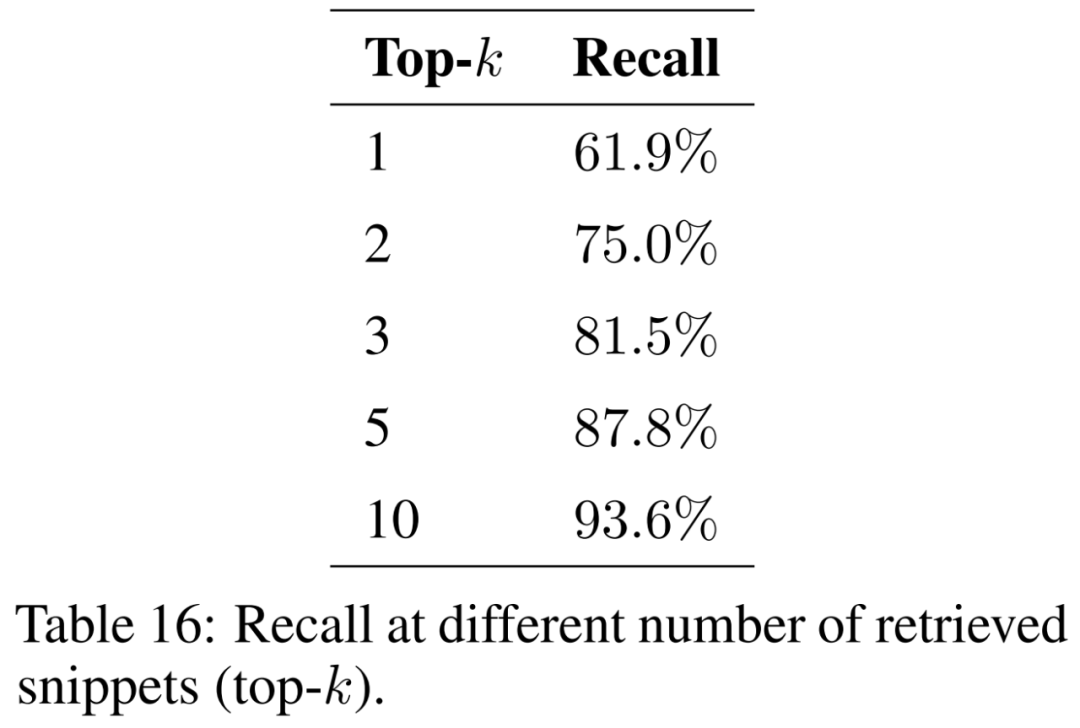
Untuk memastikan model dapat menangani masalah daripada pelbagai konteks dan fenomena geografi, korpus dokumen sokongan perlu diperluaskan untuk merangkumi pelbagai topik. Saiz indeks dijangka meningkat apabila lebih banyak dokumen dipertimbangkan. Ini boleh meningkatkan bilangan perlanggaran antara segmen yang serupa semasa pengambilan semula, menghalang keupayaan untuk memulihkan maklumat yang berkaitan untuk soalan input dan mengurangkan ingatan semula.
Penalaan halus
Percubaan ini menilai perbezaan prestasi antara model yang ditala halus dan model yang ditala halus arahan asas. Matlamatnya adalah untuk memahami potensi penalaan halus untuk membantu model mempelajari pengetahuan baharu.
Untuk model asas, artikel ini menilai model sumber terbuka Llama2-13B-chat dan Vicuna-13B-v1.5-16k. Kedua-dua model ini agak kecil dan mewakili pertukaran yang menarik antara pengiraan dan prestasi. Kedua-dua model adalah versi Llama2-13B yang diperhalusi, menggunakan kaedah yang berbeza.
Llama2-13B-chat ialah arahan yang diperhalusi melalui penalaan halus dan pembelajaran pengukuhan yang diselia. Vicuna-13B-v1.5-16k ialah versi arahan yang diperhalusi melalui penalaan halus diselia pada set data ShareGPT. Selain itu, kertas kerja ini menilai asas GPT-4 sebagai alternatif yang lebih besar, lebih mahal dan lebih berkuasa.
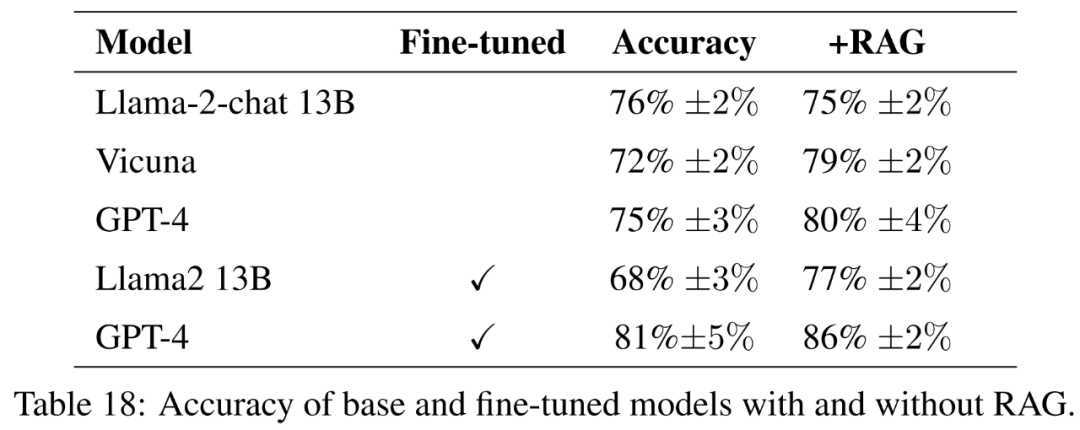
Untuk model yang diperhalusi, kertas kerja ini memperhalusi Llama2-13B secara langsung pada data pertanian untuk membandingkan prestasinya dengan model serupa yang diperhalusi untuk tugasan yang lebih umum. Kertas kerja ini juga memperhalusi GPT-4 untuk menilai sama ada penalaan halus masih membantu pada model yang sangat besar. Keputusan penilaian dengan garis panduan ditunjukkan dalam Jadual 18.
Untuk mengukur kualiti respons sepenuhnya, selain ketepatan, artikel ini juga menilai ringkasan respons.
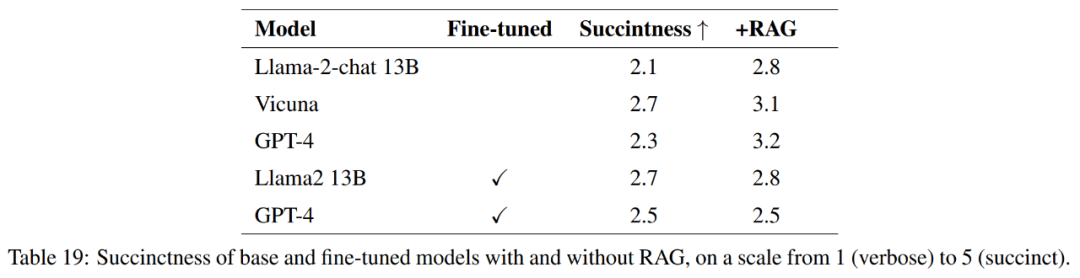
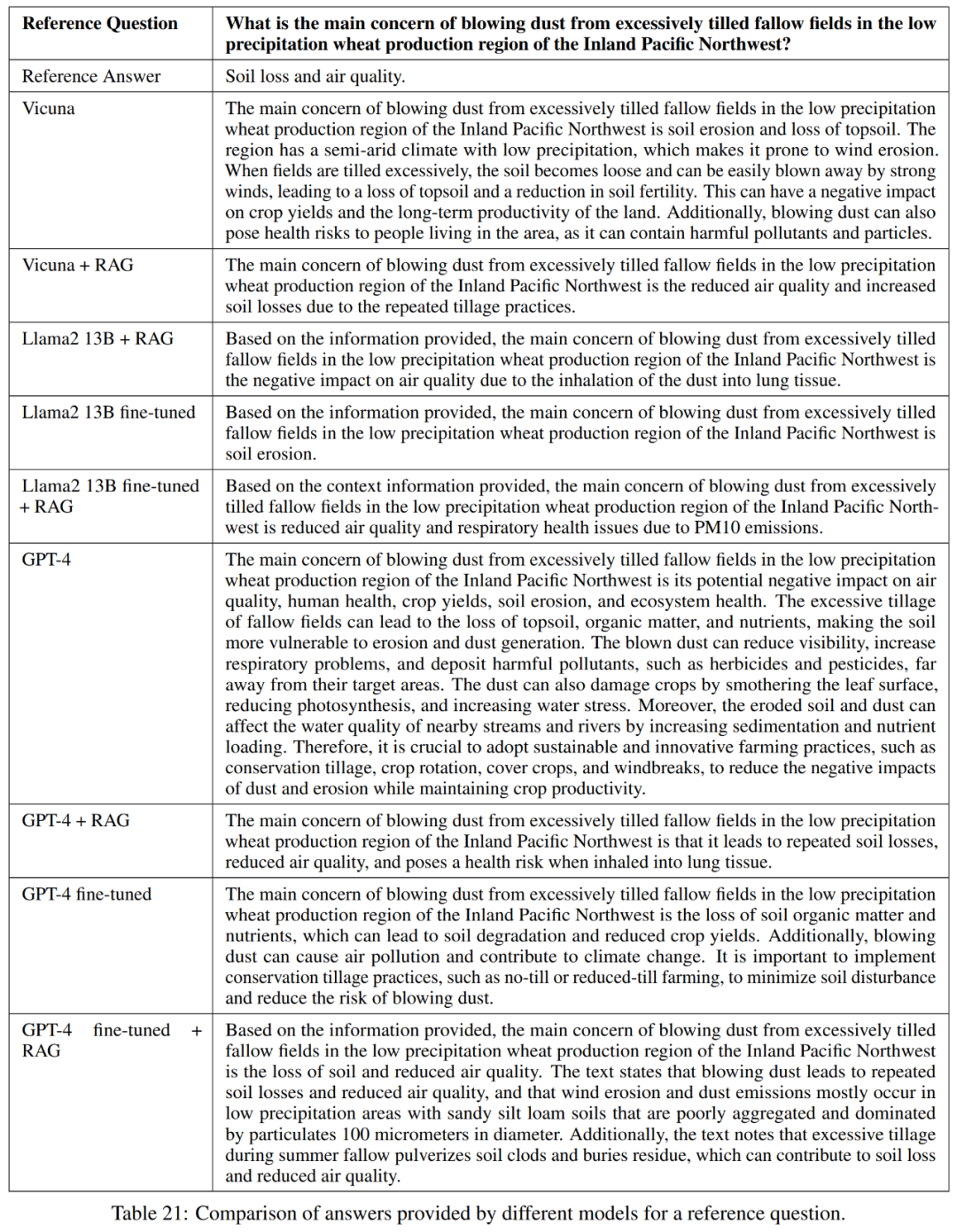
Seperti yang ditunjukkan dalam Jadual 21, model ini tidak selalu memberikan jawapan yang lengkap kepada soalan. Sebagai contoh, beberapa maklum balas menyatakan hakisan tanah sebagai masalah tetapi tidak menyebut kualiti udara.
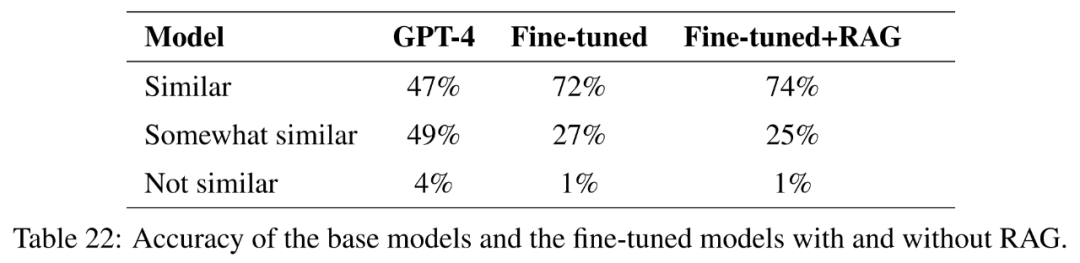
Secara keseluruhannya, model berprestasi terbaik dari segi menjawab jawapan rujukan dengan tepat dan padat ialah Vicuna + penjanaan dipertingkatkan semula, penjanaan dipertingkatkan semula GPT-4 +, penalaan halus GPT-4 dan penalaan halus GPT-4 + perolehan peningkatan menjana. Model ini menawarkan gabungan ketepatan, kesederhanaan dan kedalaman maklumat yang seimbang.
Penemuan Pengetahuan
Matlamat penyelidikan kertas ini adalah untuk meneroka potensi penalaan halus untuk membantu GPT-4 mempelajari pengetahuan baharu, yang penting untuk penyelidikan gunaan.
Untuk menguji ini, artikel ini memilih soalan yang serupa di sekurang-kurangnya tiga daripada 50 negeri di Amerika Syarikat. Persamaan kosinus pembenaman kemudiannya dikira dan senarai 1000 soalan tersebut telah dikenalpasti. Soalan ini dialih keluar daripada set latihan, dan penalaan halus dan penalaan halus dengan penjanaan dipertingkatkan semula digunakan untuk menilai sama ada GPT-4 dapat mempelajari pengetahuan baharu berdasarkan persamaan antara negeri yang berbeza.
Sila rujuk kertas asal untuk lebih banyak hasil eksperimen.
Atas ialah kandungan terperinci RAG atau penalaan halus? Microsoft telah mengeluarkan panduan kepada proses pembinaan aplikasi model besar dalam bidang tertentu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
 Pertukaran Bitcoin
Pertukaran Bitcoin
 Tutorial tetapan kata laluan permulaan Windows 10
Tutorial tetapan kata laluan permulaan Windows 10
 Bagaimana untuk menyelesaikan masalah tidak dapat membuat folder baru dalam Win7
Bagaimana untuk menyelesaikan masalah tidak dapat membuat folder baru dalam Win7
 apa itu h5
apa itu h5
 Bagaimana untuk menyemak pautan mati di tapak web anda
Bagaimana untuk menyemak pautan mati di tapak web anda
 Bagaimana untuk memulihkan fail yang dikosongkan daripada Recycle Bin
Bagaimana untuk memulihkan fail yang dikosongkan daripada Recycle Bin
 Pengenalan kepada pemalam yang diperlukan untuk vscode menjalankan java
Pengenalan kepada pemalam yang diperlukan untuk vscode menjalankan java








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



