


.

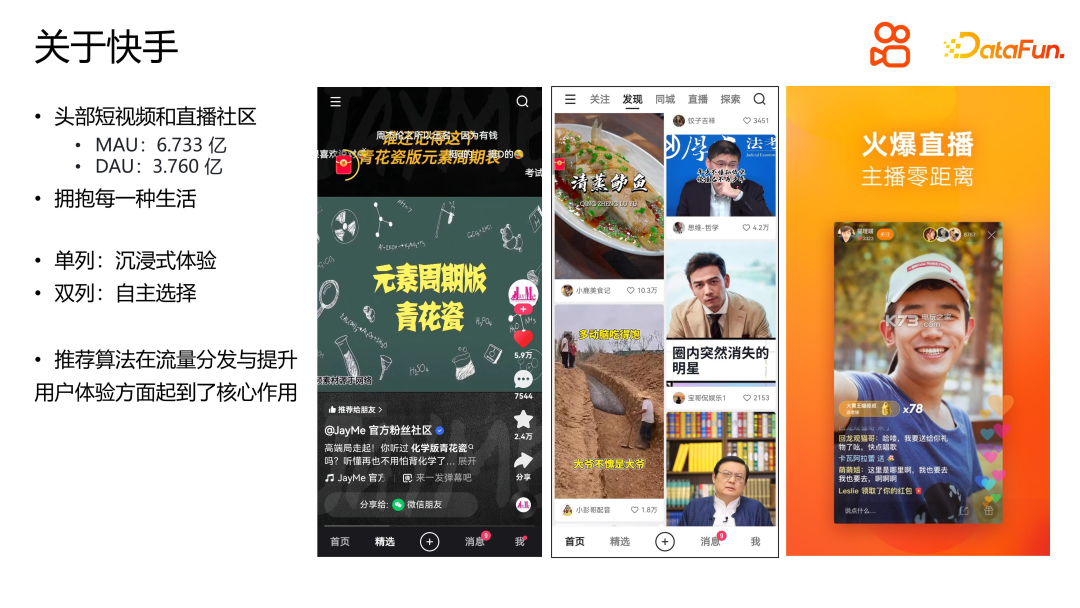
Sistem pengesyoran adalah berdasarkan pembelajaran mesin dan pembelajaran mendalam, dan log terutamanya datang daripada ciri dan maklum balas yang dijana oleh gelagat sebenar pengguna. Walau bagaimanapun, log mempunyai had dan hanya boleh menggambarkan maklumat terhad tentang minat semasa pengguna, dan maklumat peribadi seperti nama sebenar, ketinggian dan berat tidak boleh diperolehi. Pada masa yang sama, algoritma pengesyoran adalah berdasarkan pembelajaran dan latihan log sebelumnya, dan kemudian mengesyorkannya kepada pengguna, yang mempunyai ciri-ciri gelung kendiri. Di samping itu, disebabkan khalayak yang luas dan pelbagai, bilangan video yang banyak dan kemas kini yang kerap, sistem pengesyoran terdedah kepada pelbagai berat sebelah, seperti berat sebelah populariti, berat sebelah pendedahan video panjang dan pendek, dsb. Dalam pengesyoran video pendek, pemodelan bias menggunakan teknologi inferens sebab boleh membantu membetulkan bias dan meningkatkan kesan pengesyoran.
2. Teknologi inferens sebab dan perwakilan model

Sistem yang disyorkan biasanya melaksanakan pembelajaran model dengan menganalisis log interaksi. Maklum balas pengguna bukan sahaja datang daripada menyukai kandungan, tetapi juga dipengaruhi oleh mentaliti kumpulan. Mengambil pilihan filem sebagai contoh, pengguna mungkin mempertimbangkan status karya yang memenangi anugerah atau pendapat orang di sekeliling mereka semasa membuat keputusan. Terdapat perbezaan dalam mentaliti kumpulan dalam kalangan pengguna yang berbeza Sesetengah pengguna lebih subjektif dan bebas, manakala sesetengah pengguna lebih terdedah kepada pengaruh orang lain atau populariti. Oleh itu, apabila mengaitkan interaksi pengguna, selain mempertimbangkan minat pengguna, ia juga perlu untuk mempertimbangkan faktor psikologi kumpulan.
Kerja berkaitan item. Gambar rajah hubungan sebab-akibat ditunjukkan di sebelah kiri, dan hubungannya agak mudah. Dalam pemodelan khusus, perwakilan pengguna dan item dibahagikan kepada perwakilan minat dan perwakilan pematuhan. Untuk ungkapan minat, kerugian faedah dibina untuk ungkapan pematuhan, kerugian pengesahan dibina untuk tingkah laku maklum balas, kerugian klik dibina; Disebabkan oleh pemisahan struktur perwakilan, kerugian faedah digunakan sebagai isyarat penyeliaan untuk mempelajari perwakilan faedah, manakala kerugian pengesahan digunakan untuk memodelkan perwakilan mentaliti kumpulan. Kehilangan klik berkaitan dengan dua faktor dan oleh itu dibina oleh penggabungan dan persilangan. Keseluruhan pendekatan adalah jelas dan mudah.
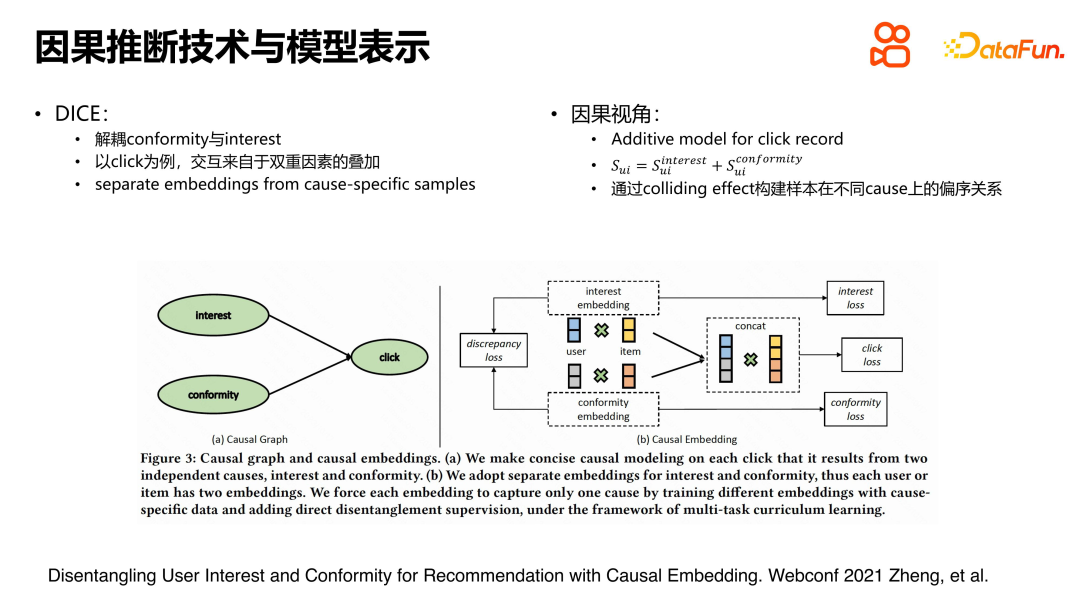
Apabila menyelesaikan masalah kompleks dalam sistem pengesyoran, sesetengah penyelidikan bermula daripada perwakilan model, bertujuan untuk membezakan minat pengguna terhadap item dan mentaliti kumpulan. Walau bagaimanapun, terdapat beberapa masalah dalam aplikasi praktikal. Terdapat sejumlah besar video dalam sistem pengesyoran, dan dedahan diedarkan secara tidak rata. Sparsity membawa kesukaran pembelajaran kepada model pembelajaran mesin.
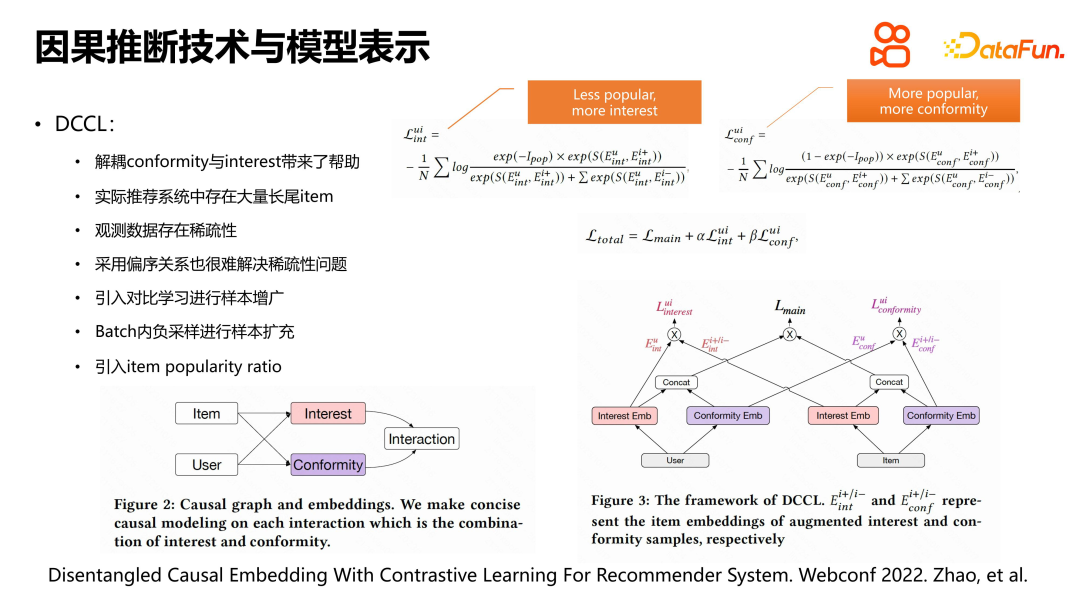
Untuk menyelesaikan masalah ini, kami memperkenalkan pembelajaran kontrastif untuk penambahan sampel. Khususnya, sebagai tambahan kepada interaksi positif antara pengguna dan item, kami juga memilih video lain dalam julat tingkah laku pengguna sebagai sampel negatif untuk pengembangan. Pada masa yang sama, kami menggunakan rajah sebab dan akibat untuk mereka bentuk model dan membahagikan perwakilan minat dan pematuhan pada sisi pengguna dan item. Perbezaan utama antara model ini dan DICE tradisional ialah ia menggunakan kaedah pembelajaran kontrastif dan penambahan sampel apabila mempelajari kehilangan minat dan pengesahan, dan membina istilah indeks nisbah ternormal populariti item untuk kehilangan faedah dan kerugian pengesahan masing-masing. Dengan cara ini, masalah sparsity data boleh dikendalikan dengan lebih baik dan minat dan mentaliti kumpulan pengguna untuk item yang berbeza populariti boleh dimodelkan dengan lebih tepat. 3. Ringkasan Pada masa yang sama, memandangkan masalah jarang sampel video ekor panjang dalam sistem sebenar, kaedah pembelajaran kontrastif dan penambahan sampel digunakan untuk mengurangkan keterlaluan. Kerja ini menggabungkan model perwakilan dalam talian dan inferens sebab untuk mencapai kesan penyahgandingan pematuhan tertentu. Kaedah ini berprestasi baik dalam percubaan luar talian dan dalam talian, dan telah berjaya digunakan dalam percubaan LTR pengesyoran Kuaishou, yang membawa peningkatan kesan tertentu.
3. Anggaran tempoh tontonan dan teknologi inferens sebab
1. Kepentingan tempoh tontonan
Panjang video adalah salah satu faktor penting yang mempengaruhi masa tontonan. Apabila panjang video bertambah, masa tontonan pengguna juga akan meningkat dengan sewajarnya, tetapi video yang terlalu panjang boleh membawa kepada kesan marginal yang berkurangan, atau bahkan pengurangan sedikit dalam masa tontonan. Oleh itu, sistem pengesyoran perlu mencari titik keseimbangan untuk mengesyorkan panjang video yang sesuai dengan keperluan pengguna.
Untuk mengoptimumkan masa tontonan, sistem pengesyoran perlu meramalkan masa tontonan pengguna. Ini melibatkan masalah regresi kerana tempoh adalah nilai berterusan. Walau bagaimanapun, terdapat kurang kerja yang berkaitan dengan tempoh, mungkin kerana perniagaan pengesyoran video pendek agak baharu, manakala penyelidikan sistem pengesyoran mempunyai sejarah yang panjang.
Apabila menyelesaikan masalah anggaran masa tontonan, faktor lain selain panjang video boleh dipertimbangkan, seperti minat pengguna, kualiti kandungan video, dsb. Dengan mengambil kira faktor ini, ketepatan ramalan dipertingkatkan dan pengguna diberikan pengalaman pengesyoran yang lebih baik. Pada masa yang sama, kami juga perlu meneruskan dan mengoptimumkan algoritma pengesyoran secara berterusan untuk menyesuaikan diri dengan perubahan dalam pasaran dan perubahan dalam keperluan pengguna.
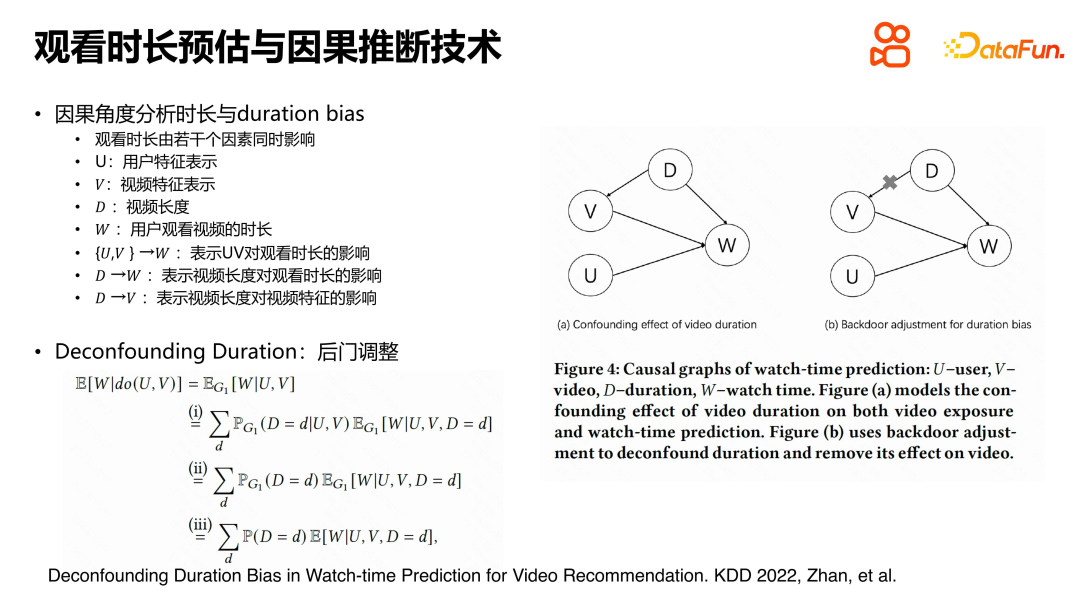
Pada persidangan KDD212, kami mencadangkan kaedah baharu untuk menyelesaikan masalah anggaran tempoh dalam cadangan video pendek. Masalah ini terutamanya berpunca daripada fenomena pengukuhan kendiri bias tempoh dalam inferens sebab. Untuk menangani isu ini, kami memperkenalkan rajah sebab dan akibat untuk menerangkan hubungan antara pengguna, video dan tempoh tontonan.
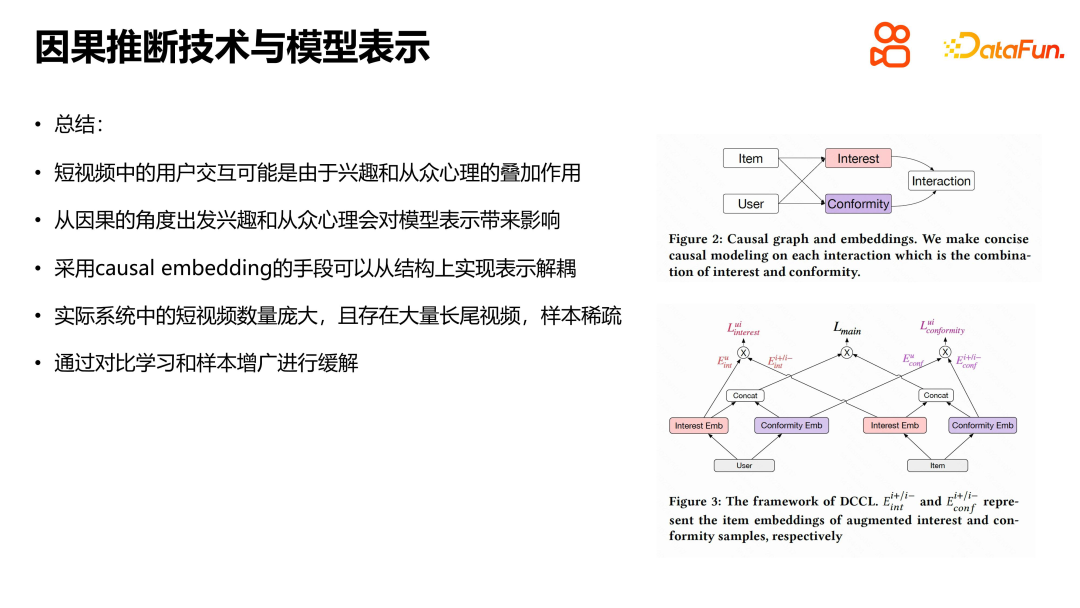
Dalam rajah sebab, U dan V masing-masing mewakili perwakilan ciri pengguna dan video, W mewakili tempoh masa pengguna menonton video, dan D mewakili panjang video. Kami mendapati bahawa disebabkan proses penjanaan kitaran kendiri sistem pengesyoran, tempoh bukan sahaja berkaitan secara langsung dengan tempoh tontonan, tetapi juga mempengaruhi pembelajaran perwakilan video.
Untuk menghapuskan kesan tempoh pada perwakilan video, kami menggunakan kalkulus buat untuk terbitan. Kesimpulan akhir menunjukkan bahawa untuk menyelesaikan masalah ini melalui pelarasan pintu belakang, kaedah yang paling mudah dan paling langsung ialah menganggarkan secara berasingan tempoh tontonan untuk sampel yang sepadan dengan setiap video tempoh. Ini boleh menghapuskan kesan penguatan tempoh pada tempoh tontonan, dengan itu menyelesaikan masalah bias jangka masa dalam inferens sebab akibat. Idea teras kaedah ini adalah untuk menghapuskan ralat dari d ke v, dengan itu mengurangkan penguatan bias.

Apabila menyelesaikan masalah anggaran tempoh dalam pengesyoran video pendek, kami menggunakan kaedah berdasarkan inferens sebab untuk menghapuskan ralat dari d ke v dan mencapai pengurangan penguatan pincang. Untuk menangani masalah tempoh sebagai pembolehubah berterusan dan taburan bilangan video, kami mengumpulkan video dalam kumpulan cadangan mengikut tempoh dan menggunakan kuantiti untuk pengiraan. Data dalam setiap kumpulan dibahagikan dan digunakan untuk melatih model dalam kumpulan. Semasa proses latihan, kuantil yang sepadan dengan tempoh video dalam setiap kumpulan tempoh diundur dan bukannya secara terus mengundurkan tempoh tersebut. Ini mengurangkan keterlanjuran data dan mengelakkan model yang berlebihan. Semasa inferens dalam talian, untuk setiap video, mula-mula cari kumpulan yang sepadan, dan kemudian hitung kuantiti tempoh yang sepadan. Dengan melihat jadual, anda boleh mencari masa tontonan sebenar berdasarkan kuantiti. Kaedah ini memudahkan proses penaakulan dalam talian dan meningkatkan ketepatan anggaran tempoh. Ringkasnya, kaedah kami secara berkesan menyelesaikan masalah anggaran tempoh dalam pengesyoran video pendek dengan menghapuskan ralat dari d hingga v, dan menyediakan sokongan kuat untuk mengoptimumkan pengalaman pengguna.
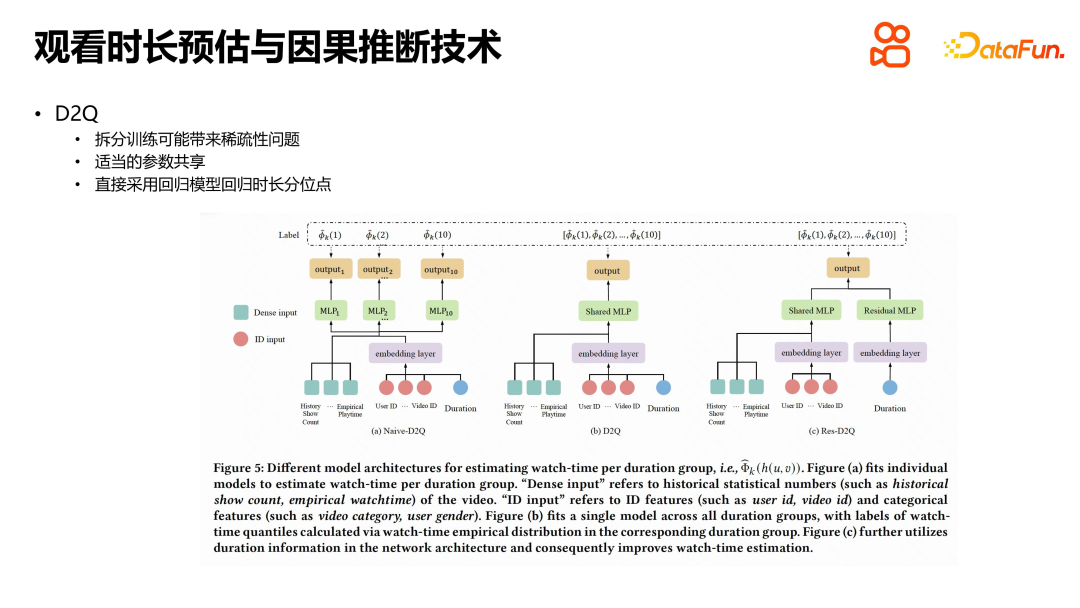
Apabila menyelesaikan masalah anggaran tempoh dalam cadangan video pendek, kami juga memperkenalkan kaedah perkongsian parameter untuk mengurangkan kesukaran teknikal. Dalam proses latihan berpecah, pendekatan yang ideal adalah untuk mencapai pengasingan lengkap data, ciri dan model, tetapi ini akan meningkatkan kos penggunaan. Oleh itu, kami memilih cara yang lebih mudah, iaitu berkongsi pembenaman ciri asas dan parameter model lapisan tengah, dan hanya membahagikannya dalam lapisan keluaran. Untuk mengembangkan lagi kesan tempoh pada tempoh tontonan sebenar, kami memperkenalkan sambungan baki untuk menyambung terus tempoh ke bahagian yang mengeluarkan kuantiti jangka masa yang dianggarkan, dengan itu meningkatkan pengaruh tempoh. Kaedah ini mengurangkan kesukaran teknikal dan berkesan menyelesaikan masalah anggaran tempoh dalam cadangan video pendek.
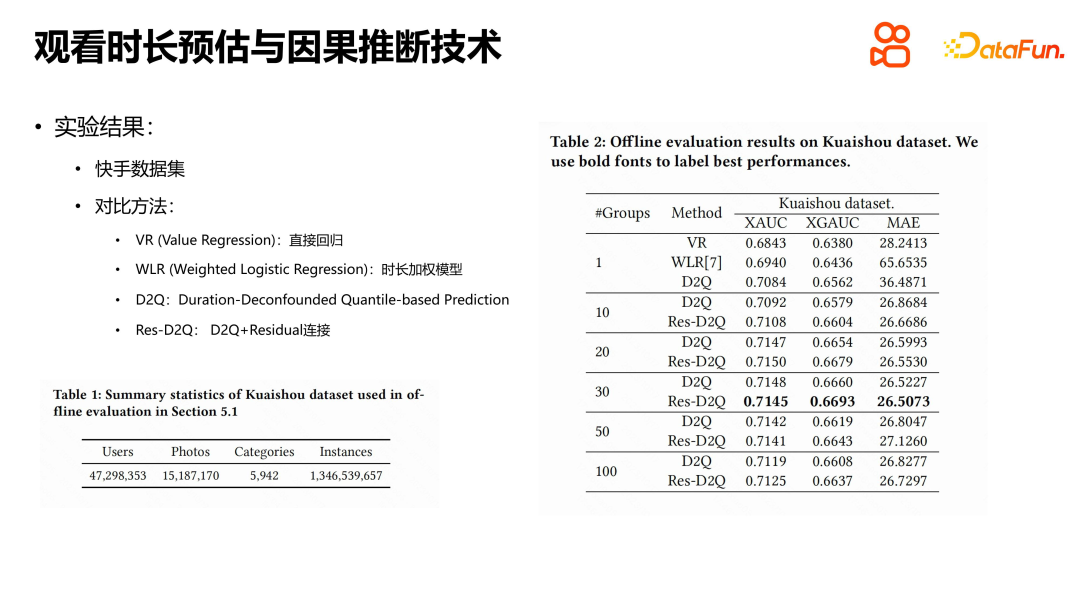
Dalam percubaan, set data awam yang dikeluarkan oleh Kuaishou digunakan terutamanya. Dengan membandingkan beberapa kaedah, kita dapat melihat bahawa prestasi regresi langsung dan model berwajaran tempoh mempunyai kelebihan tersendiri. Model berwajaran tempoh tidak asing dengan sistem pengesyoran Idea terasnya ialah memasukkan tempoh tontonan sebagai berat sampel positif ke dalam model. D2Q dan Res-D2Q ialah dua struktur model berdasarkan inferens sebab, antaranya Res-D2Q memperkenalkan sambungan baki. Melalui percubaan, kami mendapati bahawa hasil terbaik boleh dicapai apabila video dikumpulkan kepada 30 kumpulan mengikut tempoh. Berbanding dengan model regresi naif, kaedah D2Q mempunyai penambahbaikan yang ketara dan boleh mengurangkan masalah penguatan gelung kendiri bagi pincang tempoh pada tahap tertentu. Walau bagaimanapun, dari perspektif masalah anggaran tempoh, cabaran itu masih belum diselesaikan sepenuhnya.
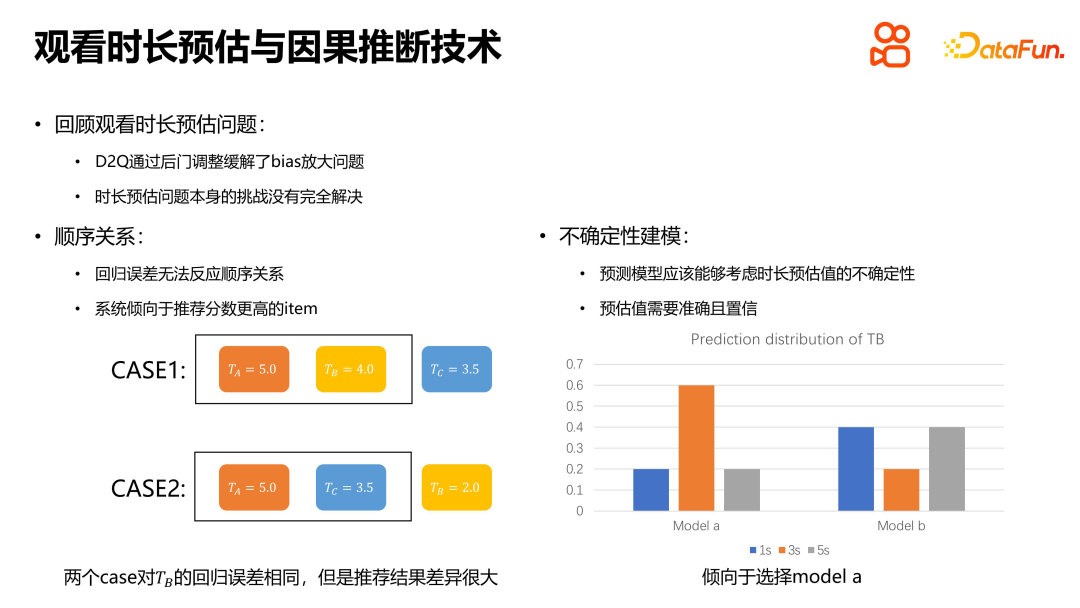
Sebagai isu teras dalam sistem pengesyoran, masalah anggaran tempoh masa mempunyai ciri dan cabaran tersendiri. Pertama, model regresi tidak dapat mencerminkan hubungan berjujukan hasil pengesyoran, jadi walaupun ralat regresi adalah sama, hasil pengesyoran sebenar mungkin sangat berbeza. Selain itu, selain memastikan ketepatan anggaran, model ramalan juga perlu mengambil kira keyakinan anggaran yang diberikan oleh model. Model yang boleh dipercayai bukan sahaja harus memberikan anggaran yang tepat, tetapi juga memberikan anggaran itu dengan kebarangkalian yang tinggi. Oleh itu, apabila menyelesaikan masalah anggaran tempoh, kita bukan sahaja perlu memberi perhatian kepada ketepatan regresi, tetapi juga mempertimbangkan keyakinan model dan hubungan tertib nilai anggaran.
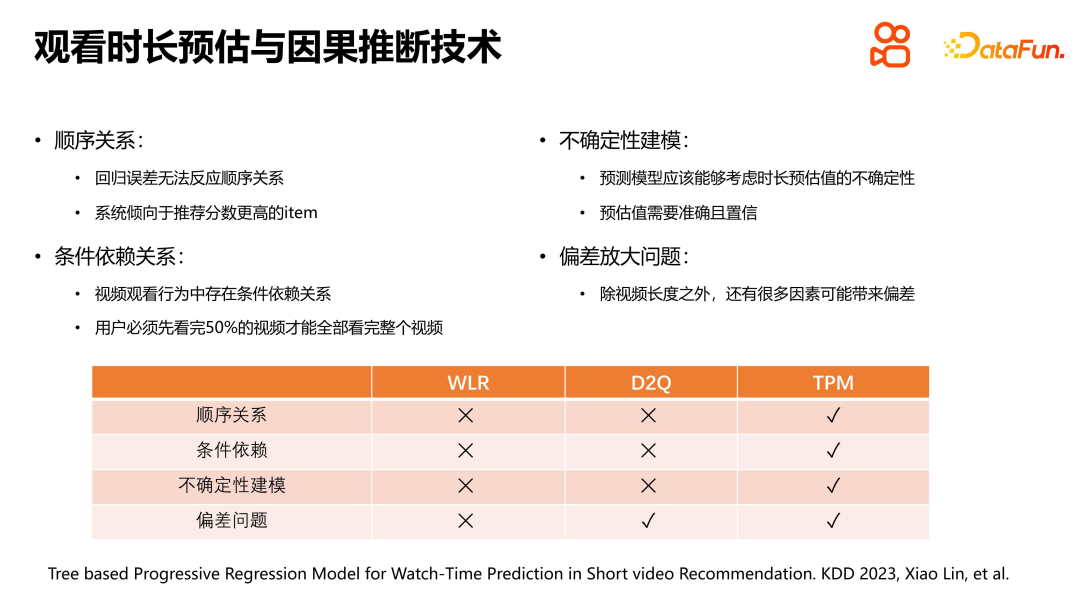
Dalam tingkah laku tontonan, terdapat pergantungan bersyarat pada tontonan berterusan pengguna terhadap video. Khususnya, jika menonton keseluruhan video adalah peristiwa rawak, maka menonton 50% video terlebih dahulu juga merupakan peristiwa rawak, dan terdapat pergantungan bersyarat yang ketat antara mereka. Menyelesaikan masalah penguatan pincang adalah sangat penting dalam melihat anggaran masa, dan kaedah D2Q menyelesaikan masalah ini dengan baik. Sebaliknya, pendekatan TPM kami yang dicadangkan bertujuan untuk merangkumi semua masalah anggaran tempoh secara menyeluruh.
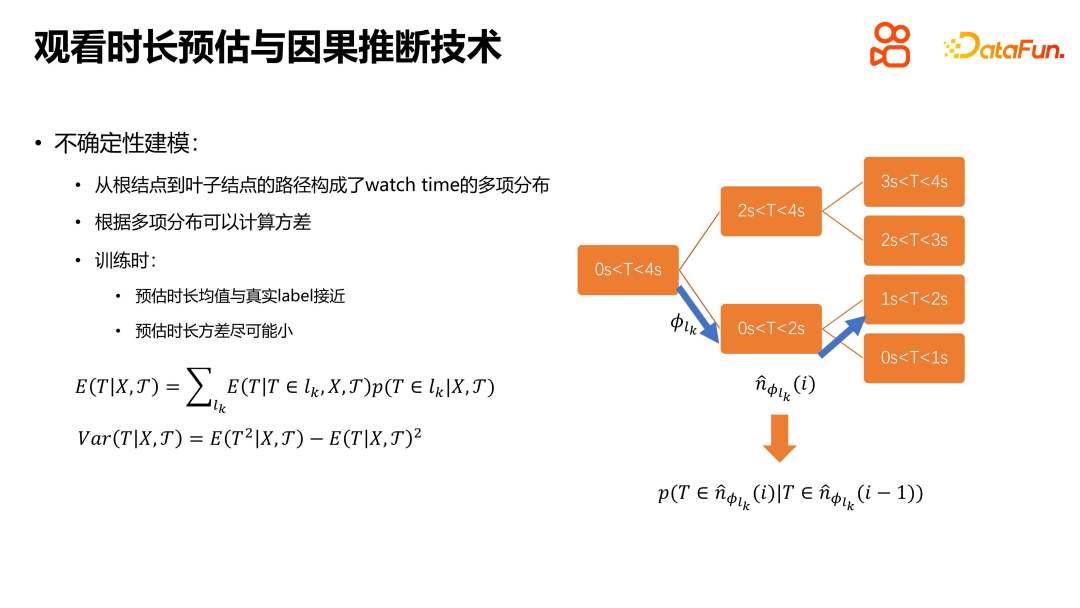
Idea utama kaedah TPM adalah untuk mengubah masalah anggaran tempoh kepada masalah carian diskret. Dengan membina pokok binari yang lengkap, masalah anggaran tempoh diubah menjadi beberapa masalah pengelasan yang bergantung secara bersyarat antara satu sama lain, dan kemudian pengelas binari digunakan untuk menyelesaikan masalah pengelasan ini. Dengan terus melakukan carian binari ke bawah, kebarangkalian tempoh tontonan dalam setiap selang tertib ditentukan, dan akhirnya taburan multinomial tempoh tontonan terbentuk. Kaedah ini boleh menyelesaikan masalah pemodelan ketidakpastian dengan berkesan, menjadikan purata jangka masa anggaran sedekat mungkin dengan nilai sebenar, sambil mengurangkan varians tempoh anggaran. Keseluruhan masalah masa tontonan atau proses anggaran boleh diselesaikan secara beransur-ansur dengan menyelesaikan masalah klasifikasi binari yang saling bergantung secara berterusan. Kaedah ini menyediakan idea dan rangka kerja baharu untuk menyelesaikan masalah anggaran tempoh, yang boleh meningkatkan ketepatan dan keyakinan anggaran.
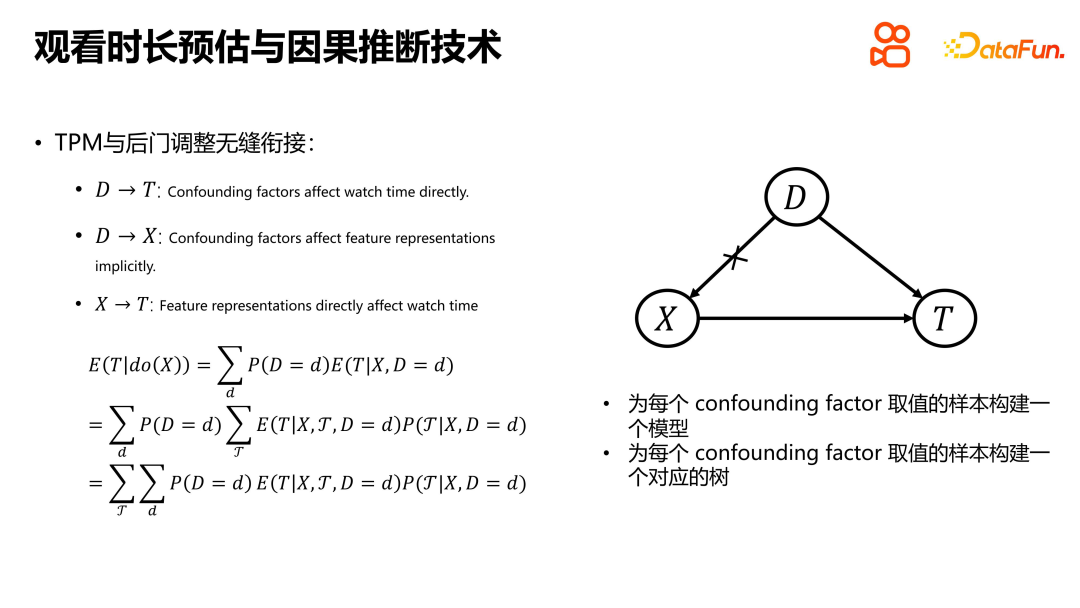
Memperkenalkan idea memodelkan tempoh kritikal TPM, ia menunjukkan sambungan lancar antara pelarasan pintu belakang TPM dan D2Q. Di sini, rajah sebab-akibat yang mudah digunakan untuk mengaitkan ciri sisi pengguna dan item dengan faktor yang mengelirukan. Untuk melaksanakan pelarasan pintu belakang dalam TPM, adalah perlu untuk membina model yang sepadan untuk setiap sampel dengan nilai faktor pengeliru, dan membina pepohon TPM yang sepadan untuk setiap faktor pengeliru. Setelah kedua-dua langkah ini selesai, TPM boleh disambungkan dengan lancar ke pelarasan pintu belakang. Sambungan jenis ini membolehkan model mengendalikan faktor yang mengelirukan dengan lebih baik, meningkatkan ketepatan ramalan dan keyakinan.
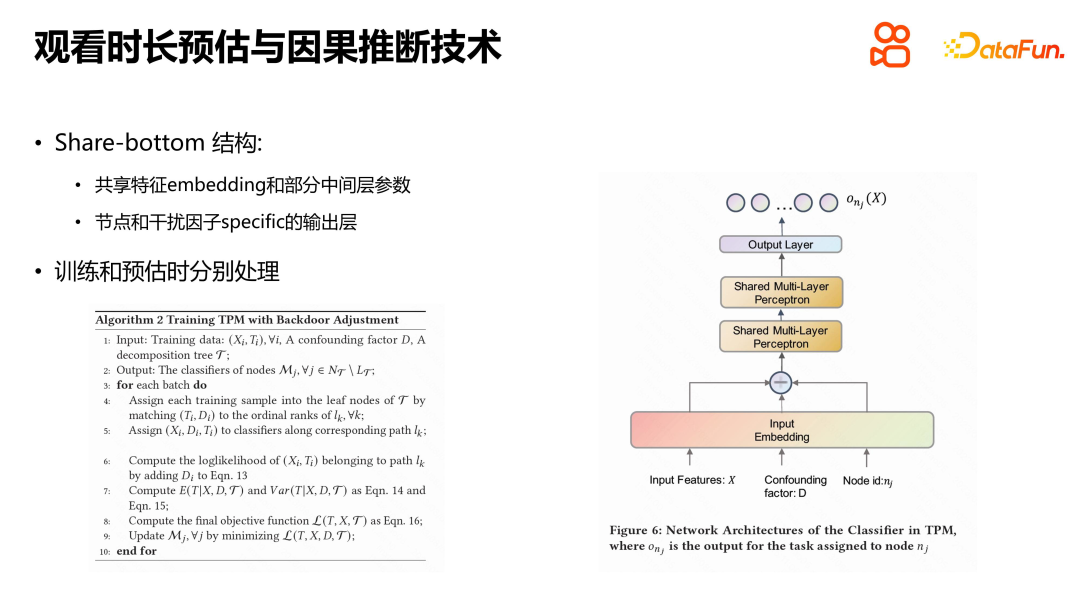
Penyelesaian khusus adalah untuk membina model yang sepadan untuk setiap faktor pengacau peringkat dalam, seperti D2Q, ini juga akan membawa masalah kelangkaan data dan terlalu banyak parameter model, dan memerlukan pemprosesan bahagian bawah untuk menukar setiap sampel. setiap faktor pengacau disepadukan ke dalam model yang sama, tetapi perwakilan pembenaman asas, parameter perantaraan, dsb. model semuanya dikongsi, dan hanya berkaitan dengan nod sebenar dan nilai faktor gangguan dalam lapisan keluaran. Semasa latihan, anda hanya perlu mencari nod daun sebenar yang sepadan dengan setiap sampel latihan untuk latihan. Apabila menganggarkan, kerana kita tidak tahu yang mana nod daun mempunyai tempoh tontonan, kita perlu merentasi dari atas ke bawah, dan menimbang jumlah kebarangkalian setiap nod daun di mana tempoh tontonan berada dan jangkaan jangka masa nod daun yang sepadan untuk mendapatkan masa tontonan Sebenar. Kaedah pemprosesan ini membolehkan model mengendalikan faktor yang mengelirukan dengan lebih baik dan meningkatkan ketepatan dan keyakinan ramalan.
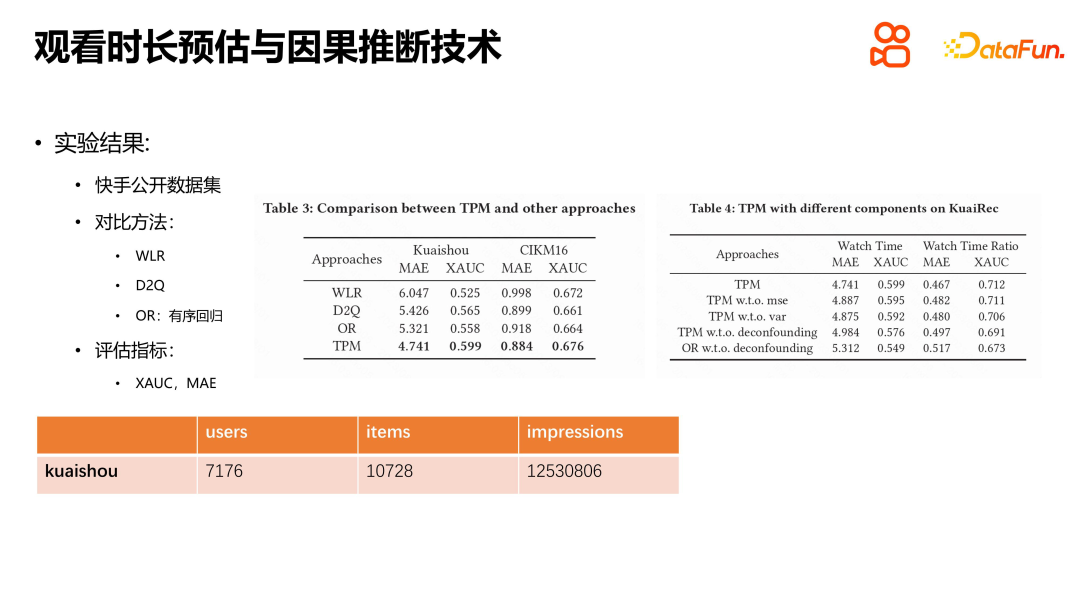
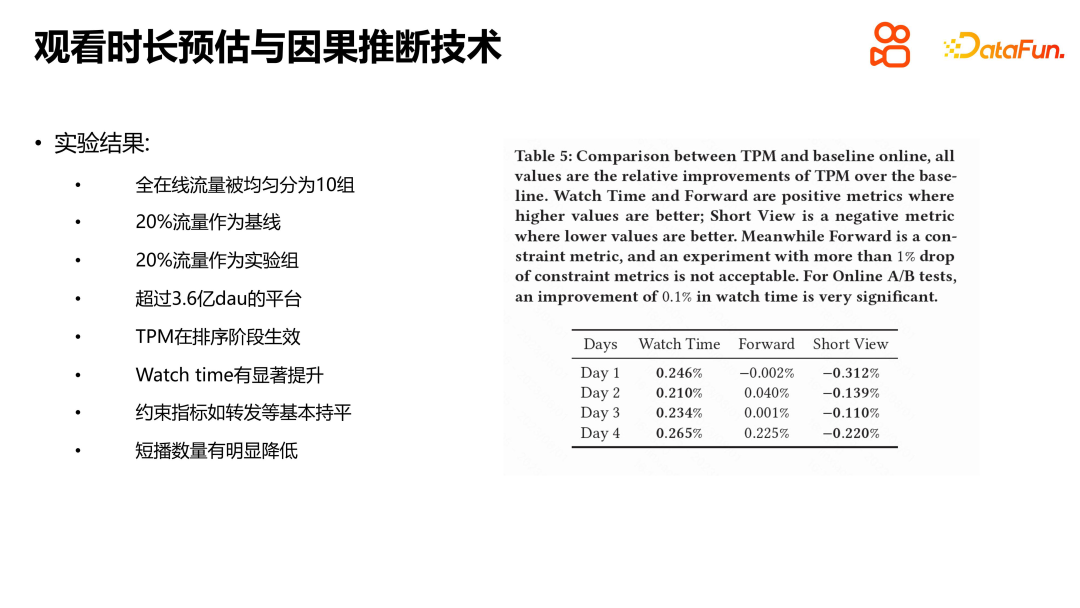
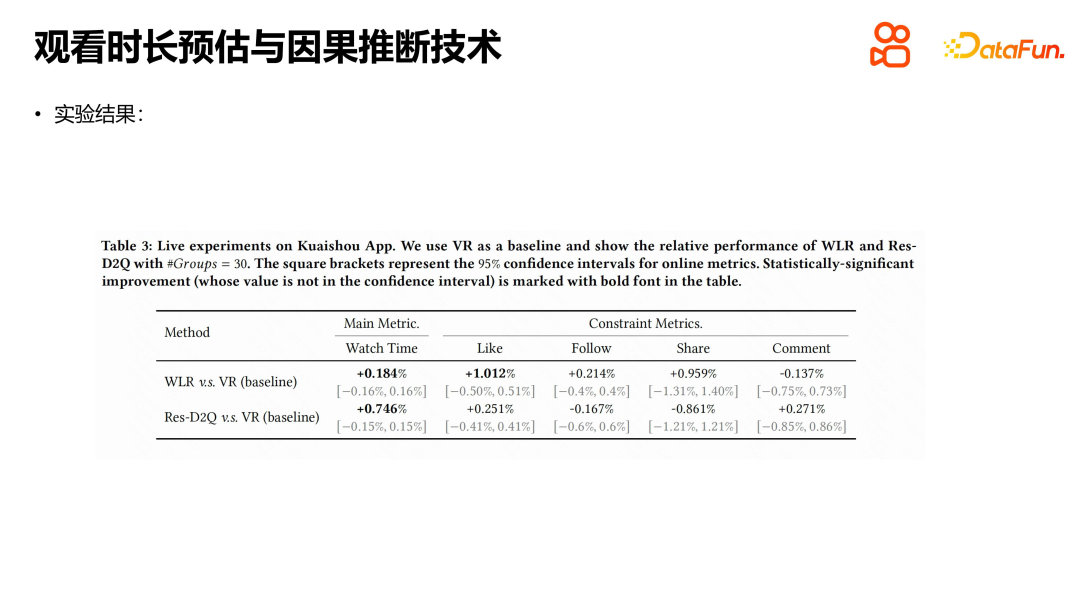
Kami menjalankan eksperimen pada set data awam Kuaishou dan set data CIKM16 pada masa tinggal, membandingkan kaedah seperti WLR, D2Q dan OR, dan keputusan menunjukkan bahawa TPM mempunyai kelebihan yang ketara. Setiap modul mempunyai peranan tertentu, dan kami juga menjalankan eksperimen lalai Hasil percubaan menunjukkan bahawa setiap modul memainkan peranan. Kami juga bereksperimen dengan TPM dalam talian Syarat percubaan adalah untuk membahagikan trafik terpilih Kuaishou secara sama rata kepada sepuluh kumpulan, dan 20% daripada trafik digunakan sebagai garis dasar untuk perbandingan dengan kumpulan percubaan dalam talian. Keputusan percubaan menunjukkan bahawa TPM boleh meningkatkan masa tontonan pengguna dengan ketara dalam peringkat pengisihan, manakala penunjuk lain pada asasnya kekal sama. Perlu diingat bahawa penunjuk negatif seperti bilangan gelombang pendek pengguna juga telah menurun, yang kami percaya mempunyai hubungan tertentu dengan ketepatan anggaran tempoh dan pengurangan ketidakpastian dalam anggaran. Tempoh tontonan ialah penunjuk teras platform pengesyoran video pendek, dan pengenalan TPM adalah sangat penting untuk meningkatkan pengalaman pengguna dan penunjuk platform.
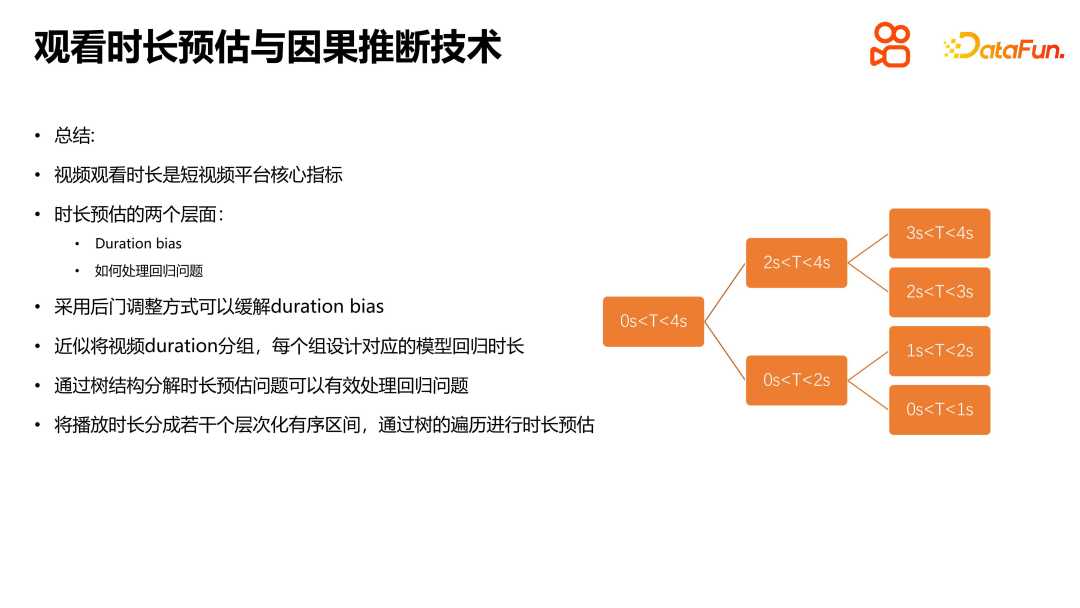
Mari ringkaskan bahagian pengenalan ini. Dalam platform cadangan video pendek, masa tontonan ialah penunjuk teras. Terdapat dua peringkat yang perlu dipertimbangkan dalam menyelesaikan masalah ini: satu ialah masalah berat sebelah, termasuk berat sebelah tempoh dan berat sebelah populariti, yang perlu diselesaikan dalam gelung kendiri bagi keseluruhan log pautan sistem kepada latihan; , yang itu sendiri adalah masalah ramalan Nilai berterusan biasanya sepadan dengan masalah regresi. Walau bagaimanapun, untuk masalah regresi anggaran tempoh khas, kaedah khusus perlu digunakan. Pertama sekali, masalah berat sebelah boleh dikurangkan melalui pelarasan pintu belakang Kaedah khusus adalah untuk mengumpulkan tempoh dan mereka bentuk model yang sepadan untuk setiap kumpulan untuk regresi. Kedua, untuk menangani masalah regresi anggaran tempoh, struktur pokok boleh digunakan untuk menguraikan anggaran tempoh kepada beberapa selang tertib hierarki Melalui proses lintasan pokok, masalah itu boleh dirungkai di sepanjang laluan dari atas ke nod daun . Semasa menganggar, tempoh dianggarkan melalui lintasan pokok. Kaedah pemprosesan ini boleh menyelesaikan masalah regresi anggaran tempoh dengan lebih berkesan dan meningkatkan ketepatan dan keyakinan ramalan.
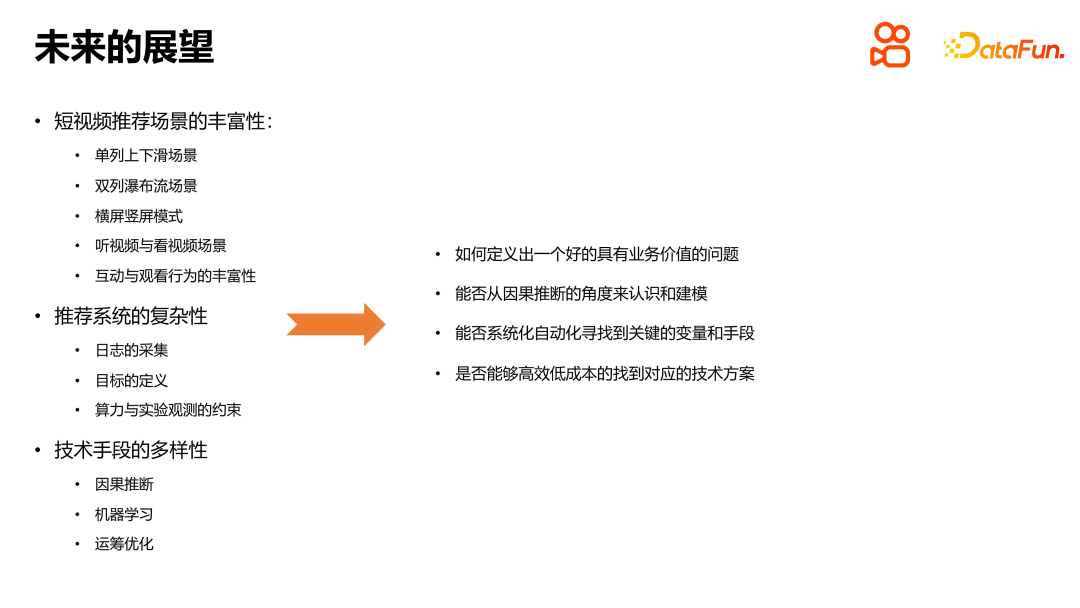
Dengan kepesatan pembangunan teknologi, dunia yang kita diami menjadi semakin kompleks. Dalam senario pengesyoran video pendek Kuaishou, kerumitan sistem pengesyoran telah menjadi semakin menonjol. Untuk membuat cadangan yang lebih baik, kita perlu mengkaji secara mendalam aplikasi inferens sebab dalam sistem pengesyoran. Pertama, kita perlu menentukan masalah dengan nilai perniagaan, seperti anggaran masa tontonan. Kita kemudiannya boleh memahami dan memodelkan masalah ini dari perspektif inferens kausal. Melalui kaedah pelarasan sebab akibat atau inferens sebab, kita boleh menganalisis dan menyelesaikan masalah berat sebelah dengan lebih baik, seperti berat sebelah tempoh dan berat sebelah populariti. Selain itu, kami juga boleh menggunakan cara teknikal, seperti pembelajaran mesin dan pengoptimuman operasi, untuk menyelesaikan masalah seperti kerumitan sistem dan pengedaran pemandangan. Untuk mencapai penyelesaian yang cekap, kita perlu mencari cara yang sistematik dan automatik untuk menyelesaikan masalah tersebut. Ini bukan sahaja meningkatkan kecekapan kerja, tetapi juga membawa nilai berterusan kepada perniagaan. Akhir sekali, kita perlu menumpukan pada skalabiliti dan keberkesanan kos teknologi untuk memastikan kebolehlaksanaan dan kemampanan penyelesaian.
Ringkasnya, penggunaan inferens sebab dalam sistem pengesyoran ialah hala tuju penyelidikan yang mencabar dan berpotensi. Melalui penerokaan dan amalan berterusan, kami boleh terus meningkatkan keberkesanan sistem pengesyoran, membawa pengalaman yang lebih baik kepada pengguna dan mencipta nilai yang lebih besar untuk perniagaan.
Di atas adalah kandungan yang dikongsikan kali ini, terima kasih semua.
A1: Melangkah dari nod kepala ke nod daun boleh dianggap sebagai proses membuat keputusan yang berterusan serupa dengan MDP. Pergantungan bersyarat bermakna keputusan lapisan seterusnya adalah berdasarkan keputusan lapisan sebelumnya. Contohnya, untuk mencapai nod daun, iaitu selang [0,1], anda mesti terlebih dahulu melalui nod perantaraan, iaitu selang [0,2]. Kebergantungan ini direalisasikan dalam anggaran dalam talian sebenar oleh setiap pengelas yang hanya menyelesaikan sama ada nod tertentu harus pergi ke nod daun seterusnya. Ia seperti dalam contoh meneka umur, mula-mula bertanya sama ada umur lebih daripada 50, dan kemudian bergantung kepada jawapan, bertanya sama ada umur lebih daripada 25. Terdapat pergantungan bersyarat yang tersirat di sini, iaitu umur di bawah 50 tahun adalah prasyarat untuk menjawab soalan kedua.
A2: Dalam perbandingan kelebihan TPM dan D2Q, kelebihan utama terletak pada pembahagian masalah. TPM menggunakan maklumat temporal dengan lebih baik dan membahagikan masalah kepada beberapa masalah klasifikasi binari dengan sampel yang agak seimbang, yang menyumbang kepada kebolehpelajaran latihan dan pembelajaran model. Sebaliknya, masalah regresi mungkin dipengaruhi oleh outlier dan outlier lain, menyebabkan ketidakstabilan pembelajaran yang lebih besar. Dalam aplikasi praktikal, kami telah menjalankan banyak kerja amali, termasuk pembinaan sampel dan pengiraan label nod graf TF. Apabila digunakan dalam talian, kami menggunakan model, tetapi dimensi outputnya ialah bilangan pengelas nod perantaraan. Untuk setiap video, kami hanya memilih satu daripada kumpulan tempoh dan mengira output pengelas yang sepadan. Kemudian pengedaran pada nod daun dikira melalui gelung, dan akhirnya jumlah wajaran dilakukan. Walaupun struktur model agak mudah, pengelas setiap kumpulan tempoh dan setiap nod bukan daun boleh berkongsi lapisan benam dan perantaraan asas, jadi semasa inferens ke hadapan, kecuali untuk lapisan keluaran, ia tidak jauh berbeza daripada model biasa.
Atas ialah kandungan terperinci Amalan inferens sebab dalam pengesyoran video pendek Kuaishou. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penyelesaian kegagalan sesi
Penyelesaian kegagalan sesi
 Bagaimana untuk menetapkan ppt skrin lebar
Bagaimana untuk menetapkan ppt skrin lebar
 Bolehkah percikan api Douyin dinyalakan semula jika ia telah dimatikan selama lebih daripada tiga hari?
Bolehkah percikan api Douyin dinyalakan semula jika ia telah dimatikan selama lebih daripada tiga hari?
 Mengapakah vue.js melaporkan ralat?
Mengapakah vue.js melaporkan ralat?
 Perkara yang perlu dilakukan jika alamat IP anda diserang
Perkara yang perlu dilakukan jika alamat IP anda diserang
 Perbezaan antara akaun perkhidmatan WeChat dan akaun rasmi
Perbezaan antara akaun perkhidmatan WeChat dan akaun rasmi
 pintu masuk laman web rasmi msdn
pintu masuk laman web rasmi msdn
 Perbezaan antara fprintf dan printf
Perbezaan antara fprintf dan printf








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



