

 Peranti teknologi
AI
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Peranti teknologi
AI
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap

0. Ditulis di hadapan&& pemahaman peribadi
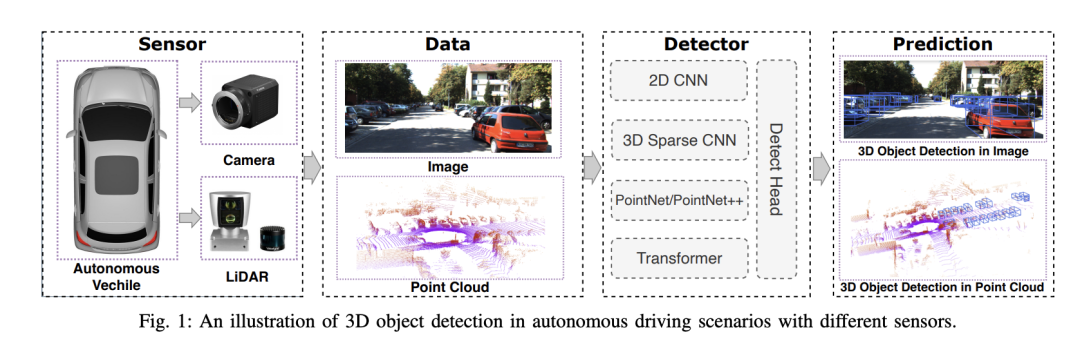
Sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan untuk melihat persekitaran sekeliling melalui penggunaan pelbagai sensor (seperti kamera, lidar, radar, dsb. .), dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara untuk membuat kereta memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek 3D dalam sistem pemanduan autonomi yang boleh melihat dan menerangkan objek dalam persekitaran sekeliling dengan tepat, termasuk lokasi, bentuk, saiz dan kategorinya. Kesedaran alam sekitar yang menyeluruh ini membantu sistem pemanduan autonomi lebih memahami persekitaran pemanduan dan membuat keputusan yang lebih tepat.
Kami menjalankan penilaian komprehensif algoritma pengesanan objek 3D dalam pemanduan autonomi, terutamanya mempertimbangkan keteguhan. Tiga faktor utama telah dikenal pasti dalam penilaian: kebolehubahan persekitaran, bunyi sensor, dan salah jajaran. Faktor ini penting untuk prestasi algoritma pengesanan dalam dunia sebenar, keadaan berubah-ubah.
- Kebolehubahan alam sekitar: Artikel ini menekankan bahawa algoritma pengesanan perlu menyesuaikan diri dengan keadaan persekitaran yang berbeza, seperti perubahan dalam pencahayaan, cuaca dan musim.
- Bunyi penderia: Algoritma mesti menangani hingar penderia dengan berkesan, yang mungkin termasuk isu seperti kabur gerakan kamera.
- Salah jajaran: Untuk salah jajaran yang disebabkan oleh ralat penentukuran atau faktor lain, algoritma perlu mengambil kira faktor ini, sama ada faktor luaran (seperti permukaan jalan yang tidak rata) atau dalaman (seperti salah jajaran jam sistem) .
Juga menyelami tiga bidang utama penilaian prestasi: ketepatan, kependaman dan keteguhan.
- Ketepatan: Walaupun kajian sering menumpukan pada ketepatan sebagai metrik prestasi utama, prestasi dalam keadaan yang kompleks dan ekstrem memerlukan pemahaman yang lebih mendalam untuk memastikan kebolehpercayaan dunia sebenar.
- Latensi: Keupayaan masa nyata dalam pemanduan autonomi adalah penting. Kelewatan dalam kaedah pengesanan memberi kesan kepada keupayaan sistem untuk membuat keputusan tepat pada masanya, terutamanya dalam situasi kecemasan.
- Keteguhan: Meminta penilaian yang lebih komprehensif tentang kestabilan sistem dalam keadaan berbeza, kerana banyak penilaian semasa mungkin tidak mengambil kira sepenuhnya kepelbagaian senario dunia sebenar.
Makalah ini menunjukkan kelebihan ketara kaedah pengesanan 3D berbilang mod dalam persepsi keselamatan Dengan menggabungkan data daripada penderia yang berbeza, ia memberikan keupayaan persepsi yang lebih kaya dan pelbagai, dengan itu meningkatkan keselamatan sistem pemanduan autonomi.
1. Set Data
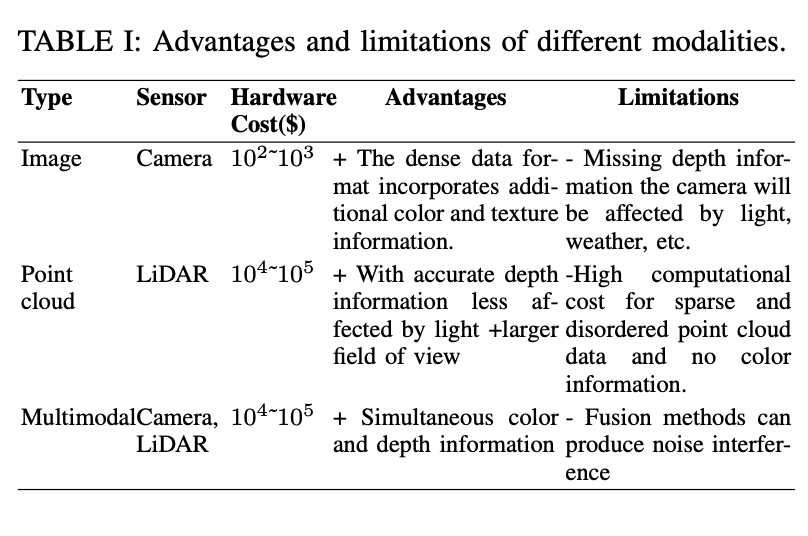
Di atas secara ringkas memperkenalkan set data pengesanan objek 3D yang digunakan dalam sistem pemanduan autonomi, memfokuskan terutamanya pada menilai kelebihan dan batasan mod sensor yang berbeza, serta ciri set data awam .
Pertama, jadual menunjukkan tiga jenis penderia: kamera, awan titik dan berbilang modal (kamera dan lidar). Untuk setiap jenis, kos, kelebihan dan had perkakasan mereka disenaraikan. Kelebihan data kamera ialah ia memberikan maklumat warna dan tekstur yang kaya, tetapi batasannya ialah kekurangan maklumat kedalaman dan kerentanannya kepada kesan cahaya dan cuaca. LiDAR boleh memberikan maklumat kedalaman yang tepat, tetapi mahal dan tidak mempunyai maklumat warna.
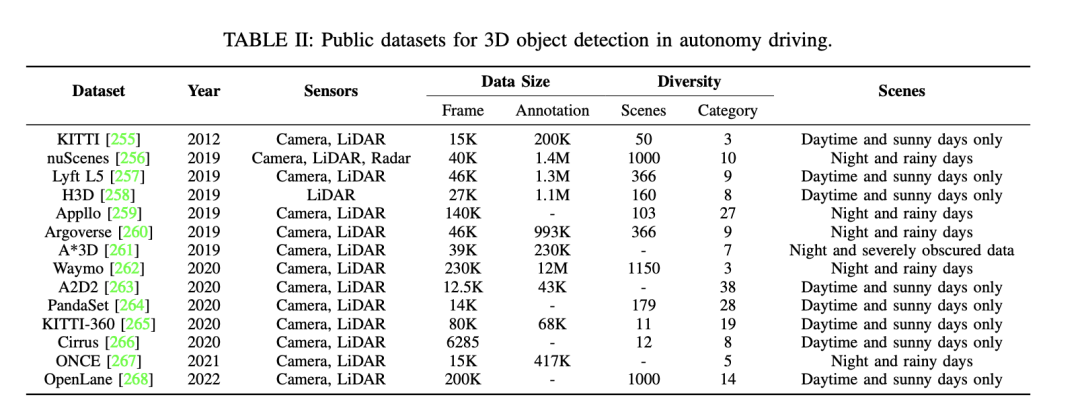
Seterusnya, terdapat beberapa set data awam lain yang tersedia untuk pengesanan objek 3D dalam pemanduan autonomi. Set data ini termasuk KITTI, nuScenes, Waymo, dsb. Butiran set data ini adalah seperti berikut: - Set data KITTI mengandungi data yang dikeluarkan dalam beberapa tahun, menggunakan pelbagai jenis penderia. Ia menyediakan sejumlah besar bingkai dan anotasi, serta pelbagai adegan, termasuk nombor dan kategori adegan, dan jenis pemandangan yang berbeza seperti siang, cerah, malam, hujan, dll. - Set data nuScenes juga merupakan set data penting, yang juga mengandungi data yang dikeluarkan dalam beberapa tahun. Set data ini menggunakan pelbagai penderia dan menyediakan sejumlah besar bingkai dan anotasi. Ia merangkumi pelbagai senario, termasuk nombor dan kategori adegan yang berbeza, serta pelbagai jenis adegan. - Set data Waymo ialah set data lain untuk pemanduan autonomi yang turut mempunyai data dari beberapa tahun. Set data ini menggunakan pelbagai jenis penderia dan menyediakan sejumlah besar bingkai dan anotasi. Ia merangkumi pelbagai bidang
Selain itu, penyelidikan tentang set data pemanduan autonomi "bersih" disebut, dan kepentingan menilai keteguhan model di bawah senario yang bising ditekankan. Sesetengah kajian menumpukan pada kaedah mod tunggal kamera dalam keadaan yang teruk, manakala set data berbilang modal lain memfokuskan pada isu hingar. Sebagai contoh, set data GROUNDED memfokuskan pada kedudukan radar menembusi tanah di bawah keadaan cuaca yang berbeza, manakala set data terbuka ApolloScape termasuk data lidar, kamera dan GPS, meliputi pelbagai cuaca dan keadaan pencahayaan.
Disebabkan kos yang tinggi untuk mengumpul data bising berskala besar di dunia nyata, banyak kajian beralih kepada penggunaan set data sintetik. Sebagai contoh, ImageNet-C ialah kajian penanda aras dalam memerangi gangguan biasa dalam model pengelasan imej. Arah penyelidikan ini kemudiannya diperluaskan kepada set data teguh yang disesuaikan untuk pengesanan objek 3D dalam pemanduan autonomi. Pengesanan objek 3D berasaskan penglihatan Pengesanan objek 3D, pengesanan objek 3D monokular kamera sahaja dan pengesanan objek 3D monokular berbantukan kedalaman.
Pengesanan objek 3D monokular berpandu sebelumnya
Kaedah ini menggunakan pengetahuan sedia ada tentang bentuk objek dan geometri pemandangan yang tersembunyi dalam imej untuk menyelesaikan cabaran pengesanan objek 3D monokular. Dengan memperkenalkan sub-rangkaian terlatih atau tugas tambahan, pengetahuan terdahulu boleh memberikan maklumat atau kekangan tambahan untuk membantu mengesan objek 3D dengan tepat dan meningkatkan ketepatan dan keteguhan pengesanan. Pengetahuan sedia ada termasuk bentuk objek, ketekalan geometri, kekangan temporal dan maklumat pembahagian. Sebagai contoh, algoritma Mono3D mula-mula menganggap bahawa objek 3D terletak pada satah tanah tetap, dan kemudian menggunakan bentuk 3D sebelumnya objek untuk membina semula kotak sempadan dalam ruang 3D. 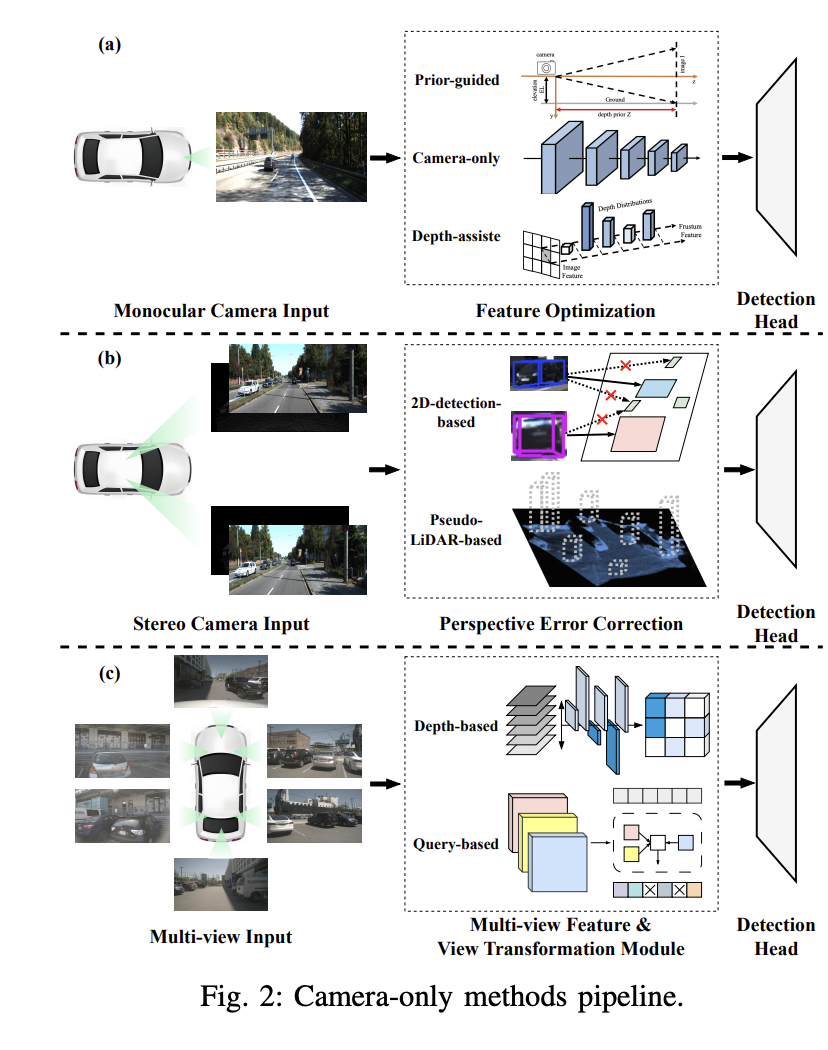
Kamera sahaja pengesanan objek 3D monokular
Kaedah ini hanya menggunakan imej yang ditangkap oleh satu kamera untuk mengesan dan mengesan objek 3D. Ia menggunakan rangkaian neural convolutional (CNN) untuk terus mengundur parameter kotak sempadan 3D daripada imej untuk menganggarkan saiz dan pose objek dalam ruang tiga dimensi. Kaedah regresi langsung ini boleh dilatih secara hujung ke hujung, menggalakkan pembelajaran keseluruhan dan inferens objek 3D. Sebagai contoh, algoritma Smoke meninggalkan regresi kotak sempadan 2D dan meramalkan kotak 3D bagi setiap objek yang dikesan dengan menggabungkan anggaran titik kunci individu dan regresi pembolehubah 3D.
Pengesanan objek 3D bermata berbantukan kedalamanAnggaran kedalaman memainkan peranan penting dalam pengesanan objek 3D monokular berbantukan kedalaman. Untuk mencapai hasil pengesanan monokular yang lebih tepat, banyak kajian menggunakan rangkaian anggaran kedalaman tambahan yang telah terlatih. Proses ini bermula dengan menukar imej monokular kepada imej kedalaman dengan menggunakan penganggar kedalaman yang telah terlatih seperti MonoDepth. Kemudian, dua kaedah utama digunakan untuk memproses imej kedalaman dan imej monokular. Sebagai contoh, pengesan Pseudo-LiDAR menggunakan rangkaian anggaran kedalaman terlatih untuk menjana perwakilan Pseudo-LiDAR, tetapi terdapat jurang prestasi yang besar antara pengesan berasaskan Pseudo-LiDAR dan LiDAR disebabkan oleh ralat dalam penjanaan imej-ke-LiDAR. 
Melalui penerokaan dan aplikasi kaedah ini, pengesanan objek 3D monokular telah mencapai kemajuan yang ketara dalam bidang penglihatan komputer dan sistem pintar, membawa kejayaan dan peluang kepada bidang ini.
2.2 Pengesanan objek 3D berasaskan stereoDalam bahagian ini, teknologi pengesanan objek 3D berdasarkan penglihatan stereo dibincangkan. Pengesanan objek 3D penglihatan stereo menggunakan sepasang imej stereoskopik untuk mengenal pasti dan mencari objek 3D. Dengan mengeksploitasi dwi pandangan yang ditangkap oleh kamera stereo, kaedah ini cemerlang dalam mendapatkan maklumat kedalaman berketepatan tinggi melalui pemadanan stereo dan penentukuran, yang merupakan ciri yang membezakannya daripada tetapan kamera monokular. Walaupun kelebihan ini, kaedah penglihatan stereo masih mengalami jurang prestasi yang besar berbanding kaedah berasaskan lidar. Tambahan pula, kawasan pengesanan objek 3D daripada imej stereo agak kurang diterokai, dengan hanya usaha penyelidikan terhad khusus untuk kawasan ini.
- Kaedah berasaskan pengesanan 2D: Rangka kerja pengesanan objek 2D tradisional boleh diubah suai untuk menyelesaikan masalah pengesanan stereo. Contohnya, Stereo R-CNN menggunakan pengesan 2D berasaskan imej untuk meramalkan cadangan 2D, menjana kawasan minat kiri dan kanan (RoI) untuk imej kiri dan kanan yang sepadan. Selepas itu, pada peringkat kedua, ia menganggarkan parameter objek 3D secara langsung berdasarkan RoI yang dijana sebelum ini. Paradigma ini telah diterima pakai secara meluas dalam kerja-kerja seterusnya.
- Kaedah berasaskan Pseudo-LiDAR: Peta perbezaan yang diramalkan daripada imej stereo boleh ditukar kepada peta kedalaman dan seterusnya ditukar kepada titik LiDAR pseudo. Oleh itu, sama dengan kaedah pengesanan monokular, perwakilan pseudo-lidar juga boleh digunakan dalam kaedah pengesanan objek 3D berasaskan penglihatan stereo. Kaedah ini bertujuan untuk meningkatkan anggaran jurang dalam padanan stereo untuk mencapai ramalan kedalaman yang lebih tepat. Sebagai contoh, Wang et al adalah perintis dalam memperkenalkan perwakilan pseudo-lidar. Perwakilan ini dijana daripada imej dengan peta kedalaman, yang memerlukan model untuk melaksanakan tugas anggaran kedalaman untuk membantu pengesanan. Kerja-kerja seterusnya mengikuti paradigma ini dan memperhalusinya dengan memperkenalkan maklumat warna tambahan untuk meningkatkan awan titik pseudo, tugas tambahan (seperti pembahagian contoh, pembahagian latar depan dan latar belakang, penyesuaian domain) dan menyelaraskan skema transformasi. Perlu diingat bahawa PatchNet yang dicadangkan oleh Ma et al mencabar konsep tradisional menggunakan perwakilan pseudo-lidar untuk pengesanan objek 3D monokular. Dengan pengekodan koordinat 3D untuk setiap piksel, PatchNet boleh mencapai hasil pengesanan monokular yang setanding tanpa perwakilan pseudo-lidar. Pemerhatian ini menunjukkan bahawa kuasa perwakilan pseudo-lidar datang daripada transformasi koordinat dan bukannya perwakilan awan titik itu sendiri.
2.3 Pengesanan objek 3D berbilang paparan
Baru-baru ini, pengesanan objek 3D berbilang paparan telah menunjukkan keunggulan dalam ketepatan dan keteguhan berbanding kaedah pengesanan objek 3D monokular dan stereo yang disebutkan di atas. Tidak seperti pengesanan objek 3D berasaskan LiDAR, kaedah Panoramik Bird's Eye View (BEV) terkini menghapuskan keperluan untuk peta berketepatan tinggi dan meningkatkan pengesanan daripada 2D kepada 3D. Kemajuan ini telah membawa kepada perkembangan ketara dalam pengesanan objek 3D berbilang paparan. Dalam pengesanan objek 3D berbilang kamera, cabaran utama adalah untuk mengenal pasti objek yang sama dalam imej yang berbeza dan ciri badan agregat daripada berbilang input sudut pandangan. Kaedah semasa melibatkan pemetaan berbilang pandangan secara seragam ke dalam ruang Pandangan Mata Burung (BEV), yang merupakan amalan biasa.
Kaedah Berbilang paparan berasaskan kedalaman:
Penukaran terus dari ruang 2D ke BEV menimbulkan cabaran yang ketara. LSS ialah yang pertama mencadangkan kaedah berasaskan kedalaman, yang menggunakan ruang 3D sebagai perantara. Kaedah ini mula-mula meramalkan taburan kedalaman grid bagi ciri 2D dan kemudian mengangkat ciri ini ke dalam ruang voxel. Pendekatan ini menawarkan harapan untuk transformasi yang lebih cekap daripada ruang 2D kepada BEV. Mengikuti LSS, CaDDN menggunakan kaedah perwakilan dalam yang serupa. Dengan memampatkan ciri ruang voxel ke dalam ruang BEV, ia melakukan pengesanan 3D terakhir. Perlu diingat bahawa CaDDN bukan sebahagian daripada pengesanan objek 3D berbilang paparan, tetapi pengesanan objek 3D pandangan tunggal, yang mempunyai kesan ke atas penyelidikan mendalam berikutnya. Perbezaan utama antara LSS dan CaDDN ialah CaDDN menggunakan nilai kedalaman ground-truth sebenar untuk mengawasi ramalan pengedaran kedalaman klasifikasinya, sekali gus mewujudkan rangkaian dalam yang unggul yang mampu mengekstrak maklumat 3D dari ruang 2D dengan lebih tepat.
Kaedah berbilang paparan berasaskan pertanyaan
Di bawah pengaruh teknologi Transformer, kaedah berbilang paparan berasaskan pertanyaan mendapatkan semula ciri ruang 2D daripada ruang 3D. DETR3D memperkenalkan pertanyaan objek 3D untuk menyelesaikan masalah pengagregatan ciri berbilang paparan. Ia memperoleh ciri imej dalam ruang Pandangan Mata Burung (BEV) dengan memotong ciri imej dari sudut pandangan berbeza dan menayangkannya ke dalam ruang 2D menggunakan titik rujukan 3D yang dipelajari. Berbeza daripada kaedah berbilang paparan berasaskan kedalaman, kaedah berbilang paparan berasaskan pertanyaan memperoleh ciri BEV yang jarang dengan menggunakan teknologi pertanyaan terbalik, yang secara asasnya memberi kesan kepada pembangunan berasaskan pertanyaan berikutnya. Walau bagaimanapun, disebabkan kemungkinan ketidaktepatan yang dikaitkan dengan titik rujukan 3D yang jelas, PETR menggunakan kaedah pengekodan kedudukan tersirat untuk membina ruang BEV, yang menjejaskan kerja berikutnya.
2.4 Analisis: Ketepatan, Kependaman, Kekukuhan
Pada masa ini, penyelesaian pengesanan objek 3D berdasarkan persepsi Pandangan Mata Burung (BEV) sedang berkembang pesat. Walaupun terdapat banyak artikel ulasan, tinjauan komprehensif bidang ini masih tidak mencukupi. Makmal AI Shanghai dan Institut Penyelidikan SenseTime menyediakan semakan mendalam tentang peta jalan teknologi untuk penyelesaian BEV. Walau bagaimanapun, tidak seperti ulasan sedia ada, kami mempertimbangkan aspek utama seperti persepsi keselamatan pemanduan autonomi. Selepas menganalisis peta jalan teknologi dan status pembangunan semasa penyelesaian berasaskan kamera, kami berhasrat untuk membincangkan berdasarkan prinsip asas `Ketepatan, Kependaman, Kekukuhan'. Kami akan menyepadukan perspektif kesedaran keselamatan untuk membimbing pelaksanaan praktikal kesedaran keselamatan dalam pemanduan autonomi.
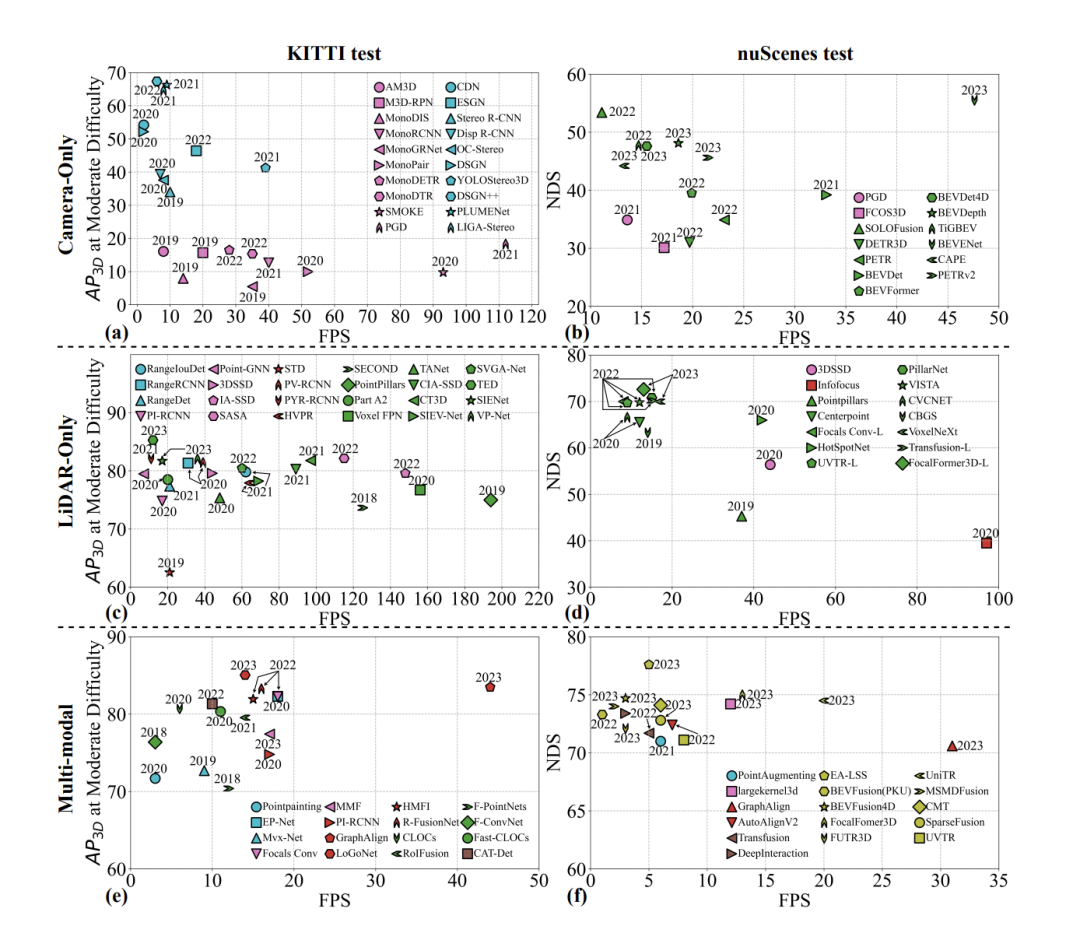
- Ketepatan: Terdapat banyak tumpuan pada ketepatan dalam kebanyakan artikel penyelidikan dan ulasan, dan ia sangat penting. Walaupun ketepatan boleh dicerminkan oleh AP (kepersisan purata), memandangkan AP sahaja mungkin tidak memberikan perspektif yang komprehensif kerana kaedah yang berbeza mungkin menunjukkan perbezaan yang ketara disebabkan oleh paradigma yang berbeza. Seperti yang ditunjukkan dalam rajah, kami memilih 10 kaedah perwakilan untuk perbandingan, dan keputusan menunjukkan bahawa terdapat perbezaan metrik yang ketara antara pengesanan objek 3D monokular dan pengesanan objek 3D stereoskopik. Keadaan semasa menunjukkan bahawa ketepatan pengesanan objek 3D monokular jauh lebih rendah daripada pengesanan objek 3D stereoskopik. Pengesanan objek 3D penglihatan stereo menggunakan imej yang ditangkap daripada dua perspektif berbeza bagi pemandangan yang sama untuk mendapatkan maklumat kedalaman. Lebih besar garis dasar antara kamera, lebih luas julat maklumat kedalaman yang ditangkap. Lama kelamaan, pengesanan objek 3D berbilang pandangan (persepsi pandangan mata burung) secara beransur-ansur menggantikan kaedah monokular, meningkatkan mAP dengan ketara. Peningkatan bilangan penderia mempunyai kesan yang ketara pada mAP.
- Latensi: Dalam bidang pemanduan autonomi, kependaman adalah penting. Ia merujuk kepada masa yang diperlukan untuk sistem bertindak balas kepada isyarat input, termasuk keseluruhan proses daripada pengumpulan data sensor kepada sistem membuat keputusan dan pelaksanaan tindakan. Dalam pemanduan autonomi, keperluan kependaman adalah sangat ketat, kerana sebarang bentuk kelewatan boleh membawa akibat yang serius. Kepentingan kependaman dalam pemanduan autonomi dicerminkan dalam aspek berikut: responsif masa nyata, keselamatan, pengalaman pengguna, interaktiviti dan tindak balas kecemasan. Dalam bidang pengesanan objek 3D, kependaman (bingkai sesaat, FPS) dan ketepatan adalah penunjuk utama untuk menilai prestasi algoritma. Seperti yang ditunjukkan dalam rajah, graf pengesanan objek 3D penglihatan monokular dan stereo menunjukkan ketepatan purata (AP) berbanding FPS untuk tahap kesukaran yang sama dalam set data KITTI. Untuk pelaksanaan pemanduan autonomi, algoritma pengesanan objek 3D mesti menyeimbangkan antara kependaman dan ketepatan. Walaupun pengesanan monokular adalah pantas, ia tidak mempunyai ketepatan sebaliknya, kaedah stereo dan berbilang paparan adalah tepat tetapi lebih perlahan. Penyelidikan masa depan bukan sahaja harus mengekalkan ketepatan yang tinggi, tetapi juga memberi lebih perhatian kepada meningkatkan FPS dan mengurangkan kependaman untuk memenuhi keperluan dwi responsif masa nyata dan keselamatan dalam pemanduan autonomi.
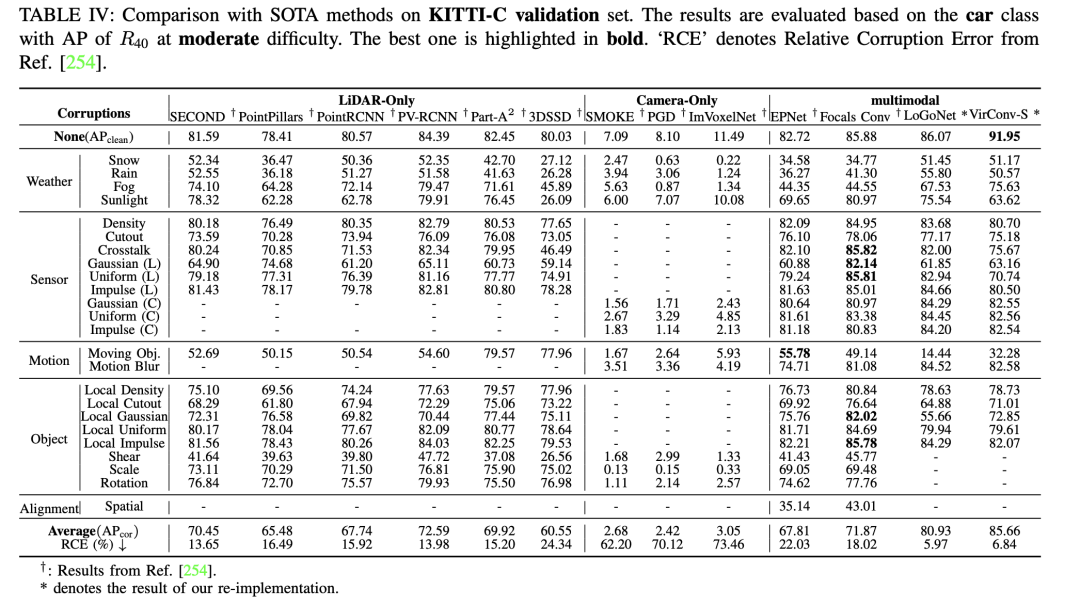
- Keteguhan: Kekukuhan ialah faktor utama dalam persepsi keselamatan pemanduan autonomi dan mewakili topik penting yang sebelum ini diabaikan dalam ulasan komprehensif. Aspek ini selalunya tidak ditangani dalam set data bersih dan penanda aras semasa yang direka bentuk dengan baik seperti KITTI, nuScenes dan Waymo. Pada masa ini, kerja penyelidikan seperti RoboBEV dan Robo3D menggabungkan pertimbangan keteguhan dalam pengesanan objek 3D, seperti kehilangan penderia dan faktor lain. Mereka menggunakan metodologi yang melibatkan memperkenalkan gangguan ke dalam set data yang berkaitan dengan pengesanan objek 3D untuk menilai keteguhan. Ini termasuk pengenalan pelbagai jenis hingar, seperti perubahan dalam keadaan cuaca, kegagalan sensor, gangguan gerakan dan gangguan berkaitan objek, bertujuan untuk mendedahkan kesan berbeza sumber hingar yang berbeza pada model. Lazimnya, kebanyakan kertas kerja yang mengkaji kekukuhan dinilai dengan memperkenalkan bunyi pada set pengesahan set data bersih (seperti KITTI, nuScenes dan Waymo). Selain itu, kami menyerlahkan penemuan dalam Ruj., yang menyerlahkan KITTI-C dan nuScenes-C sebagai contoh kaedah pengesanan objek 3D kamera sahaja. Jadual menyediakan perbandingan keseluruhan yang menunjukkan bahawa secara keseluruhan pendekatan kamera sahaja adalah kurang teguh berbanding pendekatan gabungan lidar sahaja dan pelbagai model. Mereka sangat terdedah kepada pelbagai jenis bunyi. Dalam KITTI-C, tiga karya perwakilan—SMOKE, PGD dan ImVoxelNet—menunjukkan prestasi keseluruhan yang lebih rendah secara konsisten dan mengurangkan kekukuhan kepada hingar. Dalam nuScenes-C, kaedah yang patut diberi perhatian seperti DETR3D dan BEVFormer menunjukkan keteguhan yang lebih besar berbanding dengan FCOS3D dan PGD, menunjukkan bahawa keteguhan keseluruhan meningkat apabila bilangan penderia meningkat. Kesimpulannya, pendekatan kamera sahaja pada masa hadapan perlu mempertimbangkan bukan sahaja faktor kos dan metrik ketepatan (mAP, NDS, dll.), tetapi juga faktor yang berkaitan dengan persepsi keselamatan dan keteguhan. Analisis kami bertujuan untuk memberikan pandangan berharga tentang keselamatan sistem pemanduan autonomi masa hadapan.
3. Pengesanan objek 3D berasaskan Lidar
Kaedah pengesanan objek 3D berasaskan voxel mencadangkan untuk membahagikan dan mengedarkan awan titik jarang ke voxel biasa untuk membentuk perwakilan data padat ini. Berbanding dengan kaedah berasaskan paparan, kaedah berasaskan voxel menggunakan lilitan spatial untuk melihat maklumat spatial 3D dengan berkesan dan mencapai ketepatan pengesanan yang lebih tinggi, yang penting untuk persepsi keselamatan dalam pemanduan autonomi. Walau bagaimanapun, kaedah ini masih menghadapi cabaran berikut:
- Kerumitan Pengiraan Tinggi: Berbanding dengan kaedah berasaskan kamera, kaedah berasaskan voxel memerlukan memori dan sumber pengiraan yang ketara disebabkan oleh bilangan voxel yang banyak digunakan untuk mewakili ruang 3D.
- Kehilangan maklumat spatial: Disebabkan ciri pendiskretan voxel, butiran dan maklumat bentuk mungkin hilang atau kabur semasa proses voxelisasi, manakala resolusi voxel yang terhad menyukarkan untuk mengesan objek kecil dengan tepat.
- Skala dan ketumpatan tidak konsisten: Kaedah berasaskan Voxel biasanya memerlukan pengesanan pada grid voxel dengan skala dan ketumpatan yang berbeza, tetapi memandangkan skala dan ketumpatan sasaran berbeza-beza dalam adegan yang berbeza, adalah penting untuk memilih skala dan Ketumpatan yang sesuai untuk menampung matlamat yang berbeza menjadi satu cabaran.
Untuk mengatasi cabaran ini, adalah perlu untuk menyelesaikan had perwakilan data, meningkatkan keupayaan ciri rangkaian dan ketepatan kedudukan sasaran, dan mengukuhkan pemahaman algoritma tentang adegan yang kompleks. Walaupun strategi pengoptimuman berbeza-beza, ia secara amnya bertujuan untuk mengoptimumkan perwakilan data dan struktur model.
3.1 Pengesanan objek 3D berasaskan Voxel
Terima kasih kepada kemakmuran PC dalam pembelajaran mendalam, pengesanan objek 3D berasaskan titik mewarisi banyak rangka kerjanya dan bercadang untuk bermula terus dari titik asal tanpa prapemprosesan Mengesan objek 3D. Berbanding dengan kaedah berasaskan voxel, awan titik asal mengekalkan jumlah maksimum maklumat asal, yang bermanfaat kepada pemerolehan ciri yang terperinci dan menghasilkan ketepatan yang tinggi. Pada masa yang sama, satu siri kerja di PointNet secara semula jadi menyediakan asas yang kukuh untuk kaedah berasaskan titik. Pengesan objek 3D berasaskan titik mempunyai dua komponen asas: pensampelan awan titik dan pembelajaran ciri Setakat ini, prestasi kaedah berasaskan titik masih dipengaruhi oleh dua faktor: bilangan titik konteks dan jejari konteks yang diterima pakai dalam pembelajaran ciri. . cth. Menambahkan bilangan titik konteks boleh memperoleh maklumat 3D yang lebih terperinci, tetapi akan meningkatkan masa inferens model dengan ketara. Begitu juga, mengurangkan jejari konteks boleh mempunyai kesan yang sama. Oleh itu, memilih nilai yang sesuai untuk kedua-dua faktor ini boleh membolehkan model mencapai keseimbangan antara ketepatan dan kelajuan. Di samping itu, oleh kerana setiap titik dalam awan titik perlu dikira, proses pensampelan awan titik adalah faktor utama yang mengehadkan operasi masa nyata kaedah berasaskan titik. Khususnya, untuk menyelesaikan masalah di atas, kebanyakan kaedah sedia ada dioptimumkan di sekitar dua komponen asas pengesan objek 3D berasaskan titik: 1) Pensampelan Titik 2) pembelajaran ciri
3.2 Pengesanan objek 3D berasaskan titik
Kaedah pengesanan objek 3D berasaskan titik mewarisi banyak rangka kerja pembelajaran mendalam dan mencadangkan untuk mengesan objek 3D terus daripada awan titik mentah tanpa prapemprosesan. Berbanding dengan kaedah berasaskan voxel, awan titik asal mengekalkan maklumat asal ke tahap maksimum, yang kondusif untuk pemerolehan ciri berbutir halus, dengan itu mencapai ketepatan yang tinggi. Pada masa yang sama, siri kerja PointNet menyediakan asas yang kukuh untuk kaedah berasaskan titik. Walau bagaimanapun, setakat ini, prestasi kaedah berasaskan titik masih dipengaruhi oleh dua faktor: bilangan titik konteks dan jejari konteks yang digunakan dalam pembelajaran ciri. Contohnya, menambah bilangan titik konteks boleh memperoleh maklumat 3D yang lebih terperinci, tetapi akan meningkatkan masa inferens model dengan ketara. Begitu juga, mengurangkan jejari konteks mencapai kesan yang sama. Oleh itu, memilih nilai yang sesuai untuk kedua-dua faktor ini membolehkan model mencapai keseimbangan antara ketepatan dan kelajuan. Selain itu, proses pensampelan awan titik merupakan faktor utama yang mengehadkan operasi masa nyata kaedah berasaskan titik kerana keperluan untuk melakukan pengiraan bagi setiap titik dalam awan titik. Untuk menyelesaikan masalah ini, kaedah sedia ada terutamanya mengoptimumkan sekitar dua komponen asas pengesan objek 3D berasaskan titik: 1) pensampelan awan titik 2) pembelajaran ciri.
Farth Point Sampling (FPS) berasal daripada PointNet++ dan merupakan kaedah pensampelan awan titik yang digunakan secara meluas dalam kaedah berasaskan titik. Matlamatnya adalah untuk memilih set titik yang mewakili daripada awan titik asal untuk memaksimumkan jarak antara mereka untuk menampung taburan ruang keseluruhan awan titik. PointRCNN ialah pengesan dua peringkat terobosan dalam kaedah berasaskan titik, menggunakan PointNet++ sebagai rangkaian tulang belakang. Pada peringkat pertama, ia menjana cadangan 3D dari awan titik dengan cara bawah ke atas. Pada peringkat kedua, cadangan diperhalusi dengan menggabungkan ciri semantik dan ciri spatial tempatan. Walau bagaimanapun, kaedah berasaskan FPS sedia ada masih menghadapi beberapa masalah: 1) Titik yang tidak berkaitan dengan pengesanan turut mengambil bahagian dalam proses pensampelan, membawa beban pengiraan tambahan 2) Mata diagihkan secara tidak sekata di bahagian objek yang berbeza, mengakibatkan strategi pensampelan suboptimum. Untuk menangani isu ini, kerja seterusnya menggunakan paradigma reka bentuk seperti FPS dan membuat penambahbaikan, seperti penapisan titik latar belakang berpandukan segmentasi, pensampelan rawak, pensampelan ruang ciri, pensampelan berasaskan voxel dan pensampelan berasaskan kumpulan sinar.
Peringkat pembelajaran ciri kaedah pengesanan objek 3D berasaskan titik bertujuan untuk mengekstrak perwakilan ciri diskriminatif daripada data awan titik yang jarang. Rangkaian saraf yang digunakan dalam peringkat pembelajaran ciri harus mempunyai ciri-ciri berikut: 1) Invarian, rangkaian tulang belakang awan titik harus tidak sensitif kepada susunan awan titik input 2) Ia mempunyai keupayaan persepsi tempatan dan boleh mengesan dan memodelkan kawasan setempat; , dan mengekstrak ciri setempat; 3) Keupayaan untuk menyepadukan maklumat konteks dan mengekstrak ciri daripada maklumat konteks global dan tempatan. Berdasarkan ciri-ciri di atas, sejumlah besar pengesan direka untuk memproses awan titik mentah. Kebanyakan kaedah boleh dibahagikan mengikut operator teras yang digunakan: 1) Kaedah berasaskan PointNet 2) Kaedah berasaskan rangkaian saraf graf 3) Kaedah berasaskan Transformer;
Kaedah berasaskan PointNet
Kaedah berasaskan PointNet bergantung terutamanya pada pengabstrakan set untuk mengurangkan sampel titik asal, mengagregat maklumat tempatan dan menyepadukan maklumat kontekstual sambil mengekalkan invarian simetri titik asal. Point-RCNN ialah kerja dua peringkat pertama antara kaedah berasaskan titik dan mencapai prestasi cemerlang, tetapi masih menghadapi masalah kos pengiraan yang tinggi. Kerja-kerja seterusnya menyelesaikan masalah ini dengan memperkenalkan tugas pembahagian semantik tambahan dalam proses pengesanan untuk menapis titik latar belakang yang menyumbang secara minimum kepada pengesanan.
Kaedah berdasarkan rangkaian saraf graf
Rangkaian saraf graf (GNN) mempunyai struktur penyesuaian, kejiranan dinamik, keupayaan untuk membina hubungan konteks tempatan dan global serta keteguhan kepada pensampelan yang tidak teratur. Point-GNN ialah kerja perintis yang mereka bentuk rangkaian saraf graf satu peringkat untuk meramalkan kategori dan bentuk objek melalui mekanisme pendaftaran automatik, operasi penggabungan dan pemarkahan, menunjukkan penggunaan rangkaian saraf graf sebagai kaedah baharu untuk pengesanan objek 3D. potensi.
Kaedah berasaskan Transformer
Dalam beberapa tahun kebelakangan ini, Transformers (Transformers) telah diterokai dalam analisis awan titik dan telah melaksanakan banyak tugas dengan baik. Sebagai contoh, Pointformer memperkenalkan modul perhatian tempatan dan global untuk memproses awan titik 3D, modul Transformer tempatan digunakan untuk memodelkan interaksi antara titik di wilayah tempatan, dan Transformer global bertujuan untuk mempelajari perwakilan sedar konteks peringkat pemandangan. Bebas kumpulan secara langsung menggunakan semua titik dalam awan titik untuk mengira ciri setiap calon objek, di mana sumbangan setiap mata ditentukan oleh modul perhatian yang dipelajari secara automatik. Kaedah ini menunjukkan potensi kaedah berasaskan Transformer dalam memproses awan titik mentah yang tidak berstruktur dan tidak tertib.
3.3 Pengesanan objek 3D berasaskan Point-Voxel
Kaedah pengesanan objek 3D berasaskan awan titik memberikan resolusi tinggi dan mengekalkan struktur spatial data asal, tetapi mereka menghadapi kerumitan pengiraan yang tinggi dan kecekapan rendah apabila memproses data yang jarang . Sebaliknya, kaedah berasaskan voxel menyediakan perwakilan data berstruktur, meningkatkan kecekapan pengiraan, dan memudahkan penggunaan teknologi rangkaian neural konvolusi tradisional. Walau bagaimanapun, mereka sering kehilangan butiran spatial yang halus disebabkan oleh proses pendiskretan. Untuk menyelesaikan masalah ini, kaedah berasaskan point-voxel (PV) telah dibangunkan. Kaedah titik-voxel bertujuan untuk mengeksploitasi keupayaan menangkap maklumat terperinci kaedah berasaskan titik dan kecekapan pengiraan kaedah berasaskan voxel. Dengan menyepadukan kaedah ini, kaedah berasaskan titik-voxel boleh memproses data awan titik dengan lebih terperinci, menangkap struktur global dan butiran mikro-geometri. Ini penting untuk persepsi keselamatan dalam pemanduan autonomi, kerana ketepatan membuat keputusan sistem pemanduan autonomi bergantung pada hasil pengesanan ketepatan tinggi.
Matlamat utama kaedah titik-voxel adalah untuk mencapai interaksi ciri antara voxel dan titik melalui penukaran point-to-voxel atau voxel-to-point. Banyak karya telah meneroka idea menggunakan gabungan ciri titik-voxel dalam rangkaian tulang belakang. Kaedah ini boleh dibahagikan kepada dua kategori: 1) gabungan awal;
a) Penyatuan awal: Beberapa kaedah telah meneroka penggunaan operator lilitan baharu untuk menggabungkan ciri voxel dan titik, dan PVCNN mungkin merupakan kerja pertama ke arah ini. Dalam pendekatan ini, cawangan berasaskan voxel mula-mula menukar mata kepada grid voxel resolusi rendah dan mengagregatkan ciri voxel bersebelahan melalui konvolusi. Kemudian, melalui proses yang dipanggil devoxelization, ciri peringkat voxel ditukar kembali kepada ciri peringkat titik dan digabungkan dengan ciri yang diperolehi oleh cawangan berasaskan titik. Cawangan berasaskan titik mengekstrak ciri untuk setiap titik individu. Oleh kerana ia tidak mengagregatkan maklumat jiran, kaedah ini boleh berjalan pada kelajuan yang lebih tinggi. Kemudian, SPVCNN telah diperluaskan kepada bidang pengesanan objek berdasarkan PVCNN. Kaedah lain cuba menambah baik dari perspektif yang berbeza, seperti tugas tambahan atau gabungan ciri berbilang skala.
b) Post-fusion: Siri kaedah ini terutamanya menggunakan rangka kerja pengesanan dua peringkat. Pertama, cadangan objek awal dijana menggunakan pendekatan berasaskan voxel. Kemudian, ciri peringkat titik digunakan untuk membahagikan bingkai pengesanan dengan tepat. PV-RCNN yang dicadangkan oleh Shi et al adalah peristiwa penting dalam kaedah berasaskan titik-voxel. Ia menggunakan SECOND sebagai pengesan peringkat pertama dan mencadangkan peringkat penghalusan peringkat kedua dengan pengumpulan grid RoI untuk gabungan ciri titik utama. Kerja-kerja seterusnya terutamanya mengikut paradigma di atas dan memberi tumpuan kepada kemajuan pengesanan peringkat kedua. Perkembangan ketara termasuk mekanisme perhatian, penggabungan sedar skala dan modul penghalusan sedar kepadatan titik.
Kaedah berasaskan titik-voxel mempunyai kedua-dua kecekapan pengiraan kaedah berasaskan voxel dan keupayaan kaedah berasaskan titik untuk menangkap maklumat yang terperinci. Walau bagaimanapun, membina hubungan titik-ke-voxel atau voxel-ke-titik, serta gabungan ciri voxel dan titik, akan membawa overhed pengiraan tambahan. Oleh itu, kaedah berasaskan titik-voxel boleh mencapai ketepatan pengesanan yang lebih baik berbanding kaedah berasaskan voxel, tetapi dengan kos peningkatan masa inferens.
4. Pengesanan objek 3D berbilang mod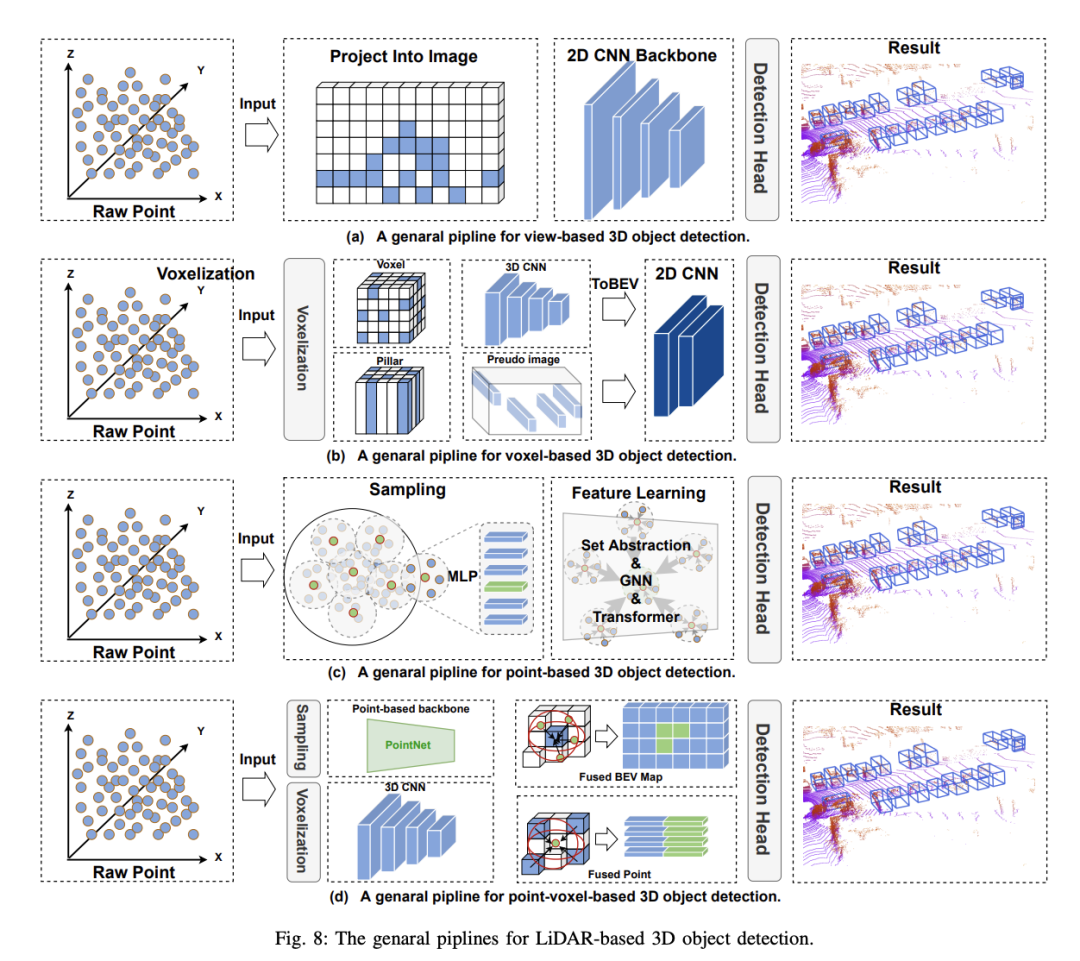
Kaedah pengesanan objek 3D berasaskan unjuran menggunakan peringkat matriks titik unjuran awan dan ciri imej. Perkara utama di sini ialah memfokuskan pada unjuran semasa gabungan ciri, dan bukannya proses unjuran lain dalam peringkat gabungan, seperti penambahan data, dsb. Mengikut pelbagai jenis unjuran yang digunakan dalam peringkat gabungan, kaedah pengesanan objek 3D berasaskan unjuran boleh dibahagikan lagi kepada kategori berikut:
- Pengesanan objek 3D berdasarkan unjuran titik
- : Kaedah jenis ini berfungsi dengan menayang imej ciri pada awan Titik asal digunakan untuk meningkatkan keupayaan perwakilan data awan titik asal. Langkah pertama dalam kaedah ini ialah menggunakan matriks penentukuran untuk mewujudkan korelasi yang kuat antara titik lidar dan piksel imej. Seterusnya, ciri awan titik dipertingkatkan dengan menambahkan data tambahan. Peningkatan ini terdapat dalam dua bentuk: satu dengan menggabungkan skor segmentasi (seperti PointPainting), dan satu lagi dengan menggunakan ciri CNN daripada piksel yang berkaitan (seperti MVP). PointPainting meningkatkan mata lidar dengan menambahkan skor segmentasi, tetapi mempunyai had dalam menangkap butiran warna dan tekstur dalam imej dengan berkesan. Untuk menyelesaikan masalah ini, kaedah yang lebih canggih seperti FusionPainting telah dibangunkan. Pengesanan objek 3D berdasarkan unjuran ciri
- : Berbeza daripada kaedah berdasarkan unjuran titik, kaedah jenis ini tertumpu terutamanya pada ciri awan titik gabungan dengan ciri imej dalam peringkat pengekstrakan ciri awan titik. Dalam proses ini, awan titik dan modaliti imej digabungkan dengan berkesan dengan menggunakan matriks penentukuran untuk mengubah sistem koordinat 3D voxel kepada sistem koordinat piksel imej. Contohnya, ContFuse menggabungkan peta ciri konvolusi berbilang skala melalui konvolusi berterusan. Pengesanan objek 3D berasaskan unjuran automatik
- : Banyak kajian melakukan gabungan melalui unjuran terus, tetapi tidak menyelesaikan masalah ralat unjuran. Sesetengah kerja (seperti AutoAlignV2) mengurangkan ralat ini dengan mempelajari offset dan unjuran kejiranan, dsb. Contohnya, HMFI, GraphAlign dan GraphAlign++ menggunakan pengetahuan terdahulu tentang matriks penentukuran unjuran untuk unjuran imej dan pemodelan graf tempatan. Pengesanan objek 3D berasaskan unjuran
- : Kaedah jenis ini menggunakan matriks unjuran untuk menjajarkan ciri dalam kawasan yang diminati (RoI) atau hasil tertentu. Sebagai contoh, Graph-RCNN menayangkan nod graf ke kedudukan dalam imej kamera dan mengumpul vektor ciri untuk piksel tersebut dalam imej kamera melalui interpolasi dwilinear. F-PointNet menentukan kategori dan kedudukan objek melalui pengesanan imej 2D, dan memperoleh awan titik dalam ruang 3D yang sepadan melalui parameter sensor yang ditentukur dan matriks transformasi dalam ruang 3D. Kaedah ini menunjukkan cara menggunakan teknologi unjuran untuk mencapai gabungan ciri dalam pengesanan objek 3D berbilang modal, tetapi kaedah ini masih mempunyai had tertentu dalam mengendalikan interaksi antara modaliti dan ketepatan yang berbeza. . Mereka memintas pengehadan unjuran kamera-ke-lidar, yang sering mengurangkan ketumpatan semantik ciri kamera dan menjejaskan keberkesanan teknik seperti Focals Conv dan PointPainting. Kaedah bukan unjuran biasanya menggunakan mekanisme perhatian silang atau membina ruang bersatu untuk menyelesaikan masalah salah jajaran yang wujud dalam unjuran ciri langsung. Kaedah ini terbahagi terutamanya kepada dua kategori: (1) kaedah berasaskan pembelajaran pertanyaan dan (2) kaedah berasaskan ciri bersatu. Kaedah berasaskan pembelajaran pertanyaan benar-benar mengelakkan keperluan untuk penjajaran semasa proses gabungan. Sebaliknya, kaedah berasaskan ciri bersatu, walaupun membina ruang ciri bersatu, tidak sepenuhnya mengelakkan unjuran ia biasanya berlaku dalam konteks modaliti tunggal. Sebagai contoh, BEVFusion menggunakan LSS untuk unjuran kamera-ke-BEV. Proses ini berlaku sebelum gabungan dan menunjukkan keteguhan yang besar dalam senario di mana ciri tidak sejajar.
- Pengesanan objek 3D berdasarkan pembelajaran pertanyaan: Kaedah pengesanan objek tiga dimensi berdasarkan pembelajaran pertanyaan, seperti Transfusi, DeepFusion, DeepInteraction, autoalign, CAT-Det, MixedFusion, dll., elakkan keperluan untuk unjuran dalam ciri proses gabungan. Sebaliknya, mereka mencapai penjajaran ciri sebelum melakukan gabungan ciri melalui mekanisme perhatian silang. Ciri awan titik biasanya digunakan sebagai pertanyaan, dan ciri imej digunakan sebagai kunci dan nilai ciri berbilang modal yang sangat mantap diperoleh melalui pertanyaan ciri global. Selain itu, DeepInteraction memperkenalkan interaksi berbilang modal, di mana awan titik dan ciri imej digunakan sebagai pertanyaan berbeza untuk mencapai interaksi ciri selanjutnya. Penyepaduan menyeluruh ciri imej membawa kepada pemerolehan ciri berbilang modal yang lebih mantap berbanding dengan hanya menggunakan ciri awan titik sebagai pertanyaan. Secara umum, kaedah pengesanan objek tiga dimensi berdasarkan pembelajaran pertanyaan menggunakan struktur berasaskan Transformer untuk melaksanakan pertanyaan ciri untuk mencapai penjajaran ciri. Akhirnya, ciri multimodal telah disepadukan ke dalam proses berasaskan lidar seperti CenterPoint.
- Pengesanan objek tiga dimensi berdasarkan ciri bersatu: Kaedah pengesanan objek tiga dimensi berdasarkan ciri bersatu, seperti EA-BEV, BEVFusion, cai2023bevfusion4d, FocalFormer3D, FUTR3D, UniTR, Uni3D, virginiv, MStMDFusion , UVTR, sparsefusion, dsb., biasanya penyatuan pra-gabungan modaliti heterogen dicapai melalui unjuran sebelum gabungan ciri. Dalam siri gabungan BEV, LSS digunakan untuk anggaran kedalaman, ciri pandangan hadapan ditukar kepada ciri BEV, dan kemudian imej BEV dan ciri awan titik BEV digabungkan. Sebaliknya, CMT dan UniTR menggunakan Transformer untuk tokenisasi awan titik dan imej, dan membina ruang bersatu tersirat melalui pengekodan Transformer. CMT menggunakan unjuran dalam proses pengekodan kedudukan tetapi mengelak sepenuhnya pergantungan pada hubungan unjuran pada tahap pembelajaran ciri. FocalFormer3D, FUTR3D dan UVTR menggunakan pertanyaan Transformer untuk melaksanakan penyelesaian yang serupa dengan DETR3D, dan membina ruang ciri BEV jarang bersatu melalui pertanyaan, sekali gus mengurangkan ketidakstabilan yang disebabkan oleh unjuran langsung.
VirConv, MSMDFusion dan SFD membina ruang bersatu melalui awan titik pseudo, dan unjuran berlaku sebelum pembelajaran ciri. Masalah yang diperkenalkan oleh unjuran langsung diselesaikan melalui pembelajaran ciri seterusnya. Ringkasnya, kaedah pengesanan objek 3D berasaskan ciri bersatu pada masa ini mewakili penyelesaian yang sangat tepat dan mantap. Walaupun ia mengandungi matriks unjuran, unjuran ini tidak berlaku antara gabungan pelbagai mod dan oleh itu dianggap sebagai kaedah pengesanan objek 3D bukan projektif. Berbeza daripada kaedah pengesanan objek 3D unjuran automatik, mereka tidak menyelesaikan masalah ralat unjuran secara langsung, tetapi memilih untuk membina ruang bersatu dan mempertimbangkan pelbagai dimensi pengesanan objek 3D multimodal untuk mendapatkan ciri multimodal yang sangat teguh.
5. Kesimpulan
Pengesanan objek 3D memainkan peranan penting dalam persepsi pemanduan autonomi. Dalam beberapa tahun kebelakangan ini, bidang ini telah berkembang pesat dan menghasilkan sejumlah besar kertas penyelidikan. Berdasarkan bentuk data yang pelbagai yang dijana oleh penderia, kaedah ini terbahagi terutamanya kepada tiga jenis: berasaskan imej, berasaskan awan titik dan berbilang modal. Metrik penilaian utama kaedah ini ialah ketepatan tinggi dan kependaman rendah. Banyak ulasan merumuskan pendekatan ini, memfokuskan terutamanya pada prinsip teras `ketepatan tinggi dan kependaman rendah', menerangkan trajektori teknikalnya.
Walau bagaimanapun, dalam proses teknologi pemanduan autonomi yang beralih daripada penemuan kepada aplikasi praktikal, ulasan sedia ada tidak mengambil persepsi keselamatan sebagai fokus teras dan gagal merangkumi laluan teknikal semasa yang berkaitan dengan persepsi keselamatan. Sebagai contoh, kaedah gabungan multimodal terkini sering diuji untuk kekukuhan semasa fasa percubaan, satu aspek yang belum dipertimbangkan sepenuhnya dalam semakan semasa.
Oleh itu, periksa semula algoritma pengesanan objek 3D, memfokuskan pada `ketepatan, kependaman dan kekukuhan' sebagai aspek utama. Kami mengklasifikasikan semula ulasan sebelumnya dengan penekanan khusus pada pengelasan semula dari perspektif persepsi keselamatan. Kerja ini diharapkan dapat memberikan pandangan baharu tentang penyelidikan masa depan tentang pengesanan objek 3D, melangkaui sekadar meneroka batasan ketepatan yang tinggi.

Atas ialah kandungan terperinci Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undress AI Tool
Gambar buka pakaian secara percuma

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)



 Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Ditulis di atas & pemahaman peribadi pengarang Gaussiansplatting tiga dimensi (3DGS) ialah teknologi transformatif yang telah muncul dalam bidang medan sinaran eksplisit dan grafik komputer dalam beberapa tahun kebelakangan ini. Kaedah inovatif ini dicirikan oleh penggunaan berjuta-juta Gaussians 3D, yang sangat berbeza daripada kaedah medan sinaran saraf (NeRF), yang terutamanya menggunakan model berasaskan koordinat tersirat untuk memetakan koordinat spatial kepada nilai piksel. Dengan perwakilan adegan yang eksplisit dan algoritma pemaparan yang boleh dibezakan, 3DGS bukan sahaja menjamin keupayaan pemaparan masa nyata, tetapi juga memperkenalkan tahap kawalan dan pengeditan adegan yang tidak pernah berlaku sebelum ini. Ini meletakkan 3DGS sebagai penukar permainan yang berpotensi untuk pembinaan semula dan perwakilan 3D generasi akan datang. Untuk tujuan ini, kami menyediakan gambaran keseluruhan sistematik tentang perkembangan dan kebimbangan terkini dalam bidang 3DGS buat kali pertama.
 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 Sparse4D v3 ada di sini! Memajukan pengesanan dan penjejakan 3D hujung ke hujung
Nov 24, 2023 am 11:21 AM
Sparse4D v3 ada di sini! Memajukan pengesanan dan penjejakan 3D hujung ke hujung
Nov 24, 2023 am 11:21 AM
Tajuk baharu: Sparse4Dv3: Memajukan Pengesanan 3D Akhir-ke-Hujung Pautan Kertas Teknologi Penjejakan: https://arxiv.org/pdf/2311.11722.pdf Kandungan yang perlu ditulis semula ialah: Pautan kod: https://github. com/linxuewu/ Kandungan yang ditulis semula oleh Sparse4D: Gabungan penulis ialah Syarikat Horizon Idea tesis: Dalam sistem persepsi pemanduan autonomi, pengesanan dan pengesanan 3D adalah dua tugas asas. Artikel ini melihat dengan lebih mendalam kawasan ini berdasarkan rangka kerja Sparse4D. Artikel ini memperkenalkan dua tugas latihan tambahan (denoising instance temporal-TemporalInstanceDenoising dan anggaran kualiti-Q
 SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
Tajuk asal: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper pautan: https://arxiv.org/pdf/2402.02519.pdf Pautan kod: https://github.com/HKUST-Aerial-Robotics/SIMPL Unit pengarang: Universiti Sains Hong Kong dan Teknologi Idea Kertas DJI: Kertas kerja ini mencadangkan garis dasar ramalan pergerakan (SIMPL) yang mudah dan cekap untuk kenderaan autonomi. Berbanding dengan agen-sen tradisional
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Ramalan trajektori memainkan peranan penting dalam pemanduan autonomi Ramalan trajektori pemanduan autonomi merujuk kepada meramalkan trajektori pemanduan masa hadapan kenderaan dengan menganalisis pelbagai data semasa proses pemanduan kenderaan. Sebagai modul teras pemanduan autonomi, kualiti ramalan trajektori adalah penting untuk kawalan perancangan hiliran. Tugas ramalan trajektori mempunyai timbunan teknologi yang kaya dan memerlukan kebiasaan dengan persepsi dinamik/statik pemanduan autonomi, peta ketepatan tinggi, garisan lorong, kemahiran seni bina rangkaian saraf (CNN&GNN&Transformer), dll. Sangat sukar untuk bermula! Ramai peminat berharap untuk memulakan ramalan trajektori secepat mungkin dan mengelakkan perangkap Hari ini saya akan mengambil kira beberapa masalah biasa dan kaedah pembelajaran pengenalan untuk ramalan trajektori! Pengetahuan berkaitan pengenalan 1. Adakah kertas pratonton teratur? A: Tengok survey dulu, hlm
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
