


Pertama, mari kita perkenalkan latar belakang perniagaan, latar belakang data dan strategi algoritma asas pengesyoran aliran maklumat komprehensif Baidu.

Aliran maklumat komprehensif Baidu termasuk halaman senarai kotak carian dalam APP Baidu dan bentuk halaman yang mengasyikkan, meliputi pelbagai jenis produk. Seperti yang anda boleh lihat daripada gambar di atas, format kandungan yang disyorkan termasuk pengesyoran mendalam yang serupa dengan Douyin, serta pengesyoran satu lajur dan dua lajur, serupa dengan reka letak Xiaohongshu Notes. Terdapat juga banyak cara untuk pengguna berinteraksi dengan kandungan Mereka boleh mengulas, menyukai dan mengumpul kandungan pada halaman pendaratan Mereka juga boleh memasuki halaman pengarang untuk melihat maklumat yang berkaitan dan berinteraksi. Reka bentuk keseluruhan aliran maklumat komprehensif adalah sangat kaya dan pelbagai, dan boleh memenuhi keperluan dan kaedah interaksi pengguna yang berbeza.
Permintaan tinggi.
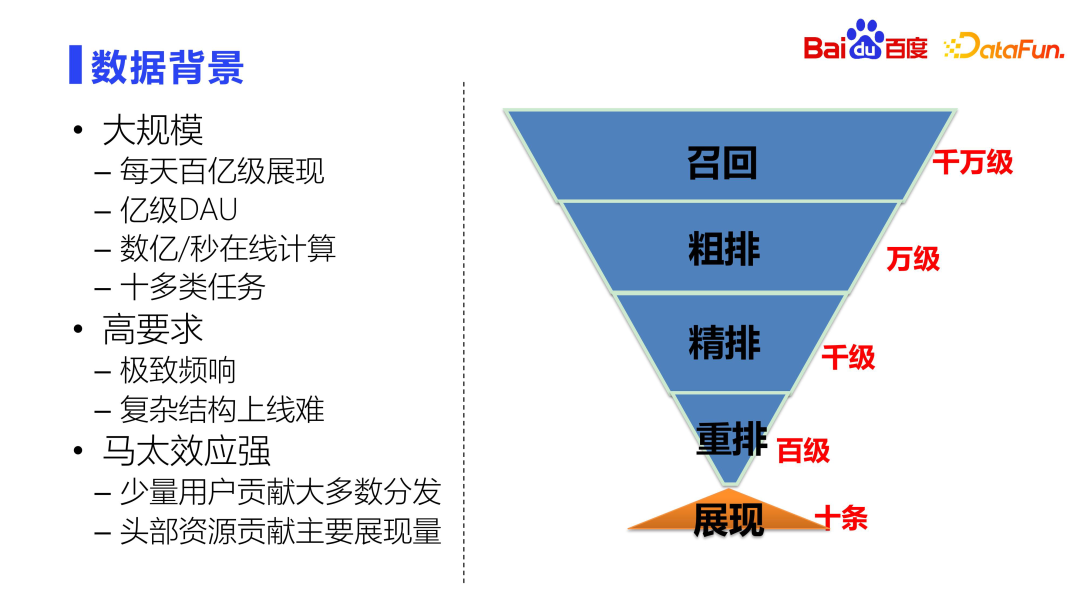
Keperluan masa tindak balas keseluruhan sistem adalah sangat tinggi dalam milisaat Jika masa yang telah ditetapkan melebihi, kegagalan akan dikembalikan. Ini juga menimbulkan masalah lain, iaitu kesukaran membawa struktur kompleks dalam talian.
Seterusnya, kami akan memperkenalkannya lagi dari tiga perspektif ciri, algoritma dan seni bina. .
Rajah berikut menunjukkan rajah matriks interaksi hubungan spatio-temporal pengguna-sumber-senario.
Dalam dimensi sumber, terdapat juga ciri jenis ID untuk merekodkan status sumber itu sendiri, yang dikuasai oleh ingatan. Terdapat juga ciri potret teks biasa untuk mencapai keupayaan generalisasi asas. Sebagai tambahan kepada ciri berbutir kasar, terdapat juga ciri sumber yang lebih terperinci, seperti membenamkan ciri potret, yang dihasilkan berdasarkan model pra-latihan seperti multi-modaliti dan pemodelan yang lebih terperinci tentang hubungan antara sumber dalam pembenaman diskret. angkasa lepas. Terdapat juga ciri potret statistik yang menggambarkan prestasi posterior sumber dalam pelbagai keadaan. Serta ciri yang serupa, pengguna boleh mencirikan sumber secara terbalik untuk meningkatkan ketepatan.
Dari segi dimensi pemandangan, terdapat ciri pemandangan yang berbeza seperti lajur tunggal, imersif dan lajur berganda.
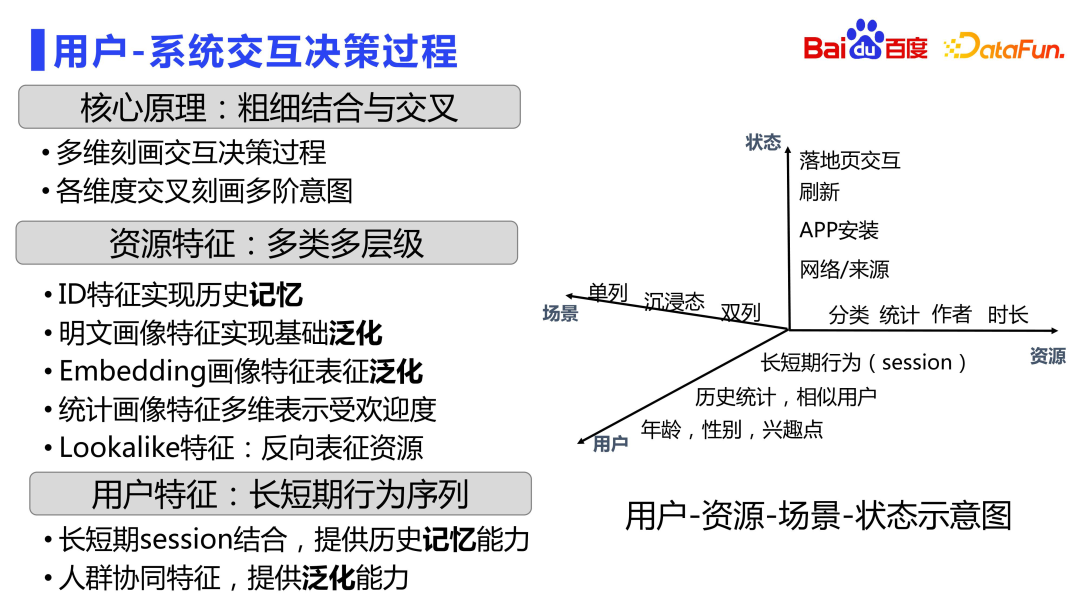
Menggambarkan proses membuat keputusan interaksi sistem pengguna melalui empat dimensi pengguna, sumber, status dan senario. Dalam banyak kes, gabungan antara pelbagai dimensi juga dilakukan.
2. Prinsip reka bentuk ciri diskret
Seterusnya, kami akan memperkenalkan prinsip reka bentuk ciri diskret.
Ciri berkualiti tinggi biasanya mempunyai tiga ciri: diskriminasi tinggi, liputan tinggi dan keteguhan yang kuat.
Liputan tinggi: Jika liputan ciri tambahan dalam keseluruhan sampel hanya beberapa persepuluh perseribu atau seratus perseribu, maka walaupun ciri-ciri itu sangat boleh dibezakan, terdapat kebarangkalian tinggi bahawa mereka tidak akan mempunyai kesan.
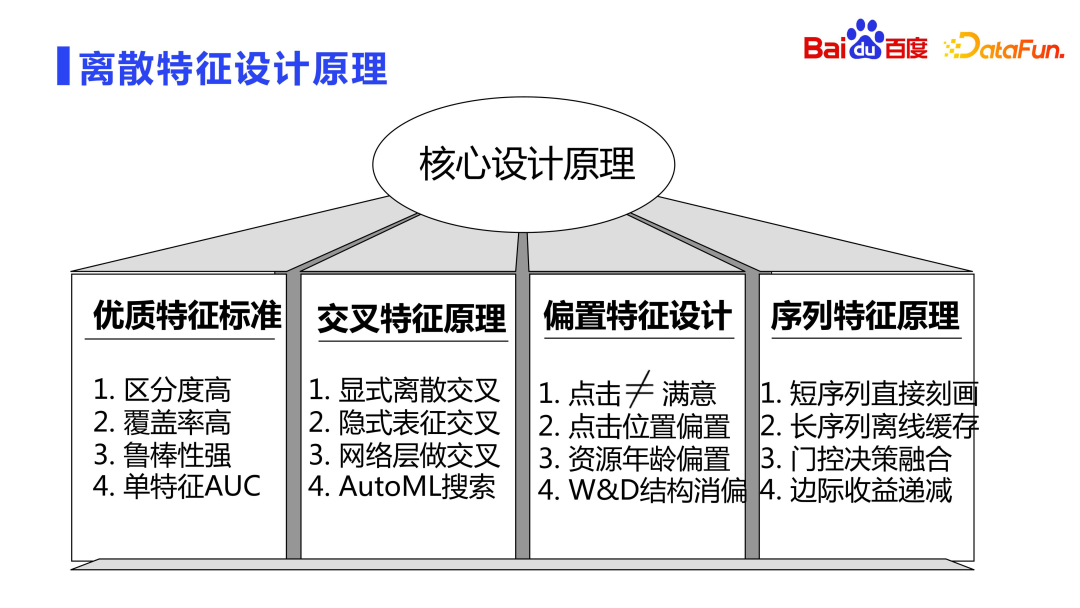
Keteguhan Kuat: Pengagihan ciri itu sendiri mestilah agak stabil dan tidak boleh berubah secara drastik dari semasa ke semasa.
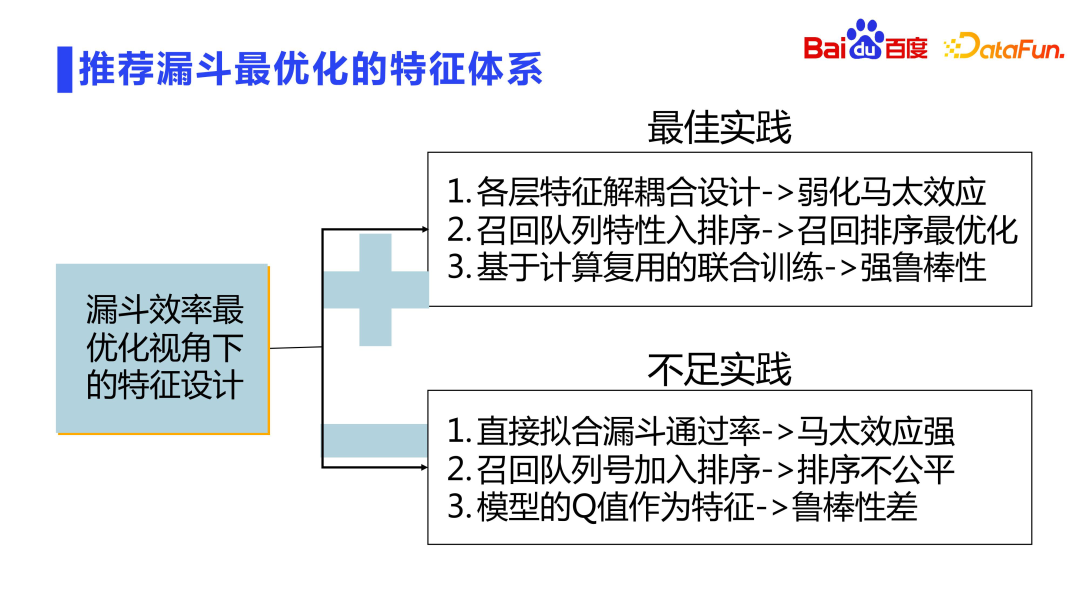
Keseluruhan corong pengesyoran direka bentuk dalam lapisan dan setiap lapisan ditapis dan dipotong. Bagaimana untuk mencapai kecekapan maksimum dalam reka bentuk berlapis dengan pemotongan penapis? Seperti yang dinyatakan sebelum ini, kami akan melakukan latihan bersama model. Selain itu, reka bentuk berkaitan juga boleh dilakukan dalam dimensi reka bentuk ciri. Terdapat juga beberapa masalah di sini:
Seterusnya, kami akan memperkenalkan reka bentuk algoritma teras.
Pertama, mari lihat model pengisihan pengesyoran. Secara amnya dipercayai bahawa penarafan halus adalah model yang paling tepat dalam sistem pengesyoran. Terdapat pandangan dalam industri bahawa susun atur kasar dilampirkan pada susun atur halus dan boleh dipelajari daripada susun atur halus Walau bagaimanapun, dalam amalan sebenar, telah didapati bahawa susun atur kasar tidak boleh dipelajari secara langsung daripada susun atur halus, yang boleh menyebabkan banyak masalah.
Seperti yang anda lihat dari gambar di atas, kedudukan isihan kasar dan isihan halus adalah berbeza. Secara umumnya, sampel latihan pengisihan kasar adalah sama dengan sampel pengisihan halus, yang juga merupakan sampel paparan. Setiap kali terdapat berpuluh-puluh ribu calon dipanggil semula untuk kedudukan kasar, lebih daripada 99% sumber tidak dipaparkan, dan model itu hanya menggunakan sedozen atau lebih sumber yang akhirnya dipaparkan untuk latihan, yang memecahkan kebebasan Di bawah andaian pengedaran yang sama, pengedaran model luar talian sangat berbeza. Situasi ini paling serius dalam penarikan balik, kerana set calon penarikan semula adalah berjuta-juta, berpuluh-puluh juta atau bahkan ratusan juta, dan kebanyakan keputusan akhir yang dikembalikan tidak dipaparkan juga kerana set calon biasanya masuk berpuluh ribu. Pengisihan yang halus secara relatifnya lebih baik Setelah melalui corong dua lapisan penarikan balik dan pengisihan kasar, kualiti asas sumber terjamin terutamanya dalam memilih yang terbaik daripada yang terbaik. Oleh itu, masalah ketidakkonsistenan pengedaran luar talian dalam penarafan halus tidak begitu serius, dan tidak perlu mengambil kira terlalu banyak masalah bias pemilihan sampel (SSB Pada masa yang sama, kerana set calon adalah kecil, pengiraan berat boleh). dilakukan. Kedudukan halus memfokuskan pada persimpangan ciri, pemodelan jujukan, dsb.
Walau bagaimanapun, tahap pengisihan kasar tidak boleh dipelajari secara langsung daripada pengisihan halus, juga tidak boleh dikira semula secara langsung sama dengan pengisihan halus, kerana jumlah pengiraan adalah berpuluh kali ganda daripada pengisihan halus secara langsung konsep reka bentuk ialah mesin dalam talian tidak boleh ditanggung sepenuhnya, jadi susun atur yang kasar memerlukan tahap kemahiran yang tinggi untuk mengimbangi prestasi dan kesan. Ia adalah modul yang ringan. Fokus lelaran pengisihan kasar adalah berbeza daripada pengisihan halus Ia terutamanya menyelesaikan masalah seperti bias pemilihan sampel dan pengoptimuman baris gilir. Memandangkan pengisihan kasar berkait rapat dengan penarikan balik, lebih banyak perhatian diberikan kepada kualiti purata beribu-ribu sumber yang dikembalikan kepada pengisihan halus dan bukannya hubungan pengisihan yang tepat. Kedudukan halus lebih berkait rapat dengan penyusunan semula dan lebih memfokuskan pada ketepatan AUC bagi satu titik.
Oleh itu, dalam reka bentuk ranking kasar, ia lebih kepada pemilihan dan penjanaan sampel, dan reka bentuk ciri dan rangkaian generalisasi. Reka bentuk yang diperhalusi boleh melakukan ciri persimpangan berbilang pesanan yang kompleks, pemodelan jujukan ultra-panjang, dsb.
Pengenalan sebelum ini adalah pada peringkat makro.
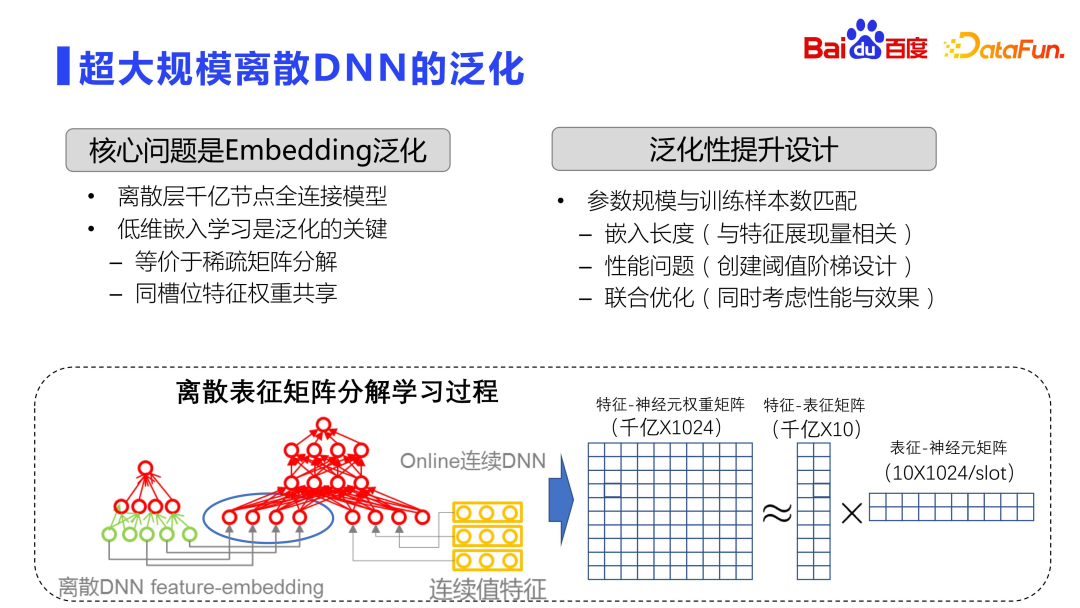
Khusus mengenai proses latihan model, arus perdana semasa dalam industri adalah menggunakan DNN diskret berskala ultra besar, dan masalah generalisasi akan menjadi lebih serius. Kerana DNN diskret berskala ultra-besar, melalui lapisan pembenaman, terutamanya melaksanakan fungsi ingatan. Lihat rajah di atas Keseluruhan ruang benam adalah matriks yang sangat besar, biasanya dengan ratusan bilion atau trilion baris dan 1,000 lajur. Oleh itu, latihan model diedarkan sepenuhnya, dengan berpuluh-puluh atau bahkan ratusan GPU melakukan latihan teragih.
Secara teorinya, untuk matriks yang begitu besar, pengiraan ganas tidak akan dilakukan secara langsung, tetapi operasi yang serupa dengan penguraian matriks akan digunakan. Sudah tentu, penguraian matriks ini berbeza daripada penguraian matriks SVD standard Penguraian matriks di sini mula-mula mempelajari perwakilan dimensi rendah, dan mengurangkan jumlah pengiraan dan penyimpanan melalui perkongsian parameter antara slot, iaitu, ia diuraikan menjadi. dua matriks proses pembelajaran. Yang pertama ialah ciri dan matriks perwakilan, yang akan mempelajari hubungan antara ciri dan pembenaman dimensi rendah ini sangat rendah, dan pembenaman kira-kira sepuluh dimensi biasanya dipilih. Yang satu lagi ialah matriks pembenaman dan neuron, dan pemberat antara setiap slot dikongsi. Dengan cara ini, volum storan dikurangkan dan kesannya bertambah baik.
lower-dimensi-dimensi pembelajaran adalah kunci untuk mengoptimumkan keupayaan generalisasi DNN di luar talian. skala dan nombor sampel lebih baik. . sumber , pengguna kepala boleh menggunakan dimensi benam yang lebih panjang Ini adalah idea umum dimensi benam yang dinamik, iaitu, lebih banyak dipaparkan lebih panjang dimensi benam. Sudah tentu, jika anda ingin menjadi lebih mewah, anda boleh menggunakan autoML dan kaedah lain untuk melakukan pembelajaran pengukuhan dan secara automatik mencari panjang benam yang optimum.
Aspek kedua ialah ambang penciptaan Memandangkan sumber yang berbeza mempunyai jumlah paparan yang berbeza, masa untuk mencipta perwakilan terbenam untuk ciri juga perlu dipertimbangkan.
Industri biasanya menggunakan kaedah latihan dua peringkat untuk menahan pemasangan berlebihan. Keseluruhan model terdiri daripada dua lapisan, satu adalah lapisan matriks diskret yang besar, dan satu lagi adalah lapisan parameter padat kecil. Lapisan matriks diskret sangat mudah untuk overfit, jadi amalan industri biasanya menggunakan Latihan Satu Lulus, iaitu, pembelajaran dalam talian, di mana semua data dilalui, dan latihan kelompok tidak dilakukan seperti di akademi.
Selain itu, industri biasanya menggunakan set pengesahan masa untuk menyelesaikan masalah overfitting lapisan jarang. Bahagikan keseluruhan set data latihan kepada banyak Delta, T0, T1, T2 dan T3, mengikut dimensi masa. Setiap latihan ditetapkan dengan lapisan parameter diskret yang dilatih beberapa jam yang lalu, dan kemudian data Delta seterusnya digunakan untuk memperhalusi rangkaian padat. Iaitu, dengan membetulkan lapisan jarang dan melatih semula parameter lain, masalah overfitting model dapat dikurangkan.
Pendekatan ini juga akan membawa masalah lain, kerana latihan dibahagikan, dan parameter diskret pada masa T0 perlu diperbaiki setiap kali, dan kemudian peringkat gabungan dilatih semula pada masa t+1, yang akan menyeret ke bawah keseluruhan latihan. Oleh itu, dalam beberapa tahun kebelakangan ini, latihan satu peringkat telah diterima pakai, iaitu lapisan perwakilan diskret dan lapisan rangkaian padat dikemas kini secara serentak dalam Delta. Terdapat juga masalah dengan latihan satu peringkat, kerana sebagai tambahan kepada ciri membenamkan, keseluruhan model juga mempunyai banyak ciri bernilai berterusan ini akan mengira klik paparan setiap ciri diskret risiko persilangan data. Oleh itu, dalam amalan sebenar, langkah pertama adalah untuk mengalih keluar ciri statistik, dan langkah kedua adalah untuk melatih rangkaian padat bersama-sama dengan perwakilan diskret, menggunakan kaedah latihan satu peringkat. Di samping itu, keseluruhan panjang terbenam boleh berskala secara automatik. Melalui siri kaedah ini, latihan model boleh dipercepatkan kira-kira 30%. Amalan menunjukkan bahawa tahap overfitting kaedah ini adalah sangat sedikit, dan perbezaan antara AUC latihan dan ujian adalah 1/1000 atau lebih rendah.
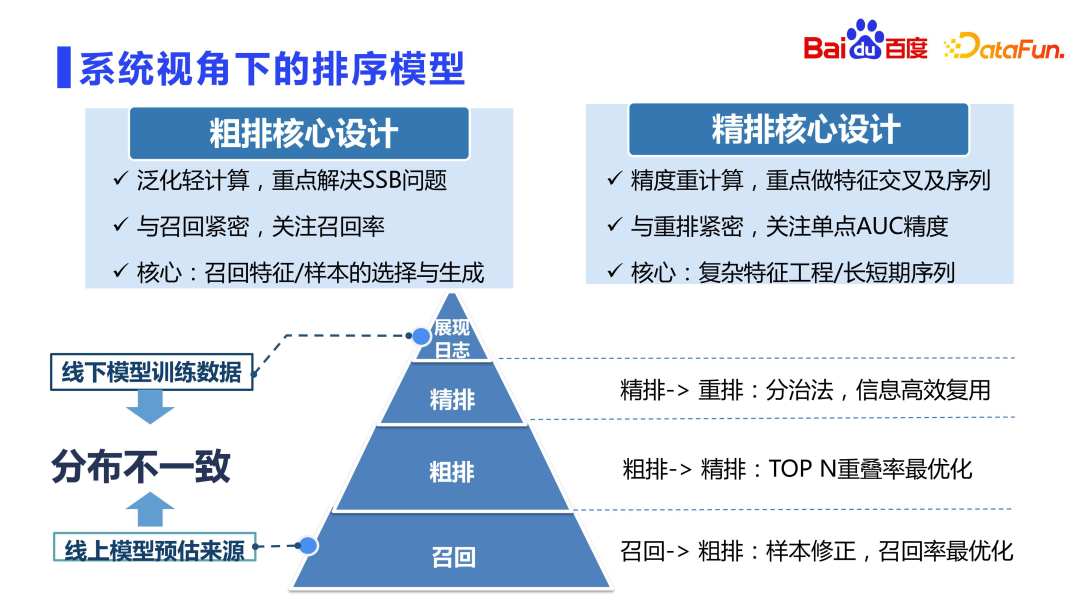
1. Prinsip reka bentuk berlapis sistem
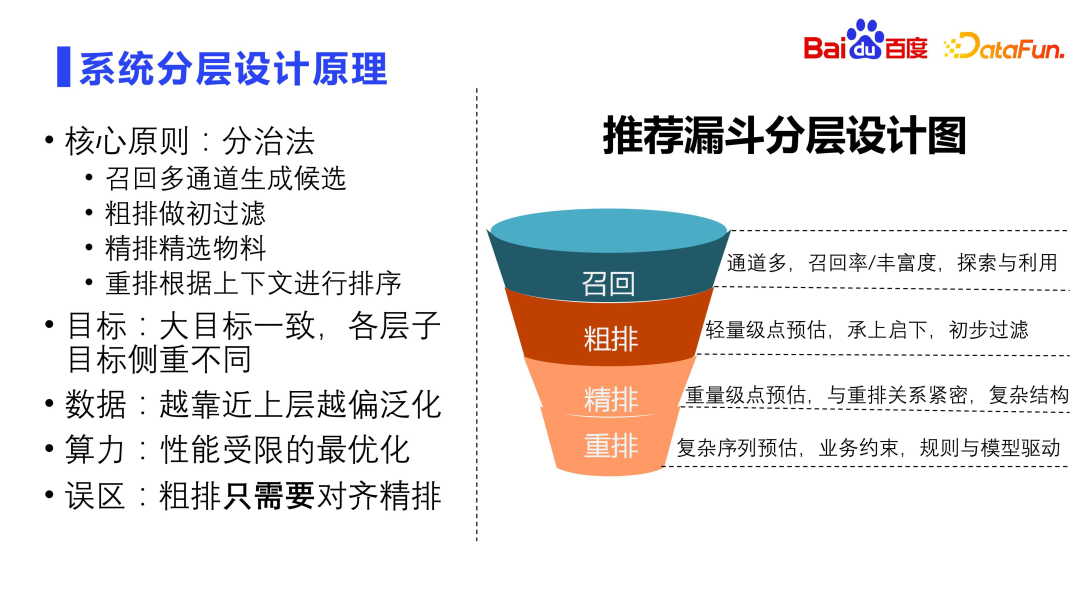 Matlamat setiap lapisan sistem pengesyoran pada asasnya adalah sama, tetapi fokus setiap lapisan adalah berbeza. Penarafan ingat dan kasar tertumpu pada pengitlak dan kadar ingatan, penarafan halus memfokuskan pada ketepatan AUC titik tunggal, dan penyusunan semula memfokuskan pada pengoptimuman jujukan keseluruhan. Dari sudut pandangan data, lebih dekat dengan pengisihan kasar ingatan, lebih umum ia, dan lebih dekat dengan pengisihan dan penyusunan semula yang halus, lebih banyak ketepatan diperlukan. Lebih dekat dengan sumber panggil balik, lebih serius had prestasi, kerana lebih banyak sumber calon, lebih besar kerumitan pengiraan. Ini adalah salah faham bahawa pengisihan kasar hanya perlu diselaraskan dengan pengisihan halus perlu mempertimbangkan konsistensi dengan pengisihan halus, tetapi ia tidak boleh hanya diselaraskan dengan pengisihan halus. Jika anda tidak melakukan apa-apa untuk pengisihan kasar dan hanya menyelaraskan dan menyusun halus, ia akan membawa kesan kuda
Matlamat setiap lapisan sistem pengesyoran pada asasnya adalah sama, tetapi fokus setiap lapisan adalah berbeza. Penarafan ingat dan kasar tertumpu pada pengitlak dan kadar ingatan, penarafan halus memfokuskan pada ketepatan AUC titik tunggal, dan penyusunan semula memfokuskan pada pengoptimuman jujukan keseluruhan. Dari sudut pandangan data, lebih dekat dengan pengisihan kasar ingatan, lebih umum ia, dan lebih dekat dengan pengisihan dan penyusunan semula yang halus, lebih banyak ketepatan diperlukan. Lebih dekat dengan sumber panggil balik, lebih serius had prestasi, kerana lebih banyak sumber calon, lebih besar kerumitan pengiraan. Ini adalah salah faham bahawa pengisihan kasar hanya perlu diselaraskan dengan pengisihan halus perlu mempertimbangkan konsistensi dengan pengisihan halus, tetapi ia tidak boleh hanya diselaraskan dengan pengisihan halus. Jika anda tidak melakukan apa-apa untuk pengisihan kasar dan hanya menyelaraskan dan menyusun halus, ia akan membawa kesan kuda
2. Latihan bersama model berbilang peringkat
Hubungan antara kedudukan halus dan penyusunan semula adalah sangat rapat pada tahun-tahun awal, penyusunan semula secara langsung dilatih menggunakan skor kedudukan yang baik , ia digabungkan Ia sangat serius Sebaliknya, menggunakan pemarkahan yang tepat secara langsung untuk latihan boleh menyebabkan turun naik dalam talian. 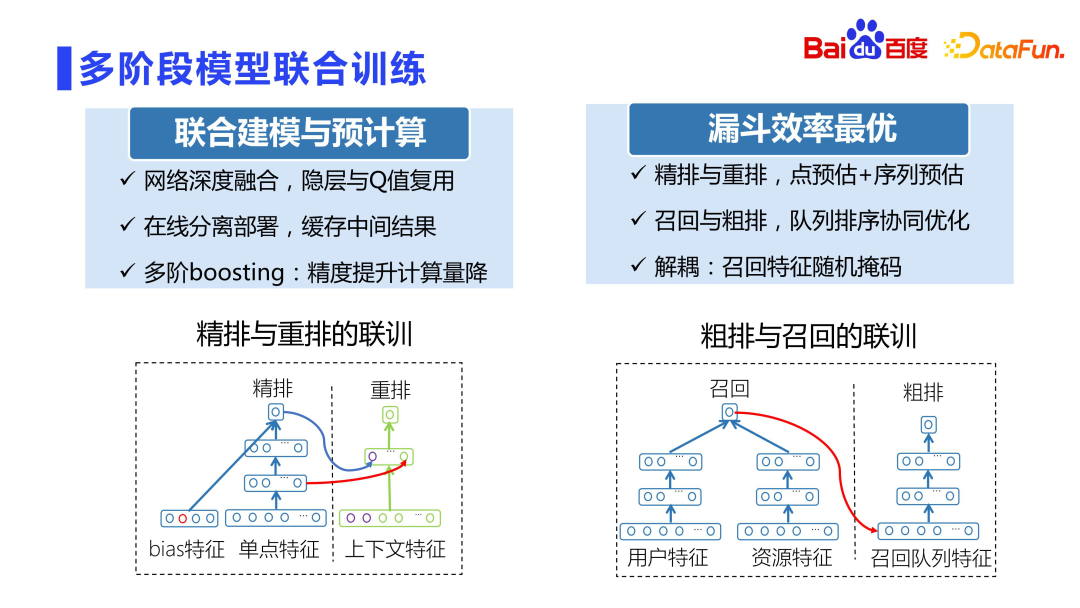
Baidu Fengchao CTR 3.0 projek latihan bersama kedudukan dan penyusunan semula dengan sangat bijak menggunakan model untuk berlatih serentak untuk mengelakkan masalah gandingan pemarkahan. Projek ini menggunakan lapisan tersembunyi dan pemarkahan dalaman sub-rangkaian peringkat halus sebagai ciri-ciri sub-rangkaian penyusunan semula Kemudian, sub-rangkaian penyusunan halus dan penyusunan semula diasingkan dan digunakan dalam modul masing-masing. Di satu pihak, keputusan pertengahan boleh digunakan semula dengan baik tanpa masalah turun naik yang disebabkan oleh gandingan pemarkahan Pada masa yang sama, ketepatan penyusunan semula akan dipertingkatkan dengan peratusan. Ini juga merupakan salah satu sub-projek yang menerima anugerah tertinggi Baidu pada tahun itu.
Selain itu, sila ambil perhatian bahawa projek ini bukanlah ESSM ESSM ialah pemodelan CTCVR dan pemodelan berbilang objektif, dan latihan bersama CTR3.0 terutamanya menyelesaikan masalah gandingan pemarkahan dan ketepatan model penyusunan semula.
Selain itu, penarikan balik dan pengisihan kasar mesti dipisahkan, kerana baris gilir baru ditambah, yang mungkin tidak adil kepada baris gilir baru. Oleh itu, kaedah topeng rawak dicadangkan, iaitu menutup beberapa ciri secara rawak supaya tahap gandingan tidak begitu kuat.
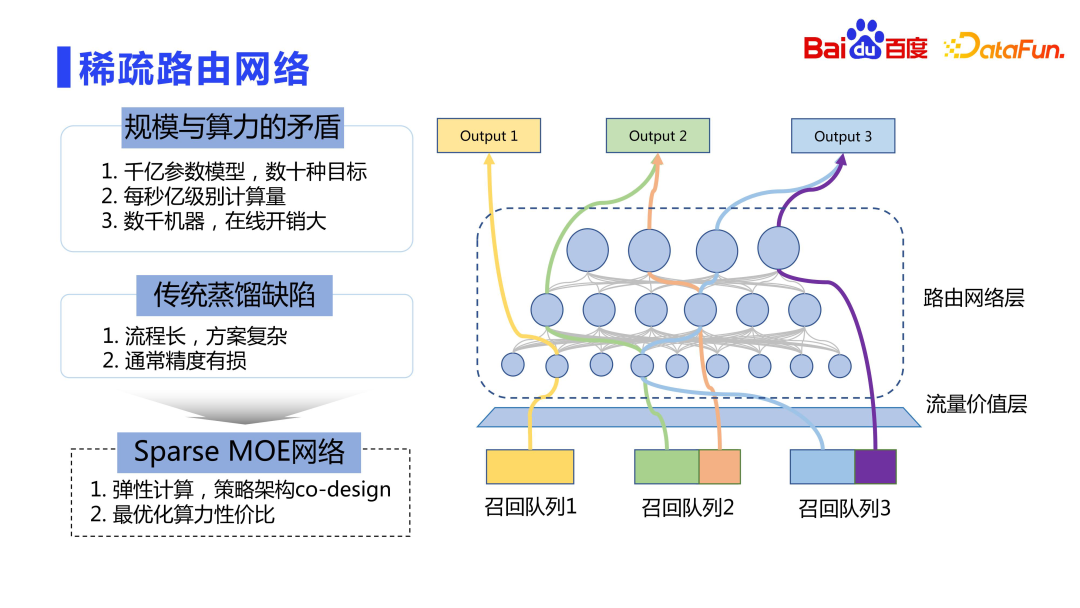
Akhirnya mari kita lihat proses penggunaan dalam talian. Skala parameter model adalah dalam susunan ratusan bilion hingga trilion, dan terdapat banyak sasaran Penggunaan dalam talian langsung adalah sangat mahal, dan kami tidak boleh hanya mempertimbangkan kesannya tanpa mengambil kira prestasi. Cara yang lebih baik ialah pengiraan elastik, sama dengan idea KPM Jarang.
Barisan kasar mempunyai akses kepada banyak baris gilir, dengan berpuluh-puluh malah ratusan barisan. Baris gilir ini mempunyai nilai dalam talian (LTV) yang berbeza Lapisan nilai trafik mengira nilai baris gilir ingat yang berbeza kepada tempoh klik dalam talian. Idea terasnya ialah lebih besar sumbangan keseluruhan baris gilir penarikan balik, pengiraan yang lebih kompleks boleh dinikmati. Ini membolehkan kuasa pengkomputeran terhad untuk melayani trafik bernilai lebih tinggi. Oleh itu, kami tidak menggunakan kaedah penyulingan tradisional, tetapi menerima pakai idea yang serupa dengan Sparse MOE untuk pengkomputeran elastik, iaitu reka bentuk strategi dan reka bentuk bersama seni bina, supaya baris gilir panggil yang berbeza boleh menggunakan rangkaian sumber yang paling sesuai untuk pengiraan. .
Seperti yang kita sedia maklum, kini kita sudah memasuki era model besar LLM. Penerokaan Baidu terhadap sistem cadangan generasi akan datang berdasarkan model bahasa besar LLM akan dijalankan dari tiga aspek.

Aspek pertama ialah menaik taraf model daripada ramalan asas kepada boleh membuat keputusan. Sebagai contoh, isu penting seperti penerokaan cekap sumber permulaan sejuk klasik, maklum balas pengesyoran urutan mendalam dan rantaian membuat keputusan daripada carian hingga pengesyoran semuanya boleh dibuat dengan bantuan model besar.
Aspek kedua ialah dari diskriminasi kepada generasi Kini keseluruhan model adalah diskriminasi Pada masa hadapan, kami akan meneroka kaedah pengesyoran generatif, seperti menjana sebab pengesyoran secara automatik, meningkatkan data ekor panjang secara automatik berdasarkan gesaan. model perolehan semula.
Aspek ketiga ialah dari kotak hitam kepada kotak putih Dalam sistem pengesyoran tradisional, orang sering mengatakan bahawa rangkaian saraf adalah alkimia dan kotak hitam sama ada boleh meneroka ke arah kotak putih juga tugas penting pada masa hadapan. Contohnya, berdasarkan sebab dan akibat, kita boleh meneroka sebab di sebalik peralihan keadaan gelagat pengguna, membuat anggaran tidak berat sebelah yang lebih baik dari segi kesaksamaan pengesyoran dan membolehkan penyesuaian adegan yang lebih baik dalam senario Pembelajaran Mesin Berbilang Tugas.
Atas ialah kandungan terperinci Penerokaan dan aplikasi teknologi ranking Baidu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



