


Baru-baru ini, kajian yang dijalankan oleh Microsoft mendedahkan betapa fleksibelnya perisian pemprosesan video PS
Dalam kajian ini, anda hanya memberikan AI foto, dan ia boleh menghasilkan video orang dalam foto , ekspresi dan pergerakan watak boleh dikawal melalui teks. Contohnya, jika arahan yang anda berikan ialah "buka mulut," watak dalam video itu sebenarnya akan membuka mulutnya.

Jika arahan yang anda berikan adalah "sedih", dia akan membuat ekspresi sedih dan pergerakan kepala.
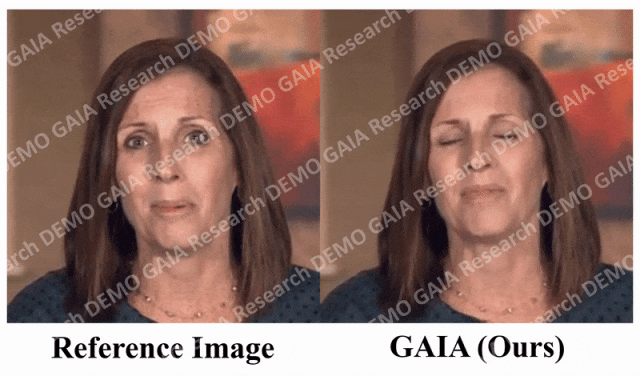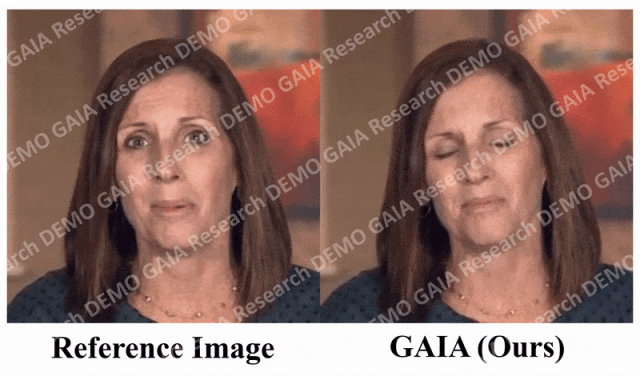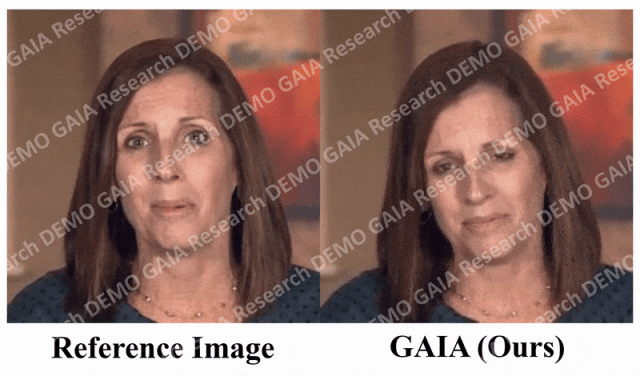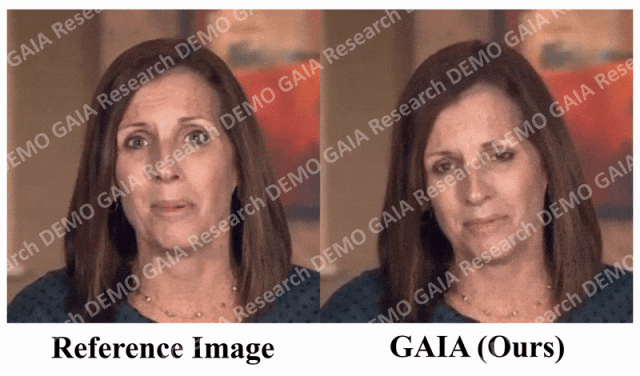
Apabila arahan "kejutan" diberikan, garisan dahi avatar dihimpit bersama.

Selain itu, anda juga boleh menyediakan suara untuk menyelaraskan bentuk mulut dan pergerakan watak maya dengan suara tersebut. Sebagai alternatif, anda boleh menyediakan video langsung untuk ditiru oleh avatar
Jika anda mempunyai lebih banyak keperluan penyuntingan tersuai untuk pergerakan avatar, seperti membuat mereka mengangguk, menoleh atau memiringkan kepala, teknologi ini juga disokong

Penyelidikan ini dipanggil GAIA (AI Generatif untuk Avatar, AI generatif untuk avatar), dan demonya telah mula tersebar di media sosial. Ramai orang mengagumi kesannya dan berharap dapat menggunakannya untuk "membangkitkan" orang mati.
Tetapi sesetengah orang bimbang bahawa evolusi berterusan teknologi ini akan menjadikan video dalam talian lebih sukar untuk dibezakan antara tulen dan palsu, atau digunakan oleh penjenayah untuk penipuan. Nampaknya langkah anti penipuan akan terus ditingkatkan.
Teknologi penjanaan watak maya bercakap sampel sifar bertujuan untuk mensintesis video semula jadi berdasarkan pertuturan, memastikan bentuk mulut, ekspresi dan postur kepala yang dihasilkan adalah konsisten dengan kandungan pertuturan. Penyelidikan terdahulu biasanya memerlukan latihan khusus atau penalaan model khusus untuk setiap watak maya, atau menggunakan video templat semasa inferens untuk mencapai hasil yang berkualiti tinggi. Baru-baru ini, penyelidik telah menumpukan pada mereka bentuk dan menambah baik kaedah untuk menghasilkan avatar bercakap sifar pukulan dengan hanya menggunakan imej potret avatar sasaran sebagai rujukan penampilan. Walau bagaimanapun, kaedah ini biasanya menggunakan prior domain seperti perwakilan gerakan berasaskan meledingkan dan Model Boleh Morf 3D (3DMM) untuk mengurangkan kesukaran tugasan. Heuristik sedemikian, walaupun berkesan, mungkin mengehadkan kepelbagaian dan membawa kepada hasil yang tidak wajar. Oleh itu, pembelajaran langsung daripada pengedaran data adalah fokus penyelidikan masa depan
Dalam artikel ini, penyelidik dari Microsoft mencadangkan GAIA (Generative AI for Avatar), yang boleh mensintesis orang yang bercakap secara semula jadi daripada gambar pertuturan dan potret tunggal. domain prior dihapuskan semasa proses penjanaan.

Alamat projek: https://microsoft.github.io/GAIA/Perincian projek berkaitan boleh didapati di pautan ini
Pautan kertas: https://arxiv.org/pdf/ 2311.2311. .pdf
Gaia mendedahkan dua pandangan utama:
Berdasarkan dua cerapan di atas, kertas kerja ini mencadangkan rangka kerja GAIA, yang terdiri daripada pengekod auto variasi (VAE) (modul oren) dan model resapan (modul biru dan hijau).
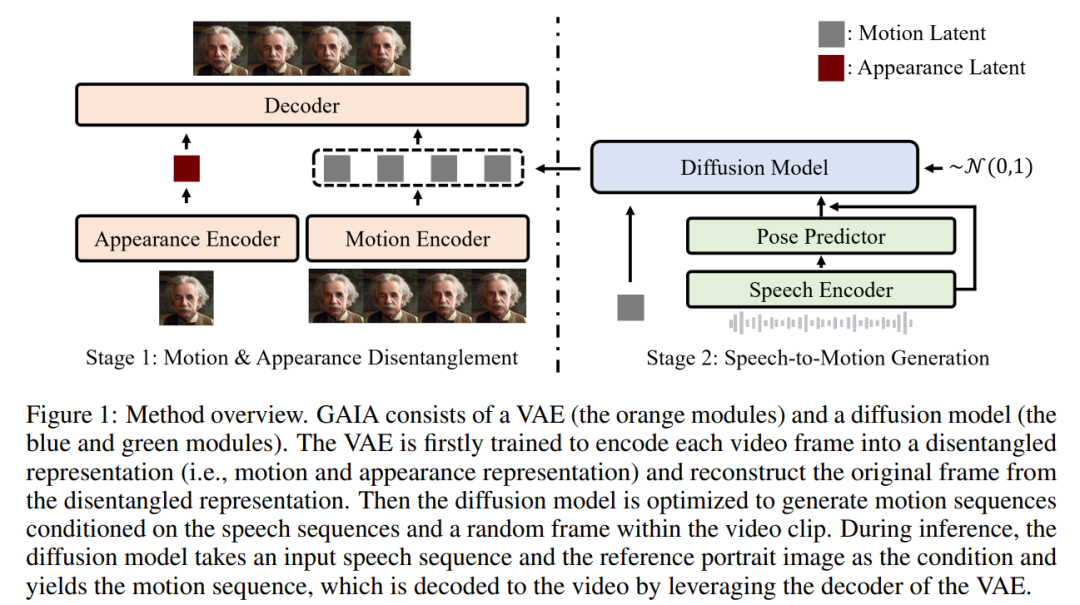
Fungsi utama VAE adalah untuk memecahkan pergerakan dan penampilan. Ia terdiri daripada dua pengekod (pengekod gerakan dan pengekod rupa) dan penyahkod. Semasa latihan, input kepada pengekod gerakan ialah bingkai semasa tanda tempat muka, manakala input kepada pengekod penampilan ialah bingkai sampel rawak dalam klip video semasa
Berdasarkan output kedua-dua pengekod ini, ia kemudiannya penyahkod dioptimumkan untuk membina semula bingkai semasa. Sebaik sahaja anda mendapat VAE terlatih, anda mendapat tindakan yang berpotensi (iaitu output pengekod gerakan) untuk semua data latihan
Kemudian, artikel ini menggunakan model resapan yang dilatih untuk meramal gerakan berdasarkan bingkai sampel rawak daripada pertuturan dan klip video Urutan terpendam gerakan, dengan itu memberikan maklumat penampilan untuk proses penjanaan
Dalam proses inferens, diberikan imej potret rujukan watak maya sasaran, model resapan mengambil imej dan urutan pertuturan input sebagai syarat untuk menjana urutan terpendam gerakan yang menepati kandungan pertuturan. Urutan terpendam gerakan dan imej potret rujukan kemudiannya disalurkan melalui penyahkod VAE untuk mensintesis output video pertuturan.
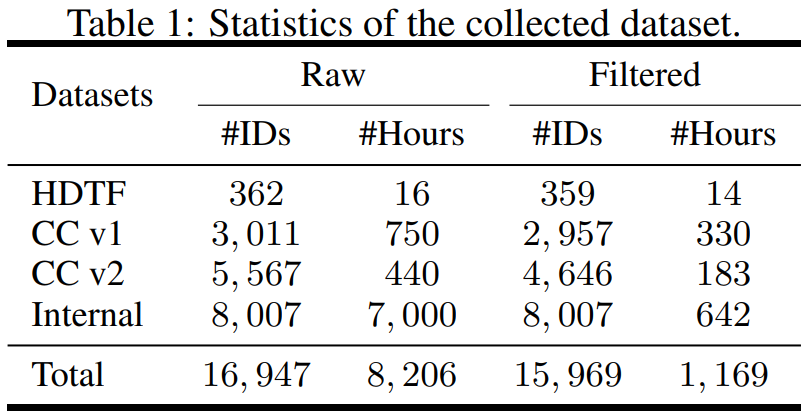
Kajian ini berstruktur dari segi data, mengumpul set data daripada sumber berbeza termasuk Set Data Muka Bercakap Definisi Tinggi (HDTF) dan set data Perbualan Kasual v1&v2 (CC v1&v2). Selain tiga set data ini, penyelidikan juga mengumpul set data avatar pertuturan dalaman berskala besar yang mengandungi 7K jam video dan 8K ID pembesar suara. Gambaran keseluruhan statistik set data ditunjukkan dalam Jadual 1
Untuk mempelajari maklumat yang diperlukan, artikel tersebut mencadangkan beberapa strategi penapisan automatik untuk memastikan kualiti data latihan:
Artikel ini melatih model VAE dan penyebaran pada data yang ditapis. Daripada keputusan percubaan, kertas kerja ini telah memperoleh tiga kesimpulan utama:
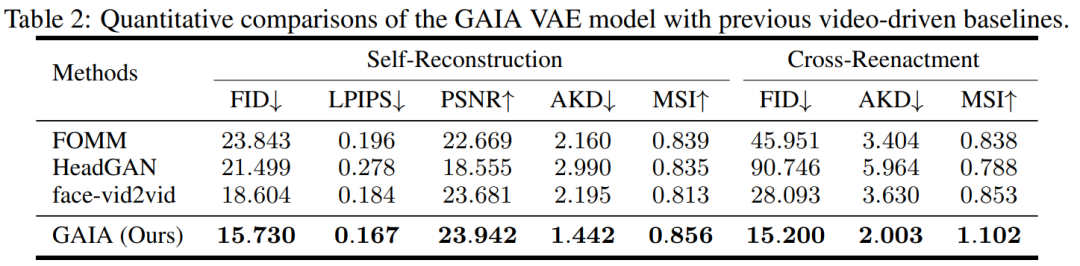
Semasa percubaan, kajian membandingkan GAIA dengan tiga garis dasar yang kuat, termasuk FOMM, HeadGAN dan Face-vid2vid. Keputusan ditunjukkan dalam Jadual 2: VAE dalam GAIA mencapai peningkatan yang konsisten berbanding garis dasar dipacu video sebelumnya, menunjukkan bahawa GAIA berjaya menguraikan penampilan dan perwakilan gerakan.
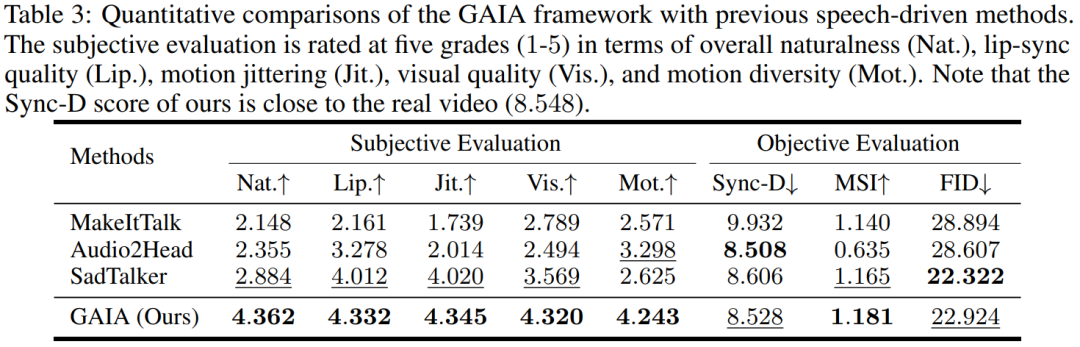
Hasil dipacu suara. Penjanaan avatar pertuturan dipacu pertuturan dicapai dengan meramalkan gerakan daripada pertuturan. Jadual 3 dan Rajah 2 memberikan perbandingan kuantitatif dan kualitatif GAIA dengan kaedah MakeItTalk, Audio2Head dan SadTalker.
Adalah jelas daripada data bahawa GAIA jauh mengatasi semua kaedah asas dari segi penilaian subjektif. Lebih khusus, seperti yang ditunjukkan dalam Rajah 2, walaupun imej rujukan mempunyai mata tertutup atau pose kepala yang luar biasa, hasil penjanaan kaedah garis dasar biasanya sangat bergantung pada imej rujukan sebaliknya, GAIA mempamerkan prestasi yang baik pada pelbagai imej rujukan. Teguh dan menjana hasil dengan keaslian yang lebih tinggi, penyegerakan bibir yang tinggi, kualiti visual yang lebih baik dan kepelbagaian gerakan

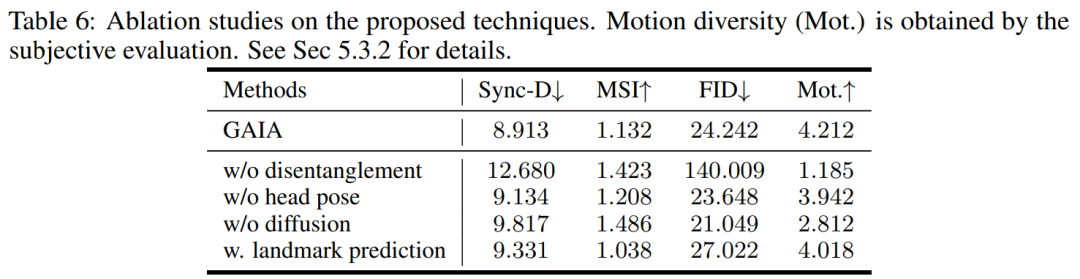
Menurut Jadual 3, skor MSI terbaik menunjukkan bahawa video yang dihasilkan oleh GAIA Mempunyai kestabilan pergerakan yang sangat baik. Skor Sync-D 8.528 adalah hampir dengan skor video sebenar (8.548), menunjukkan bahawa video yang dihasilkan mempunyai penyegerakan bibir yang sangat baik. Kajian itu mencapai skor FID yang setanding dengan garis dasar, yang mungkin telah dipengaruhi oleh pose kepala yang berbeza, kerana kajian mendapati bahawa model tanpa latihan penyebaran mencapai skor FID yang lebih baik, seperti yang diperincikan dalam Jadual 6
Atas ialah kandungan terperinci Foto menghasilkan video Membuka mulut, mengangguk, emosi, kemarahan, kesedihan dan kegembiraan semuanya boleh dikawal dengan menaip.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
Penyelesaian kepada sambungan gagal antara wsus dan pelayan Microsoft
 javac tidak diiktiraf sebagai arahan dalaman atau luaran atau program yang boleh dikendalikan Bagaimana untuk menyelesaikan masalah?
javac tidak diiktiraf sebagai arahan dalaman atau luaran atau program yang boleh dikendalikan Bagaimana untuk menyelesaikan masalah?
 Bagaimanakah cara saya menyediakan WeChat untuk memerlukan persetujuan saya apabila orang menambahkan saya ke kumpulan?
Bagaimanakah cara saya menyediakan WeChat untuk memerlukan persetujuan saya apabila orang menambahkan saya ke kumpulan?
 Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
Bagaimana untuk menyemak sama ada kata laluan mysql terlupa
 Bagaimana untuk menulis kod kotak teks html
Bagaimana untuk menulis kod kotak teks html
 Platform dagangan pukal
Platform dagangan pukal
 Apakah perbezaan antara rangka kerja css dan perpustakaan komponen
Apakah perbezaan antara rangka kerja css dan perpustakaan komponen
 Bagaimana untuk membuang tera air pada TikTok
Bagaimana untuk membuang tera air pada TikTok








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



